

The data platform team at Atlassian re-built their data platform into an opinionated platform; one that saw the introduction of a novel deployment capability. The new capability takes inspiration from Kubernetes and Micros (Atlassian’s internal Platform-as-a-Service) but adjusted to the data domain. This new capability provides:
- A declarative metadata driven, self-serve, data pipeline provisioning system;
- An extensible abstraction over pipeline execution capabilities; and
- A single governed deployment experience.
To build this capability we leveraged the flexibility of the Kubernetes framework.
At Atlassian, our internal data lake is regularly used by more than half of the company; grows in excess of 85 terabytes a day; and it powers both internal and customer facing experiences. Not bad for something that started as a ShipIt (a regular company wide innovation day) project .
Part of the success of the first generation lake is due to the fact that it is an open and un-opinionated platform. Users of the platform are free to decide: what tooling they build (or install) and use; how they model their data; what metadata they capture and expose; and how they run and support their data pipelines. Being open and un-opinionated makes it easy for our users to onboard. The only barrier to entry is learning the available capabilities. But it also puts our users at the centre of everything:
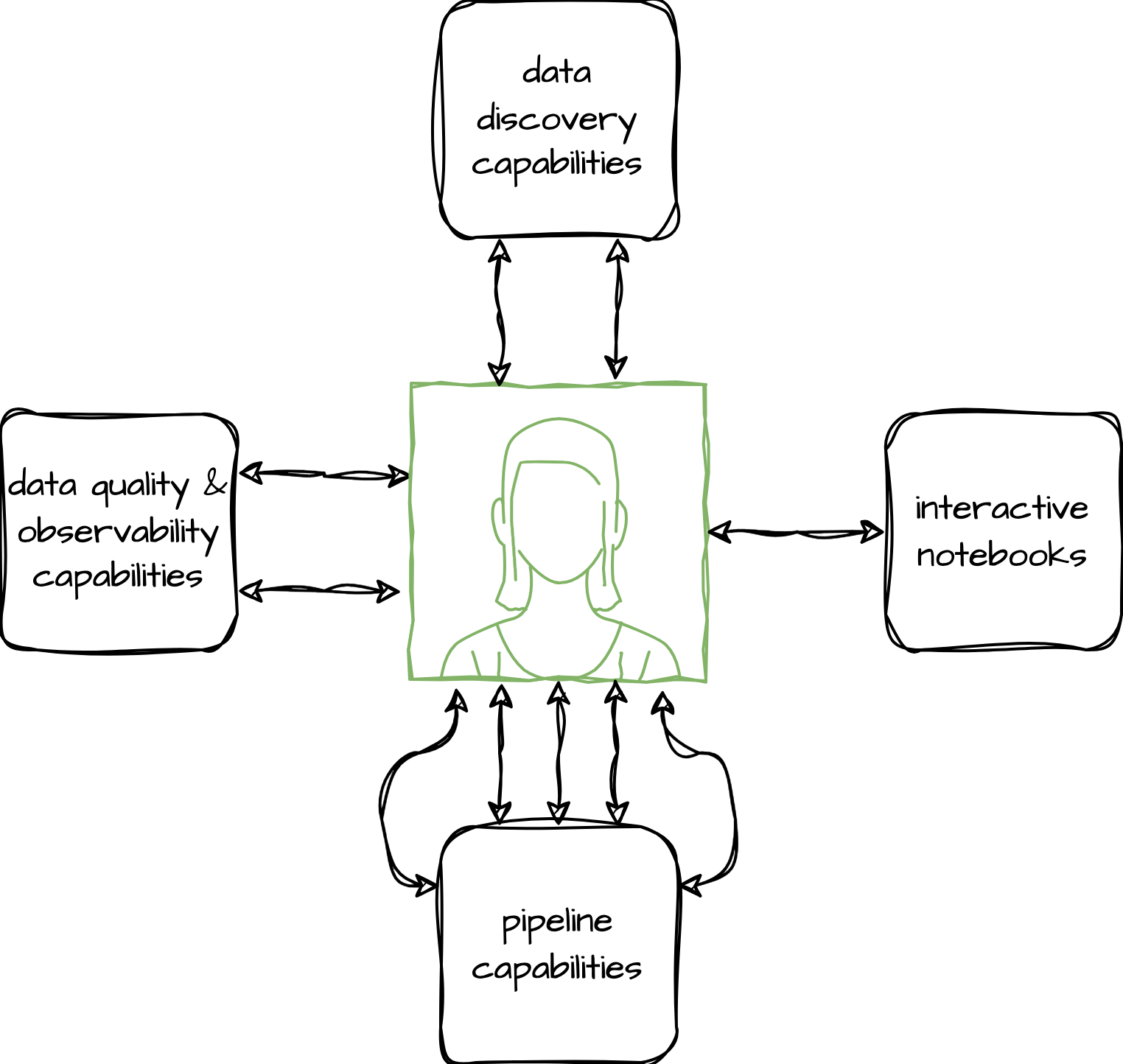
The users of the platform become responsible for:
- knowing what capabilities are available;
- how to make them work and, more importantly, work together;
- all operational and consumer support of the data they produce; and
- capturing and sharing relevant metadata about their data.
