In 2019, we wrote about Tenant Context Service (TCS), a critical infrastructure service at Atlassian which is called multiple times in the path of every web request for the majority of our cloud products. Since then, the TCS team has worked on many improvements to our client sidecar (a sidecar is a co-process that runs alongside a host service) and we’ve evolved it into a high-performing and resilient node-local cache. Our TCS sidecars can now serve up to 32 billion requests per day, run concurrently across up to 10,800 compute nodes, and have cache hit ratios that generally exceed 99.5%.
This post will discuss the technology behind it, ongoing improvements we’re making, and why we can now treat our TCS and sidecar like “infrastructure” that should never fail (like DNS resolution or the network). Getting above four nines of availability is hard and we’re now consistently above six nines. What we’ve learned on this journey might help you too!
TCS and sidecar architecture
Before we dive in, here’s a quick recap from our previous post:
- TCS is a CQRS system that is designed to provide a highly-available, read-optimized view of our catalogue of “tenant metadata.” This catalogue contains metadata required to locate and serve a request to any of our cloud products (like product shard locations, backing resource locations, etc).
- TCS lookups are required to serve every single request that hits Atlassian cloud products. Usually, there will be multiple lookups per request across different systems.
- As changes occur in the “tenant metadata” catalogue, TCS will ingest transformed views of the “tenant metadata” into AWS DynamoDB. These transformed records are then available to be fetched via a standard REST API.
- TCS is highly read-optimized. We make extensive use of L1 in-memory caches. An invalidation broadcasting system allows these in-memory caches to be long-lived, with background refresh as required.
- TCS sidecars are essentially remote extensions of our web server caches. They are co-processes that provide very similar long-lived in-memory caches, but running alongside our client applications.
- Our TCS deployments are entirely and independently replicated across multiple AWS regions.
- Our TCS sidecars are in active communication with multiple parent TCSs at all times. They are constantly re-evaluating the “health” of all parent TCSs. From this, they regularly choose the best TCS(s) for their request traffic and invalidation stream subscriptions.
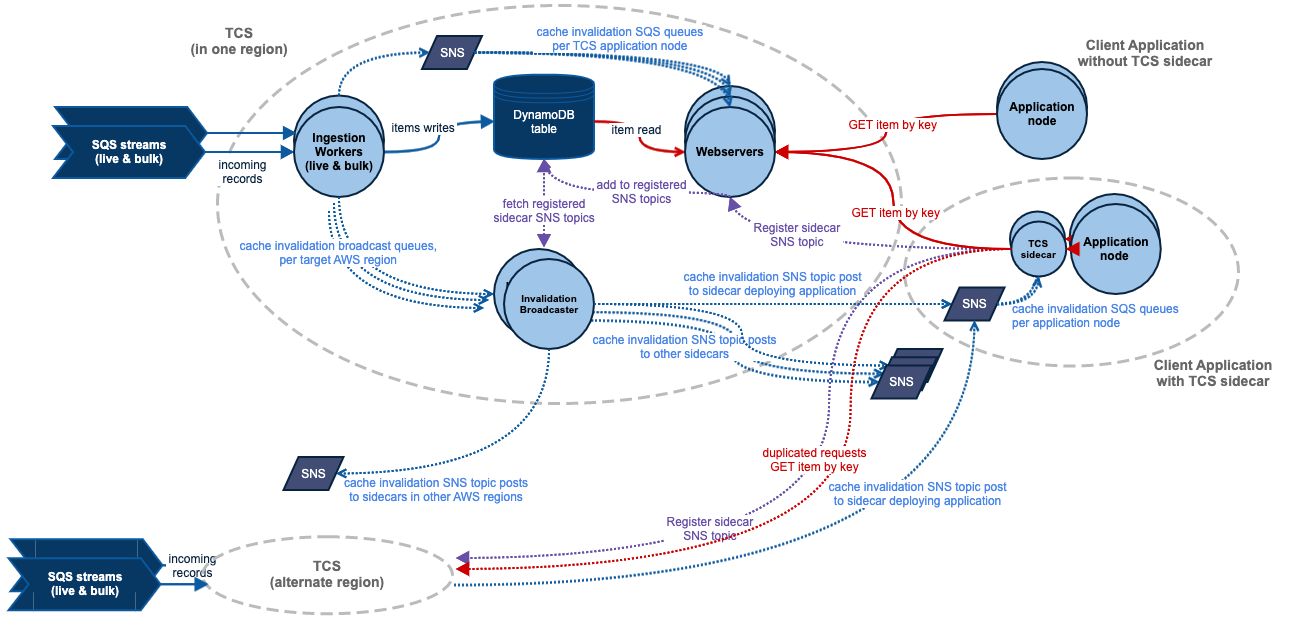
This architecture is set out in the following diagram. In this, we show the components of a single TCS within the big gray circle. Note that TCS deployments are independently replicated across multiple AWS regions.

