
Scaling is a nice problem to have. It usually means your product is successful and there is more demand than you can offer.
Scaling is a challenging problem to have. It usually means that a beautiful design you implemented just recently no longer works and significant parts of your system may need a redesign.
Scaling is a time-sensitive problem. Approach it too early and you may end up wasting efforts moving in the wrong direction. Approach it too late, and you could be caught in never-ending fire-fighting and forced into sub-optimal short term solutions.
Recently we finished “Account Sharding” – a project to re-design our internal cloud platform to address scaling problems. We want to share history behind it, decisions we made and some implementation details.
What is the Atlassian PaaS?
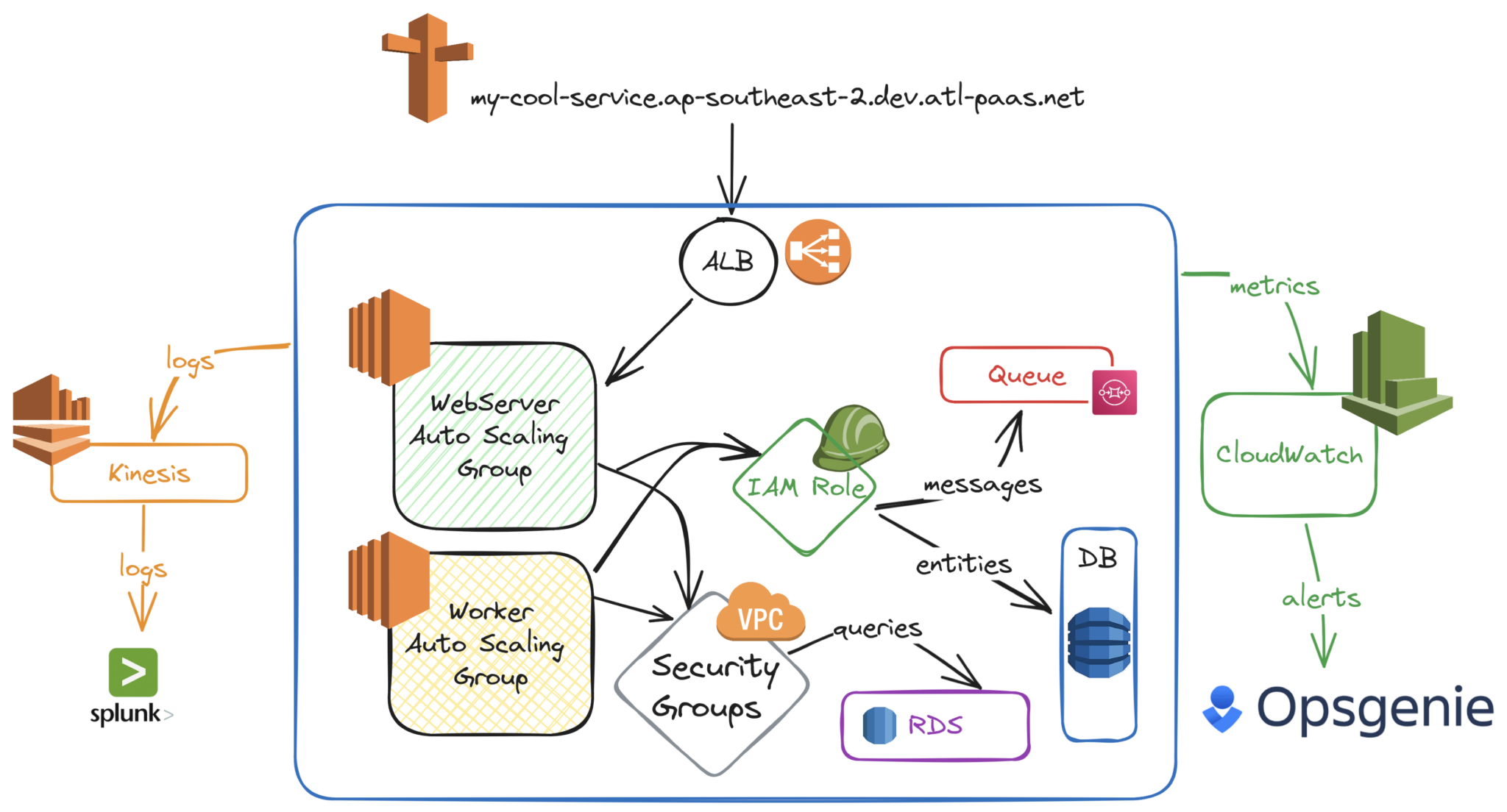
Before we start talking about scaling the Atlassian PaaS (Platform as a Service), let’s do a quick recap on what it looks like. The Atlassian PaaS is called Micros. It deploys and runs the majority of our cloud services. It’s an abstraction on top of AWS, allowing our developers to focus on products and features for our users and not underlying infrastructure. That also allows our PaaS teams to focus on scaling infrastructure to accommodate ever-growing needs of our products.
