
At Atlassian, we’ve found that the key ingredients to empower autonomous teams are ownership, trust, and a common language.
We want every team to own our customers’ success. As opposed to a static command and control model, we start from a position of trust in every team and continually work together to verify the quality, security, and reliability of a product. We then scale this practice by ensuring our engineers have a common language. This includes a set of principles, rituals, and expectations to which they can align. The outcome is a loosely coupled and highly aligned system that empowers our teams to move fast, make decisions, and come up with innovative solutions that propel us forward.
We want to share the way we work with everyone, to help improve teams across industries. Hopefully, our learnings will help you build autonomous teams and ingrain ownership in your own organization.
True to our value of Be the Change You Seek, we’re always after new ways of thinking to better our teams. If you have ideas to supercharge this rocketship, join us and make it happen. Visit our Careers page to find out more about becoming an Atlassian engineer.
Contents
- Abstract
- Engineering philosophy and priorities
- Section 1: How we work
- Section 2: How to stay informed
- Section 3: How we develop software
- Cloud engineering overview guide
- Architecture principles
- Development lifecycle
- Developing high-quality software
- Developing secure software
- Section 4: How we ship
- Section 5: How we operate and maintain
- Service tiers
- Service level objectives (SLOs) and error budgets
- Global on-call policy
- Service catalog (Microscope)
- Operational security
- Reliability standards and practices
- Bug resolution and support escalations policy
- Managing costs
- Incident management and response
- Risk, compliance, and disaster preparedness
Abstract
As mentioned in our Cloud Engineering Overview, Atlassian engineering builds upon common foundations in order to develop, ship, and run highly secure, reliable, and compliant software at scale. This guide outlines widely used rituals, practices, processes, and operational tools for our engineering organization. It is a resource for new staff to understand how we operate and is an ongoing reference for existing staff that provides a comprehensive overview of how we work.
For each topic, the engineering handbook aims to include:
- a synopsis of the policy, process, practice, or ritual
- an explanation of why these exist
- the basics of how it’s intended to be used
While each team will likely have adapted specialized rituals for their daily work, they should be closely aligned with the contents of this document.
Engineering philosophy and priorities
As we pursue our mission to unleash the potential of every team, we’ve documented our shared philosophy with the hopes it will guide our actions in the engineering organization, as our company values continue to serve us. We have a team of motivated engineers who deserve a high degree of ownership, and this philosophy supports that ownership.

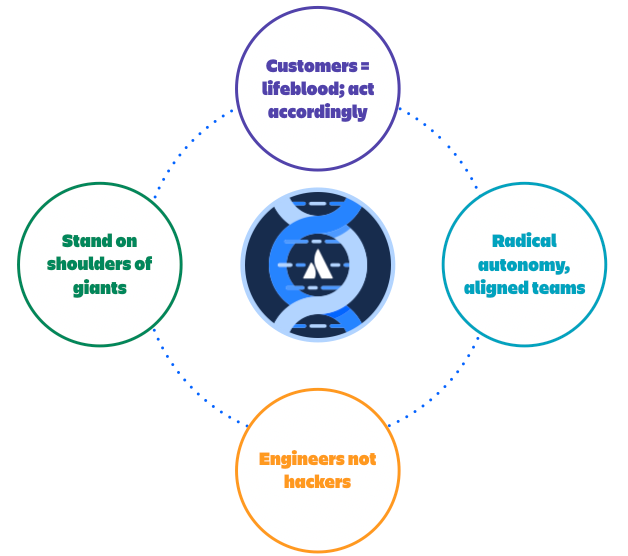
Customers are our lifeblood; we act accordingly
Everything we do creates value for our customers, either by reducing the pain they experience with our products or delivering new innovations to unleash their potential. We regularly interact with customers and we make decisions as if they are in the room, without assuming we know what they need. We value a “bias for action” and we act with a pragmatic, incremental approach because that’s what our customers want.
We expect our teams to have consistent, regular interactions with customers.
Radically autonomous, aligned teams
We are loosely coupled but highly aligned. We prune coordination overhead and dependencies whenever possible. Decisions are made quickly with the right people involved and no more. Teams are empowered to decide and act with autonomy, yet they align with common practices, consistent with our company values and engineering philosophy. Radical autonomy is a two-way street. Every team contributes to our culture of autonomy by empowering other teams to move fast.
We expect our teams to own the outcomes they deliver, document their work, and empower other teams as a result.
Engineers, not hackers
We build with pride and rigor because it leads to better outcomes for our customers and a sustainable pace of innovation for the future. We avoid and eliminate unnecessary complexity, pay off technical debt, and reduce toil through automation. We earn and maintain our customers’ trust by ensuring we build and maintain well-architected, cloud-native infrastructure and applications that are secure, high-performing, resilient, and efficient to operate. We are innovators who deliver the quality that our customers expect.
We expect our teams to measure the metrics that matter, set challenging objectives to improve them, take action if we’re not meeting our baselines, and innovate with quality for the future.
Stand on the shoulders of giants
We leverage the wealth of our rich history and use what we’ve learned and created to power the future of teamwork. We believe a common platform underpinning all of our products will allow our customers to have a consistent experience and will create a competitive advantage for the long term. We invest in high-value, consistently built, reusable components to reduce duplication and wasted effort.
We expect our teams to use, contribute, and enhance our common services, libraries, patterns, and guidelines.
Guidelines for prioritization
In the course of our daily work, teams will need to make prioritization decisions as they choose to focus on one task or project above another. These priorities ensure we apply sufficient time and attention to the following list of activities, in the order in which they are listed.
- Incidents: Resolve and prevent future incidents, because our products and services are critical to our customers’ ability to work. If there are multiple, high-priority incidents that are competing for our attention and resources, then we will prioritize using the following guidance: security incidents first, then reliability incidents, then performance incidents (which we consider part of reliability), followed by functionality incidents, and all other categories of incidents.
- Build/release failures: Resolve and prevent build/release failures, because our ability to ship code and deploy updates is critical. If we’re unable to build and/or release new software, we’ll be unable to do anything else.
- SLO regressions: Triage, mitigate, then resolve out-of-bounds conditions with existing service level objectives (SLOs), because without meeting our SLOs we’re losing the trust of our customers. If multiple SLO regressions are competing for attention, security regressions are always given priority. The prioritization for SLO regressions includes (in priority order): security, reliability, performance, and bug SLOs.
- Functionality regressions: Fix regressions in functionality that have been reviewed and approved by your product manager.
- High-priority bugs and support escalations: Resolve bugs in agreement with your product manager and resolve customer escalations because they impact customer happiness.
- All other projects: Everything else, including roadmap deliverables, new objectives, and OKRs (objectives and key results, described further below).
Section 1: How we work
A combination of OKRs and SLOs
- Deeper dive into OKRs: OKRs: Your seriously simple goal setting guide
- Deeper dive into SLOs: SLA vs. SLO vs. SLI – Differences | Atlassian
What it is
Objectives and Key Results are a goal-setting method we use across the company. OKRs can be set at different levels such as company, department, or team. OKRs represent goals for achieving something new, like increased customer engagement, or new levels in performance or reliability.
Service level objectives (SLOs) are used to maintain all that we’ve achieved in the past, preventing regressions and taking swift and sufficient action when we backslide. For example, maintaining all of our product capabilities, maintaining established levels of performance, security controls, compliance certifications, and our customer’s happiness and trust. When we want a significant step change in an SLO, then we’ll create a new project for it and track the achievement of the new goal as an OKR.
Using a metaphor from airplane flight, you can think of SLOs as maintaining a smooth, level altitude and OKRs as gaining new heights. As mentioned above, we always seek to maintain our SLOs and build on that foundation to achieve new goals defined by our OKRs.
Why they exist
- SLOs and OKRs align our employees with our company goals and give every team and employee clear direction and focus.
