
At Atlassian, there are many situations we need to move large amounts of data between different systems – validating and transforming them in-flight. What is unique about Atlassian’s use cases is that several require data pipelines to be entirely provisioned at run time.
Normally, we’d consider frameworks such as Apache Flink to move and transform data at scale – effectively through a streaming ETL (Extract, Transform, and Load). ETLs have been around for decades – we’ve all worked with or benefitted from them.
But ETL systems are usually long-lived, always ready for new data. That’s why this requirement of provisioning at runtime required a new approach and led us to build the Lithium Platform, which we call an ETL++. This is because it includes features traditional ETLs do not, including:
- Dynamic and ephemeral pipelines
- Sidelining and In Progress remediation capabilities
- Tenant level isolation
- Proximity to data and domain logic
So, why is provisioning at run time so critical that we developed Lithium?
Consider:
- Migrations (server to cloud or cloud to cloud) are user-initiated, and the data movement happens within a fixed period of time. Thus, the pipeline needs to be set up when the user is requesting the data movement and needs to be brought down as soon as the movement completes.
- Scheduled backups are triggered on fixed schedules (e.g. once a day at 01:00 AM) and require the data movement pipelines to be created to do the backup. Having the pipelines run forever would incur significant additional costs, leading us to require closing them down after backups are complete.
- Stream processors must be embedded directly in product and platform services to enable in-process access to service context to meet functional requirements along with throughput goals.
- Our pipelines require coordination amongst sources, transforms, and sinks that exist in different product and infrastructure services.
These requirements help support core product features that deliver a world-class customer experience. We could not compromise on them.
That is why we built the Lithium Platform. It is 100% event-driven and is built on Kafka and Kafka Streams. Let’s take a look at how it’s designed.
Workplans: Dynamic and ephemeral streaming pipelines
The data pipelines in Lithium are called a Workplan and they contain all the information about the ETL components (and other information we will see later) required to run the pipeline. A workplan is dynamically provisioned to serve a data movement request and is deprovisioned as soon as the movement finishes, making it “ephemeral”.

Everything in yellow in the above diagram is dynamically provisioned and ephemeral including the Source, Transform, Sink, and the Kafka topics between them. Workplans typically consist of three primary types of processors, with a potential fourth type that we will delve into later:
- Source (a.k.a Extract) – The component responsible for sourcing the data from the source system and sending it into the pipeline
- Transform – The component that transforms and/or validates the incoming data so that it is ready to be ingested by the destination system
- Sink (a.k.a Load) – The component responsible for sending the data into the destination system
But how are these workplan processors hosted/deployed? Let’s see in the next section.
Bring your own host

The Lithium platform implements a Bring your own Host (BYOH) model. The Lithium processors are housed within services. These services are owned by the consumers of Lithium, for example Jira and Confluence, that have use cases for data movement. They just need to integrate the Lithium SDK and write their own custom processors to be provisioned on demand. The Lithium SDK is a Java library that abstracts out all the Kafka-related processing such as discovering Kafka clusters, creating Kafka topics, publishing to and consuming from those Kafka topics, authentication, and more. The SDK provides very simple APIs to the consumers to interact with the platform.
Consumers of the platform just focus on writing their processing logic and don’t need to worry about how the underlying platform works. This gives them the ability to host their processors closer to the data and the domain logic, one of the key advantages of Bring your own Host model.
Heterogenous distribution

Each processor of a Lithium work plan can be hosted in a different kind of service, and potentially in different instances of a service. Each processor type is hosted in an appropriate service instance based on the type of processor, business logic, and data locality. This results in a work plan where different processors are hosted and owned by different services.
Pipeline isolation

Since all Lithium workplans are dynamic and ephemeral, data pipelines operate in isolation from each other. Although they may share local service resources, they DO NOT share processor instances of Kafka topics. Each data pipeline has its own set of Kafka topics, processor types, and runtime parameters. This isolation is also the enabler for core capabilities such as pause, resume, rewind, and remediation. The pipelines can be paused and resumed at will without impacting other workplans. This also allows us to guarantee that the data of each tenant is isolated in its own set of Kafka topics.
Workplan spec

Every work plan requires a specification which defines all the parameters for its execution. A specification contains the details about source, sink, and data processors (or transformations). It also contains other parameters such as parallelism, retry attempts, etc.
Each of the processor sections contains the processor definition as well as the number of workers required to run this work plan. The parallelism defined in the work plan spec is used to decide the number of partitions of the work plan’s Kafka topics. This, and the number of workers defined in the spec, allow a work plan to process the data in parallel.
Control plane and data plane
The Lithium platform can be divided into two logical boundaries, a control plane and a data plane. The control plane can be considered as the nervous system of the platform and is responsible for handling several responsibilities for the platform (we will cover this in the next section). The data plane contains all the service instance integrations with the Lithium control plane using the Lithium SDK. These service instances are called resource providers because they are responsible for providing resources for a work plan through the SDK, as explained in this section. Also, the data plane is responsible for the actual data movement within a pipeline using the provisioned Kafka topics and different types of processors hosted by the data plane resource providers.

