Over the last few years, Software Supply Chain Security has rapidly emerged as a critical aspect in the software development lifecycle, ensuring compliance, enhancing security measures, and building trust with customers. As Atlassian relies on a myriad of first and third-party sources/artifacts, the need to secure these components throughout the software development lifecycle has become paramount.
Atlassian is continuously evolving and enhancing our processes to uphold the trust and security of our products while meeting present and future regulatory requirements. In prior years, production deployment controls were limited to enforcing peer review and pre production testing via ‘Peer Review, Green Build’ (PRGB) for specific components which were in scope for regulatory controls related to SOX / SOC2.
The former method of monitoring and enforcing this specific deployment control relied heavily on the trust and security of every component within the Source, Build, and Deploy process. This trust was deemed necessary because each system had the ability, to effectively label any artifact passing through the system as ‘compliant’, and each following system would unquestionably trust the preceding one.

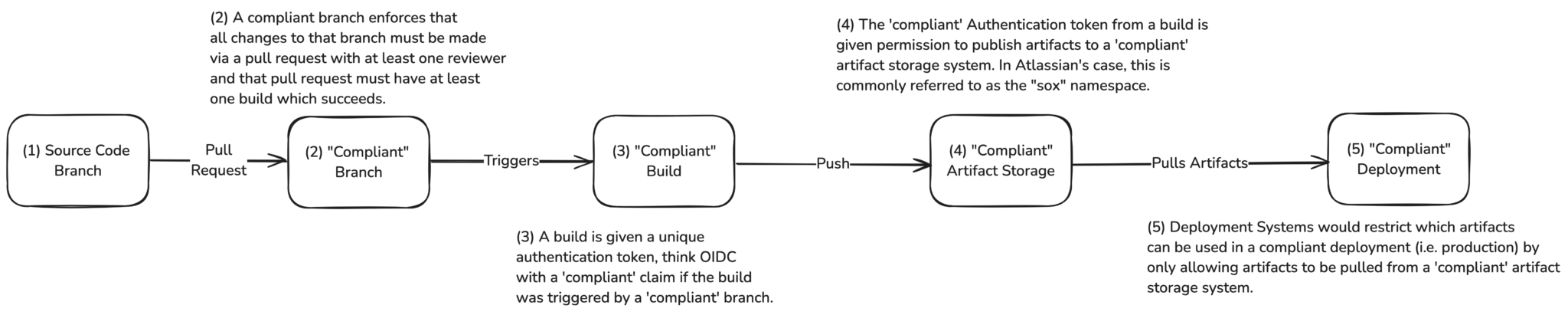
This type of system, where compliance controls are passed from one system to another, has inherent weakness that can potentially impact security and reliability:
- Implicit Delegated Trust: This delegated trust system creates an implicit chain where each subsequent system relies on the previous one to pass on the “compliant” state. This chain can introduce vulnerabilities if any system in the sequence fails to enforce controls effectively.
- Complexity and Lack of Transparency: Delegated trust systems can be complex and lack transparency. It may be challenging to trace back compliance issues to their source, leading to difficulties in identifying and resolving security breaches or non-compliance.
- Increased Risk of Errors: With multiple systems involved in passing on compliance controls, there is an increased risk of errors or misconfigurations at each handover point. These errors can accumulate and lead to significant security gaps.
- Limited Accountability: Delegated trust systems may lack clear accountability mechanisms. When issues arise, it can be challenging to determine which system or entity is ultimately responsible for the compliance failure.
- Scalability Challenges: As the systems and number of controls grow, maintaining a delegated trust model becomes increasingly complex. Scaling the system while ensuring consistent enforcement of compliance controls across all components can be a significant challenge.

