

The beginning of multi-region in cloud
We have written before about our journey from our own data centres to utilising AWS. This migration of Jira and Confluence into AWS was only the start of our journey of evolving our architecture to a more cloud-native approach. In this blog, we want to talk about one of the next steps in our cloud journey, involving the evolution of our approach to multi-region architectures.
Much like many other companies using AWS, we started out using regions within the US, specifically us-east-1 and us-west-2 (we also made some usage of us-west-1 but generally advised against this). A number of months after the migration of Jira and Confluence to AWS, a team of Atlassian’s decided to use one of our regular Hackathons (what we call ShipIt, ShipIt Days | Atlassian) in order to try out what would be required to allow us to deploy our services to a new region. This involved adding support for that region to our internal Platform as a Service, which we call Micros. The outcome of this ShipIt was successful, and we were able to show one of the huge benefits of the migration to AWS – the ability to spin up services in entirely new global regions quickly.
Armed with the capability to deploy our services to this new region (eu-west-1 in Ireland), we decided that we wanted to test out moving a selection of Jira and Confluence tenants into this region. At the time, Jira and Confluence were fairly monolithic codebases, so deploying them to the new region involved deploying the corresponding monolithic application and Postgres database, along with a set of supporting services, primarily handling routing and metadata related requirements. One such service was the Tenant Context Service, which will play an important role later, but there were other services as well, including required parts of the Atlassian Identity Platform.
Once we were able to operate Jira and Confluence in our new region, it was time to start putting our customers there. We used traffic logs at our edge in order to determine a set of customers whose traffic was primarily coming from Europe, and then we proceeded to migrate those customers into our new region (more on this process later).
Following migration, we looked at performance numbers for the customers, and compared them to before migration. The results were encouraging – performance measurements on the frontend showed that page loads were ~500ms faster at the 90th percentile (readers might be surprised that this number is substantially larger than the latency from EU to US data centres; this is due to page loads requiring a number of serial and parallel calls to the Jira/Confluence backends – meaning that client-to-server latency impact is amplified in terms of overall performance).
The results of the new AWS region in the EU were encouraging, and we decided to proceed with adding more AWS regions and migrating customers to those regions based on traffic patterns. We had soon grown to a total of six regions, covering eu-west-1, eu-central-1, ap-southeast-1, ap-southeast-2, us-west-2 and us-east-1.
Evolution of our multi-region architecture
At the same time, as we were expanding the AWS region foot print of Jira and Confluence, we were doing work in order to break up our single monolithic codebases into a more granular microservices architecture. These microservices would take ownership of parts of data and functionality from the monolithic product codebases. For stateful services (i.e. those that owned some form of data), this meant that we now had to determine how to support the multi-region nature of our products. At first, we saw a a couple of patterns.
- Services that were less latency sensitive typically deployed to a single region.
- Services with stricter latency requirements would generally be deployed to all six regions and replicate their data across regions (using AWS-native replication features wherever possible).
These approaches were fairly effective starting points and allowed numerous microservices to be built. However, it was clear that we needed a more consistent approach to our multi-region architecture – something that was brought to the forefront of our priorities by the arrival of data residency.
What is data residency?
When speaking to customers interested in migrating to Atlassian’s cloud products, we consistently heard about the importance of customers having control over where their data is stored. Data residency formed another important aspect of our multi-region strategy for Jira and Confluence – not only did we have to determine ways to have data close to our users, but we also needed to ensure that User Generated Content (UGC) on customers’ Jira and Confluence sites would only reside within data centres in specific geographic regions.
Building our multi-region strategy
In order to shift our multi-region architecture towards a cohesive approach, we took a fairly standard problem-solving approach.
- Define the problems you want to solve, what you want to optimise for, and the tradeoffs to be made.
- Design a set of common principles and guidelines to drive the architecture.
- Implement the architecture across affected services, and iterate as required.