- They allow us to maintain what we’ve achieved, measure progress towards new goals, and increase accountability and transparency.
- They improve resource allocation and help limit duplication and work not aligned with our priorities.
How they are intended to be used
- OKRs
- The objective within an OKR is a short statement summarizing what we’re trying to achieve with the purpose of aligning our teams with a common purpose.
- Key results within OKRs are a small set of measures (three to five, typically) that define the success criteria for the objective. The measures are selected to be a feedback mechanism that helps you know if you’re on the right track and when you are done.
- Company-level OKRs are defined and then each department and team create OKRs that tie into the company-level OKRs.
- All OKRs are documented as Jira issues, in a specific project, located in the tracker link above.
- SLOs
- An SLO is a target value or range of values for a capability that we intend to maintain in order to keep our customer’s trust and happiness.
- We use tools to track and measure our SLOs to ensure they are within an acceptable range, and take swift action when they fall outside the range.
Our Product Delivery Framework
What is it
Our product delivery framework is how we address and improve products and services used across Atlassian. It provides a common approach, language, and toolbox of practices to help us collaborate and create impact for our customers.
Why this exists
As we have continued to grow, it’s become more difficult to communicate across teams and to introduce new team members to our ways of working at scale.
To address this challenge, we introduced a common approach for teams to tackle projects. Our customers benefit from this standardized approach. It allows us to prioritize customer needs, allocate more time to innovation, and allows us to continue improving our products instead of duplicating existing processes and practices across teams.
How it’s intended to be used
We celebrate a healthy combination of what already works in our teams, The Atlassian Team Playbooks, as well as elements of other frameworks that are proven to work.
When new projects are conceived and started, four components help us align on our ways of working from idea to impact: principles, phases, checkpoints, and plays.
Principles
The principles guide our thinking and decision-making as we work in our teams. They are intentionally not binary and use a ‘this over that’ format, to help us favor one behavior over another.
- Are we optimizing for customer value over feature delivery?
- Do we prioritize delivering an outcome rather than simply shipping on time?
- Do we have the confidence to make informed bets rather than spinning in analysis paralysis?
- Do we have a flow and rhythm in how we work across teams rather than being too reactive?

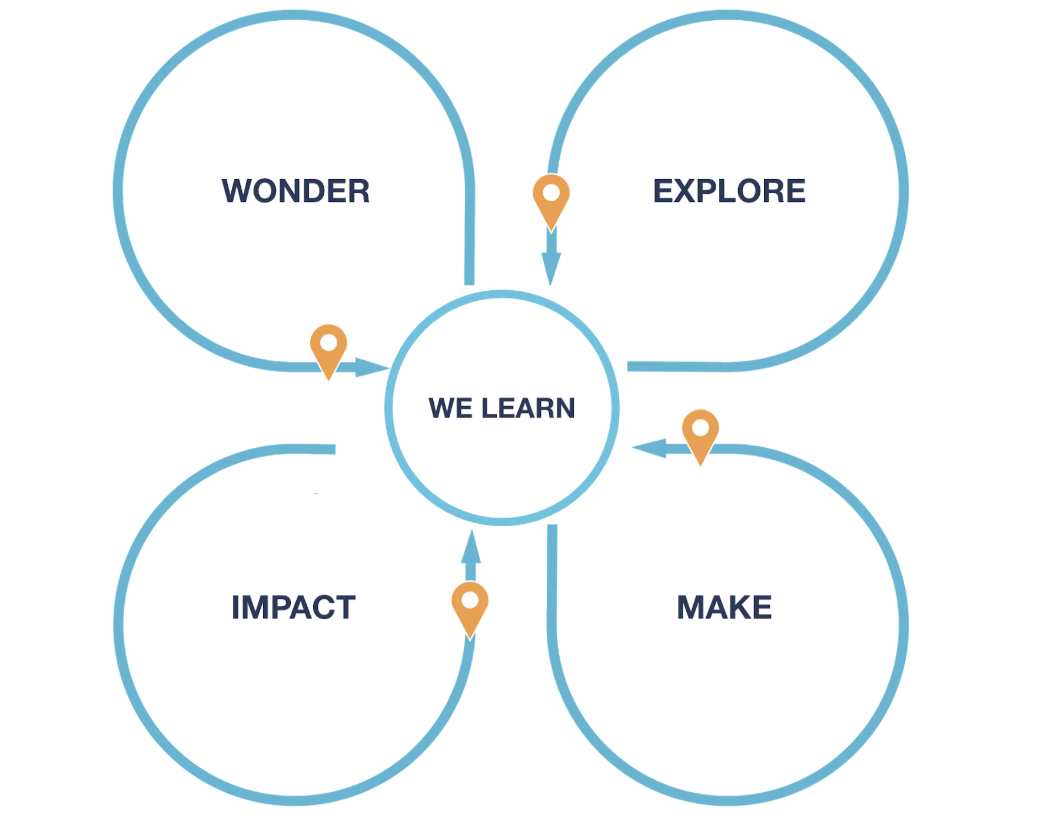
Phases
Our ways of working are shaped around four phases, from having an idea to delivering customer value:
- Wonder, take the time to discover the problem space
- Explore multiple potential solutions
- Make, solve the problem
- Measure impact and gather learnings for both our customers and Atlassian
Checkpoints
We are using intentional moments of reflection to help ensure continued clarity about the outcomes we are working toward, the problem we are solving, and whether we are still heading in the right direction.
Checkpoints enable our teams to orient where we are and prioritize what to do next, while ensuring we are addressing the right concerns at the right time. Are we confident enough to move on?
Plays
Plays are our way of putting these ideas into practice. Some are well defined in The Atlassian Team Playbook, some are newer and we’re still learning how to make the most of them.
The Atlassian Team Playbook
What is it
Team Playbooks are resources we’ve developed for addressing common team challenges and starting important conversations. They’re used extensively within our company and have also been published publicly for use by any team in the world.
Some of the most popular Plays include:
- Trade-offs: Our engineering teams use this play in order to make appropriate trade-offs between competing priorities, like extensibility, maintainability, and scalability.


- Clean Escalations: When they get stuck on a decision rather than engage in unproductive debates, they escalate to make a decision and move forward quickly.
- Health Monitors: We regularly use Health Monitors across all teams at Atlassian in order to assess how our teams are functioning, so we can make improvements when necessary.


- Project Kickoff: We use project kickoffs to bring all team members together and get aligned on our goals, priorities, metrics, and trade-offs. The kickoff is used as a forum to ensure we have a shared understanding before we proceed.
- Managing dependencies: Our engineering teams do their best to eliminate as many dependencies as possible before starting a project. However, when we can’t eliminate them all, we use this technique to avoid potential bottlenecks.
- 5 Whys Analysis: We use the 5 Whys Analysis to go beyond a surface-level understanding of a situation and dig deeper to get to the bottom of a problem. This is an essential step in our incident reviews.

- Inclusive Meetings: We recognize the value of diverse teams, and will regularly invoke the principles from our Inclusive Meetings Play to ensure we make space for all attendees to participate and have their voices heard.
- Goals, Signals, and Measures: We use this Play to align on project goals, key measurements, and signals for indicating we’re on the right path. This is usually done just prior to the Project Kickoff and revisited as new information surfaces.
- End-to-end Demo: Our teams use this method of prototyping to help everyone on the team visualize solutions, gather feedback, and achieve a shared understanding.
How they are intended to be used
Each Play is designed to be a simple workshop-style tool that will help your team address a common problem or start a conversation about something new. Each Play is used with the following steps:
- Do some prep work, schedule a meeting, and share the materials.
- Run the Play by facilitating the workshop with your team.
- Leave with a plan by documenting insights and assigning action items.