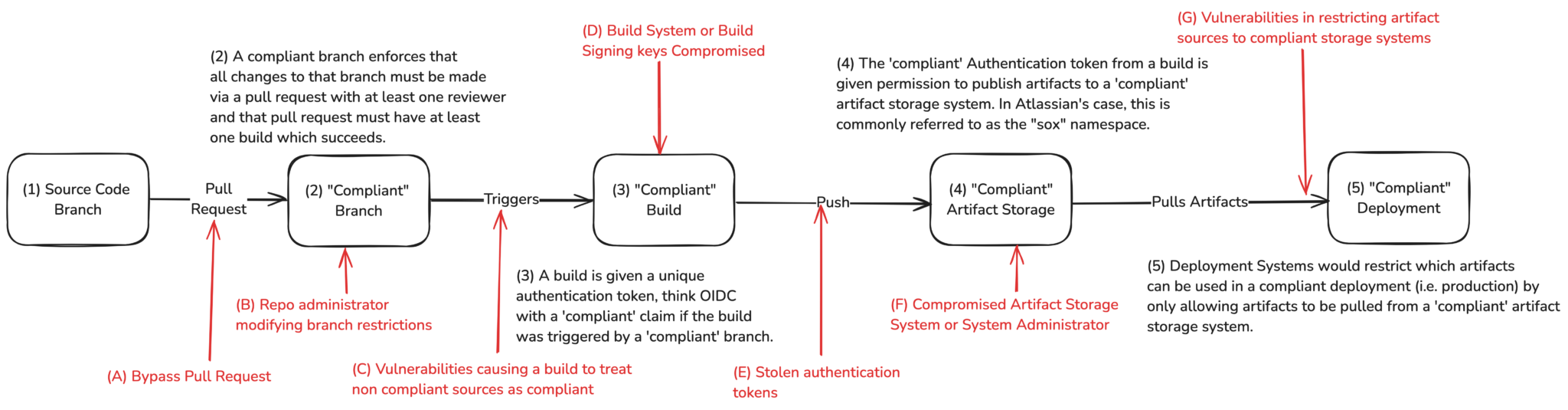
As seen in Figure 2, the compromise of any step in the process is carried forward through all remaining steps in the chain.
Over the last couple of years the Pre Deployment Verification team has been working on a significant change to this process in order to support direct source and build provenance verification for artifacts at deployment time. This work also aligns with industry trends such as SLSA (Supply Chain Levels for Software Artifacts), Binary Authorization, Sigstore, and more.
This shift has significantly improved the security and trust surrounding how we implement and validate artifact controls. The task presented many challenges due to the diverse array of source, build, artifact storage, and deployment methods in use at Atlassian.
Three primary goals were initially defined;
- Standardize the structure of source, build and artifact metadata
- Make the metadata readily available in a centralized location
- Centralize policy decision making & standardize enforcement across all deployment mechanisms
With thousands of engineers and over 10,000 repositories and builds combined at Atlassian, a significant amount of attention was placed on minimizing any adoption requirements and not introducing any developer friction. This prevented what would have been been a 20,000+ hour negative impact on developer productivity.
Standardized Artifact Metadata
The Artifact Metadata Store (Metadata-API) was developed using the Grafeas project as inspiration and foundational data model to standardize and centralize the storage of all artifact metadata generated by the numerous build, storage, and deployment systems. This component facilitates the inclusion of signed attestations linked to individual artifacts, and allows users and systems to execute diverse operations like querying and filtering to access necessary data. As a result, a uniform data structure was established and processes put in place to ingest and transform the data to that structure across various platforms including Bitbucket Server, Bitbucket Cloud for source tracking, Bamboo, Bitbucket Pipelines for builds, and Artifactory, S3, and other internal artifact storage systems for artifact storage.
Grafeas provides a standard structure for many kinds of metadata, we focussed on Builds, Deployments and Attestations. Attestations are the most flexible and allow defining your own structures and claims. Many public systems have been recently standardizing on in-toto format attestations, however as long as the contracts between the producers and consumers of the attestations are well defined the format of the attestation is not critical.