As can be seen in the above diagram, control Plane and data Plane communicate with each other using a set of Kafka topics:
- Control plane events – This is used as a broadcast channel by the control plane to announce important updates such as a workplan creation request, provisioning request, or a termination request. Each message in this topic is received by every resource provider instance in the data plane.
- Data plane events – This is used by the data plane components (resource providers) to send events to the control plane
It is worth noting that since the Lithium SDK abstracts all the Kafka processing from its consumers, they are not at all required to write any implementation related to the control plane and data plane event handling.
The external world connects to the Lithium Control plane using a set of input and output topics.
- Control Plane inputs – These are a set of topics which the control plane uses to receive instructions from the clients of Lithium. As shown in the diagram above, there can be many types of clients which might send commands to the control plane to perform certain tasks, such as start or stop a job.
- Control Plane outputs – These are a set of topics where the control plane puts all the meaningful events for its clients. These events can be the responses for the issued commands, or lifecycle events for the submitted job. For example, a client when issuing a command to create an ETL job might be interested in knowing if the job was created successfully as well as all the updates related to the job.
Control plane

Let’s dive deeper into the control plane to understand its major responsibilities, which are:
- Workplan management: The control plane tracks the statuses of all workplans running on the platform or which are queued for execution and also manages the transition of state and statuses for each of these workplans. We do that using the Kafka Streams aggregator. It’s a reliable method of getting the data, which is going to come out of a change log topic in Kafka, manipulating certain pieces of that data based on messages that have come in through the data plane event topic, and handing it back to Kafka through a compacted workplan topic. This compacted topic is the source of truth for workplan state and statuses, which are completely managed using Kafka.
- Resource provider management: The other responsibility of the control plane is to manage all the registered resource providers. As shown in the above diagram, resource provider management looks exactly the same as workplan management.
- Workplan and resource provider materialization: We materialize this information into a Postgres database, which is designed for handling the complex queries on the workplan and resource providers. However, the source of truth for both workplans and resource providers is in Kafka topics. We don’t rely on the information in the materialized store, which is only used for query purposes.
- Topics manager: This part manages the creation and deletion of Kafka topics used by workplans, along with the roles required to connect to these topics, which we will discuss in more depth later in this post.
Anatomy of a resource provider

Let’s dig a little deeper into what’s inside a resource provider. As discussed previously, a resource provider is in communication with the control plane. It receives all the events from the control plane, such as workplan updates, control plane heartbeats, and more, and emits events back to the control plane through the data plane event topic. Examples of such events can be resource provider heartbeats, workplan heartbeats, bid events (explained in the subsequent section), and more. It is also responsible for provisioning in-process instances of the processors for workplans if the host hosting the resource provider is participating in the workplan.
The resource provider and the processors follow an actor model enabling them to use asynchronous messages internally, thus mirroring the way we do things externally using Kafka. The processors do not communicate with the control plane at all. They only communicate with the resource provider and the topics provisioned for a particular workplan.
Workplan auctioning and provisioning
Okay, we have delved into different platform components and work plan specifications. Now, let’s explore how to initiate the definition of a work plan and determine the involvement of resource providers in the work plan. Remember that resource providers are responsible for provisioning processors for a workplan. For some of our use cases, our clients have hundreds or even thousands of participating nodes. So which one gets to actually do the provisioning, and has capacity to do all this? The model used in Lithium platform to manage this is auctioning. As the name suggests, it is exactly the way an auction works where multiple participants bid and then the winner is chosen.
The way this works is that the control plane is not responsible for deciding that a particular service host should provision or participate. This knowledge is solely held by the service hosts. Does it have capacity? Does the resource provider know about the tenant ID for data migration? Is it responsible for managing the data for that tenant? Is it aware of the processors that are described in the workplan? All of that information is known locally in the data plane hosts. So, whenever a workplan request is submitted on the control plane event topic, the resource provider evaluates the workplan and sees that the workplan is in auctioning phase and evaluates whether it can participate in the workplan. If yes, it sends a positive bid back to the control plane through the data plane event topic. Let’s walk through an example as shown in the next diagram.

