

Enhancing Rovo Chat with Hybrid LLM Approach
Introduction
Rovo Chat is an AI-powered assistant designed to boost productivity and unlock creativity through a simple chat interface. By leveraging a mix of advanced Large Language Models (LLMs) such as GPT, Claude, Gemini, Mistral, and LLaMA, Rovo Chat transforms the way enterprises interact with information, making it more accessible and actionable. The platform offers three key capabilities:
- Enterprise QnA: open domain question and answering using enterprise searches including data across all your workplace apps such as Jira, Confluence, Atlas, Google Docs, Sharepoint, etc.
- Content Consumption: helping users to consume content efficiently. e.g., “List the action items from this page”
- Content Creation: helping write a draft or polishing a provided draft. This leverages the inherent powerful LLM capabilities. e.g., “write my self review for the past quarter”

Optimizing Performance with a Hybrid LLM Approach
Rovo Chat utilizes a hybrid LLM approach to optimize quality, latency, and cost. In this section, we will walk through how we formulate each problem and chose the best LLM for each task.
Query Rewriting
Problem: In a conversational chatbot, user queries often need refinement to be efficiently processed by the underlying search engine. We leveraged Atlassian’s document search engine which scales to hundreds of millions of users.
Answer: We perform two stages of query rewriting:
- Semantic query: Given conversational history, user context and current query, we generate a
semantic querywhich trims unnecessary bulk, adds context from any previous conversational turns (e.g., coreference resolution), and injects any implied user context (i.e. location, company, time). - Keywords queries: Given the generated
semantic querywe create multiple short keyword queries to maximize document recall.
We optimize queries in several ways:
- Generalizing overly specific questions
- “Can I bring a dog to the office” -> “Office pet policy”
- Breaking down complex queries into multiple simple ones
- “What is the difference in Q2 earnings and Q3 earnings” -> “Q2 earnings”, “Q3 earnings”
- Expanding single queries with synonyms and additional user context
- “How do I get a visa for Sydney?” -> “Sydney visa application”, “Australia visa application”, “Sydney visa requirements for <user’s country>”
We’ve seen a higher answer precision (+10%) and faster latency (-17%) with the query optimization for an internal search QnA query set.