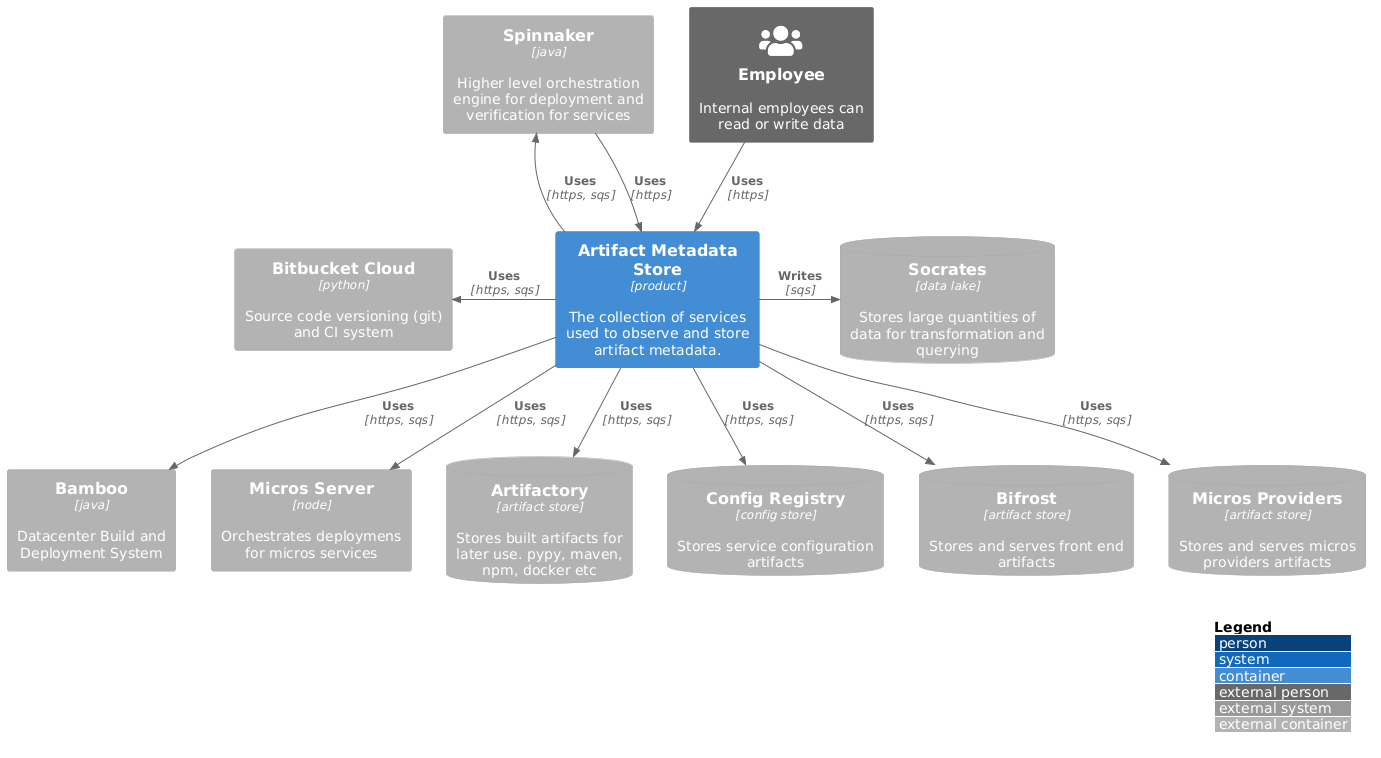
Build Data Collection
Build provenance is gathered via integrations with the build systems, transformed into the standard BUILD metadata kind and stored in the Metadata API. The core requirements for the build provenance are;
- The ID and reference to the build
- The list of commands run in the build
- The source provenance used to trigger the build
- The artifacts produced by the build
There are two approved build systems that are integrated for build data collection, Bitbucket Pipelines and Bamboo Server.
Bitbucket Pipelines
Bitbucket Pipelines build data is gathered via a connect plugin which receives hooks from build events. When a build stage completes the hook is received and immediately written to a queue. An internal worker process receives events from this queue and processes the event, collects any additional context by making requests to Bitbucket Cloud and Bitbucket Pipelines, transforms the data into the correct structure and writes it to the Metadata API.
Bamboo Server
The Bamboo Server integration is built into a server plugin which is triggered at the end of any bamboo build. The server plugin collects any relevant data from the build and then writes it to Streamhub (Atlassian’s event bus – designed to allow service to service, decoupled communication through events) where it it later received by the metadata collector service which transforms the data into the correct structure and writes it to the Metadata API.