Our TCS sidecar cache hit ratios allow our client applications to avoid observing any noticeable difference during a parent TCS outage. Going cross-region for a cache miss isn’t actually a big deal when you only need to do that on 0.5% of your actual requests. Our TCS servers have gone from being critical infrastructure with a massive blast radius on failure to just one component in a global network. Our clients (the TCS sidecars) are entirely capable of detecting faults in that network and just routing around them.
With the above architecture working so well, you might think we were finished. We have successfully defended against regional DynamoDB outages, SNS/SQS slowdown incidents, entire AWS region failures, and our own inevitable operational errors. We have run real chaos testing in production to prove it works. However, with increasing time and scale, new and unexpected failure modes will always show up, and we will always find new ways to improve. This blog documents more of our journey to scale, and beyond!
Complete region isolation
It’s easy to draw a diagram showing redundancy and/or region isolation. But in practice, coding for complete isolation is trickier than it looks. In this system, getting it right involves careful design across both the sidecars and the TCS servers.
In our sidecars, we expect our cache hit ratio to be good enough that cache misses will be rare. Accordingly, on cache misses, we preemptively send duplicate requests: one to our chosen “primary” parent TCS, and one to a random secondary TCS. Sending duplicate requests to secondary TCSs helps, because:
- it allows the sidecar to evaluate the latency and failure profile of all parent TCSs, and periodically recompute the “primary” TCS (this system also gives Atlassian great insight into AWS cross-region latency profiles).
- the sidecar will seamlessly handle parent or network failures. It does not need to first detect a failure in order to react, as the “fallback” requests are already in flight.
- it pre-warms the L1 caches of other parent TCS, ensuring they are in a better position to handle shifts in traffic between AWS regions.
While the logic makes sense and it works pretty well for fail-fast scenarios, you also need to plan for when things fail-slow. Often that’s the most problematic failure mode for a system to handle. This is where proper isolation can be most critical. For us, to have proper isolation implies that a failure of any single parent TCS, AWS service, or entire AWS region must not impact our sidecar’s ability to operate against a different region.
Isolation in the TCS sidecar
To achieve isolation in the sidecar, we adopt a fully separate and asynchronous pattern from the perspective of the incoming request. So a cache miss for an incoming request will submit two fetch tasks into independent task queues and thread pools. These worker pools are entirely isolated for each parent TCS (even down to the HTTP connection pool instances), and the first task to return wins.
However, task queues and thread pools need to be guarded against fail-slow situations. If one parent TCS starts to return slowly, its fetch tasks will queue up and consume additional resources, starving out other tasks for that particular parent, and consuming more than its fair share of CPU resources. To defend against this, we implement:
- Load-shedding: When a task is no longer needed by the time we get around to starting it (if a concurrent task has already completed or the task TTL has expired), it’s dropped.