The Micros contract is very simple – you provide a docker image and list of resources needed, and we give you a highly-available, resilient and secure infrastructure behind a single DNS entry point.
There are currently more than 2000 services running in our production environments with around 5500 service deployments daily (or 1 deployment to production every 15 seconds).
If you want more details, read this, still mostly accurate, blog from 2019: Why Atlassian uses an internal PaaS to regulate AWS access – Work Life by Atlassian .
Why do we need account sharding?
Up until few years back when we started the Account Sharding project, all of our production workflows were running in 3 giant AWS accounts. What do we mean by “giant”? We can define it from an operational point of view as regularly hitting all kinds of limits – soft and hard, resources and APIs. To better understand this, let’s deep dive into AWS accounts limitations.
Firstly, there are 2 types of account limits in AWS: soft limits and hard limits. Soft limit means it can be increased by request via AWS Service Quotas service. Usually, it applies to a number of resources which can be provisioned in a given region in account. A few examples of soft limits are:
- Number of EC2 instances
- Number of EIP (elastic IP) or ENI (elastic network interface)
- Number of memcached clusters
A hard limit means it can’t be increased. A few examples of hard limits are:
- Number of IAM roles in account
- Number of S3 buckets in account
- Number of hosted zones in ACM certificate
Another dimension is “what the limit is applied to”, which can be condensed down to:
- How many resources (such as EC2 instances, IAM roles, Redis clusters) can live in a single account
- AWS management APIs – how often you can call a specific AWS API before getting rate-limited
Hitting resource limits could be painful – it slows down the AWS console experience and requires constant support load to increase soft limits. However it is something one can live with.
Hitting API limits is another story. First of all, most of these are hard limits and can’t be increased. Secondly, many of them are not disclosed at all – we can only observe the effects of being rate limited, but don’t know where the limit is. For example, let’s imagine AWS CloudFormation has a hard limit of 5 requests per second (actual limit is unknown) for DescribeStacks API. So, if 6 developers logs in into AWS console to view CloudFormation stacks at the same time, 1 of them will get rate limited and would need to retry. What if there are 10 developers – or 1000’s of developers, like we have at Atlassian?
Our PaaS is also utilizing the same APIs. Each time a service is deployed, there are multiple calls to AWS STS, KMS, CloudFormation, Route53, EC2 and other AWS services to provision or modify resources. And as I’ve mentioned before, there are over 5000 deploys happening daily and they are not evenly distributed. For example, there are spikes of activities at the beginning of the working day because teams tend to have scheduled deploys for their services.
We generated the graphs below to better understand the scale of the rate-limiting problem in an early phase of the project. They visually represent all API calls we made to AWS CloudFormation DescribeStacks API within a 24 hour interval, based on data available in AWS CloudTrail logs.
The first one represents our development account:
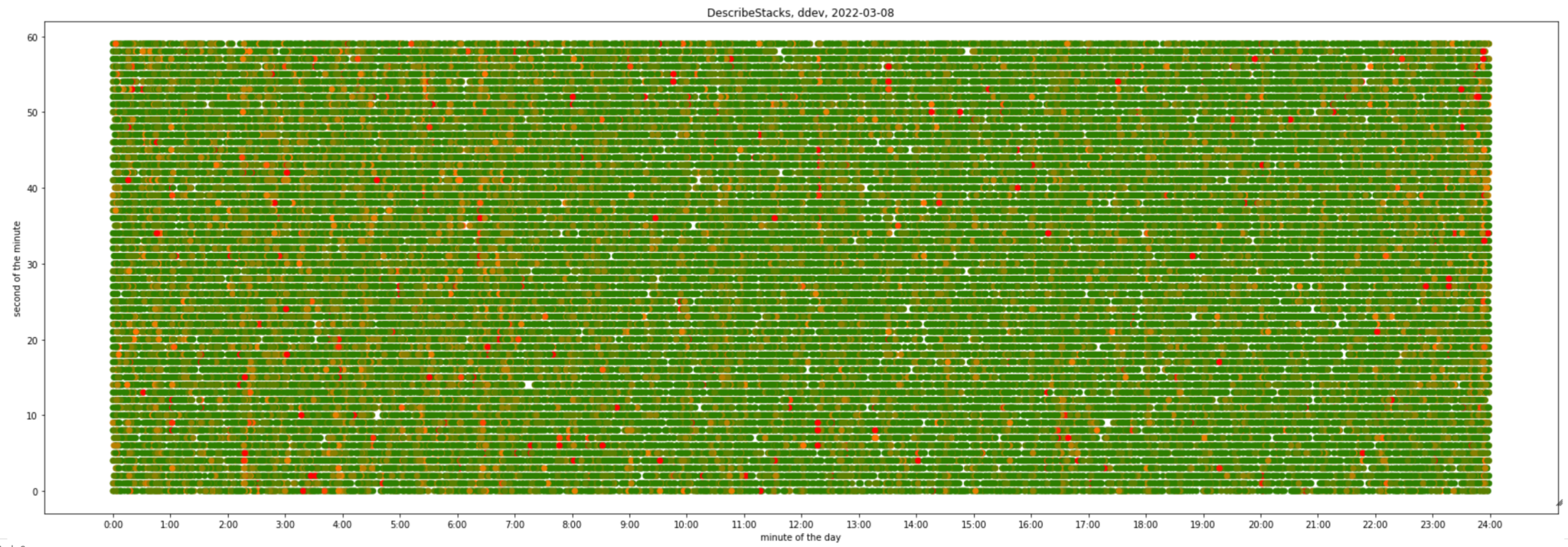
It might be hard at first to read a graph with 2 time axes, but you eventually get used to it. Let’s take a single point with coordinates x=04:00, y=30. It shows number of requests being made at 04:00:30 UTC, from green (1 request), to shades of orange (2 to 10 requests) to red (11 or more requests). There are also empty (white) areas representing 0 requests.