The open and un-opinionated nature of the platform has also resulted in an explosion of data transformation, data quality & observability, and data discovery capabilities. With some teams building their own, while others prefer off-the-shelf tooling that best matches their preferred way of working, and yet others taking a hybrid approach.
Similarly, the un-opinionated nature has led to a lack of shared standards, which means that data comes with varying degrees of documentation, metadata, lineage, quality checks, and observability.
As a result users of the platform:
- struggle to find relevant data;
- often have low trust in the data they can find; and
- have a disconnected user experience deploying and managing their own data.
While platform teams struggle to support the platform and its varied ecosystems of capabilities.
None of this is unique to Atlassian. Organisations setting up their own lakes all struggle with the technical challenges of making things work. They want their new lakes to be successful so optimise for adoption. But as adoption grows and data regulations are tightened, the realisation quickly sets in that something has to change; more governance and standardisation are needed.
The common evolutionary path of data platforms is to standardise on a small set of capabilities (one or two each to cover the capability boxes in the above diagram). Then select those capabilities that have some level of point-to-point integration whilst meeting current governance needs. At first glance such an approach makes sense; platform teams have a much smaller support burden, while users have some semblance of unity/integration. But governance requirements change and data tooling evolves quickly, resulting in point-to-point integrations that are hard to maintain, and generally have diminishing business value.
Rather than focus on a user experience constructed from individual capabilities, instead the experience should be modelled after the natural workflow of users of the platform; that is, start with users’ process not platform capabilities. This is also where it gets more complicated, as can be seen in the next diagram.
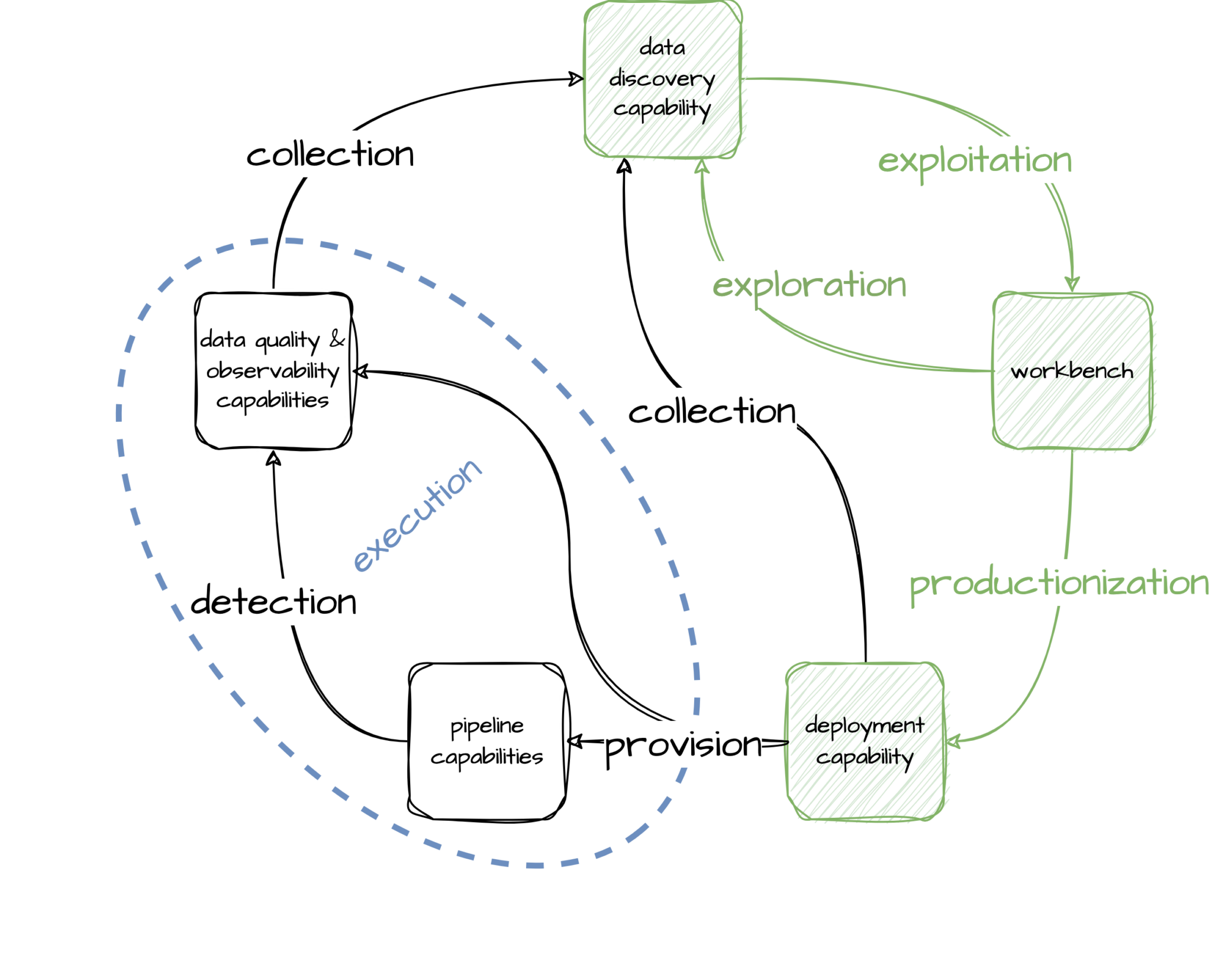
Users typically iterate between the data discovery capability and a workbench. The data discovery capability should be a one-stop-shop where users are able to explore all data across all of a company’s data platforms to find out what it means and where it comes from (lineage), and get a measure of trust in the data (quality and reliability).
Similarly the workbench should be an environment where users can connect to all data (subject to permissions) for them to exploit the data and build out new transformation logic (with tooling already setup for them) that solves the problem at hand.