Project Communications
Team Central
Team Central BETA | Organize your projects’ updates
The Loop: Project Communications for Teams-of-Teams


What is it
Team Central is an Atlassian product that helps organizations share the status of projects and goals among their teams. We use it internally to openly share work-in-progress across teams, functions, locations, and levels. Teams are required to use our internal instance of Team Central to communicate project status and foster an open, transparent culture of work. Engineering and cross-functional leaders use Team Central as their source of truth to effortlessly discover and give feedback on the status of the projects, goals, and teams they care about, without having to sift through the noise of traditional status spreadsheets.
Why this exists
It gives everyone access to real-time progress, potential problems, and priorities, in a digestible feed they’ll actually read.
How it’s intended to be used
- Create a project on Team Central for all new or existing projects (available now in beta).
- You can also discover and follow any project you’re interested in to receive updates in your feed and/or a weekly digest email.
- Every Friday, you’ll get a reminder to write an update communicating the latest status of your project, highlighting outcomes you achieved for the week and flagging important information stakeholders or dependent teams need to be aware of.
- Every Monday, your project’s followers will receive an email with your update, plus any other projects they’re following. Just like that, everyone’s on the same page.
DACI Decisions
DACI: a decision-making framework | Atlassian Team Playbook

What it is
A decision-making framework used extensively throughout the company and the industry, when a team is faced with a complex decision. Internally, we document our decisions with a standard template used in Confluence. DACI is an acronym for Driver, Approver, Contributor, and Informed.
Why this exists
DACIs are used to make effective and efficient group decisions. They spread knowledge, reduce surprises, highlight background research, and increase openness and visibility within our organization. Writing down the details creates accountability, fosters collaboration, and almost always leads to better decisions.
How it’s intended to be used
- Start by creating a DACI document using a Confluence template.
- Fill out the document by naming the stakeholders:
- a single individual who is driving the decision
- the individual who will approve the decision
- the list of people who need to be informed the decision is made
- the list of people who will contribute to the research
- Document the background and the research that went into the decision.
- Make the final decision and record it in a document so others can learn from it and/or stay informed.
Request for Comments (RFCs)
What it is
An RFC is a short, written document describing how something will be implemented. They are used for any nontrivial design. Some companies refer to these as design documents or architectural decision record. Whatever they’re called, they’re very similar. They’re used to solicit feedback and increase knowledge sharing within an engineering organization.
Why this exists
It spreads knowledge, reduces surprises, highlights tech debt and other challenges, and increases openness and visibility within our organization. As with DACIs, writing down the details and sharing them with others creates accountability and almost always leads to better outcomes. RFCs are slightly different from DACIs in that they’re used to communicate the chosen solution while also soliciting feedback to further refine the approach.
How it’s intended to be used
- Create a Confluence page, using the RFC template.
- Write the approach as succinctly as you can. Maximize understanding by avoiding jargon and unexplained acronyms and using simple language.
- Similar to a pull request, a few relevant peers and, in most cases the team architect, should review the document to validate the approach. The document should be open to anyone in the company to view or comment on.
Global engineering metrics (GEM)
What it is
A set of engineering metrics that can be consistently applied across all engineering teams, inspired by industry-standard DevOps metrics. Teams should augment these metrics with additional measures that make sense for their specific team or organization.
Why this exists
Having a shared set of metrics allows organizations and teams to benchmark themselves relative to their peers, identify bottlenecks/common roadblocks, and practice continuous improvement.
How it’s intended to be used
By harvesting data from Jira, Bitbucket, and other sources, GEM automatically populates a dashboard for each team that includes the following metrics.
| Metric Name | Measurement | What does the measure mean? |
| Pull request cycle time | The time from when a pull request is opened until it’s deployed in a production environment, or to a successful build for codebases with no prod deployments. | Shorter pull request times indicate fewer bottlenecks in our continuous delivery process. |
| Story cycle time | Time to transition from an In Progress status category to a Done status category. | Shorter cycle time means our work is delivered to customers faster and in smaller increments, leading to improved iteration. |
| Successful deployments | How often the team deploys new code to a production environment. For pipelines that don’t deploy directly to a prod environment, we look at successful builds on the main branch. | Higher deployment frequencies allows us to reduce the batch size (fewer changes in each deployment), reducing the likelihood of conflicts and making problem resolution easier. |
We expect teams to use the global engineering metrics dashboard to establish a baseline, identify ways to improve their effectiveness, share the lessons with others, and look to amplify the impact across teams.
Section 2: How to stay informed
Below are the guidelines and resources for staying informed within our engineering org.
Engineering-wide communication
We share information within the engineering organization in the following ways:
- CTO Organization space—A space in our Confluence Cloud instance where the CTO leadership team shares important information.
- Sri’s blog—a space for communicating updates and announcements across our globally distributed engineering organization.
- Our public engineering blog—This is our engineering blog where we publish content to inspire our community.
- Engineering Town Halls and AMAs—We host recurring town hall meetings for all engineering team members where we discuss topics relevant to everyone and create a forum for questions.
- Engineering team.work() conference—Every year we put on a conference to help all of our engineers hone their craft. Many parts of this conference are open to the public so we can connect with our peers and openly share our work. We invite guests from across the industry to discuss topics such as building large-scale SaaS applications, collaborating with remote engineering teams, leveraging emerging technologies, and software architecture for the cloud.
Engaging with customers and ecosystem
Our primary means for engaging with our customers and our developer ecosystem is our community forums. We have a community for customers at Atlassian Community and a community for our developer ecosystem at community.developer.atlassian.com. These resources complement our support tool and developer documentation by enabling our employees to engage with our community. All of our employees are encouraged to join conversations there and help answer questions or share tips on how to get the most out of our products.
Section 3: How we develop software
Cloud engineering overview guide
All of Atlassian engineering builds upon common foundations in order to develop, ship, and run highly secure, reliable, and compliant software at scale. The document located at Atlassian’s Cloud Engineering Overview – Atlassian Engineering introduces our shared services, components, and tools.
Architecture principles
What it is
We’ve created a set of architecture principles to keep in mind as you design and evolve software. They go hand in hand with our engineering philosophy and they are intended to serve as a reminder of what’s essential in our approach for designing software and components.
Why this exists
When developing software, it’s easy to get bogged down in the details and day-to-day challenges of getting work done when working under time pressure.
How it’s intended to be used
These principles are designed to establish a north star for anyone who is designing a system or component. Additionally, when designs are being reviewed through an RFC process, the reviewers can use these principles to “pressure test” a design to ensure it’s aligned with our principles.
The principles are summarized below but the document linked above contains more context and details.
- Keep it simple: Simpler architectures are less complex to operate, inherently driving a better security posture and enabling efficient operations.
- Be data-driven: Use real, empirical data to make informed decisions. Making too many assumptions and not relying on real-world data can lead to catastrophic failures.
- Design for failure: Failures are inevitable. The best designs are resilient, degrade gracefully, and protect the other components they interact with. Testing for failure scenarios is often more important than testing for normal operations.
- Spend like it’s your money; don’t waste it: Our business model involves keeping our costs low so we can offer our cloud products at low prices and achieve our mission of unleashing the potential of all teams. You should ensure your systems are right-sized and there is a plan to adapt the resources as capacity changes occur.
- Security by design: There are no safe networks. Our software designs must prepare for the worst by assuming breaches will often occur at the most unexpected and weakest parts of our systems. We should also plan how we’ll respond to a breach, if it occurs, to minimize impact.
- Use existing patterns: We leverage existing patterns where possible to stand on the shoulders of the work that’s come before. By leveraging the mistakes of the past, we are able to build more secure, reliable, performant, and efficient components. When teams improve existing patterns or establish new ones, those improvements are shared with our entire organization.
- Extensibility for the win: Our components should come with self-service APIs, documentation, and tools to help both our ecosystems and internal teams. However, don’t overdo it on excessive extensibility. Beware of over-engineering beyond what is necessary. Take inspiration from the Unix philosophy.