What can we see here?
- Load is evenly distributed across a 24 hour time period.
- There is slightly more load from 0:00 till 7:00 due to Sydney business hours, where some of our largest engineering teams are based.
- There are regular vertical clusters – they correspond to additional API calls due to synthetic deploys and cleanups (we’ll see more obvious examples of this in other environments)
Let’s compare it with one of our least-used environments – eu-central-1 region in one of our staging accounts:
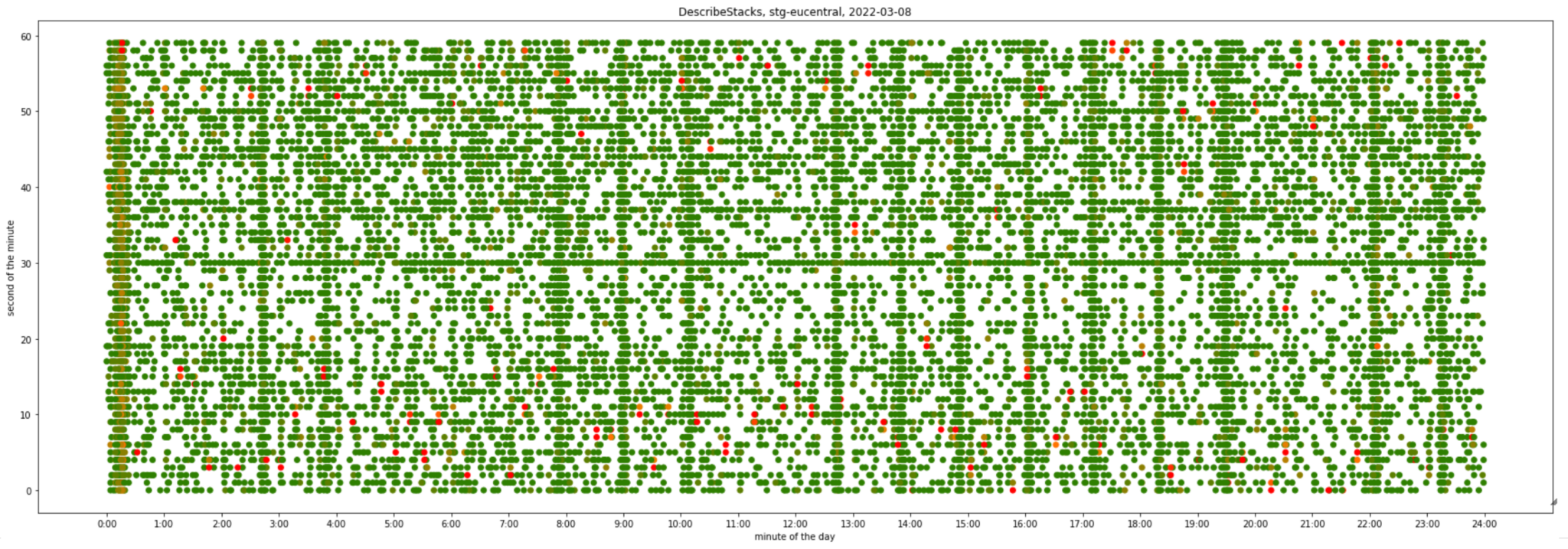
- It’s very defused and mostly green
- There is visible activity at 00:00 (Sydney morning) from people triggering pipelines to deploy and test in staging
- There are very visible vertical clusters – synthetic deploys and cleanups stand out clearly when there is less “natural” activity
Finally, one of our busiest environments – us-east-1 region in production used to look like this:
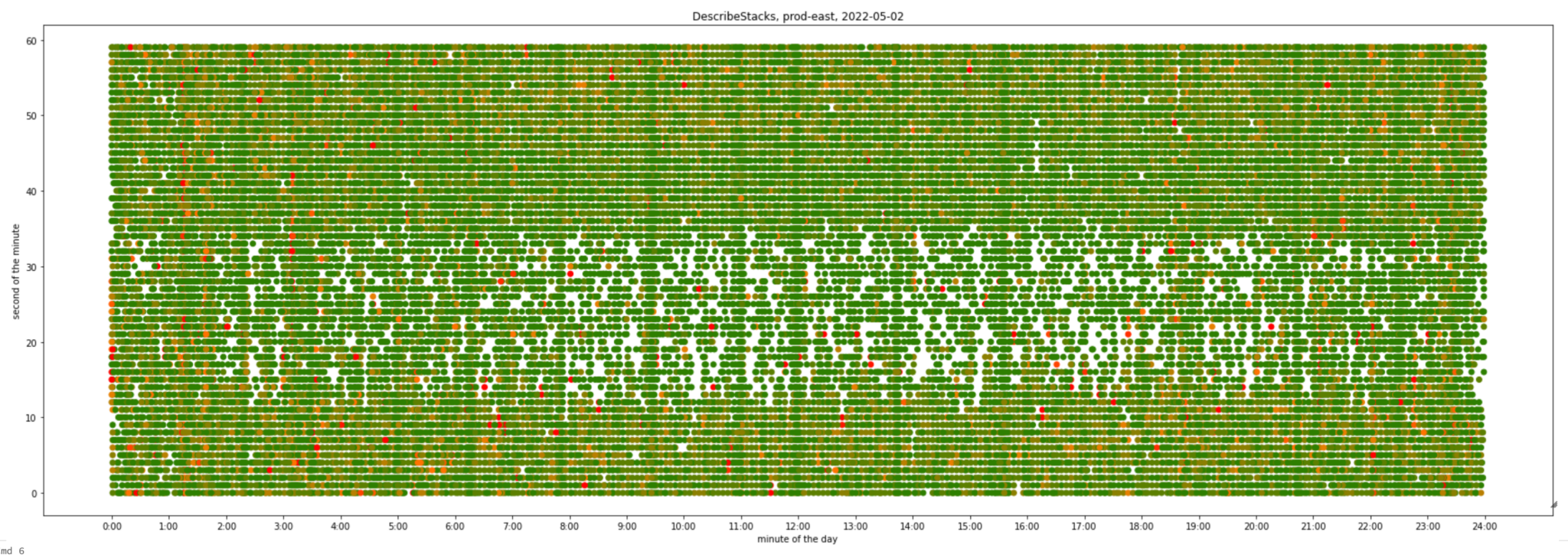
- There is an “empty” horizontal line representing our backoff strategy
- It’s much more orange than the pre-prod environments above, which means production deploys took longer due to rate limiting and retries
Operating inside an account that constantly hits various limits has a material impact on our platform and developer experience:
- When the soft limit for resources is reached, all deployments are blocked until we raise a limit with AWS
- When the hard limit for resources is reached, all deployments are blocked until we clean up resources to increase capacity – although in most cases we monitor resource usage proactively and prevent this.
- When an API limit is reached, there is nothing we can do but backoff and retry. In particularly bad situations we may also exhaust retry attempts and deploys start failing
Slow or temporary blocked deploys can cause multiple negative effects:
- Operational waste for platform users – engineers need to spend time investigating failing deploys
- Operational waste for platform developers – engineers need to spend time investigating and addressing the root cause
- Slower dev loop, increased lead time to production and missing project timelines
- Restricted ability to rollout critical fixes or security patches
- Bigger, riskier releases (most of our services are following CI/CD practices and deploying latest code multiple times a day, slow or blocked deploys means less, therefore bigger releases)