Once they are happy with their transformation logic, users shouldn’t have to deal with a variety of execution capabilities (pipeline and/or data quality & observability). Instead they should be able to simply deploy all their logic in one go; be that SQL, Python, Kotlin, etc. for data engineering, machine learning, or analytics purposes. This suggests that there should be a deployment capability in place that provisions all resources for pipeline execution and data quality & observability.
Metadata about anything provisioned should be collected and fed back into the data discovery capability. The data quality and observability outputs (detection) of all provisioned pipelines should similarly be collected and fed into the data discovery capabilities.
What the above diagram shows is that there are circular dependencies between the various capabilities. This is something that is hard to solve with point-to-point solutions of available capabilities. Next we will introduce the deployment capability we’ve developed that addresses these pain points by providing:
- a gate to production (so controls can be applied);
- a single consistent interface for its users to self-serve deployments;
- an extensible mechanism for supporting new execution capabilities; and
- a declarative provisioning framework.
The deployment capability hides the complexity of provisioning data pipelines behind a declarative interface. Using a declarative interface means users don’t have to learn how to use different execution capabilities directly, or even know how to write (platform provisioning) code. Instead they declare what they want their pipelines to do and what it should produce; all through configuration metadata. In other words, it decouples the user from the actual pipeline execution capabilities. This also means that it is easier for platform teams to upgrade/migrate those execution capabilities.
The purpose of the deployment capability is to provision data pipelines; as such, using a declarative approach means capturing lots of metadata about both pipelines and their outputs. For example, provisioning pipeline jobs needs information about the type of job and its inputs. Outputs (such as tables) need to be pre-created to ensure appropriate permissions can be set. And so on. The upside is that all this metadata has immense value for data discovery purposes.
Declaring metadata upfront, in combination with a capability that provisions what is declared, has a further benefit. It removes the need to inspect (or scrape) the platform in order to understand the state of the platform. While post-deployment inspection may at first seem like a useful mechanism for collecting metadata about a platform; it does come with risks. For example, it is not possible to detect breaking changes until after they have been deployed.