Defining the problems
While exploring the problem space of multi-region deployments, we found that our problems could be broadly classified into:
- optimisation of latency for end-users interacting with our products
- customer-driven restrictions on where data could be stored
- pragmatic cost efficiency with regards to replication or large amounts of data
In addition to the above, we had the engineering challenges of building distributed systems and the associated need to handle tradeoffs between latency, consistency, and availability.
Let’s dig into each of these problems in some more detail.
Optimising latency for end-users: We want our products to be faster for end-users, and this means that we must minimise network latency between the end-user and our backend systems by placing data in regions close to the end user (and automatically rebalancing as necessary). However, this is complicated by customers who display a global footprint with offices using products, such as Jira and Confluence, from many different regions like Europe, US, Australia, and Asia.
Restrictions on where data can be stored: In order to meet customer requirements around Data Residency (e.g. all their Jira issue data resides within the EU), we needed to be able to provide guarantees that their data would be stored at rest within a geographical boundary (called a “realm,” which can be made up of some number of countries or locations). Additionally, we need to be precise around exactly what data is covered by Data Residency, as Atlassian offers many cross-product experiences, and customers would be able to configure Data Residency on a per-product basis. Thus, we decided that Data Residency should target at rest primary UGC – that is, data like Jira Issues and Confluence Pages.
Cost efficiency: Replication of data across regions can become expensive, particularly for types of data with a large volume or are individually large in size. In the case of Jira and Confluence, this includes Jira Issues, Confluence Pages, and associated Comments and Attachments. This is a problem that grows as we progressively add more regions – while the overhead of always replicating data to 3 regions may be acceptable, it’s likely this will become problematic as the number of regions grows to numbers like 10 or 20. We still want to store data as close to end-users as possible, but there is no point in replicating data to Ireland, Germany, Japan, and Sydney if the customer is operating only out of the US.
Defining the principles
In order to create technical solutions to solve the problems that we saw in the multi-region space, we first had to establish some guiding principles. The purposes of these principles were to bring some consistency to our approach, somewhat constrain the problem space, and make it more tractable.
- For a given instance of a product (i.e. an instance of Jira or Confluence on a domain like foo.atlassian.net), there must be a realm in defining which AWS regions data can be stored. This realm must be canonically stored in a centralised system.
- Services that hold UGC must be divided into shards. A shard should define the data regions for a service’s data as well as the URLs / metadata needed for accessing that specific shard.
- For a given instance of a product, all individual services holding UGC for that product must have a canonical shard selected and stored in a centralised system.
- The data for a given instance of a product must be able to be migrated between realms.
It’s worth calling out at this stage that we had a practical constraint in the development of our approach to multi-region architecture and data residency, which is that we must be able to progressively onboard new and existing services – this is because not all services are going to meet the required capabilities (i.e. deployed to every required region) at the same time.
Designing our multi-region architecture
Following our principles, we have the need for a set of centralised systems that allow us to store and retrieve information about where data is stored in services, along with orchestrating migration of service data between regions. Let’s introduce some of these key services.