A clear example of the impact of this could be seen in the deployment of Jira, which is our flagship product and largest service running on the PaaS. Jira deploys hundreds of nearly-identical microservices (shards) serving a subset of customers (tenants) each. Deploying Jira triggers hundreds of deploys on our platform causing substantial load on underlying AWS APIs. We’ve reached the point where deploying all Jira shards at once became impossible, and our platform came to a halt due to constant rate-limits, fails and retries. As a result we’ve been forced to split Jira deployments into groups to reduce concurrency, which resulted in longer deploys negatively affecting the development loop and our ability to rapidly ship features.
Discovery and decisions
As soon as we started to look into what would it take to add new accounts to the platform, we realized that the scope of work is enormous and we have to take some critical decisions to reduce the scope and make delivery timelines realistic. These decision played a critical part in how we delivered this project both from project management and technical perspectives.
How many new accounts do we want to add?
This was one of the first questions we needed to answer, and we considered a broad range of options, from “just one more” to “thousands” to support an account per service. Having an account for each service offers various advantages such as enhanced security, operational efficiency, and better cost allocation. However, moving to this model would pose several risks that need to be carefully considered:
- It’s a completely different operations model for us. We’ve been dealing only with a single-digit number of accounts so far and there are definitely unknown unknowns out there.
- It’s a completely different operations model for platform users. New tooling needs to be developed (extra project scope we could not afford) and they need to be educated to operate in a new environment.
- There are are teams outside of the platform integrated with us such as systems dealing with account management, security, or finops, and their tooling was not ready to integrate with thousands of accounts.
We decided to move incrementally instead and deal with these risks at smaller scale:
- Start with 3 new accounts in each environment type (we have dev, staging and prod available for all Atlassian developers, plus “platform dev” for our internal use), effectively increasing capacity 4 times
- Going forward, add more accounts to gradually decrease the number of services allocated per account
- Develop capabilities to enable account per service when it’s needed
- Analyze new data along the way to adjust the decision
Should we evacuate services and resources from large existing accounts?