- Balancing act: All software design involves making trade-offs and balancing goals. Make your trade-offs explicit and ensure the trade-offs are well understood and agreed upon by your team. It’s very easy to get caught up in over-designing a solution to accommodate too many edge cases, resulting in overly complex systems.
- Being good is not good enough: Maintain and elevate your internal standards of craftsmanship. Strive for a level of quality that we can all be proud of and recognize that a temporary solution often becomes a permanent problem.
- Internalize distributed systems: Leverage the concepts that have fueled the renaissance in distributed systems, such as asynchronous methods, availability over consistency, single-purpose, well-understood building blocks that do one thing incredibly well, and circuit breaking for limiting failures.
Development lifecycle
In addition to the development lifecycle that is outlined in Our Product Delivery Framework (see above), there are some common development lifecycle steps that most engineering teams follow while working on a team.
Outcome-driven development and Agile process
There is no prescribed process that all engineering teams must use. Most teams use a variation of Agile, each refining their own process through cycles of iteration, retrospection, and adaptation. We encourage all teams to deliver measurable outcomes over simply delivering output and projects. However, there are some common traits that most team’s processes include, such as:
- Two-week sprints: Time-boxing a development cycle allows for incremental progress and iteration. Each sprint generally includes sprint planning, a shared understanding of what it means to be “done,” some form of stand-up, and periodic retrospection.
- Milestone planning: Most teams use milestones from one month to one quarter to track their progress against a larger plan that sometimes involves syncing up with other teams, and regular reflection on goal achievement.
- Demos with the team and stakeholders to create a shared understanding, celebrate achievements, drive discussions, and improve the work.
Engineering efficiency formula
Our engineering efficiency score is a metric we use at Atlassian to measure the percentage of engineering effort that moves the company forward. It’s the percentage of time an org spends on developing new customer value vs. time spent on “keeping the lights on (KTLO)” or maintaining the current products and service level objectives.
Our engineering efficiency formula is defined as:
Engineering_Efficiency = Move_Atlassian_Forward / (Move_Atlassian_Forward + KTLO)
Here are our definitions of the terms in the equation above:
Moving Atlassian forward
Move_Atlassian_Forward = Org_Development + Internal_and_Customer_Improvements + Innovation_Time
Moving Atlassian forward is defined as the time we spend developing ourselves and our organization, improving our products, and innovating. Some examples of these activities are:
- Organization development: Hiring, interviewing, on-boarding, and career development.
- Internal and customer improvements: Building new product capabilities, improving performance, scalability, reliability, accessibility, security, and privacy. This category of work also includes improving our own productivity and efficiency, as well as engaging with customers to better understand their needs.
- Innovation time: This category includes ShipIts (our internal hackathons), innovation time where we explore new ideas outside of our product roadmaps and pursue new research and development projects that hopefully lead to new products and innovations.
Keeping the lights on (KTLO)
KTLO = Tech_Entropy + Service_Operations + Administration_Work
Keeping the lights on refers to the time we spend addressing routine tasks that fall outside of improving our products and our organization. This includes maintaining what we’ve built, engaging in daily operations tasks, and attending to routine administrative work. Some example of these activities are:
- Tech entropy—Upgrading and responding to breakages in dependencies, fixing bugs, security vulnerabilities, remedial work to sustain an objective, maintaining our development velocity, and addressing technical debt.
- Service operations—Operating services by maintaining alerts and monitoring, triaging errors in logs, maintaining compliance certifications, etc.
- Administrative category—Taking time off from work, parties, celebrations, town hall meetings, and other administrative tasks that don’t fall into the categories above.
When we see problems with efficiency, we explore the root causes and address the problems in order to bring the efficiency score back into an acceptable range.
Developing high-quality software
Tech stack policy
What it is
Our policy is to use standardized tech stacks for building cloud services, web applications, and mobile applications. The tech stacks include languages, libraries, frameworks, and other components.
Why this exists
This allows us to be more effective at scaling our organization through consistency and shared understanding. Being consistent with a small number of tech stacks increases our flexibility when resource shifts are required, while still allowing us to make an appropriate selection. It also enables us to achieve greater leverage with shared libraries, frameworks, testing tools, and supporting functions like the security teams, release engineering teams, platform teams, and others.
How it’s intended to be used
When browsing the tech stacks, you’ll see the following terms:
- Mandatory—You must use this unless you are modifying existing code that exists in another tech stack. Exceptions can be made only with a DACI and approval from a Head of Engineering and a member of the core architecture team.
- Recommended—It’s strongly recommended you use this. If you choose something else, you must explain the decision in an RFC, proposal, and DACI and get buy-in from your team’s architect (or de facto architect).
- Suggested, Status Quo or Default—These are suggestions or the status quo. You may choose alternatives without additional approval, if necessary.
Consistent architecture and reusable patterns policy
What it is
Our policy is to use standard architectural design patterns across all our products, services, and components, whenever possible. Our architectural patterns describe the preferred approach to solve common engineering challenges.
Why this exists
There are many requirements to develop, ship, and run highly secure, reliable, and compliant software at scale. To scale efficiently, we need to be able to reuse patterns and best practices across the company. This is where standardization helps. Standardization unlocks scale by promoting reusability, consistency, and shared understanding. This leads to predictable results and reduces unnecessary complexity and cost.
How it’s intended to be used
Our catalog of standardized architectural design patterns:
- Engineers can browse the catalog of patterns and company-wide standards. Each pattern, standard, and best practice is in a consumable, consistent format, including code snippets, reference architectures, version information, and team feedback.
- Anyone can contribute to the body of knowledge in a structured manner using an RFC or a pull request.
- Anyone can use the prescribed framework to identify, develop, and create new standardized patterns.
Cloud platform adoption guidelines
What it is
- Products should not duplicate fundamental existing platform capabilities.
- We would rather take a reasonable delay in releasing a new product to build it on our platform rather than building custom functionality that duplicates existing platform capabilities.
- All Enterprise products will adopt platform capabilities in the “Enterprise readiness” bucket instead of building their own data stores, compliance mechanisms, and admin capabilities.
Why this exists
We invest in shared platforms to:
- Support our company strategy by creating customer acquisition leverage through growth virality and further enabling our self-service distribution engine.
- Increase cross-sell and cross-flow between our products.
- Deliver superior features and enterprise capabilities across all of our products nearly simultaneously, at a much lower cost than developing those capabilities individually for each of our products.
- Increase the speed of innovation by leveraging shared technology to build features and new products faster than our competitors.
- Centralize and connect data across our products to surface unique insights for our customers.
- Make the development APIs of all our products consistent through a common extensibility framework within a central ecosystem and marketplace for our partners and developer community.
- Enable ourselves to grow through acquisitions and increase our product portfolio diversification faster than competitors by making it easy to onboard new products onto our shared platforms.
Peer review and green build (PRGB) policy
What it is
All changes to our products and services, including their configurations and the tools that support the provisioning of them, must be reviewed and approved by someone other than the author of the change. In addition, the change must pass a set of build tests to confirm they work as expected.
PRGB is also a critical process used for our compliance certifications, covered later in this doc.
Why this exists
For our own peace of mind, customer confidence, and compliance requirements, we need to show our customers, auditors, regulators, and anyone that wants to know, that changes we’ve made have been peer-reviewed and tested.
How it’s intended to be used
Repository owners must ensure compliance settings on new repositories are enabled on either Bitbucket Data Center or Bitbucket Cloud and that they’re using a build plan or pipeline that includes the PRGB controls.
Once the PRGB repository settings are enabled, changes are made using the following process:
- To merge code into the branch you need to raise a pull request.
- Pull requests must have at least one peer review and the number of reviewers should increase based on the complexity or risk associated with the change.
- If you change the code after a peer review then the approvals are reset.