Artifacts & Attestations
The Artifact Metadata Store uses attestations to store observations made about artifacts as they progress through the build, storage and deployment process. For instance, when an artifact is produced an attestation is written to record which build produced the artifact and whether the build was marked as ‘compliant’.
Attestations are also used within the system to store other supporting evidence which may be required to successfully link an artifact back to its sources. An example of this is that when a build attempts to publish an artifact to Artifactory, it will request an ephemeral authentication token in order to make that request. The ephemeral token and the build identity which requested it are recorded in an attestation so they can be used to link any artifacts published by that token back to their build.

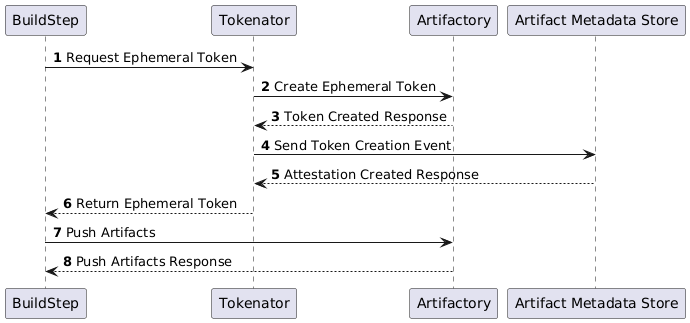
Artifact Attestations
There are a handful of Artifact Storage Systems which have been onboarded to the Artifact Metadata Store, these include;
- Artifactory
- Config Registry
- Bifrost (an internal Atlassian platform service which handles the upload, storage and deployment of all web resources)
- Micros Providers (a component of Micros, Atlassian’s internal platform as a service, which handles serverless resource provisioning and deployments such as Lambda, Step Functions, etc)
When an artifact is published to any of the onboarded systems an event is written to a queue with the artifact information and the identity of the build (or system) publishing the artifact. A metadata collector service receives the event, parses its contents and then makes any additional requests to the Metadata API in order to clearly identify the build, source provenance and whether they were PRGB ‘compliant’. It then creates the attestation and links the artifact to the build which produced it.

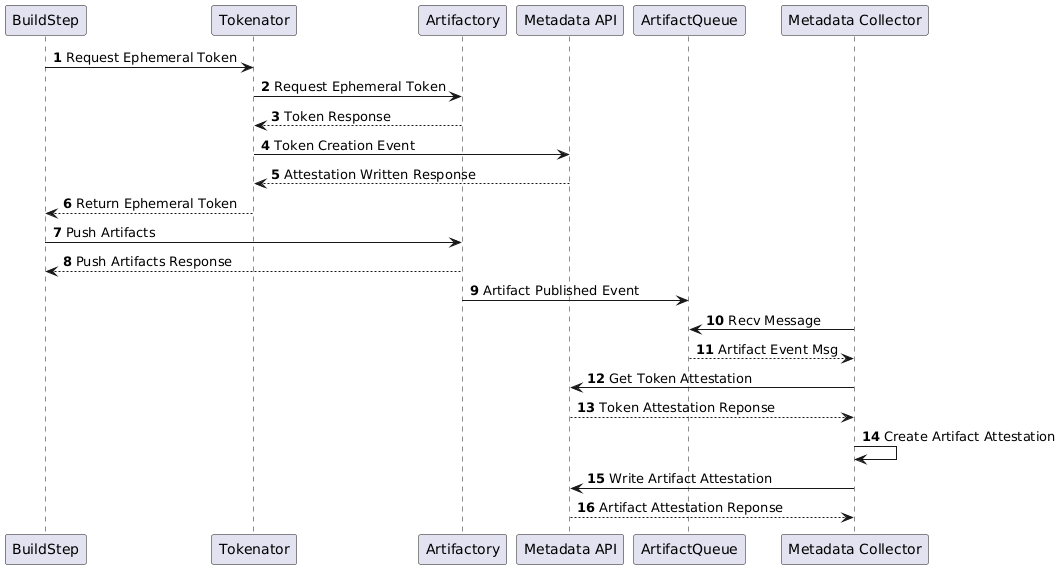
Artifactory is a unique case due to its authentication and permissions management requirements resulting in the ephemeral token creation step. The other artifact stores are far simpler as they’re able to include the identity of the build or principal performing the upload directly in the event. For example, creating artifact attestations for Config-Registry (Config-Registry is an internal Atlassian platform service which handles the upload, storage and tagging of configuration blobs.) can be seen in Figure 6 below. This is also the same sequence used for the other storage system integrations.