To answer this question, we needed to understand what migration between accounts would look like for a typical service. Generally speaking, there are 3 types of resources making up a microservice:
- Compute workloads such as code running on EC2 instances, lambdas or step functions that are ephemeral by the nature and recreated all the time in their lifecycle which are easy to migrate.
- Ephemeral resources such as SQS queues, SNS topics, Elasticache clusters, Kinesis streams etc. While not persisting any data, these resources are usually created once and exist for the lifetime of the service. As a result these resources require more effort to migrate, and might cause downtime or partial data loss if re-created depending on the service implementation.
- Persistent resources such as S3 buckets, DynamoDB tables, or RDS databases that additionally require data migration and potential code changes to handle 2 stores during the transition period or may require downtime. These are high effort, high risk changes.
Involving service owners in migrations was a strict NO for us. Given that the majority of services have persistent resources, the engineering time required for migrations and the risk involved scales pretty quickly to unacceptable levels – remember, we have still more than 2000 services running in production!
So how do we solve these scaling problems for services allocated to old accounts without having to involve hundreds of engineers? As mentioned earlier Jira – our largest platform customer – consists of hundreds of sharded services. We realized that if we evacuate the majority of the Jira shards, that alone would be enough to bring existing accounts to a stable state. Moreover, this approach could also be applied at scale – while most other services have unique architectures and require individual approaches for migration, the fleet of Jira shards are mostly identical, allowing us to run the same migration process multiple times without engineering overhead. The high-effort, high-risk change mentioned above transformed into a low-effort, low-risk adjustment when implemented on a large scale across Jira shards.
Should we separate compute workloads from resources?
Another tempting change was to start provisioning AWS resource in dedicated AWS accounts, separate from compute workloads. This account topology has some advantages, similar to “compute per resource” – it gives a clear boundary, simplifying operations and making them more secure. It also enables you to scale parts of the platform independently. For instance, if you have reached a limit of 1000 S3 buckets in your AWS account, you don’t need to configure new account to work with all platform components. Instead, you can just plug it into the component provisioning S3.
The downside of this is that in many cases it requires changes from service owners. To provide services with a secure way to access AWS resources, we rely on IAM. IAM works slightly differently when access is within the same account vs cross-account. For access within the same account, you only need explicit Allow on either the identity or resource policy, while for cross-account access you need both. If a particular resource doesn’t support resource-based policy, cross-account access can’t be granted. To make it work, a new role needs to be provisioned in the target account with a trust policy allowing it to be assumed from the source account. But that means code changes for service owners, which we strictly wanted to avoid.
Another inconvenience is the requirement to operate across multiple accounts. This means that you would need multiple browser sessions authenticated into different accounts to be able to debug issues during an incident. Depending on the available tooling, the issue could range from minor to major. In this scenario, we opted against creating new tools to avoid expanding the project scope.
One of our teams, responsible for RDS provisioning and management, has chosen to use the opportunity to centralize RDS instances within their dedicated AWS accounts. Access to RDS is managed on the network level via security groups, so a change in the IAM access pattern is not relevant here, and overall the pros of dedicated accounts outweighed rest of cons in this case.
Should we use a new network topology?
Around the same time we started Account Sharding, another company-wide project kicked off – Network Segmentation, aimed to create a network-level boundary between customer-facing services (and data they store) and the rest of the company infrastructure and internal services. The network team needed to own VPCs and related network infrastructure and share it with everyone (VPC sharing: A new approach to multiple accounts and VPC management | Amazon Web Services ). This is the opposite of what we had before in our existing accounts – we provisioned and managed VPCs and network infrastructure.
On one hand, this change reduced our scope as we won’t need to deal with networking any more. On the other, it increased scope as we would need to re-design the platform to work with new network setup.
Fully depending on another project is a major risk – in this case, if Network Segmentation got delayed or failed, we might miss our delivery dates or be completely blocked.
Another major consideration was our plans to support 6 new regions for Data Residency. This was on our near-term roadmap and the direction was pretty clear – networking for the new regions would only be available in a new, shared VPC. As a result we’d have to support the new network topology sooner or later, so we decided to take the risk and incorporate the required changes in Account Sharding from the very beginning.
Should we give service owners control over account allocation?
Previously, services only existed in the same account for a given production region. It was an implicit platform feature, and, as we all know from Hyrum’s Law and from xkcd:
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.
We were pretty sure that there were services in the wild depending on the fact they reside in the same account. There were also groups of microservices, working together as a single product. For example, OpsGenie comprises nearly a hundred microservices deployed in each region. It’s reasonable to assume that when considering launching a new service, they would prefer it to be colocated with the existing services. This would go against one of project’s main goals of stopping existing account growth.