Now that we know that rich metadata should be captured upfront, the next step is to realise that the metadata makes up a large and complex graph of relationships. For example:
- Pipelines consist of one or more steps, where each step typically equates to a job that executes;
- Pipelines can depend on (upstream) pipelines;
- Pipelines produce outputs (e.g. tables);
- Tables are part of a database, and they consist of columns;
- Columns can depend on other columns (lineage);
- Policies apply to tables; and
- Versioning relationships have to be maintained.
In addition to all of these relationships, we also introduce one further one: data products. Data products consist of the tables (and by extension their database) and pipelines that together make it Data as a Product. Data products allow us to introduce a strong sense of ownership of data coupled with a contract on the data within the product.
Putting all of this together, the following model starts to emerge:
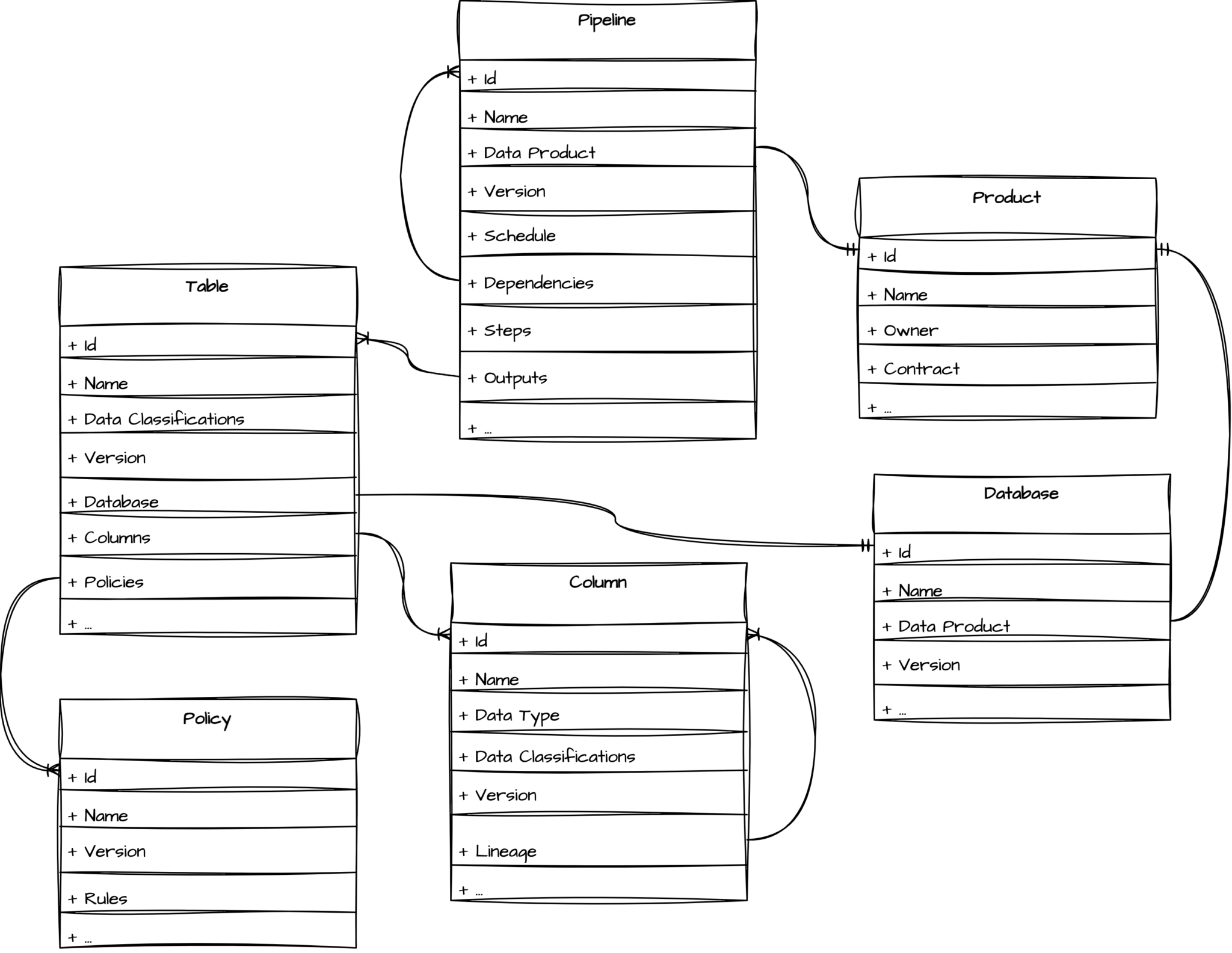
Each of the entities in the above model has its own schema (with the exception of Column which is a nested type in Table). Each schema contains all metadata needed to provision such an entity and any additional metadata that is useful in a discovery context.