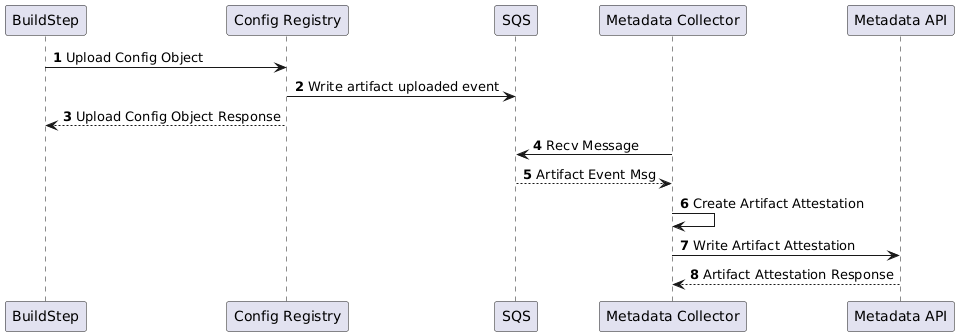
The decision to use an observation based approach to linking artifacts back to their build and source provenance was largely driven by the need to minimize developer friction, not requiring an onboarding process or changes to build configuration. There are still pitfalls with this approach (such as leaking build tokens) and it is an ongoing effort to continue closing those gaps.
Centralized Artifact Metadata
The second objective was that all of the Artifact Metadata must be stored in such a way that it was simple to query and filter across different kinds of data regardless of the build, storage or deployment system. This was necessary in order to streamline the ability for consumers to quickly identify and query artifact information or build provenance without needing to integrate with the multitude of different systems and APIs. Next lets review how all that data is accessed and how it ties together.
Metadata API Operations
Metadata API supports all of the expected operations over http. Direct queries and filters can be made against the Metadata-API to get the fetch data based on attributes such as the project name, data kind, artifact URI or timestamps.
There are some limitations to the API. For instance, sorting and ordering query results, such as by creation time, currently require paginating through all results and then doing additional filtering on the client side, which is quite cumbersome. In order to mitigate this, all of the data is also synchronized to Socrates (Atlassian’s data lake) in order to support additional analysis and aggregation (such as identifying all unique Artifacts published during a time window; the number of builds and sources contributing to a deployment; or the artifacts which were produced by a specific build system; etc) via platforms such as Databricks.
Conceptual Model
Understanding how the data fits together is very important in order to draw insights from or extend the data. The conceptual models (Figure 7) provides an basic overview of how the data is connected.