For a simpler problem like this, a small language model such as LLaMA-3 8B performs equally well, being cheaper and faster than heavy LLMs. We started with a large model and moved to progressively smaller models while the document recall gain persisted. On each step, we prompt-tuned each model to match the recall. In addition to recall numbers, looking through hundreds of rewritten queries from our internal dogfooding was the most useful since it’s easy to scan for short keyword queries for engineers and see if each model’s output conveys the same semantics with a larger model.
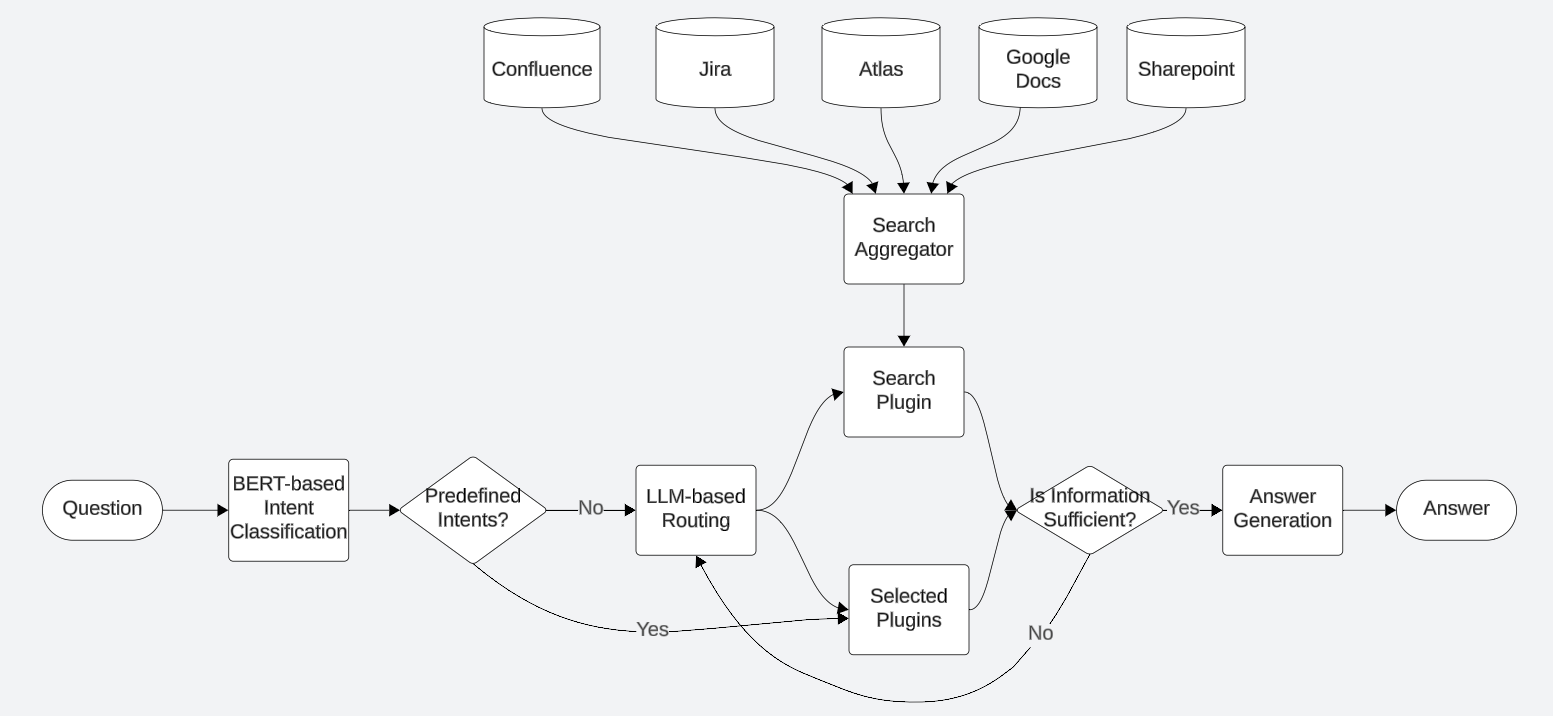
Accurate Information Retrieval through Multiple Plugin Routing
Problem: LLM’s function calling doesn’t work reliably when a user’s intent is ambiguous. Given a user question and a list of available plugins (functions), decide which ones to call to retrieve necessary information to answer the user’s question.
Enterprise data is stored in diverse locations in both structured and unstructured forms (e.g., relational database, search index, key value stores) across products and services such as Jira, Confluence, Atlas, Google Docs, Sharepoint, Slack, User Profile Service, Teamwork Graph, etc. To answer a user’s question, it often requires Rovo Chat to look up several places to decide whether a user’s question can be answered. LLM models often pick one data source and try to answer based on incomplete or irrelevant information in a naive RAG.
Here is a set of example plugins:
Search-QA-Plugin: Retrieve relevant passages from workplace apps like Jira, Confluence, Atlas as well as connected third-party products like Google Docs, Sharepoint, etc.Content-Read-Plugin: Retrieve the contents given a URL.Jira-JQL-Plugin: Searches for Jira issues based on a set of filters using JQL (Jira Query Language), supporting a structured query.People-Plugin: Find a person’s profile information, recent activities, and their close collaborators.Page-Search-Plugin: Finds a Confluence page or blog post using CQL (Confluence Query Language), supporting a structured query.
Answer: we placed more orchestration around LLM’s function calling to increase the chance of retrieving relevant information to user’s question from diverse data sources.
- BERT-Based Intent Classifier: we trained binary intent classifiers for simple and frequent intents (e.g., whether a question is about the current browsing page) for a faster latency and a higher accuracy. We seeded the training data with our internal dogfooding queries and used a LLM to generate 100K training data.
- Search in Parallel: hitting search indexes while looking up other data sources since the search indexes are the largest source of information.
Here is an example showing the benefit of multiple plugin routing for Rovo chat. By applying multiple plugin routing, Rovo Chat summarize the project’s core objectives instead of detailed enumeration of Jira tasks.