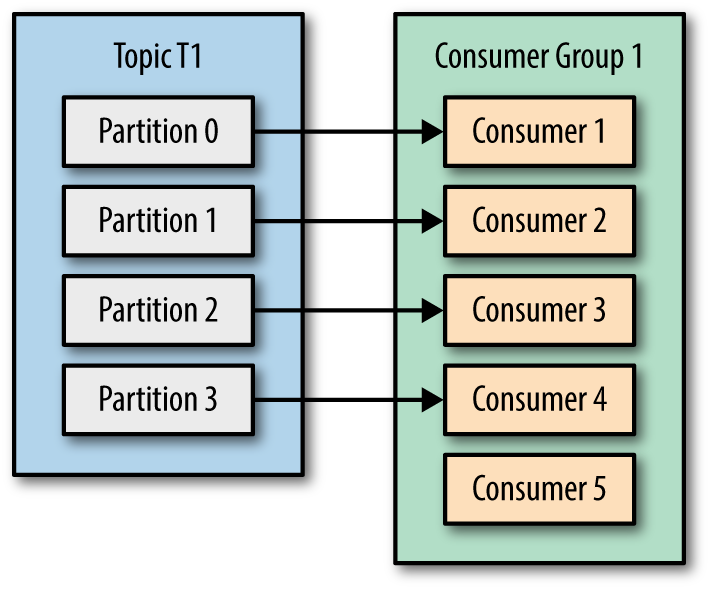
In the above example, a work plan is created using a parallelism of 4. It requires a source of type sourceB, transform of type transE, and a sink of type sinkY with their configured min and max workers. Please note that there is no inherent benefit in defining max worker count which is more than the configured parallelism due to the way Kafka consumers work in a consumer group. This article explains it further, but the important section is this:
Let’s say we have 5 consumers in the consumer group which is more than the number of partitions of the TopicT1, then every consumer would be assigned a single partition and the remaining consumer (Consumer5) would be left idle. This scenario can be depicted by the picture below:
Coming back to the workplan auctioning diagram, on the right side we can see multiple resource provider instances of each processor type: a few hosts hosting sourceA, a few hosting sourceB, and so on. When the control plane puts the workplan 001-002 into the control plane event topic in the auctioning status, all the resource providers get this event. However, only the resource providers that can participate in this workplan (marked in red) send a positive bid back to the control plane. The resource provider’s eligibility to participate in a workplan is determined by various factors:
- Does this resource provider understand the processors defined in the workplan spec?
- Does this resource provider have the capacity to take on more work?
- Is this resource provider part of the shard that handles the tenant’s data?
After the auction window closes, the control plane aggregates all the positive bid events for this workplan and adds them to the list of bidders in the workplan. At the moment, these bids are just an indication and not a commitment from the resource providers.
Many resources can bid for a workplan, whereas only a few may be required to run the workplan. The control plane may receive two source bids but only needs one resource to run a workplan, for example. The control plane then reconciles the bids and chooses the winning bidders depending on their individual capacities. After obtaining a sufficient number of winning bidders, the control plane then adds these processors in the resources section of the workplan. The provisioned flag is set to false as the resources are not provisioned yet.
But before we actually provision anything, we need topics. So, the control plane then moves the workplan into topic provisioning status where the workplan topics are created.

The control plane’s topic management module then communicates with the Kafka cluster to create work plan specific topics, as shown in the above diagram, and adds them to the topics section of the work plan. At this point, any processor will be free to subscribe to or publish to these topics as they exist now. This is what happens in the resource provisioning phase.

We can see that in each of the service hosts that won the bidding process, they’ve now provisioned an instance of the appropriate stream processor and the provisioned flag for these resources is set to true. Since we have now acquired all the resources required for this work plan, we can start running this work plan. If any of the above phases fail to acquire a sufficient number of resources, the work plan will be retried again after some delay, as defined in the deploy section of the work plan spec.
Here is a simplified view of this work plan after going through the provisioning process.

