
Any team that slings code for a living deals with service issues. They know all too well the hated red alert… the dreaded text in the middle of the night… the loathsome ping from a coworker telling them that $#!π just hit the fan. But what separates good services from great services is the ability to recover swiftly with minimal effect on users. And a big factor in swift recovery is ChatOps.
All teams that build and run software should have a process for dealing with incident management – it’s part of the job. The more the software community shares these best practices, the better everyone is at dealing with them. So we wanted to share some of the ways we deal with incidents here at Atlassian using ChatOps.
We use our own products, as well as many others, to run incident management when a service is in trouble. With new developments in Hipchat’s API, Atlassian site reliability engineering (SRE) teams are taking their ChatOps practice to a new level. Here’s how they do it.
A bit about our SRE team

Following a continuous delivery model, our engineering teams push code to production several times a day. Our products run in the cloud and rely on a matrix of other cloud tools working together. So we rely on our SRE teams (yes, plural: most products and a handful of web properties have dedicated SREs) to monitor production health at the macro level so we can resolve incidents promptly. And they, in turn, rely on Jira Service Desk as their ticketing system. As soon as an incident arises, they create an issue to track the status, the work being done, and, ultimately, the resolution.
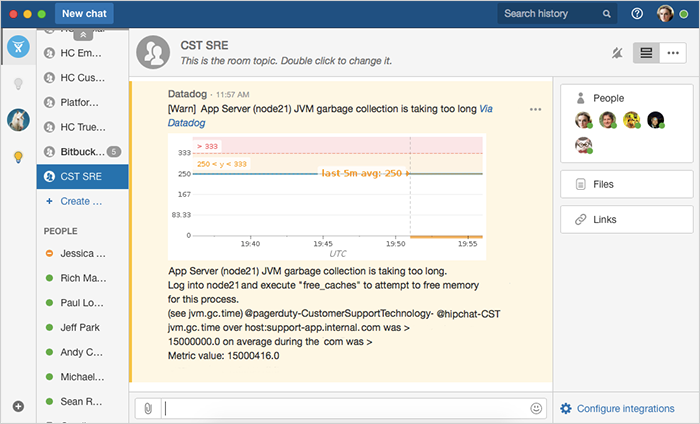
Our SRE teams use Hipchat as the base of operations for all reliability issues: bugs, site crash, alerts, asteroid, whatever. Because they use a wide range of tools – Jira Software, Jira Service Desk, Datadog, PagerDuty, Statuspage, and more – having Hipchat as the hub keeps our SRE teams focused on the task at hand.
While the particulars of each incident are different, the ChatOps approach to incident management follows the same basic steps each time.
Step 1: Verify there is an issue
 Usually issues start to appear in the teams’ chat rooms as alerts from integrated tools like Datadog, PagerDuty, Jira Service Desk, or Statuspage. Without chat, this process is much slower and harder. It might take several minutes (or an hour) for the right people to realize something is amiss and come together to discuss. Even then, the team can’t easily share what they are doing to diagnose the issue, which drags things down even further.
Usually issues start to appear in the teams’ chat rooms as alerts from integrated tools like Datadog, PagerDuty, Jira Service Desk, or Statuspage. Without chat, this process is much slower and harder. It might take several minutes (or an hour) for the right people to realize something is amiss and come together to discuss. Even then, the team can’t easily share what they are doing to diagnose the issue, which drags things down even further.
We measured this internally and found a 5x improvement in the speed of response when using chat to resolve the incident, versus before we adopted ChatOps.
Step 2. Evaluate the severity of issue in your chat room
 As alerts and tickets start to show up, everyone on the team sees them, and immediately starts discussing – transparency and information flow is a major benefit of chat-driven incident response. As a group, they verify whether the incident is being handled appropriately, or needs escalation. They often share charts, graphs, and tickets in their chat room to lend more context to the discussion.
As alerts and tickets start to show up, everyone on the team sees them, and immediately starts discussing – transparency and information flow is a major benefit of chat-driven incident response. As a group, they verify whether the incident is being handled appropriately, or needs escalation. They often share charts, graphs, and tickets in their chat room to lend more context to the discussion.
Pro-tip
Make sure every team has their own Hipchat room. Set notifications to “normal” so you’re always alerted when a teammate mentions your name or the entire room.
Step 3: Create a “hot room” or an incident-specific chat room
 All Atlassian teams’ Hipchat rooms are connected to Jira Service Desk. Anytime a ticket is filed against a critical component, an automated process kicks off – tight integration for the win! Hipchat creates a new room with the name of theJira Service Desk issue, and everyone watching the issue is invited to the room. We call this a “hot room”. Incident-specific rooms can also be created manually by clicking a button on the Jira issue, as shown below.
All Atlassian teams’ Hipchat rooms are connected to Jira Service Desk. Anytime a ticket is filed against a critical component, an automated process kicks off – tight integration for the win! Hipchat creates a new room with the name of theJira Service Desk issue, and everyone watching the issue is invited to the room. We call this a “hot room”. Incident-specific rooms can also be created manually by clicking a button on the Jira issue, as shown below.
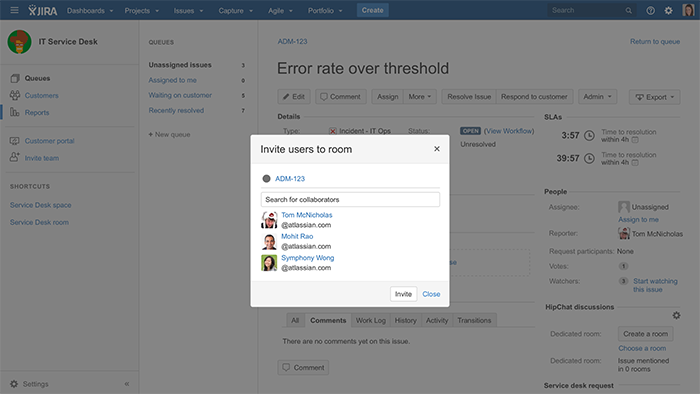
From here, the SRE responder goes into incident-management mode, paging the necessary developers through PagerDuty. The broader team is then invited into the “hot room” where everyone can see in real-time what is happening, who is doing what, and how the incident is being resolved.
Hot rooms typically include a cross-functional group – SRE, engineering, support, IT leadership, product management, product marketing, social media support – each playing a different role in the resolution process. Some are very active in the room, while others are more passive and simply use the room to monitor the state of the incident.
What makes ChatOps so effective is that everyone knows what everyone else is doing – transparent communication leads to faster resolution.
Once inside the room, everyone can reference details about the incident, pulled straight from the Jira Service Desk issue, in Hipchat’s side bar. They can even move an issue from Open to In Progress to Resolved, or add comments to it, right from Hipchat.
Pro-tip
By using Hipchat with Jira Service Desk, you and your teammates will get alerts with the exact name of the issue (i.e. HOT-330) when an incident is reported. And when a “hot room” is created through JSD, any teammate can search for the issue key to find that room.
Step 4: Make the information come to you and automate routine tasks
It’s hard to work in real-time to solve a problem if the information and reports you need to make a decision aren’t visible inside your chat room. The Bitbucket SRE team, for example, connects Datadog to their team chat room to receive warnings (complete with graphs!) anytime their support site shows signs of trouble. ChatOps helps reduce the endless alt-tabbing needed to work with multiple tools.