- A set of builds that must be green are also defined.
Testing recommendations
We don’t have specific guidelines or requirements for testing. Each team should make those decisions for themselves. However, it’s recommended that all changes should include unit, function, and regression test coverage prior to merging.
In addition, some back-end services should also include:
- Capacity testing
- Resiliency testing using chaos tools where we test a system’s response to outages
- Failure injection testing is a great way to identify the limitations of failure scenarios for a service
- Performance and benchmark tests to ensure the change hasn’t caused a regression in performance or key benchmarks
Developer documentation standard
What it is
All teams are required to expose their service and API documentation on internal pages on developer.atlassian.com. That site is our central resource for all of our internal developer documentation for our shared resources, components, services, and platform. Because it is such a critical resource for all of our teams, we require that every team allocate some portion of time to writing and maintaining high-quality documentation.
Why this exists
We want to reduce the cost associated with unnecessary overhead around service integration and adoption. When our APIs aren’t documented well, are hard to discover, or are difficult to integrate with, we create inefficiencies and friction within our organization. This results in more meetings between teams. Because we have a large number of products, dependencies, and teams operating in different time zones, this can eat up a lot of time.
How it’s intended to be used
If you build a service, API, component, or library that is intended to be used by other teams within Atlassian, then it should have high-quality documentation including:
- A brief overview
- Reference material
- A comprehensive guide on integration
These documents must be written as if they can easily be understood by an outside developer. We refer to this mindset as “third-party first” thinking. Whereby we build our internal components and documentation to the same level of quality we would use for external (or third-party) developers.
Developing accessible software
What it is
Accessibility is part of our DNA and therefore in many circumstances, it’s usually a required part of building our products. We have guidelines on how to make our products more accessible and a detailed “definition of done for accessibility” that describes our standards for delivering software. We require our products to undergo periodic accessibility assessments, as we aim to meet the needs of all of our customers.
Why this exists
Our mission is to help unleash the potential of every team. We simply cannot achieve this mission unless our products are accessible to everyone. Our products need to usable by people who have permanent or temporary disabilities so they can do the best work of their lives when they use our products.
We not only stand to lose business in the future should we fail to keep up with our competitors and standards, this is also our moral and ethical obligation to our customers and shareholders, not a feature request or a legal checkbox. We cannot be proud to ship unless we ship accessible software.
How it’s intended to be used
- Product management will set accessibility goals for each product, that make forward progress against our company-wide accessibility goals.
- Teams will use the definition of done for accessibility, as well as the instructions on how to test for it to build accessible products.
Working with open-source software
What it is
We have guidelines for working with open-source software that everyone must follow. The guidelines cover:
- Open-sourcing things you’ve worked on as an Atlassian employee
- Using open-source software in Atlassian software
- Contributing to open-source projects as an Atlassian employee
- Maintaining and merging external contributions to an Atlassian open-source project
Why this exists
There are legal, intellectual property, security, privacy, and compliance risks associated with open-source projects. We developed a set of guidelines for everyone to follow in order to reduce these risks while unlocking all of the benefits associated with open-source software.
How it’s intended to be used
- Learn about our open-source philosophy
- Understand how to contribute to an existing open-source project
- Ensure you understand how, why, and under what circumstances you can create a new open-source project using code you’ve worked on as an Atlassian employee
- Learn about the various open-source licenses that can be used within our software
- Learn how to be a great maintainer of an open-source project, particularly one that accepts external contributions
Note: We will share our open-source guidelines and philosophy in the coming months.
Developing secure software
The following are a series of activities, practices, and required policies that exist to ensure we build security into our products, services, and applications.
Secure Development Culture and Practices (SDCP)
What it is
The SDCP encapsulates the security practices we use during development. All of our development teams partner closely with our security engineers to ensure we design and build security into our products.
Why this exists
Secure development culture and practices are the cornerstones of secure software. You cannot pen-test your way to secure software; you must build security in. The focus of this program is maintaining verifiable secure development practices so we can demonstrate, to ourselves and our customers, that security is a primary consideration in the design and development of our products.
How it’s intended to be used
There are several parts to our SDCP, including:
Security reviews
We include security risk consideration as part of our engineering processes. Higher risk projects warrant security verification activities such as threat modeling, design review, code review, and security testing. This is performed by the security team and/or third-party specialists, in conjunction with the product teams.
Embedded security engineers
Product Security engineers are assigned to each major product/platform engineering group in order to collaborate and encourage engineering teams to improve their security posture. In many situations, the product security engineer will be embedded within a single team when they’re working on a component that has a higher risk profile for potential security issues.
Security champions program
A security champion is a member of an engineering team who takes on an official role in which the person dedicates time to helping their team make sure our products are secure. They are trained to become subject matter experts and assist teams with tasks such as answering security questions, reviewing code, architecture, or designs for security risks.
Application security knowledge base
We have a secure development knowledge base that helps to share knowledge among our development teams. This knowledge base contains patterns and guides for developing secure applications.
Secure developer training
We offer various types of secure code and security training to all engineers as part of our effort to build secure products from the beginning.
Automated detection and testing
Our security team uses tools that automatically scan our repositories and operate as part of our standard build pipelines. These tools are used to detect common security problems. All engineers are required to resolve alerts or warnings coming from our security scanning tools and these alerts are tracked as one of our critical SLOs.
Section 4: How we ship
This section introduces practices, rituals, and processes that we use to ship new features, improvements, services, and entire products. We use the processes below as part of our preflight steps to guide how we release new functionality to our customers.
It includes the topics of:
- Release management
- Deployment
- Stakeholder awareness
Operational readiness checklist (Credo)
What it is
Credo is the code name for our operational readiness checklist and review process for launching new services or major upgrades for existing services. The checklist contains prelaunch reminders that include capacity planning, resilience testing, metrics, logging, backups, compliance standards, and more.
Why this exists
Anyone can forget a step resulting in a disastrous outcome. Using a checklist is a proven technique for avoiding mistakes and oversights. We use an operational readiness checklist when launching new services to ensure they all reach a certain level of service maturity before they launch so major problems can be avoided.
How it’s intended to be used
Before a new service or major component is released for the first time or after a major update in functionality or implementation, the team who built it is required to achieve a passing grade on the Credo checklist. This involves a process that includes:
- Create or update the service metadata in our service catalog.
- Credo issues that are automatically created in Jira and answer the questions on the issues.
- Schedule a review with the site reliability engineers (SREs) team prior to launch.
- If the review passes inspection, launch your service; if not, remediate the issues and perform a follow-up review.
Controlled deployments to customers
What it is
Our teams use an incremental and controlled release process whenever they introduce changes into our products or production environments. This ensures that the change performs as expected and our key metrics are monitored as the change is gradually introduced. This process is used for code changes, environment changes, config changes, and data schema changes.
Why this exists
This reduces the blast radius of problems introduced by any change.
How it’s intended to be used
There are several options for performing controlled releases to customers. Some of these techniques are often used in combination.
Canary deployments/Progressive rollouts
These are techniques where code and configuration changes are released to a subset of users or a subset of the production cluster and monitored for anomalies. The changes only continue to roll out to the wider population if they behave as expected.
Preproduction deployments
This is a practice to add a deployment stage that closely resembles the production environment before the release. Often, the preproduction environment is used by the team or the entire company as a testing ground for new functionality.
Blue-green deployments
Blue-green deployments involve running two versions of an application at the same time and moving production traffic from the old version to the new version. One version is taking production traffic and the other is idle. When a new release is rolled out, the changes are pushed to the idle environment followed by a switch where the environment containing the new release becomes the live environment. If something goes wrong, you can immediately roll back to the other environment (which doesn’t contain the new release). If all is well, the environments are brought to parity once more.