We decided to break same-account assumption instead. Instead of assigning account allocation ourselves, we have delegated this task to the platform for a more random allocation. This approach ensures that service owners cannot anticipate which account they will be assigned to. To offset this platform behavior, we made changes to user-facing tooling so platform users don’t need to deal with specific account IDs in their everyday interactions.
In some cases this required work from service owners, such as applying configuration changes to add trust relationships to new accounts or update operational runbooks. The scope of this was limited to a just a few services, and therefore deemed acceptable. As a result, we now have complete control to prevent any further deterioration of existing accounts, and the issue of account co-location is no longer a concern moving forward.
Technical design
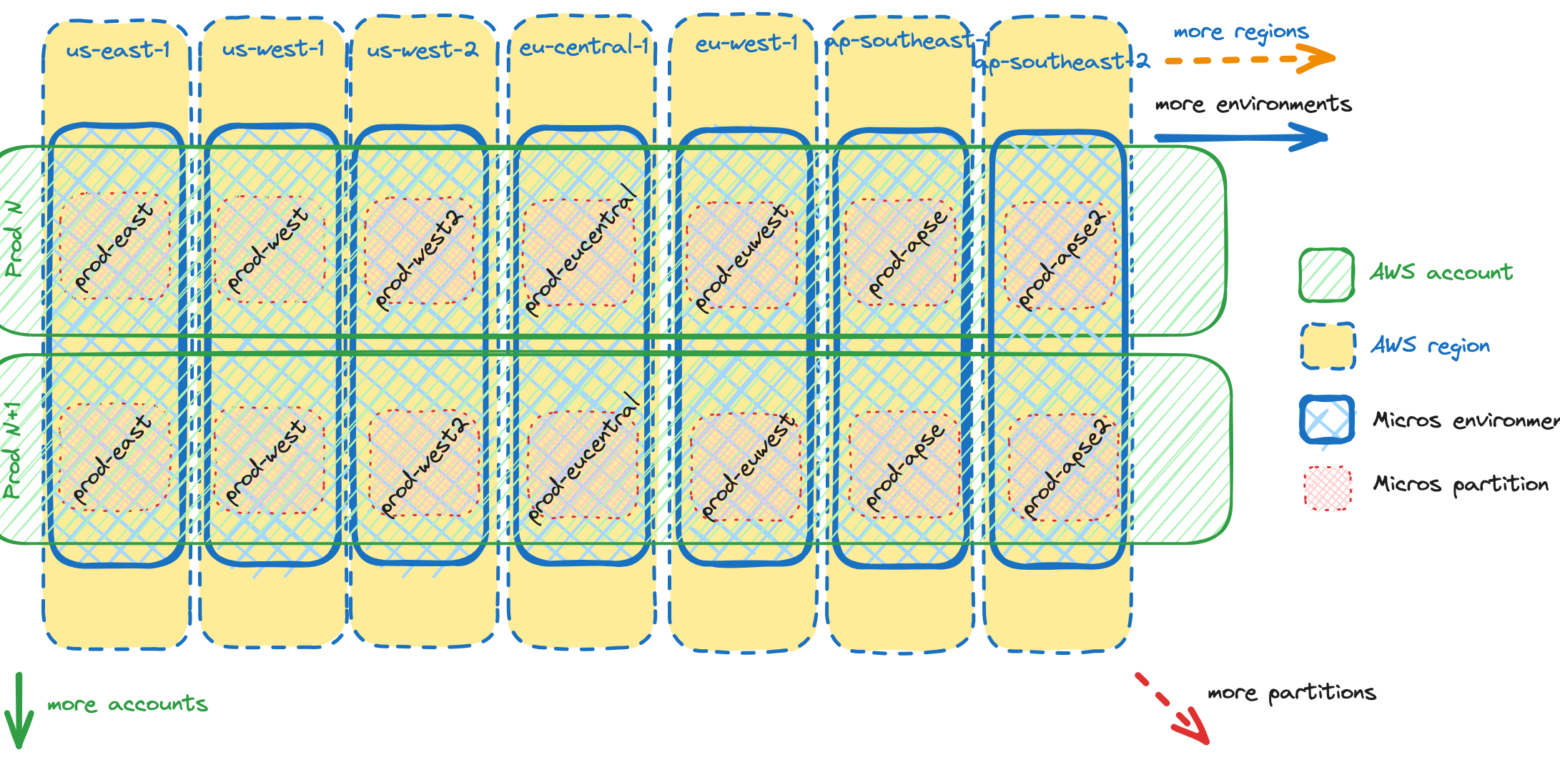
Once these critical decisions has been made, we started to draw our future account topology.