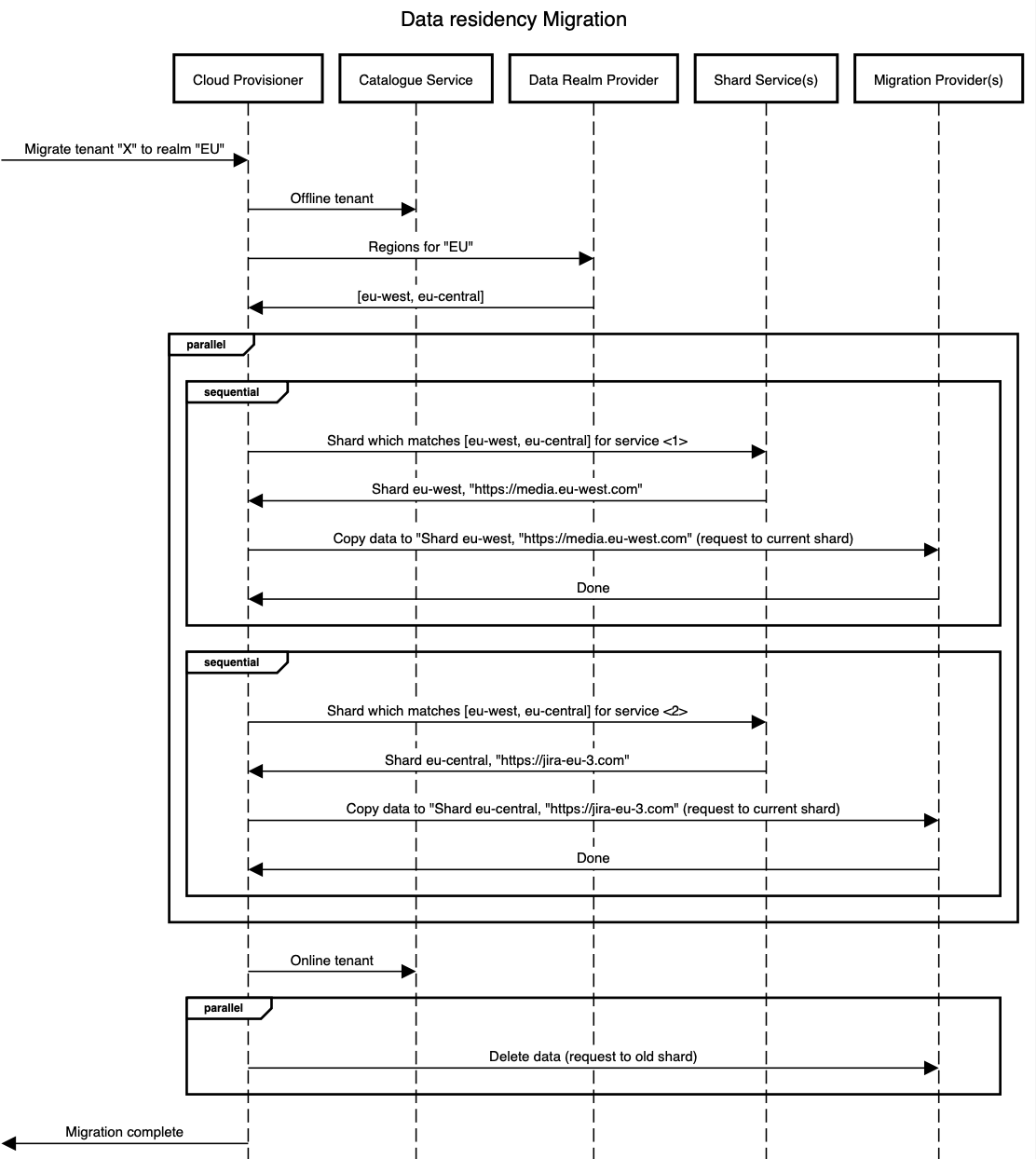
Cloud Provisioner: An orchestration service built on top of AWS Simple Workflow Service (SWF), which is responsible for actions, such as provisioning and de-provisioning Atlassian products, along with the migration of data for product instances between realms.
Catalgoue Service: A system-of-record for meta-data that is associated with a given tenant (this is an instance of a product, such as Jira or Confluence). Catalogue Service is written by Cloud Provisioner during workflows and executed by Cloud Provisioner.