On the left side, we have one instance of a source because we asked for one min and max source worker. This source extracts data from some data source that it understands and feeds the data as messages into the input Kafka topic. In the second step, we see that we had asked for two transformers, and we were able to get them. This splits the workload between these two processors by assigning an equal number of topic partitions to them. It is worth mentioning is that transformers and validators are built using Kafka Streams topologies. One of the really important considerations here is that the platform should ensure that it does not produce duplicates in the middle. To achieve this we use Kafka Streams and its transactional guarantees and exactly-once semantics.
The messages then go to the output topic of the work plan and are received by 4 hosts which have provisioned the sink processors for this work plan. This is because we had requested four sink workers to equally distribute the work across them. The sinks then write the data into the destination data storage.
In the above example, we were able to acquire the max number of workers for each type, but it’s worth discussing what happens if that’s not the case. For example, if we could only partially obtain the resources, or some of these processor nodes (resource provider hosts) come and go, leaving work plans with less than the optimal number of workers.
In the above example, we had requested two transformers, and the work plan was able to acquire them. This work plan is called a fully provisioned work plan. Assume that one of the hosts crashes, leaving the work plan with only one transformer. Since we had defined one min transformer worker for this work plan, it can still run with a nominally provisioned status. In this case, Kafka partition assignment will kick in, and all the partitions of the input topic will be assigned to one available host. The control plane detects this through the processor heartbeats sent by these resource providers and appropriately sets the status of the work plan. If the remaining one transformer also goes down, this work plan is now considered unviable and the control plane stops the work plan and sets the status to underprovisioned. This instructs all the processors to pause themselves and wait for the resources to become available again. At this stage the work plan enters into a secondary auction and tries to acquire new resources to revive the work plan. This auction works exactly in the same way as the initial auction, and the resource providers bid if they have capacity to take up the work.
“Rewinding” the source processor

We discussed earlier that the source puts the messages immediately into the input topic of the work plan. The source processor collects the data from its data source but sends it to what we call an ingress topic. A Kafka stream topology called an usher picks up the data from the ingress topic and sends it into the input topic. While this may seem like an unnecessary extra step, this enables us to add one of the core features of Lithium work plans, the ability to rewind. In a lot of cases, data extraction from the data source is expensive, and we would want to avoid that if we just want to start over and rerun the work plan. In the case of Lithium, the extracted data remains in the ingress topic, and when the rewind is requested, the usher stream reads messages from the beginning of the ingress topic and redelivers them to the input topic with a different stream generation number. All the existing data in the pipeline with the previous stream generation number is then filtered out by each of the processors.
The transform processor chain

We discussed earlier that a work plan can have a transformer and/or validator, but this actually is a chain of transformers, also called a processor chain. Each element in this processor chain is a fine-grained transform and validate function, specified in the order that they are meant to pass data down the line. All of these processors live in one host and are implemented as a single Kafka Stream topology, and the wiring of all these processors is done under the cover by the Lithium SDK. Outside the Lithium platform, it is basically messages in and messages out, but inside there are multiple functions chained together.

There might be use cases where different transformation functions need to live inside different services because of their proximity to the required context or business domain logic. A Lithium workplan supports the notion of multiple transformation chains which can live on multiple services. The control plane chains them together by creating all the intermediate Kafka topics.
Multiple sink processors

Lithium supports the definition of multiple sink processors in the workplan specification. This means that the data generated on the output topic can be used by various services employing different types of sinks. In the provided example, the workplan specification outlines two types of sinks along with their respective number of worker configurations. Within the pipeline, two types of services are involved in this workplan, each providing the specified sinks. sinkA operates on two hosts, as the maximum worker configuration is set to 2, while sinkB runs on a single host for the same reason. Both sets of sinks receive the same data and have the option to process it if deemed relevant or disregard it.
Internally, multiple sinks are managed through distinct consumer groups assigned to each sink type. In the aforementioned scenario, all data from the output topic is distributed among the two sink hosts of type sinkA due to their membership in the same consumer group. Similarly, all data is directed to the singular instance of sinkB since there is only one consumer within this consumer group.
Workplan state processor