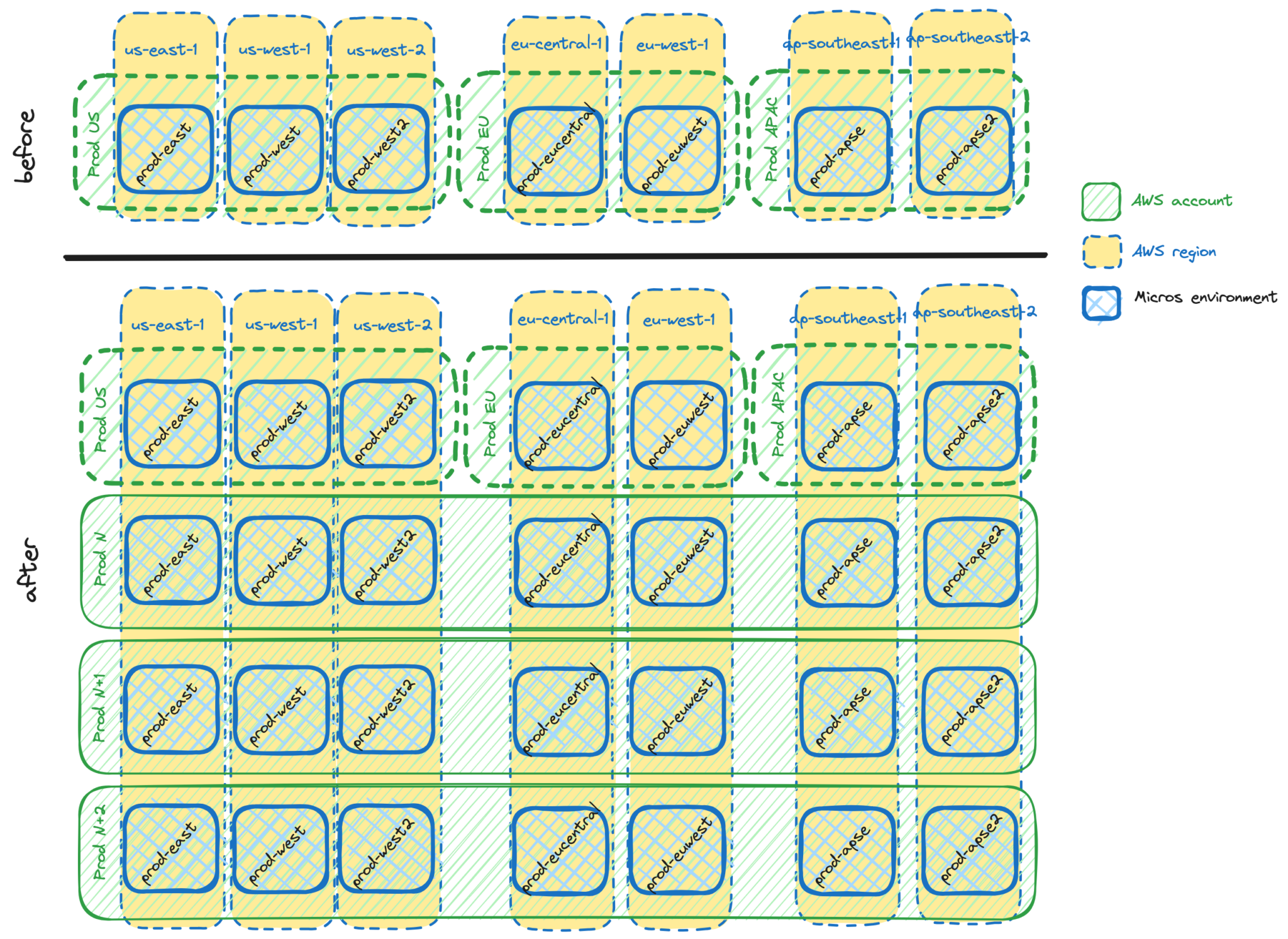
Looking at above picture, it’s easy to spot two differences:
- Accounts were geo-based, for example, the Prod US account hosted only environments for AWS US regions. In a new setup, each account hosts all available regions.
- Environments were mapped 1:1 to accounts. The prod-east environment always meant Prod US account. In a new setup, the prod-east environment is mapped to one of 4 accounts.
While the first difference is not that important, addressing second one required significant changes. Remember we just talked about Hyrum’s law in the previous section?
We were pretty sure there are services in the wild depending on the fact they live inside the same account.
The fun part is that this also applied to us. Micros components relied on the fact that they live inside the same account where they deploy other services, and that there is a 1:1 mapping between an environment and an account. But before diving into how we broke those assumptions, we need to introduce new term.
Introducing partitions
In the previous section we introduced the account sharding model for adding additional accounts, where we add environments across additional accounts. However, when it comes to deploying a service into an environment, we need to send our deployment to a specific AWS account. We refer to a specific combination of Micros environment and AWS account as a “Micros partition”.