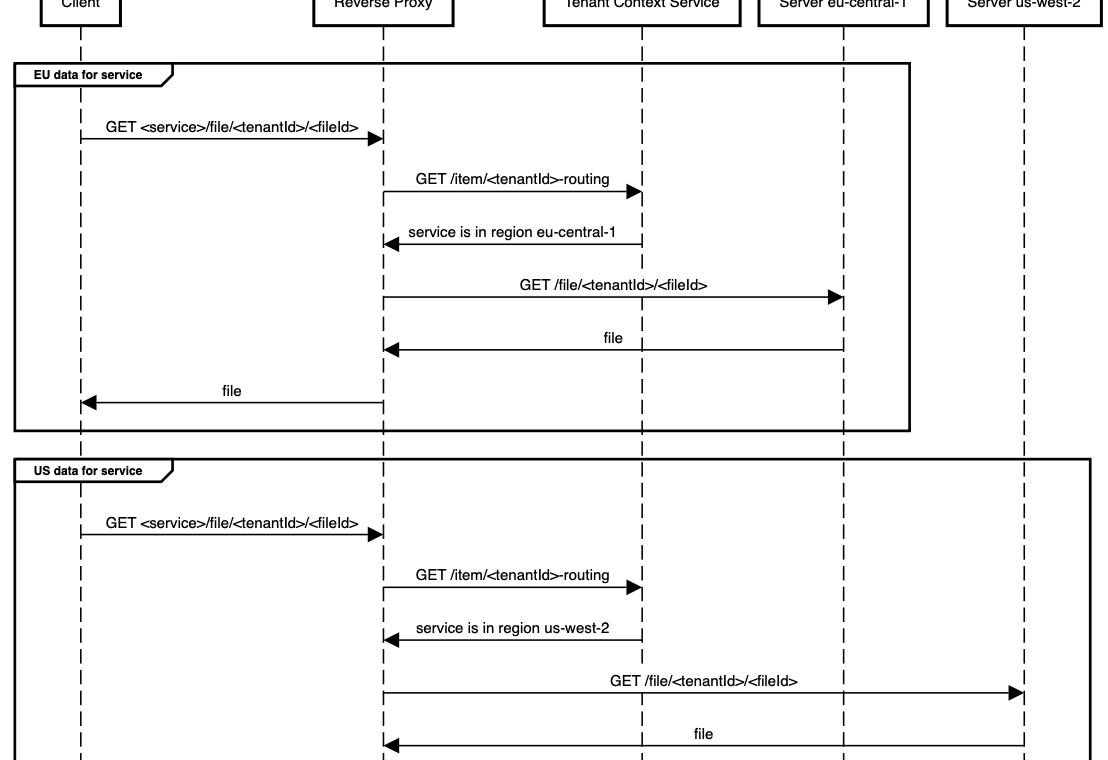
Tenant Context Service: This is a service that we have written about previously. TCS is responsible for providing a set of read-optimised views to corresponding consumers, achieving at least 1ms latency at the 90th percentile and serving millions of requests per minute.
These services will then interact with the other services storing UGC for Jira and Confluence in order to perform the various required operations. We classified these operations into two groups.
- Data plane: Covering the flow of standard requests between services to perform operations, such as reading and writing product data (i.e. Jira Issues and Confluence pages).
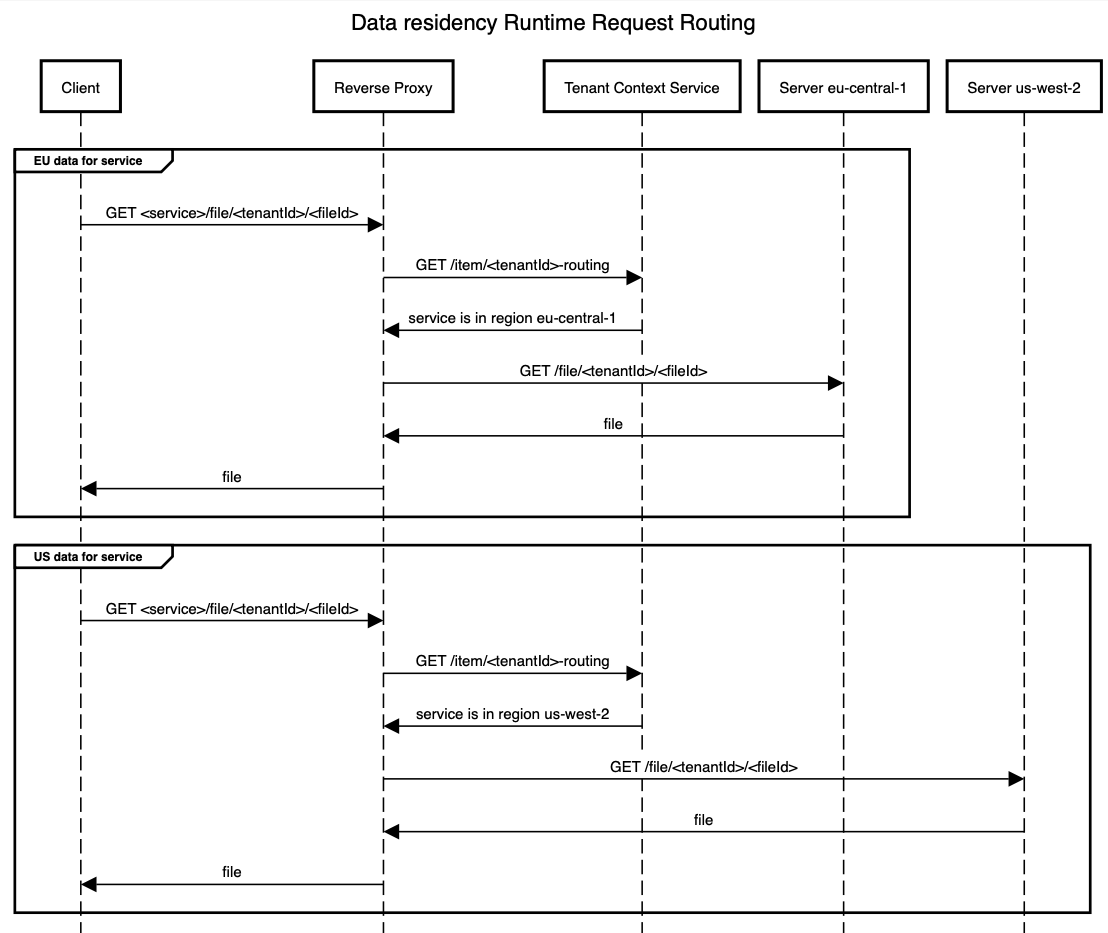
- Control plane: Covering the flow of operations that affected where data was stored across services, such as the provisioning of new tenants (when customers sign up for Jira or Confluence), or migration of data between realms for corresponding services.
Solving the hard challenges
We had been able to define the problems we wanted to solve, create a set of principles to guide our solutions, and put in place the required centralised infrastructure to enable services to participate in our multi-region architecture in a consistent manner. However, we still had many interesting engineering challenges to solve, which we encountered as we progressively onboarded new services to the system.
Challenge 1: Large scale migrations in multi-tenant data stores