Until now, the data pipeline processors have been entirely stateless. However, many use cases benefit from the ability to render state information.
There are various use cases for rendering state on a work plan, one of which involves progress tracking and marking a work plan as Done. Lithium is unable to detect when a work plan is completed because it is entirely controlled by the consumers; for example, it is unknown if the source has extracted all necessary information. Therefore, the state processors can be used to track the progress, such as monitoring how many entities have been extracted versus how many have been loaded into the definition, determining the percentage of entities that have been processed, or marking the work plan as done when all entities have been extracted (a source can produce a state) and when the sink has loaded all data (a sink can emit a state).
This is achieved by an additional data plane processor called a state processor, making it the only stateful processor in the work plan. These state processors are provisioned in the same manner as any other type of processors. Each of the other processor types can publish custom state messages to the data pipeline’s state event topic, which is once again a provisioned topic for the work plan. The state processor’s custom state functions process those messages and maintain an aggregated state. This is accomplished using Kafka Streams aggregators, providing reliable data pipeline state processing. The custom state functions are defined by the state processor owners and declared in the work plan spec, which outlines the aggregation logic for the Kafka stream. It is important to note that only one worker is required for any work plan’s data pipeline. Therefore, the state event topic is a single partition topic. The state processor utilizes a punctuator to periodically send the entire rendered state to the lithium control plane, where work plan management uses it to update the work plan’s custom state. Subsequently, this action triggers the work plan event to be broadcast to all data plane resource providers.
Sidelining and remediation

Data sidelining refers to a process where data that fails validation in the pipeline is diverted to a specific “sideline topic” within a work plan. Valid data continues downstream while failed data is held at a gate within the sideline topic. Initially, the gate is closed, keeping the data in the sideline topic. This gate is created using a Kafka stream topology, and pausing the topology effectively closes the gate. If the number of failed entities exceeds a set limit on the work plan specification, the control plane halts the work plan. In this scenario, all processors pause, awaiting the control plane to resume the work plan.
When does the control plane restart the work plan? The key lies in one of Lithium’s core features, known as “In Progress Remediation.” Platform users can examine failed data and rectify issues by introducing new transformers to the active work plan (hence the term “in progress remediation”). This action leads to the addition of new transformers to the existing processing chain, triggering a work plan update. Consequently, the update opens the feedback gate, allowing both sidelined entities and new data to undergo processing using the updated transformations.
Bring your own topic

There may be use cases where the consumers of work plans need to send some data beyond the work plan boundaries to Kafka topics which don’t have the same lifespan as that of the work plan’s topic. The data might be required to land in some long-lived topic for further processing by some downstream system. Lithium provides the concept of external topic integration which allows consumers to inject their topics in the work plan processors, and the Lithium SDK provides very simple APIs to publish to these topics. These topics aren’t owned by the Lithium platform and are managed by the services requiring the integration.
There are several use cases that benefit from this feature and have already been adopted inside the migration workflows. One such use case is ID mapping: For server to cloud or cloud to cloud migrations, ID’s of Jira entity references (from the source system)need to be resolved with the IDs of the entities in the destination system. For example, consider this example Jira Entity A in the source system. The entity bearing the ID 123 has a reference to the issue id 456. When the issue is migrated to cloud, the issue ID might change and require the new ID of this issue to be used in the Jira Entity A. This requires the transformer in the pipeline to have knowledge about the mapped IDs for all the entities. This is achieved by utilizing an external topic in the Sink processor where the sink sends the ID mappings after it has written the records to the destination database. The external topic is then fed back into the transformers to enrich the entities which depend on these mapped ids.
Jira Issue
{
"id": 456
}
Jira Entity A
{
"id": 123,
"parentIssueId": 456
}
// After Migration
Jira Issue
{
"id": 789
}
Jira Entity A
{
"id": 123,
"parentIssueId": 789
}Platform in action
The Lithium team have performed multiple rounds of Scale and Performance testing of the platform and have observed extraordinary results.
| Kafka Cluster | num_broker_nodes=12 |
| Workplan Parallelism | 6 |
| Number of Source, Transform and Sink workers per workplan | 1 |
| Total number of Workplans | 100 |
| Entities per workplan | 5 Million |
| Size of each entity | 1 KB |
| Total data moved | 500 Million, 500 GB |
| Total time taken | ~ 7 mins (420 secs) |
| Achieved throughput | ~ 1.2 Million/sec, 1.2 GB/sec |
The platform is fully operational in the production and has been serving all Atlassian customers in use cases such as server to cloud migrations, cloud to cloud migrations, backup and restore etc.
Summary
At the core of it, Lithium is a streaming ETL platform, but what makes Lithium truly unique are its niche set of features. Its dynamic and ephemeral nature gives the consumers the flexibility to create the ETL pipelines only when they are required. The hosted data plane gives the ability to the consumers to write the data processing logic closer to their data and business domain logic to achieve maximum throughput. The very important sidelining and remediation enablers powerful capabilities for monitoring data validation failures and fixing them in flight.
It has been a truly rewarding journey to work on this platform from its inception to having it running in production, working with some of the greatest engineers I have ever met.