- Thread pool dynamic sizing: Our slower “secondary” TCSs have a tendency to consume more resources since they take much longer to respond and therefore have more outstanding requests. Left unchecked, this would consume more CPU resources than the faster-responding primary. To prevent this, each time we re-evaluate the “primary,” we also dynamically limit the total size of all thread pools available across all secondaries to have the same total thread count as allocated to the current “primary.” This leads to deliberately increased request queuing across all secondaries and creates substantial load-shedding as a result (assuming the primary is still functioning and will likely return fast).
Isolation in the TCS server
Region isolation also matters in the invalidation broadcast system for TCS servers (they don’t matter in our L1 web server caches or ingestion workers, which are inherently region specific).
TCS sidecars will subscribe to invalidation broadcast from at least two parent TCSs at all times. This means that on the server side, our invalidation broadcast system will always be making cross-region calls to publish invalidation messages. Given this, cross-region latency will significantly impact invalidation broadcast.
A cross-region outage (like an AWS SNS failure in one target region) must not delay or prevent invalidation broadcasts to other regions from that TCS server. To achieve isolation against this, the TCS server invalidation broadcast system replicates all invalidation broadcast data andprocessing threads into separate region-specific queues. Isolated worker threads then publish to each target region from just one of those queues. A slowdown or complete failure to send broadcasts into one target region will slow processing for that region only, and will have no impact on the publication of messages to other target-regions.
Scaling invalidation broadcast
Invalidation broadcast messages are triggered whenever a TCS record is updated in DynamoDB. A receiver of this message will trigger a background refresh of that key (if present in L1 cache), repeating refresh as necessary until an “expected version” condition is met.
As our TCS sidecar adoption footprint has increased, our invalidation broadcast system has grown from an internal component of the TCS web servers into a widespread broadcast mechanism that delivers huge numbers of SQS messages to the majority of Atlassian’s compute nodes.
The invalidation broadcast system was initially built with an SNS fanout pattern, where:
- each service deployment (a collection of compute nodes running same software) gets a unique SNS topic.
- each compute node within that deployment gets a unique SQS queue subscribed to the SNS topic.
- the TCS sidecars regularly register their SNS topics with at least two parent TCSs.
- each TCS will forward invalidation messages to every registered SNS topic, and the SNS topic will fan it out to the queues for each compute node, which the TCS sidecar will finally consume.
We have hundreds of unique services, comprising of many thousands of compute nodes. So, we end up needing a lot of SQS queues and even more individual SQS messages. SQS is good at scale generally but problems can arise.
What is particularly interesting about this scale is the amplification factor. A single write to a TCS will be amplified into thousands of unique SQS messages, one for every compute node running our TCS sidecar. A thousand writes into any TCS quickly amplifies into millions of unique SQS messages. We also run multiple independent and redundant TCSs, replicating events and our write pattern is not smooth, it can be very bursty at times. This quickly adds up in terms of cost, and ultimately, it produces dangerously uneven burst loads on AWS’s SQS infrastructure.
In our time running this invalidation system, we’ve had a few trials and errors. There were cost-related incidents due to us failing to clean up expired SQS queues and delivering redundant messages, and a few reliability-related incidents where our excessive burst loads resulted in heavy throttling to SQS infrastructure in our accounts.
After in-depth discussions with AWS, we decided to batch our invalidation broadcast events. We trade off immediate broadcast for an accumulation pattern. We accumulate invalidation messages in-memory for up to 1s before merging and publishing a single combined event. It’s a simple change but has made a huge impact on stabilizing our burst traffic, and it only incurs a ~500ms on average in additional invalidation delays. We haven’t had substantial throttling incidents since.
However, our SNS/SQS costs continued to grow with our number of unique SQS queues. Cost-related incidents remained a risk due to the complexity of managing SQS queue and SNS topic and subscription lifecycle across deployments of producing and consuming services. So, we’ve since moved away from SNS fanout to a bespoke implementation of a fanout pattern via S3, which we’re continuing to work on improving.