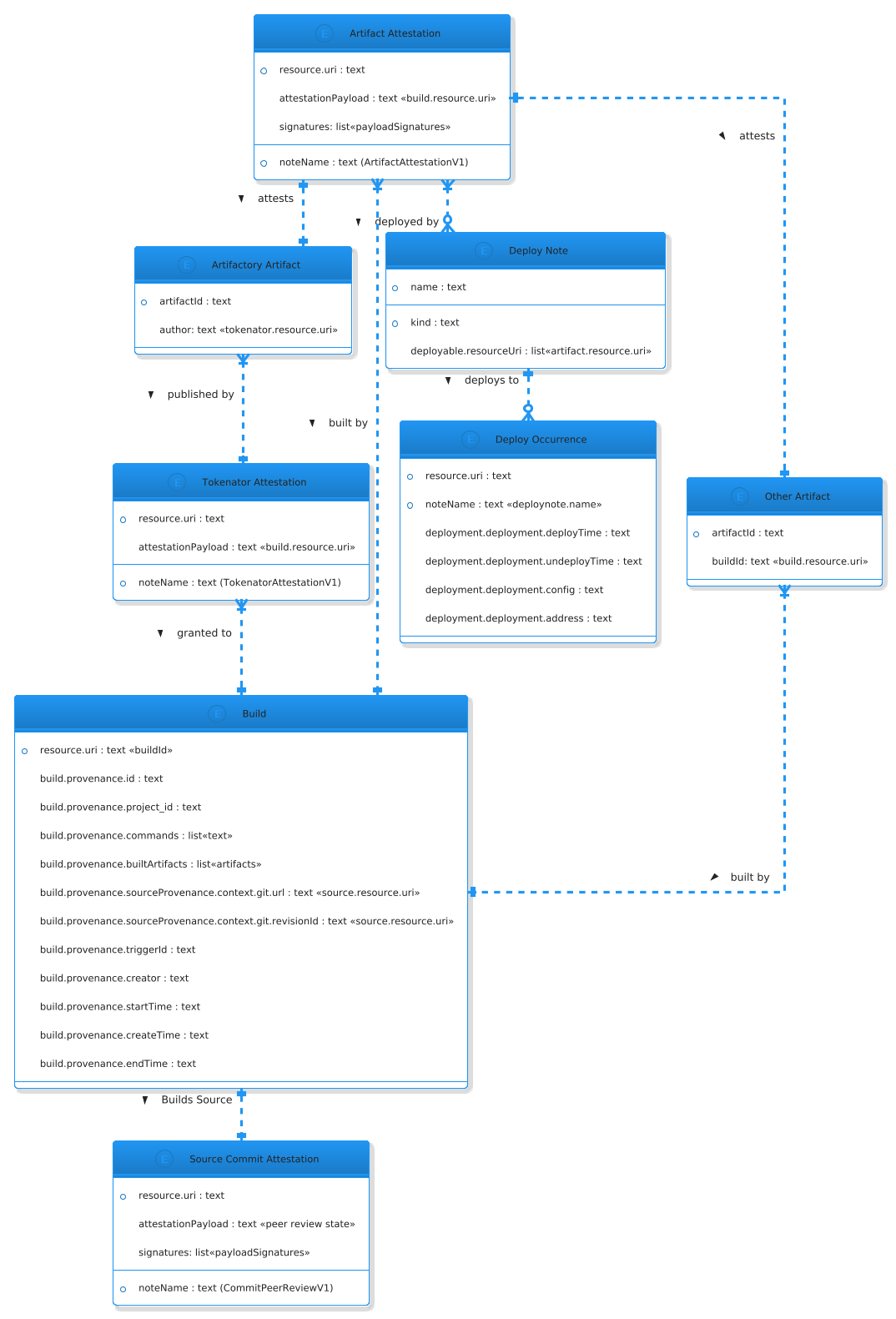
Centralized Policy Decision Making
Metadata Gatekeeper is a crucial component in Atlassian’s deployment process, acting as the PDP (Policy Decision Point; a component which makes policy decisions. In the context of this post, the Metadata Gatekeeper service is the single centralized PDP) for all deployments. Policy decisions are made based on the request sent by a deployment mechanism acting as the PEP (Policy Enforcement Point; a component which enforces policy decisions from a PDP. When discussing deployment gating, all deployment mechanisms are considered PEPs). The PEP is responsible for enforcing the decisions of metadata-gatekeeper in order to allow or deny a deployment.
The Open Policy Agent (OPA) is central to defining and evaluating deployment gating policies, this is very similar to an OPA based Kubernetes admission controller, applied across many different deployment mechanisms.