In their source code repository, and next to their transformation logic, users create configuration files containing metadata about the entities needed for their logic to run in the lake. The repository provides an audit trail for all changes to the configuration files, as well as an approvals process via pull requests (PRs). Once a PR is approved, as part of CI/CD, the configuration files are submitted to the deployment capability. Which then takes the transformation logic and provisions the declared entities around it.
The above model only covers tables and databases. Naturally it can easily be extended beyond data lakes to streaming platforms – we’ve omitted this for brevity and clarity.
The Steps in the pipeline map to jobs running in the lake. Here we adopt a leaky abstraction. Users have control over which pipeline execution capability they want to use but without having to learn all the implementation details of those execution capabilities, while the engineers building and maintaining the platform don’t have to come up with a universal pipeline configuration language. Take for example a pipeline with a dbt transformation; its configuration file looks like the following.
id: pipeline/91b21ee3-57be-4380-ac95-a809d216bd49
name: example_pipeline
product: product/30c151b9-d841-4bff-b27a-06ac980fcbe6
version: 1
schedule:
cron: 0 0 * * *
dependencies:
- pipeline/73a7ba9d-f0f5-40e4-93d6-cc62014902de
- pipeline/c464915c-ee5f-4118-b1ec-c5db4f63da71
steps:
- name: simple_transformation
transformation:
dbt:
project: mySimpleDbtProject
outputs:
- table/1c698484-4988-49b7-8f2c-83ac4f93350d
Note the use of the dbt keyword (line 13). Different execution capabilities (or different versions of given capability) have different keywords. This provides an extensible mechanism to add additional execution capabilities simply by introducing new keywords. It also makes it easy to identify pipelines impacted by a change to a given execution capability.
We will now delve a little deeper into the implementation of the deployment capability. The first thing to note is that the capability is the only way for users to make changes to production pipelines. It is imperative that it validates all metadata it receives, so validation is the first action the capability undertakes.
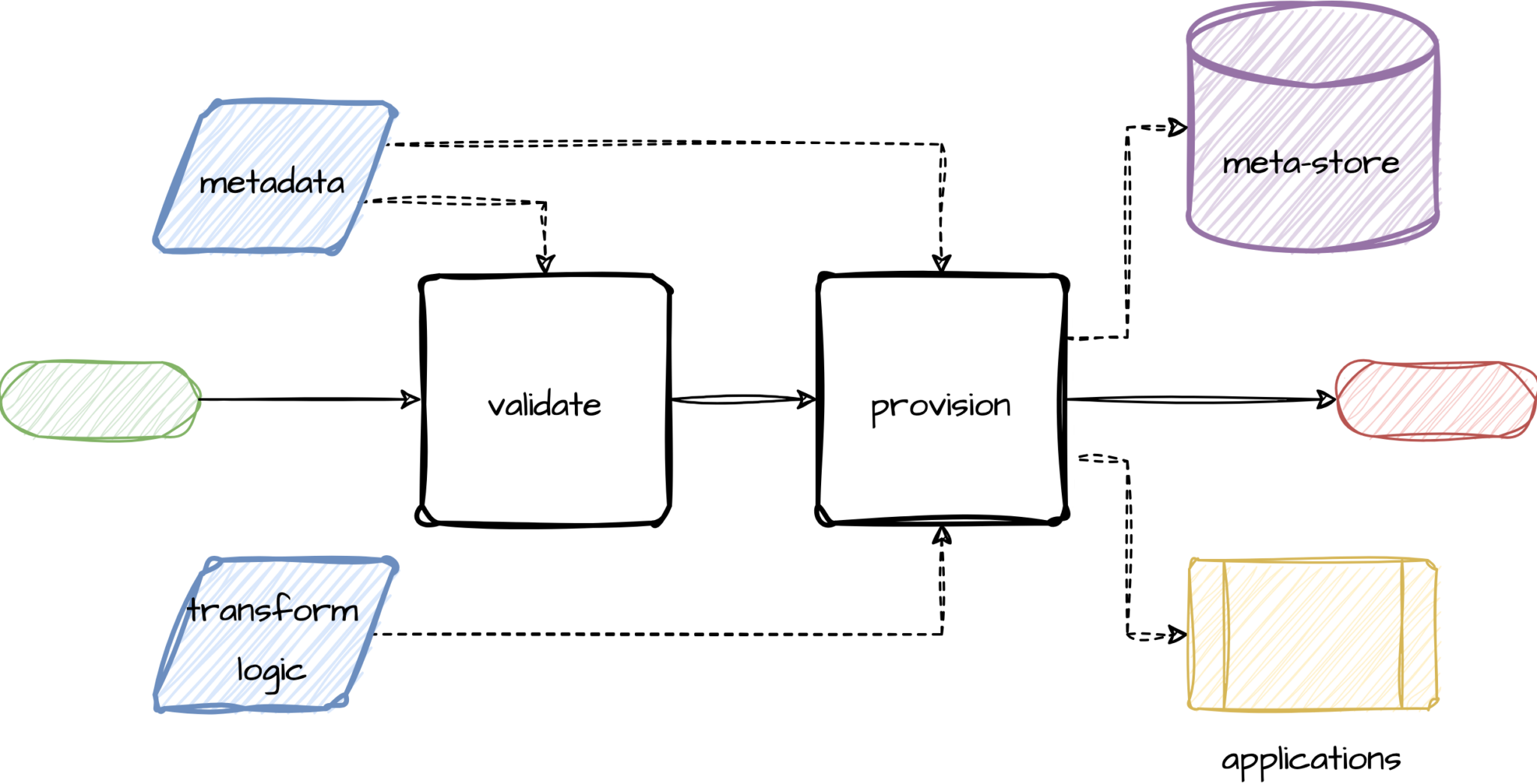
Validation ensures not only the health of the platform and data in the lake, but it also adds a gate for any additional requirements (e.g. naming conventions, ownership information, quality standards, etc.).