In this sense, their Hipchat room is more than a destination – it’s the canary in their coal mine. The sooner they can respond to incidents, the fewer support tickets relating to production help are raised and the more time they can spend making Bitbucket better and better.
Step 5: Enjoy the historical record you’ve just created

No one wants incidents to happen, but everyone wants them resolved ever-faster. That’s where the chat log comes in. It’s a ready-made transcript of the entire incident, perfect for post-incident review and root cause analysis.
Like all great teams, our SREs know that those who do not understand history are doomed to repeat it. Once an incident is resolved, our team immediately creates a Confluence page that explains exactly what happened, how we responded, and how we could improve next time. This is shared with the entire company, increasing transparency yet again, and helping other teams learn from the experience.
For SREs, ChatOps is about making sure all communication about an incident – graphs, reports, and data analysis – are centralized in a single stream. By defining a room and using the corresponding Jira Service Desk issue’s key as the name, they get a single source of truth for incident communications, and get the right people talking about the right issue in real-time. They also have a place to invite internal stakeholders (*ahem* the boss) or other engineers in so they can see all the updates, too.
The next big thing in collaboration
ChatOps keeps teams more productive, and customers happier. And this is just the beginning. Using tools like Hipchat, ChatOps’ potential applications stretch far and wide – beyond IT, and into development, support, and even business teams like PR.
The process I’ve described here didn’t pop into existence overnight – our SREs have iterated on this over many months. But it’s not rocket science either. My hope is that your team can use our current state as your starting point. Keep experimenting, and keep improving. And drop us a line to let us know how it goes.
Share with your team!
Download or share this quick-reference sheet on using ChatOps for incident management: 5 Steps to Resolve Incident 5 Times Faster with ChatOps