Least outstanding requests and defense against traffic blackholes
All software can be slow. It takes non-zero time to serve individual requests because we usually have work to do to create a response. The amount of time required to create a response may be radically different, depending on what that request is.
When incoming traffic causes uneven load patterns, a least outstanding requests (LOR) load balancing strategy in a stateless application is a good way to route requests to the “least loaded” backend node and prevent resource intensive computations occurring on one node from impacting the latency of unrelated requests on other nodes.
LOR is usually great but it comes with its own set of problems.
Consider the following situations: a node has a hardware failure and cannot initiate outbound network traffic; the local DNS resolver process crashes and does not restart; something goes wrong with a node and leads to an apparently healthy process that can accept incoming traffic but is actually not able to do any work.
We’ve seen all of these things happen, and with a LOR strategy, a node in these states can quickly become a traffic blackhole. It can swallow huge volumes of incoming traffic because it responds with simple error pages, very, very fast. With LOR, a single bad node can end up consuming pretty much all your traffic. Boom! Your shard has a complete outage, all caused by one bad node.
Having seen this happen in Atlassian, we figured that our TCS sidecar could help detect and mitigate this. We already recommend that our TCS sidecar is integrated into the local node health checks (if our sidecar is not running, the node cannot serve traffic, so we replace it). However, we never include external dependencies in our application health checks because temporary network faults do happen. It’s too risky to declare an entire fleet of nodes unhealthy and start replacing them just because a network or downstream service is temporarily glitchy.
We figured we could use the TCS sidecar health checks to improve this situation. Our TCS sidecars are actively aware of their comms status to their parent TCSs at all times and they are immune to service or AWS region failure. Our sidecars maintain node local caches, and are coded to discard those caches after a short period of comms loss from parent TCSs (without invalidations, cache contents can no longer be trusted). To validate the current network connectivity, we verify that specific keys exist in the sidecar in-memory cache. If those keys are gone and have not been re-loaded, then the node is clearly not healthy and should not serve traffic.