Fast five for data schema changes
“Fast five” is a process for safely making data schema changes and updating the associated code (or configuration) that depends on those changes. Our goal is to prevent situations where we have tight coupling between code and schema changes that prevent us from being able to recover to a healthy state if something goes wrong. Fast five can be summarized as:
- There can be no guarantee that a change to the database schema (or data) and a corresponding code change will be deployed at the same time. Code cannot be tied to a particular version of the underlying data or schema, or else it becomes a source for a potential failure.
- To prevent this, you need to write new code capable of detecting which version of the database it’s accessing and able to handle it correctly. The new code must support both versions.
- New code should be deployed everywhere before you deploy the schema changes.
- Once the schema changes are deployed everywhere you can deploy additional code which only supports the latest schema since the old code and schema have now been completely replaced by the new versions in a safe way.
The five stages are:
- Stage 1—the software is running as-is.
- Stage 2—we deploy a version of the software that at least has code to handle data in the current and next state.
- Stage 3—we update the data. It’s more than likely the task to do that is part of the code deployed in stage 2. We just trigger that task at a suitable time. This allows us to not leak data changes all the way through to the behavior layers.
- Stage 4—we alter the code that exhibits external behavior. It’s also quite likely this code was already present in the deployment at stage 2 but was disabled behind a feature flag.
- Stage 5—the new functionality has been fully deployed and all users are engaged with it. We can now delete the obsolete code in a future deployment. Finalizing database refactoring (e.g. deleting columns that are no longer used) would be part of a subsequent cycle of this sequence.
Feature flags
Feature flags are used to fence off new code changes and then the flags are incrementally enabled after the code has been deployed into production. We use LaunchDarkly, a third-party feature flag service provider. Teams are encouraged to use the “feature delivery process” (described below) in combination with feature flags.
Feature delivery process
What it is
Our feature delivery process is a recommended process for delivering every nontrivial product change and is used by many of our teams. This process leverages automation that connects feature flags to a workflow to ensure stakeholders are notified, metrics are associated with new flags, and no steps are missed in rolling out new features.
When a team uses feature flags, there is a recommended process to associate a “feature delivery issue” with each feature flag in order to participate in a workflow that helps automate the process of informing stakeholders including product managers, designers, and the customer support team about new changes that will impact customers as the feature flag is incrementally enabled to our user population.
Why this exists
It enables a workflow to prevent steps from being missed during the release of any change. The workflow also ensures collaboration between all of the participants in the process, including:
- The development team implements the feature and associates it with logs, metrics, and analytics.
- The product manager sets goals for the feature and analyzes the impact.
- The content designer publishes documentation and content that’s timed with the activation of the flag.
- The service enablement engineer ensures our support engineers have the information they need to support customers with questions or issues relating to new features being rolled out.
- The site reliability engineers are informed and able to turn off the flag if anomalies are detected.
- The development team is encouraged to tidy up flags once the rollout is complete to avoid building up technical debt from code that’s no longer used.
How it’s intended to be used
- In the planning stage of your project, create your feature flag and update the auto-generated feature delivery issue in Jira to describe the changes.
- Use the feature flag to fence off the new code changes.
- All of the stakeholders involved are connected to the feature delivery issue and reminders occur through Jira and Slack.
- Boards and dashboards can be used by the team to visualize flags and their statuses.
- Once the new feature is deployed, you can incrementally enable the flag and monitor the results. The associated issue will be updated and transitioned through the workflow as a result.
- Once the feature flag is fully enabled and no longer useful, you must remove the old code and archive the flag. The associated Jira issue will automatically be closed.
Section 5: How we operate and maintain
We have a series of rituals, practices, processes, and standards to ensure we’re able to maintain and uplift the operational health of our products.
Service tiers
What it is
Our policy is that all teams use standardized tiers of service for categorizing a service’s reliability and operational targets. These targets have been developed based on the usage scenarios commonly encountered for the services we build at Atlassian.
Why this exists
Tiers give us a way to split our services up into easily understood buckets. This helps our teams decide what level of engineering effort is appropriate when building their service. Once the service is live, it sets quality standards that should be maintained throughout its life in production. This allows teams to allocate their time appropriately to feature work vs. remedial tasks.
Tiers also allow other teams to understand what to expect from the services they depend on.
How it’s intended to be used
There are four tiers that all services must be bucketed into:
- Tier 0—Critical infrastructure
- Tier 1—A service that directly provides functionality vital to our business
- Tier 2—A service that’s not considered core functionality
- Tier 3—Internal only to Atlassian or experimental/beta services, where customer expectations are low or nonexistent
These tiers are used within our service catalog and also used to drive behaviors across many of our operational practices and policies.
Service level objectives (SLOs) and error budgets
What it is
We use SLOs and error budgets to communicate reliability targets for all of our products and services. When these targets are breached, alerts are raised to trigger the responsible team to take action. We require that all teams use our internal SLO management tool for managing, measuring, alerting, and reporting on our SLOs.
Why this exists
We need to ensure we don’t lose the trust of our customers when it comes to reliability and performance. We’ve built a tool to manage SLOs and raise alerts.
How it’s intended to be used
- Each team defines capability-based SLOs for all products and platforms, using our internal SLO management tool.
- Each SLO will have an associated mechanism for ensuring this SLO is met and an alert if the SLO is breached.
- When alerts are raised our teams take action to determine whether this qualifies as an incident.
- The SLOs for each of our capabilities are the focus of our operational maturity rituals, including TechOps, WORLD, and TORQ (described below).
Global on-call policy
What it is
We need to ensure we are able to support the operations of our business 24/7. Designated teams will be required to be on-call outside of normal business hours, including nights and weekends, to respond to alerts and incidents as quickly as possible. To compensate employees for the burden of being on-call, we have developed a specific compensation policy.
Why this exists
We need to ensure we don’t lose the trust of our customers, but we also need to treat our employees fairly for the extra burden of being on-call outside of normal business hours.
How it’s intended to be used
Teams use OpsGenie to manage their on-call rotations. We have several processes tied to the on-call schedule within OpsGenie, including our compensation process.
Service catalog (Microscope)
What it is
Microscope is our service catalog that records all of the metadata associated with our services. It’s integrated with Micros, our service and infrastructure provisioning system, as well as many other tools and processes we use. It also has an associated Service Linter tool that performs automatic checks on services to help us meet our operational health goals.
Why this exists
A single service catalog tool helps us have a consistent mechanism for exploring, tracking, and operating all of our microservices.
How it’s intended to be used
Service owners/admins are required to use Microscope to create and maintain the metadata associated with their services.
Operational security
Security Practices | Atlassian
The following series of activities, practices, and required policies exist to ensure we maintain security for ourselves and our customers, across all the products, services, and applications we maintain.
Security vulnerability resolution policy
What it is
We’ve made a public commitment to our customers that we’ll fix security vulnerabilities quickly once they’re reported to us and that commitment is backed up by our company policy.
Why this exists
Customers choose our cloud products largely because they trust that we can run our products more reliably and more securely than they could. Maintaining this customer trust is crucial to our business and is the reason security is our top priority.
How it’s intended to be used
- Our product security team will identify vulnerabilities coming from different sources.
- They will triage the incoming vulnerabilities and assign a due date based on the severity of the vulnerability.
- Teams must monitor their dashboard.
- Fixes must be delivered to customers by the assigned due date to ensure we maintain a high bar for customer trust.
- Leverage the available training.
Security scorecards
What it is
Product Security Scorecard is a process to measure the security posture of all products at Atlassian. Specifically, it’s an automated daily data snapshot of a variety of criteria set by the security team. You can then review your score and plan actions to improve.
Why this exists
The goal is the continual improvement of every product through the closing of existing gaps and by pushing for the adoption of emerging security improvements.
How it’s intended to be used
- Scorecards are self-service and can be reviewed any time to check the posture of your product.
- Engineering managers (or team leaders) should review their scorecards at least twice per month.