The first, and most obvious challenge, is that we have many services that store a lot of data for a tenant. Services like the Jira Issue Service contain all the Issue data for an instance, and media contains terabytes of attachment info. For a large Jira tenant, this could mean storing 5+ million or even 10+ million Issues.
While patterns around supporting high-throughput reading and writing of data vary based on the properties of the underlying database, a large number of our services used DynamoDB – enabling us to establish a consistent pattern on how to handle this high-through.
- Store all entires in DynamoDB along with the Tenant ID, and create a Global Secondary Indexes (GSI) over the Tenant ID.
- Iterate over entries in the GSI to identify all DynamoDB entries, which must be read and written to the target region.
- Read and write entries in parallel from step (2) in batches to the target region.
This approach was quite effective at handling high throughput migrations. However, we found that we would run into problems with throttling of writes to the GSI in the target region, which would slow down data migration (as we would trigger retries with exponential backoffs if we encountered throttling errors).
To address the problem of GSI write throttling, we further sharded the Tenant ID stored in the GSI, and when inserting data, we hashed the partition key to determine which shardId to use. In terms of shard space, the amount of shards per Tenant ID vary per service. In Issue Service’s case, we chose 10, and thus on migration in parallel also queried through those 10 different GSI values. This enabled Issue Service to migrate even the largest tenants between regions in under 60 minutes.