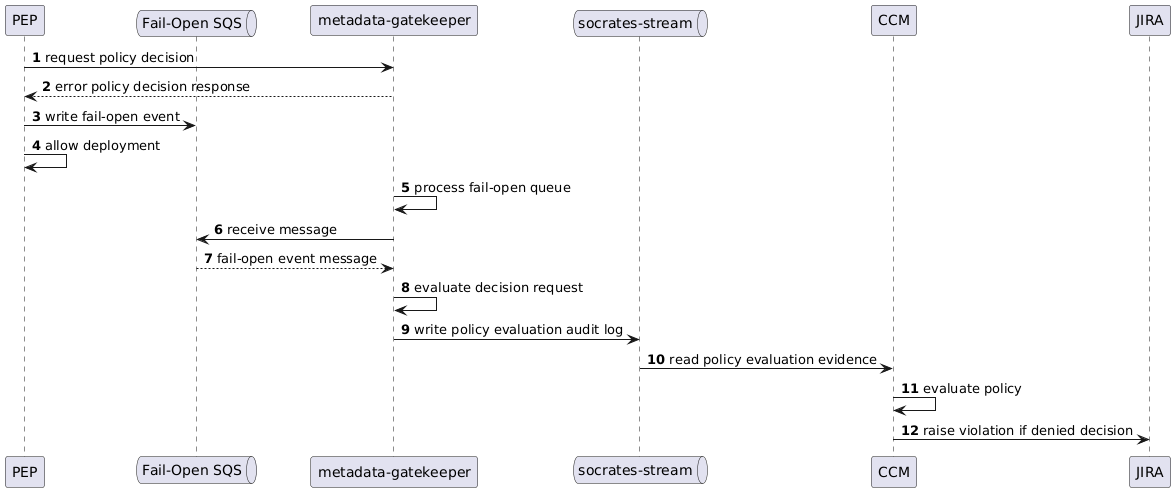
As this component is on the critical path for deployments, further consideration was made to ensure minimal disruption to deployments during an incident and to support circular dependencies and platform recovery. These decisions result in PEPs implementing their integrations as a fail-open design, with fallback to asynchronous decision making. If there is an error receiving a policy decision (that is neither a clear Allow or Deny response is able to be obtained), the PEP will allow the deployment to proceed while writing the decision request to AWS SQS to be re-evaluated once the problem has been resolved. During re-evaluation, if a decision was found that should have been denied, a violation will be raised (for the offending service) and recorded in the deployment gating audit log.

A policy decision request must always include the target environment for the deployment and the set of artifacts to have the controls applied to. This allows metadata-gatekeeper to aggregate the correct deployment control policies into a policy set and apply it to all artifacts in the request for the deployment to that target environment.
The data that metadata-gatekeeper relies on to make policy decisions is pulled from multiple sources depending on the policy. The primary provenance information is stored in the Metadata API though and it is required for every policy decision. A policy decision is determined based on the evidence available in the attestations associated with the artifacts being evaluated. For example, metadata-gatekeeper verifies that artifact attestations contain valid signatures ensuring the integrity of the evidence in the attestation. The most relevant check implemented is ensuring that PRGB is met for production deployments. This is simple as the ‘PRGB compliance’ state of an artifact is encoded into the artifact attestation’s payload and only requires the single piece of evidence from the metadata store.
As a centralized PDP, metadata-gatekeeper is designed to be called from all deployment mechanisms (PEP) involved in the deployment process. This provides a significant improvement in Atlassian’s ability to scale deployment controls by ensuring any changes to existing policies or the introduction of new policies can be made in a single component and applied to all deployments. The previous model required each deployment mechanism to implement the controls themselves. This has already been realized through the new controls implemented as part of FedRAMP Moderate. An example of this is shown in Figure 9, as Metadata Gatekeeper enforces SAST (Static Application Security Testing) is integrated with any sources used to produce artifacts being deployed into the FedRAMP moderate perimeter.


Using this process for making deployment policy decisions based on facts and evidence produced through the CICD lifecycle of an artifact, Atlassian is able to begin removing dependencies in the implicit chain of trust previously identified. Even if only considering the introduction of PRGB enforcement via metadata-gatekeeper, the implicit trust on a “Compliant” Artifact Storage system has been removed.


As deployment mechanisms continue completing their integration with Metadata Gatekeeper, Atlassian will quickly reach a state where there are no more Artifact Storage systems with the ability to delegate ‘compliance’ state on an artifact. In the future this will be extended to remove the ability for builds or branches to delegate trust and to rely solely on source and build provenance observation.