This solution has helped our major cloud products isolate and replace misbehaving compute nodes in their product shards before any traffic blackhole phenomenon can have significant impact.
You may be wondering why we didn’t use 5xx load balancer rules to help here. We generally limit our use of them because they’re too sensitive, tripping on other transient load-related errors. This can cause cascading failures as traffic shifts across overloaded systems.
CacheKey broadcasting
When Atlassian’s API gateway service first deployed the sidecar, we hit a new problem. That particular service runs a lot of nodes (they scale very wide), and the request rate to each individual sidecar was not high. This created unusually low cache hit ratios since subsequent requests for that tenant were unlikely to land on a node with the required key already cached.
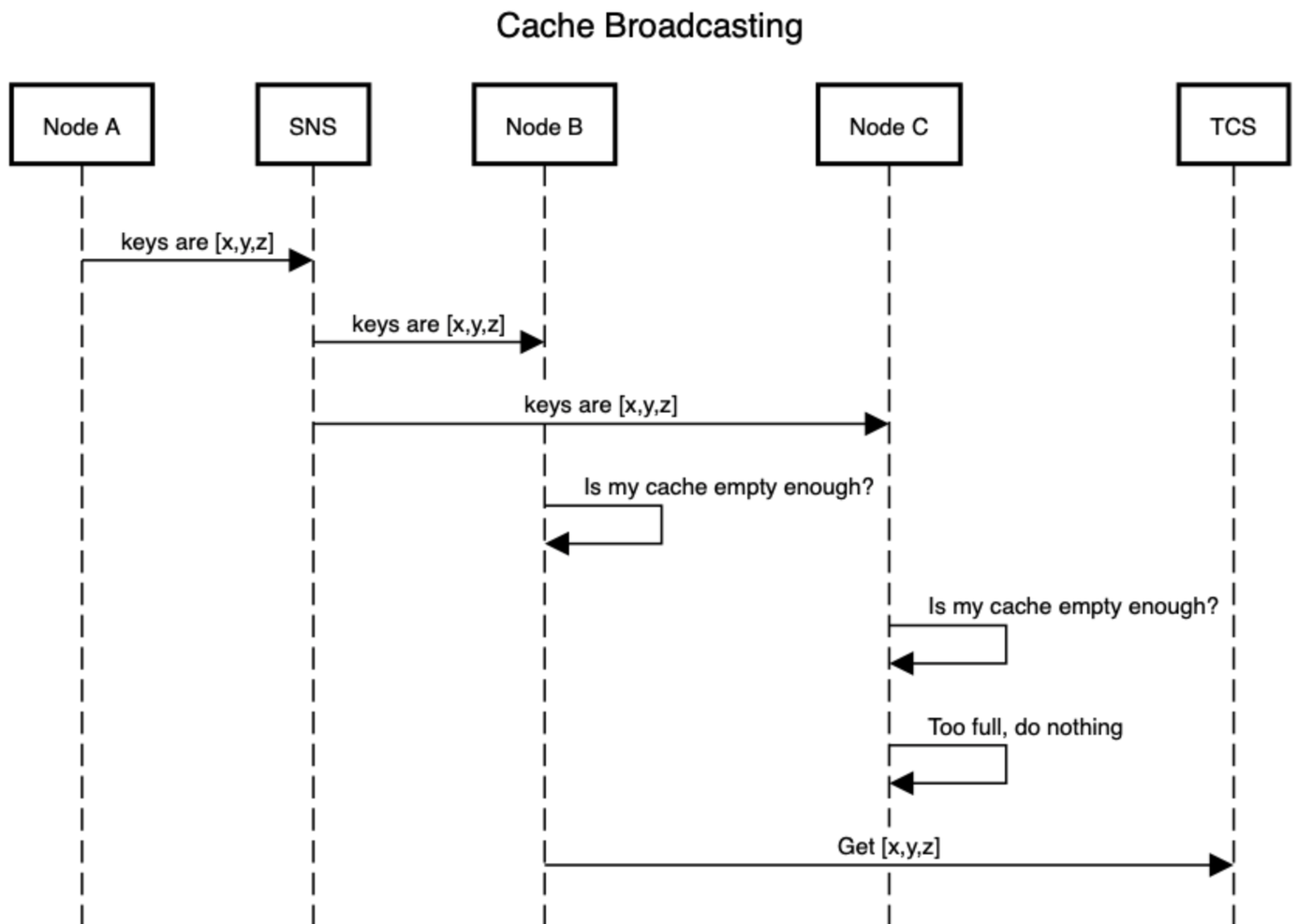
An obvious solution was a distributed L2 cache. However, there’s a bit of effort involved in that. There are also consistency issues (consistency is harder than it looks when you use invalidation streams plus a cache-on-cache pattern). Instead, we have our sidecars to talk to each other and inform others in the same service group of the contents of their own cache.
Our sidecars already have a SNS fanout mechanism per service deployment. TCS uses this to broadcast to the sidecars. We were able to easily extend this mechanism to allow the sidecars to broadcast to each other. They periodically announce the keyspace in their own caches to the other sidecars in the same service group. Recipients of this broadcast will, if their own caches have enough headroom, begin async pre-loading of those keys, thus pre-warming their own caches.
This has helped a lot with our client services that scale very wide because keys that are cached on one node will automatically pre-populate to all other nodes, instead of only populating after a cache miss on each node. It also helps with the cold-start scenario. New nodes start out with cold caches and will initially experience poor cache hit ratios. With this mechanism, new nodes are highly likely to have received and fully processed a CacheKey broadcast prior to serving any real traffic. They now start with entirely warm caches but the entire cache remains in-memory and node-local.
For now we’ve deliberately avoided broadcasting cache contents, for the same reasons we have not yet implemented a distributed L2 cache: It creates consistency challenges when combined with the invalidation system, and so far, has not been necessary.