- Engineering OKRs are tied to security scorecard results, and engineering leadership reviews scorecards regularly to ensure scorecard targets are met.
Reliability standards and practices
Operational maturity model (ServiceQuest)
What it is
ServiceQuest is the operational maturity model we use to measure and improve our operations. It’s essentially a scorecard that covers five critical areas for operational maturity and a process for periodically reviewing that scorecard to determine areas for improvement and/or investment.
Why this exists
Building great services and running them efficiently is critical to the success of our cloud business. ServiceQuest is built on the industry-standard concept of an “operational maturity model” and enables us to measure, monitor, and track our operational maturity over time. This leads to fewer unaddressed regressions in our operational health and improvements over time. By using a standardized set of measures, we can compare the health of our services and also look at how we are trending across a multitude of services.
How it’s intended to be used
- There are five categories we measure and score, each worth 20 points with a highest possible score of 100.
- The categories are: Reliability, Security, Quality, Service Design, and Compliance.
- Every quarter, data from our monitoring tools are combined with survey responses from the team that owns the service. This information is used to produce an updated operational maturity score for each category, which is used during our quarterly operational reviews, known as TORQ (described below).
- Improvements are made by analyzing the scores and tweaking team allocations and/or enhancing operational practices.
Weekly operations review, learnings, and discussion (WORLD)
What it is
WORLD is a weekly operational review that cuts across all of the cloud teams in the company. It’s intended for Engineering Managers, architects, de facto architects, and Principal Engineers. The intention is to create a forum to spar on operational challenges, learn from each other, and increase mindshare on topics like resilience, incident resolution, operating costs, security, deployments, and other operational issues.
Why this exists
WORLD focuses on the “learn” aspect of the Build-Measure-Learn feedback loop. Build-Measure-Learn is a framework for establishing, and continuously improving, the effectiveness of products, services, and ideas quickly and cost-effectively. These meetings ensure senior staff within engineering are equipped to make sound, evidence-based business decisions about what to do next to make continuous improvement on operational health concerns.
How it’s intended to be used
The meeting brings together senior staff (managers and engineers) from all cloud teams and includes a cross-company operational review of incidents and dashboards. It also includes a rotating deep dive into one of the teams’ scorecards and practices, with the intent of creating mindshare around operational health that cuts across all cloud teams. Any Atlassian is welcome to attend.
TechOps process
What it is
A weekly meeting and process used by teams that operate a service or own responsibility for a shared component. The meeting and related activities are intended for the engineering manager and engineers who are on-call for a service or component.
Why this exists
The process aims to build a culture of reliability and help a team meet its operational goals through deliberate practice. It keeps operational metrics top of mind and helps to drive work to address any reported health issues of a service or component.
How it’s intended to be used
- Establish your operational goals. Write them down and ensure they’re being measured.
- While on-call, take notes about events and anomalies that occur.
- Upon completing your on-call rotation, prepare a TechOps report that includes events, anomalies, measurements against your objective, and follow-up actions.
- Conduct a weekly TechOps meeting with the on-call staff and engineering manager to review the reports and drive the follow-up actions.
TORQ process
What it is
TORQ is a quarterly operational maturity review with the CTO leadership team. The review is attended by org leaders, Heads of Engineering, Product leaders, and senior engineering staff. Its focus is to raise awareness of operational excellence concerns, establish operational OKRs, and influence product roadmaps and resource allocation decisions across all departments to ensure we don’t regress or under-invest in operational maturity.
Why this exists
Historically, it’s been easy to focus too heavily on building new features at the expense of operational maturity. The TORQ process is designed to highlight important operational health metrics and trends to influence the organization and product leaders to ensure they’re balancing operational health alongside product development activities.
How it’s intended to be used
Leaders attend a quarterly review meeting where results from the previous quarter and year are discussed. The results include SLOs, security scorecard measures, and infrastructure spending. The department leaders share plans and important learnings with each other, creating accountability for operational excellence.
Bug resolution and support escalations policy
- Public bug fix policies: Data Center/Server bug fix policy & Cloud bug fix policy
Bug fix SLOs
We have a public bug fix policy that helps customers understand our approach to handling bugs in our products. We have SLOs in place to meet our customers’ expectations and engineering managers must ensure these SLOs are met by assigning adequate staff and regularly reviewing the SLO dashboard. Most teams use rotating roles where engineers are assigned to fixing bugs according to the priorities indicated in the bug fix tool.
Support escalation SLOs
There are occasions where customers are blocked and a Support Engineer needs your help to get them unblocked. The developer-on-support (DoS) mission is to understand why the customer is blocked and provide the Support Engineer with the information they need to get them moving again. You do this by accepting the support case, investigating the problem, providing information in comments on the case, and then returning the case to support.
We have SLOs to track how quickly we respond to customers.
Why this exists
One of our company values is “Don’t #@!% the customer. Customers are our lifeblood. Without happy customers, we’re doomed. So considering the customer perspective—collectively, not just a handful—comes first.” More specifically, this policy ensures engineering managers prioritize bug fixing and support escalation activities for their team.
How it’s intended to be used
The process most teams use for bug fixing is summarized as follows:
- Teams will assign developers to a rotating developer-on-support (DoS) role using OpsGenie.
- The DoS will use our bug fix tool to manage support escalations and urgent bugs for the team:
- Support escalations are issues where a Senior Support Engineer needs help from the DoS to resolve a support case for a customer.
- Urgent bugs are those with High or Highest priority.
- We use bug fix SLO dashboards to determine whether sufficient investment is being made into quality and bug resolution and adjust accordingly.
Managing costs
What it is
All cloud teams are responsible for managing their costs and ensuring we’re deriving adequate business value from the associated costs. This includes adhering to our tagging policy and using our FinOps (financial operations) reporting tools to review costs periodically. Engineering Managers and Principal engineers and above are accountable for cost-efficiency within their teams.
Why this exists
Cloud FinOps includes a combination of systems, best practices, and culture to understand our cloud costs and make tradeoffs. By managing our costs, we can make our products more accessible and achieve our mission to unleash the potential in all teams.
How it’s intended to be used
- All cloud resources must be tagged using the Micros service descriptor or the environment tags.
- Teams should have a cost model for their services and use our tracking tools to monitor costs over time and take steps to avoid waste.
- We use the TechOps, TORQ, and WORLD processes to monitor costs and share practices on cost efficiencies.
Incident management and response
Below are guidelines, practices, and resources that help us detect and respond to incidents and then investigate and fix the root causes to ensure the incidents don’t reoccur.
Incident severities
What it is
We have guidelines on determining the severity of an incident, used across all of our cloud teams.
Why this exists
These guidelines provide a basis for decision-making when working through incidents, following up on incidents, or examining incident trends over time. They also foster a consistent culture between teams of how we identify, manage, and learn from incidents.
How it’s intended to be used
We use four severity levels for categorizing incidents:


In addition to the table above, we have detailed guidelines for determining the severity of an incident that considers the service tier of the affected service.
Our incident values
We have defined a set of values that helps empower our staff to make decisions during and after incidents as well as establish a culture around incident prevention and response.
| Our incident values | What they mean |
| Atlassian knows before our customers do | A balanced service includes enough monitoring and alerting to detect incidents before our customers do. The best monitoring alerts us to problems before they even become incidents. |
| Escalate, escalate, escalate | Nobody will mind getting woken up for an incident it turns out they aren’t needed for. But they will mind if they don’t get woken up for an incident when they should have been. We won’t always have all the answers, so “don’t hesitate to escalate.” |
| Shit happens, clean it up quickly | Our customers don’t care why their service is down, only that we restore service as quickly as possible. Never hesitate in getting an incident resolved quickly so we can minimize the impact on our customers. |
| Always blameless | Incidents are part of running services. We improve services by holding teams accountable, not by apportioning blame. |
| Don’t have the same incident twice | Identify the root cause and the changes that will prevent that entire class of incidents from occurring again. Commit to delivering specific changes by specific dates. |
How we handle incidents
What it is
We have specific guidelines and training available to all engineers on how to handle incidents. These guidelines are based on years of real-world experience and common practices used across our industry.