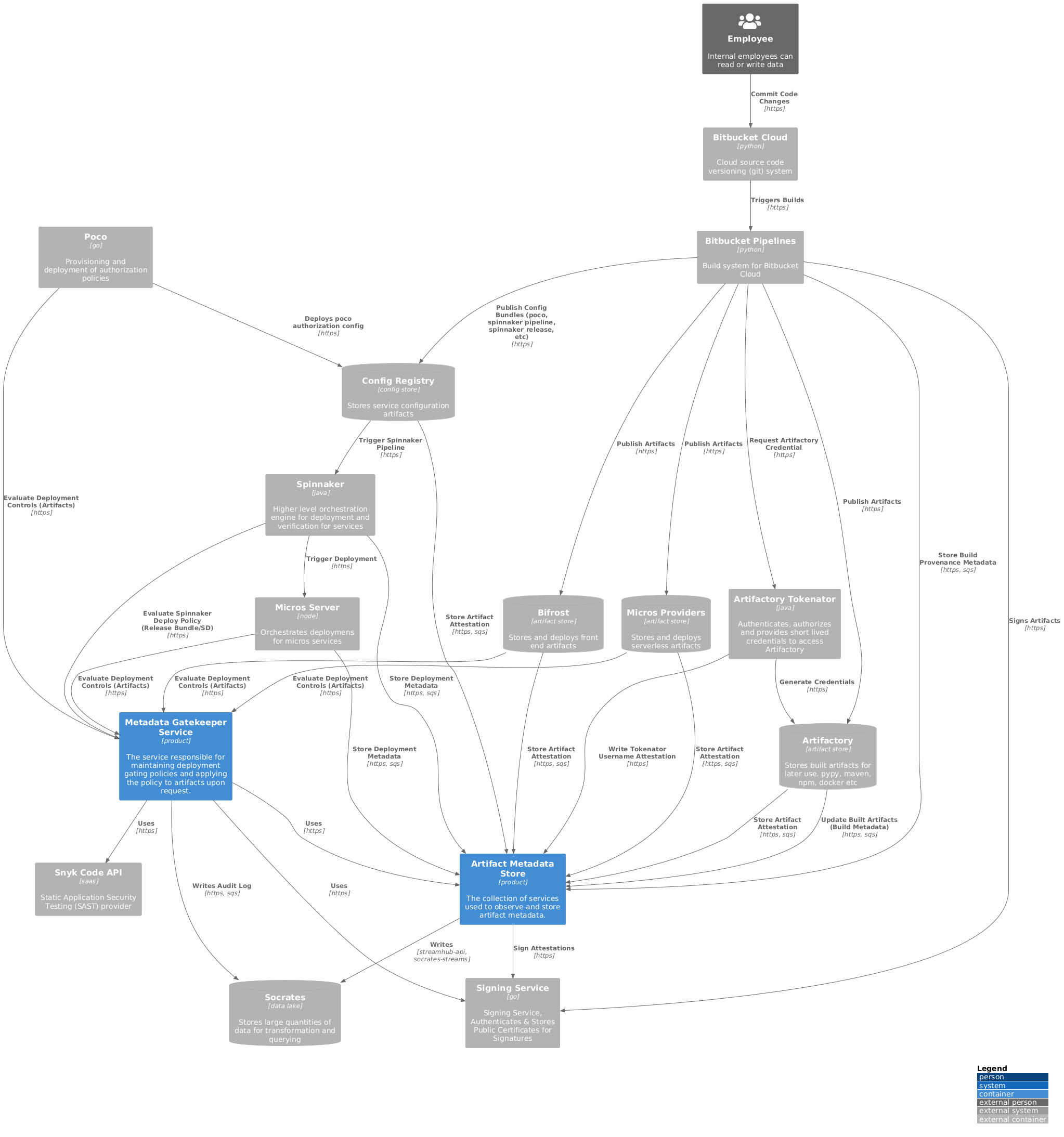
Finally, here’s all the components and how they interact with the Deployment Metadata Platform (Artifact Metadata Store and the Metadata Gatekeeper Service). As of writing this, the Artifact Metadata Store is storing roughly 2 million occurrences of CI/CD metadata or attestations and Metadata Gatekeeper is responding to millions of deployment gating policy control decision requests on any given day.