Encrypted content
There are a number of use cases which require reading encrypted data from TCS. For example, we have credentials of various flavors which are encrypted within TCS. Atlassian’s encrypted data is handled through envelope encryption, backed by AWS KMS masterKeys. We wrap our calls to the AWS Encryption SDK with an internally developed library we call Cryptor. This is Atlassian’s solution for multi-region highly available encryption and decryption. With this Cryptor library, our encryption remains secure and fully controlled by IAM roles, but we also have aggressive datakey caching, background generation of encryption materials, and complete resilience to any AWS region failure. Cryptor was built on the same principles as the TCS sidecar: It proactively observes latency and failure rates of KMS regions when deciding where to send decryption requests, and can actively handle KMS or AWS region outages.
The basic solution to handling encrypted data in TCS is to fetch the data from our sidecar caches as normal and have the application decrypt it via Cryptor each time. This is fast enough to work, but has drawbacks. Our consuming application now needs to integrate both the TCS sidecar and Cryptor which increases their complexity. And having two calls in sequence makes it hard to cache the end result (you could cache the result of your decryption, but you won’t know when to invalidate it because invalidations are handled internally within the TCS sidecar). Plus, envelope encrypted payloads are often much larger than their decrypted contents and waste cache memory when cached in full.
The solution we found was to bring Cryptor into the TCS sidecar. So, we auto-decrypt at fetch time and cache the decrypted data. We allow our consumers to contribute pluggable AutoDecryptor classes that post-process TCS content and perform decryptions on behalf of the client IAM role prior to local cache insertion. AutoDecryptors also allow the sidecar to bypass unnecessary decryptions during content refreshes. This means they don’t decrypt again if a hash of the encrypted payload is found to be unchanged. With AutoDecryptors in place, our clients now incur near zero overhead from handling encrypted content from TCS.
gRPC
The TCS sidecar substantially reduced client code complexity by removing the need for fallback logic, but some services still saw occasional latency issues accessing sidecar REST APIs. This was often due to thread or connection constraints within their own application.
We saw this happen with Jira Issue Service (JIS), a microservice containing Jira Issue functionality, which we recently extracted from the monolithic core Jira application to achieve better latency and scale. JIS is a very high throughput service and aims for very low and predictable latencies, so is cautious and tends to profile all dependencies.
One such dependency is the TCS sidecar. When measuring the performance of its HTTP calls to the sidecar under heavy load, a stable P50 (50th percentile) of ~1ms and a fairly spiky P90 (90th percentile) was observed:


Connection re-establishment was suspected, but not proven. Rather than spend time debugging this under load, the team was interested in investigating gRPC, which is a newer, high-performance RPC protocol utilizing async HTTP2 channels and Google’s Protobuf serialization framework. gRPC has been designed from the ground up for high performance API calls and is designed for high concurrency.
With gRPC connections, the performance seen by Jira Issue Service at P50 and P90 dramatically improved:

Since then, gRPC has become the preferred client for traffic from the host service to our sidecar. Although, we still see a mix of traffic, depending on the tech stack of the client application, etc. In the future, we’d like to extend the gRPC model to cover the sidecar → TCS WebServer comms (our loader calls for cache misses) as other parts of the platform reach full support of gRPC traffic through our ALBs.
TCS anomaly detection
We had a partial outage in 2019, where several TCS deployments unexpectedly went live with brand new (as in suddenly and unexpectedly empty) DynamoDB tables. This was quickly traced back to a data migration in Atlassian’s PaaS and we were able to resolve it in under two hours for most affected customers.
In the meantime, as far as our systems and sidecars were concerned, everything was operational but the local data had been poisoned (since 404 is an entirely valid response code from TCS and those valid responses will be fully cached). In practice, this meant that our cloud products began to go progressively offline across some AWS regions, as the local and fastest TCS started responding with 404s for all tenant resources, and our running sidecars slowly adopted this poisoned data. New application nodes were the worst affected. Starting with empty caches, they would contain only poisoned data.