If the metadata passes validation, the the next step is for the deployment capability to provision what is declared in the metadata. For this the provisioning logic interfaces with the applications that make up the lake. The applications include off the shelf products such as AWS, dbt, Databricks, Anomalo, Airflow, Fivetran, Immuta, etc., as well as in-house developed applications. Once provisioned, the metadata is added to the metadata store for discovery purposes.
The capability is built around Kubernetes. The entry point to the capability is a gateway that performs validation based on the bundle of configuration files (all files that make up the data product) submitted via CI/CD. It then wraps each configuration file into an annotated Kubernetes manifest before handing over to Kubernetes.

Kubernetes itself is setup with custom admission controllers and operators for each entity in the above model. Upon receipt of an entity’s manifest the admission controllers perform additional validation; this may include calling out to the applications associated with the controller.
If everything validates then the operator for an entity will provision resources for the entity according to what’s in the configuration files, using the associated applications. It achieves this because Kubernetes’ operators are built around the idea of a control loop. Each time the configuration files are changed via a PR, or based on a defined schedule, the operators compare the current state of the entity’s resources with the desired state declared in the configuration files. If the states do not match then the operators reconcile the entity’s resources to the desired state in the configuration files.
Note that Kubernetes provides more than the reconciliation framework used by the deployment service. It is, after all, a system for automating the deployment, scaling, and management of containerised applications. Our deployment capability only utilises Kubernetes’ reconciliation framework because the controllers and operators provide an extensible mechanism to provision and manage the resources associated with each entity. The custom controllers and operators together with the Kubernetes’ reconciliation framework allow us to deploy data pipelines.
In this article we’ve presented a new capability for deploying data pipelines. The capability:
- abstracts platform capabilities from users:
- allowing them to focus on their strength (defining transformation logic); and
- gives them a simple consistent way to self-serve the deployment of their transformation logic;
- gives platform teams more control over the evolution of the platform; and
- provides a mechanism to apply governance to data pipeline deployments.
The new capability is able to do this because it’s design starting point is the users’ process. As a result the capability ties together separate but related problem spaces of data discovery, data governance, and data pipeline deployment & management.