Challenge 2: Rollbacks
One important thing when designing cross system orchestrations is to make sure the rollback / failure case is significantly more likely to succeed than the happy path. This is important because if the failure case is as complicated as the happy path, then a failure in that flow makes it extremely likely the rollback will also fail – which is fairly disastrous if not done with extreme care.
Because of this, our migration process comprised of separating out “copy” and “delete” steps and only calling any “delete” operations after all the copying operations were complete. This lead to some desirable properties.
- When copying succeeds, we can immediately online the tenant again and async delete in the background.
- If delete fails, replaying it at any time afterwards is safe (given it’s no longer live data).
- If copying fails, we can immediately online the tenant, and then attempt to delete the data we may have partially copied.
This means that in all failure cases, the amount of work is never more than “re-online the tenant.”
Challenge 3: Pairing global replication with Data Residency
So far, the examples we’ve given around data replication strategies have assumed that data will be written to a single region for a given tenant. However, while this will be true of many services, there are services who wish to replicate data to additional regions if the configuration is allowed. Typically, we have seen three different approaches to data replication to other regions:
- No replication
- Active-active region pairs
- Global replication
The last option –global replication – is the most interesting. Due to residency requirements these services also had to offer shards only within a given realm.
As an example, let’s consider a simplified version of our Activity Service (which powers start.atlassian.com):
activity-service:
- shard: activity-global
dataRegions: [us-east-1, eu-west-1]
- shard: activity-us-east-1
dataRegions: [us-east-1]In this case the “global” replication is just two regions, and we have a residency shard in the US. This presents an interesting challenge to the migration flow posted above – when going from US → global, you definitely don’t want to delete any data, even though that is a step. Similarly, when going global → US, no copying has to be done, but some deletion does.
Thus, it’s more correct to say that copy is more specifically “addition of data to regions”, and delete is “removal of data from regions”. With this new definition we still maintain all the rollback properties we worked hard for (reverts are still easy!), but it now works for services that may have overlapping regions between shards.
Specifically, in the above example a migration from activity-global to activity-us-east-1 would:
- On “copy” → do nothing, as there is no new regions to add data to
- If failure → delete nothing, as no new regions were attempted to add data
- On “delete” → remove data from
eu-west-1as that is the region not remaining after the migration
Conversely for activity-us-east-1 to activity-global we would:
- On “copy” → add data to
eu-west-1 - If failure → delete from
eu-west-1 - On “delete” → do nothing
This strategy allows services to define very complex topologies while preserving the two-phase commit and rollback properties.
Challenge 4: Event delivery
HTTP and reverse proxies aren’t the only ways that our services communicate with each other. We also employ a large number of async event mechanisms, including SQS / Kinesis. For the most part, these are solved in a similar way – before submitting the message to a queue, check which queue should actually be receiving the message for the tenant.
However, events pose a unique challenge for migration – while HTTP requests are typically < 30s (or in some extreme cases, a few minutes) before they get timed out, events like SQS queues can have messages submitted to the queue hours before actually getting processed.
This becomes a problem if between submitting to the queue and processing, a migration was completed for the tenant. What this meant was, in addition to checking the location before submission on reading the message, the service in question also had to verify that it was still valid to process the message in the current shard upon reading it. If a message was found to be in the wrong region when read, then the consuming service could choose to either discard it or re-route it to the correct region (depending on the processing requirements of the message).
The Results
After all this work, we now have a couple of things: we shipped data residency as well as more performant experiences to customers; and we have a much more robust way to think about multi-region designs using the building blocks we’ve created, which lets us have flexible sharding policies per service that can weigh up solutions in terms of:
- how many regions to deploy into
- how much replication is worthwhile
- how often we need to change the locations
with these being balanced off against the cost (for any service) of doing so.