Thankfully, as a CQRS system, the TCS data stores are never our primary source of truth, and no actual data was lost. We didn’t immediately understand the cause or scope of the outage as sidecar caching meant that the outage wasn’t instantaneous. Our chosen path to recovery was to begin bulk re-ingestion of the data into the affected AWS region, and normal service was restored within a matter of hours. This rapidly began to restore normal service as each customer’s record was re-ingested.
Even with the speedy recovery, the fact that our systems had no defenses against poisoned content was unacceptable. We defend against almost everything else yet this still happened. Nothing prevented our TCS deployments from starting with entirely empty tables. Our sidecars blindly trusted the server responses, without applying any “bullshit factor” analysis to those responses. We’ve since improved on this.
TCS server side defense
We’ve now defended against this at the server end in two ways: We don’t allow our CQRS query system to start with empty tables (unless something else specifically says “right now, an empty table is expected and okay” – a rarely desired situation) and we now pay attention to 200 vs. 404 response code ratios.
In production, 200 vs. 404 response code ratios are usually very stable. If they begin to deviate, engineers should be alerted on this (we were not). If they begin to deviate as a result of an ongoing deployment, then that deployment should be automatically terminated and reverted (it was not).
We already deploy TCS using a canary deployment model. Traffic load is incrementally cutover to any new software stack while we have automatic checks looking for anomalies on that deployment, like 500 response code counts, error log events, ingestion failures, etc. If anomalies are detected, then we automatically terminate the rollout and immediately return all load to the previous stack. This has served us well, but we were not considering 200 vs. 404 response code ratios in that anomaly detection, an oversight we’ve now fixed.
Either of these solutions would have prevented this particular outage. But, we also wanted a solution where the sidecars can work it out for themselves.
TCS sidecar side defense
Our sidecars are now built to be suspicious of the responses they receive from parent TCS. We’ve approached this in two ways.
We now regularly fetch a couple of dummy “content check” keys, keys that will always exist and return fixed content, or should not exist and return 404. If either of these exist/not-exist keys deviates from the expected response, then something is clearly wrong with that parent TCS. It could be running with an empty table, or it could be serving a static HTML page to all requests.
Our sidecars are also now paying attention to the 200 vs. 404 response ratios across all parent TCSs. All TCSs should share the same content and should show similar response ratios for an equivalent set of requests. A TCS whose current ratio deviates from “the consensus” should be considered suspect. “Normal” ratios will vary wildly between different clients with different access patterns, so each sidecar has to work out what the current “normal” is for itself, before it can assess for deviations.
A sidecar that detects an abnormal parent TCS via either of these mechanisms will:
- immediately mark that parent TCS as “untrusted.” It will not be used as a primary or secondary to query.
- dump its caches. Locally cached content cannot be trusted if it could have been loaded from an “untrustworthy” TCS.
While all of this allows sidecars to detect and react to poisoned responses, it still doesn’t help an “untrusted” parent TCS regain its trusted status. How do you determine a parent is again trustworthy, unless you continue to evaluate its 200 vs. 404 response ratios, like every other TCS? We figured the only way was to keep sending it requests, but never use responses from “untrusted” TCSs. This was our first approach:
- When handling a cache miss, choose primary and secondary parent TCSs to query as normal but continue choosing additional secondary TCSs until at least 2 trusted TCSs are in the list.
- Ignore response contents from “untrusted” TCS unless all parents were “untrusted,” in which case, choose the latest version from the lot of them.