We evaluated 10 different LLMs for multiple function calling task for a benchmark of 226 queries from an internal dogfooding. The correct plugins are human-annotated and they could be multiple. Selecting any of the right plugins are marked as correct. We’ve experimented with a native function calling as well as in-house react prompt with a few shots. The plugin accuracy ranged from 73.1% ~ 94.2% on the benchmark and we use the model with the highest accuracy. As LLMs become stronger at multiple functions and we add more functions, we constantly evaluate new LLMs and switch to the best performing model.
Ensuring Relevance with Plugin Helpfulness Verification
Problem: Even if the correct plugin was selected and the right arguments was fed, it’s possible that underlying components may have made mistakes. A search engine could return irrelevant information or an entity linking service might have failed to connect a person name “Steven” to the right entity in a team work graph. When irrelevant information is retrieved, LLM is likely to generate incorrect answers.
Answer: we placed a SLM (Small Language Model) to check whether the retrieved information is relevant to a user’s question before feeding them into a LLM to generate an answer. We experimented with 3 different SLMs and their accuracy ranged from 88% ~ 98.9% for an internal human-annotated data set of 91 queries.
Here’s an illustrative example of Rovo Chat’s response to the question “who is CRO” before and after the plugin helpfulness check.

Generating Accurate and Contextual Responses
Problem: Given collected enterprise information, generate accurate and contextually relevant answers. This is the problem where the most powerful LLMs could show its power.
For measurements, we created an evaluation set from our internal dogfooding; ~241 queries consisting of the three scenarios: enterprise QnA, content consumption, and content generation. The data set is in the format of (query, user context, plugin outputs, ground truth answer). We iteratively collected the ground truth answers as we develop Rovo Chat either from an earlier version’s correct answer (labeled by humans) or humans wrote ground truth answers. It contains both positive and negative examples.
- Positive example (83%, 199/241 queries): plugin outputs contain sufficient information to answer a user’s question and LLM is expected to answer a response that is semantically similar to the ground truth answer.
- Negative example (17%, 42/241 queries): plugin outputs do not contain sufficient information to answer a user’s question and LLM is expected not to answer instead of using its internal knowledge to answer the question.
Answer: we’ve evaluated 6 different LLMs and they achieved 93.7% ~ 81.3% accuracy on this task. Note that we froze the plugin outputs in this evaluation to isolate the measurement of answer generation task from function calling and retrieval accuracies. We’ve observed generally newer and stronger models in the industry outperform the previous versions so we have been constantly testing and switching to stronger models as they become available.
Automatic Prompt Tuning: We implemented automatic prompt tuning to iteratively refine prompts, ensuring responses are easy to read and contextually relevant. This process involves using techniques like those described in this paper to improve the quality of generated answers. We reviewed queries and answers that are generated by our teammates and used the judgments to fine-tune prompts, ensuring that the generated answers align closely with human expectations and are easy to understand.

Assessing Rovo Chat Quality with a LLM Judge
Problem: Evaluating the quality of responses generated by LLM can be challenging as they are long. Computation based methods like BLEU, ROUGE, BERT score are highly sensitive to reference answers. Human evaluation is slow and expensive to repeat frequently. Having a high quality evaluation is critical to make sure Rovo Chat is consistently improving on every version.
Answer: For scalable measurement of Rovo Chat’s quality, we use a LLM judge. The task is to judge whether an Rovo Chat’s response is semantically similar to the reference answer for a user’s question. This binary labeling simplifies the evaluation for both humans and LLM evaluators, compared to using a range of scores where the calibration of scores becomes another problem to solve.
- Input: (user question, reference answer, Rovo Chat response)
- Output by LLM judge: (justification, correct or incorrect)
For the measurement, we’ve collected ~800 question and reference answer pairs from internal employees. Here is an illustrative example of reference dependent evaluation where a user asked “how do I get on wifi?”. While Rovo Chat’s answer answers how to connect to Wifi in general, the enterprise user was asking about their corporate network connection, so the LLM judge marked the Rovo Chat’s answer as incorrect. This is difficult to judge even for humans without a reference answer.

We also judged the quality of LLM judge by comparing the overlapping judgments between humans and LLM judgements. We evaluated 6 different LLMs and their agreement rate with human judgements range from 79% to 95% and used the model with the highest overlap. The best model still has a 5% disagreement with human judgements but this is an acceptable noise as even humans won’t have 100% agreement with each other.
Conclusion
We used a mix of LLMs to optimize the quality while keeping the latency and costs at a reasonable level in building the Rovo Chat. This strategic approach has enabled Rovo Chat to deliver precise and contextually relevant answers, enhancing user experience and productivity. By leveraging automatic prompt tuning, we have refined the system’s ability to generate easy-to-read responses, ensuring that users receive information that is both accurate and accessible.
The field of Gen AI is advancing fast. We will continue to integrate the latest advancements of LLMs into Rovo Chat to enhance user’s productivity by handling more complex queries and highly contextual questions. We will continue to measure on every turn to deliver the best experiences for our users.