Why this exists
The goal of incident management is to restore service and/or mitigate the security threat to users as soon as possible and capture data for post-incident review.
How it’s intended to be used
- We use many sources of information to detect incidents including monitoring tools, customer reports, and reports from staff.
- When an incident is suspected, the on-call staff will be alerted and will investigate whether or not an incident is occurring.
- During an incident, an incident manager will be assigned and they will decide on the severity of the incident and coordinate the response to restore service as quickly as possible.
- When the incident is resolved, the incident manager will also drive a post-incident review (PIR, see below).
Security incident response
Atlassian Security Incident Management Process | Atlassian
Our security team has processes and systems in place to detect malicious activity targeting Atlassian and its customers. Security incidents are handled in the same way any other incidents are handled.
Post-incident review (PIR) policy
How we run incident postmortems | Atlassian
What it is
A post-incident review (PIR) is a process we use to create a written record of an incident detailing its impact, the actions taken to mitigate or resolve it, the root cause(s), and the follow-up actions taken to prevent the incident from recurring. PIRs are required for all incidents. We follow the blameless approach for the root cause and preventive action evaluation.
Our policy for PIRs is that they must be completed within 10 business days of the incident:
- seven business days for the PIR meeting (if necessary) and the creation of the draft document.
- three days for the owner and approver to review.
Why this exists
Post-incident reviews help us explore all contributing root causes, document the incident for future reference, and enact preventive actions to reduce the likelihood or impact of recurrence. PIRs are a primary mechanism for preventing future incidents.
How it’s intended to be used
A PIR has five steps, which are described more thoroughly in the document linked above.
- A PIR is created during an incident and is used to capture data.
- After the incident is resolved, the PIR form is filled out with relevant information, the most important being the root cause(s), contributing cause(s), system gap(s), and learnings.
- The draft PIR is reviewed and improved by the team who participated in the incident.
- A PIR meeting is held to determine the priority of the necessary follow-up actions.
- An approver will review the document, primarily to ensure the root and contributing causes were identified and that they’re willing to commit sufficient resources and time to complete the required follow-up actions.
Publishing public PIRs
What it is
For customer-facing incidents, the Head of Engineering who owns the faulty service should publish a public post-incident review to the Statuspage for the service within six days business days of the incident. There are guidelines and templates available for writing a public version of a PIR, but they should include the root cause analysis, remediations, and a commitment to completing them to prevent similar incidents in the future.
Why this exists
Public PIRs make us more transparent and accountable to our customers. Most customers understand that incidents can occur. Our timely communications and commitments to preventing similar incidents in the future help restore trust.
How it’s intended to be used
- The Head of Engineering for the faulty service drives a process to publish a public PIR to the Statuspage for the faulty service.
- They use guidelines linked above to determine when a public PIR is necessary and they draw on the information from the internal PIR to explain the root causes and remediations in the public post.
Risk, compliance, and disaster preparedness
Compliance at Atlassian | Atlassian
We aim to maintain a balance between calculated risks and expected benefits. We have a dedicated team that establishes policies for managing risks, helps to achieve industry certifications, coordinates the audit processes associated with our certifications (ISO 27001 & 27018, PCI DSS, SOX, SOC2 & SOC3, GDPR, FedRAMP, etc.), and helps to design solutions and practices that are resilient to disasters. This team will work with engineering teams from time to time, as described below.
Risk management
Atlassian’s Risk Management Program | Atlassian
What it is
We have a program to manage risks associated with our company strategy and business objectives. There is a tool for cataloging risks where they are all tracked, accepted (or mitigated), and reviewed annually.
Why this exists
Integrating risk management throughout the company improves decision-making in governance, strategy, objective-setting, and day-to-day operations. It helps enhance performance by more closely linking strategy and business objectives to both risk and opportunity. The diligence required to integrate enterprise risk management provides us with a clear path to creating, preserving, and realizing value.
How it’s intended to be used
The risk and compliance team uses a process for dealing with risks that:
- Establishes the context, both internal and external, as it relates to the company business objectives.
- Assesses the risks.
- Facilitates the development of strategies for risk treatment
- Communicates the outcome.
- Monitors the execution of the risk strategies, as well as changes to the environment.
As it relates to engineering, we are sometimes required to participate in an interview or provide details on a risk ticket as a subject matter expert for our products, technology, and/or operations. Within the engineering organization, we have embedded Risk & Compliance managers who help and provide guidance around risks, policies, and controls. They also manage company-wide initiatives, including achieving certifications and capabilities.
In addition, we may be required to participate in a control, a recurring process to ensure that risks are mitigated, by verifying some data or taking a specific action. A control is a process (manual, automated, or a combination) designed to ensure that we manage the risk within the agreed upon boundaries. The Risk & Compliance team works closely with engineers to design and implement necessary controls, and to manage internal and external audits. The purpose of these audits is to provide a high level of assurance that the controls are properly designed and operated. We have a strong bias toward automated controls. The control owner is responsible for the design, operation, and for providing evidence the control is working as intended.
Policy central
What it is
It’s a space within our Confluence instance for all of our corporate policies, including those covering technology, people, legal, finance, tax, and procurement.
Why this exists
All employees should be familiar with the policies that apply to their role. Within engineering, you should specifically be up-to-date on our technology policies at a minimum.
How it’s intended to be used
Our policies are made available internally to all of our teams to ensure they understand the bar they are expected to meet. The policies are updated whenever necessary and are reviewed annually, at a minimum.
Disaster recovery (DR)
What it is
Disaster Recovery involves a set of policies, tools, and procedures to enable the recovery or continuation of vital technology infrastructure, data, and systems following a disaster.
We require all engineers to use existing architecture patterns whenever possible and follow our policies to ensure:
- All systems are prepared for failover and can automatically recover with data integrity.
- Automated recovery systems are regularly tested while under load.
- Our teams have confidence in the automated recovery mechanisms.
- Disaster recovery patterns are defined, implemented, and adopted.
- We have real-time visibility into the recovery posture.
- We have reliable, verified, and protected data backup processes in place.
Why this exists
When recovering our products during a disaster, all that matters is whether our customers are able to use our products again without broken experiences. Our products and experiences depend on an ever-growing collection of interdependent components and services owned by product and platform teams. To make sure we can recover fully functioning experiences, we rely on recovery patterns, tools, tests, and processes that understand and can manage the recovery of the customer journey’s system as a whole.
How it’s intended to be used
All engineers are required to read and follow our policy for disaster recovery.
Maintaining existing certifications and assisting an audit
What it is
Engineers are required to help maintain our existing compliance certifications.
Why this exists
Our customers deserve and rely on our ability to prove we meet our control obligations. To do this, we obtain third-party certifications via independent audit firms.
How it’s intended to be used
- Assist during an annual audit, when asked.
- If you are a control owner or participant, you will be required to periodically take action on a control ticket.
- Service owners must ensure proper Business Continuity and/or Disaster Recovery plans that are within the tolerance standards for disruption in case of disaster.
- No mission-critical system can be deployed in production without an appropriate continuity plan.
- Disaster recovery and continuity plans must be tested quarterly and proven to meet the maximum time for recovery (RTO) and recovery point objectives (RPO) for their stated service tier. Any issues identified during the quarterly tests must be addressed with high priority.
Turn ideas into action
Hopefully, this handbook has given you insight into the ways Atlassian’s engineering organization works. To learn more about our shared services, components, and tools, read our Cloud Engineering Overview. If you’re interested in joining our engineering rocket ship, make sure to visit our Careers page to learn more about our open roles.