Unfortunately, when we implemented all of this, unexpected deviations in our client response code ratios happened:

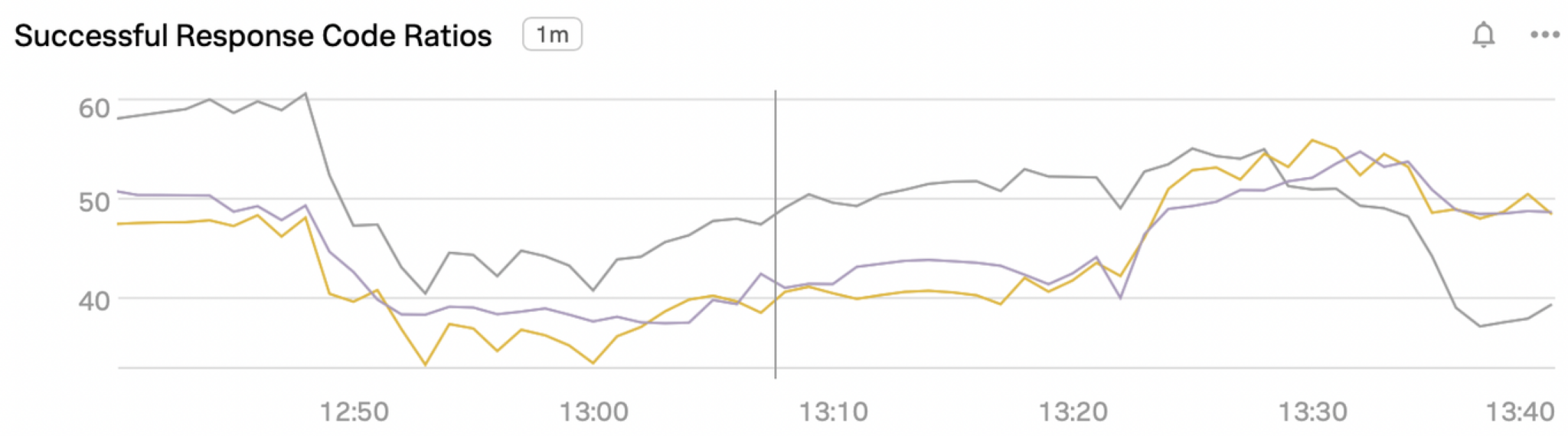
The response code ratios deviated between TCS parents much more than we expected. After some deeper analysis, we realized that the weighted-moving-average (WMA) algorithms we used elsewhere across the sidecars were not fit for this purpose since we were trying to compare responses for exact time windows. So, the first fix was to get our metric collection right.
Afterwards, our metrics stabilized but still remained off. We achieved stable values across the secondaries, but they were consistently tracking below the primary, as shown in the beginning of this graph:


The graph above also shows that we found and solved the problem. Our thread pool dynamic sizing code deliberately causes our secondaries to queue a greater proportion of requests, and when the request is for a valid item (a 200 response), the primary often responds fast enough that we end up load-shedding the secondary request, skipping it entirely. Thus, the secondaries see a lower rate of actual 200 responses. A 404 response will more often be a cache miss at the parent end too, and so will be slower to respond. Therefore, concurrent requests to secondaries for 404 responses are less likely to be load-shed.
Once we understood this, the solution was simple: Simulate successful response codes for load-shed requests. When discarding a queued request, assume that it would have responded as the successful one did. This stabilized our response code ratios and allowed us to start relying on them to assess “trust.”
Results
If you’re still reading, then obviously you have an interest in software at scale and like to see big numbers! The following statistics were compiled against our production systems across a week in late July 2022:
- Sidecars served up to 32 billion requests per day.
- Peak request rate (across all sidecars) was 586,308 requests per second.
- Sidecars were running concurrently across up to 10,800 compute nodes.
- Overall availability (measured as success vs. failure response codes) is higher than 99.9999% (yes, we’re exceeding six nines, thanks to our sidecars).
- Our client with the highest throughput saw median response times averaging around 11μs during peak times (they also go lower, into hundreds of nanoseconds territory).
- Sidecar cache hit ratios generally exceed 99.5% (although they do vary a lot, across different client usage patterns).
What’s next?
Innovation and development of TCS and its sidecars is continuing today. We’re working on replacing invalidation broadcast via SNS/SQS fanout with S3 polling. The team is also looking into extending into additional content types leading to scaling, sharding, and more scaling.