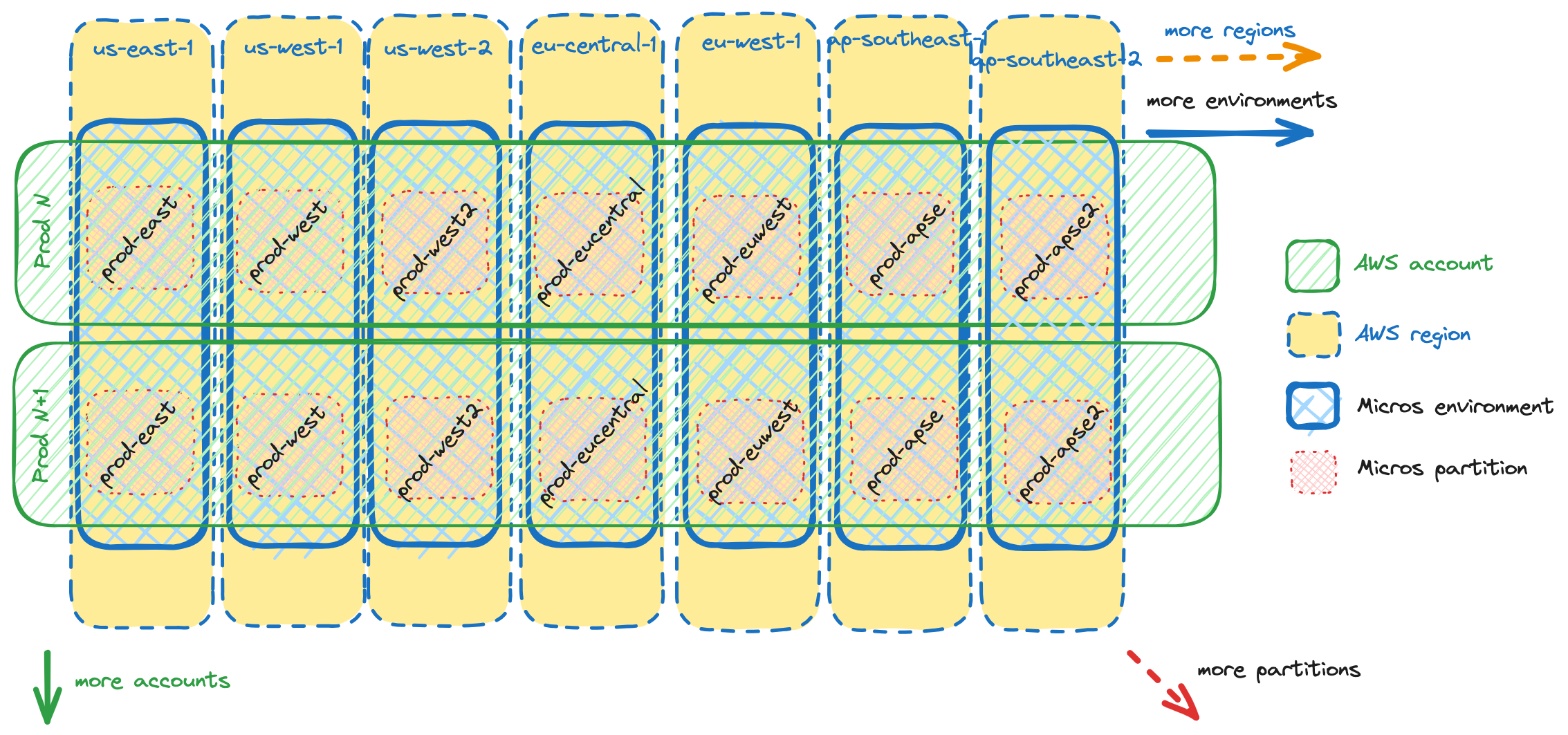
This partition concept became our main operational unit in Micros. Adding new accounts means adding new partitions, as does adding new regions.
While the infrastructure provisioned in each partition for a given Micros environment is mostly the same, some of the resources need to be provisioned in exactly one partition. Partitions hosting such resources are called primary partitions. For example:
- Each environment has an associated hosted zone (
*.us-east-1.prod.atl-paas.netfor prod-east Micros environment), which can only exist in a single account. - The S3 buckets that store load balancer logs.
Each partition that existed before account sharding naturally became a primary partition. The prod-east environment in the Prod US account is a primary partition for the prod-east environment. All other prod-east partitions are called secondary partitions.
Breaking platform assumptions
The first assumption we will be working with is 1:1 mapping between environment and account. Our implementation here was driven by decisions we made in the beginning:
- As we are not intending to move services and resource between accounts, the partition allocation should be persistent
- As we want to control account allocation and avoid any assumptions from user end, partition allocation should be non-deterministic
- As we want to keep all resources to be co-located in one account for a given environment, we need to propagate partition allocation to all platform components
To fulfill all of these somewhat conflicting requirements, we needed a single source of truth for partition allocation. Such a system should perform partition allocation exactly once in a non-deterministic way and then persist the result. It can be fetched later to propagate partition allocation to platform components.
The second platform assumption was about platform services co-located with services they deploy. Having extra partitions means platform services need to learn how to provision resources in other accounts. As mentioned in From Firefighting to Future-Proofing: Atlassian’s Journey with a Multi-Account Strategy | Should we separate compute workloads from resources? , IAM access becomes quite complex for cross-account cases and even impossible in certain instances. So we took an “assume role” approach. For each platform component, we provisioned an IAM role in each of the partitions that is configured with permissions required for specific resource provisioning, and has a trust policy allowing platform components to assume it from their “home” account.
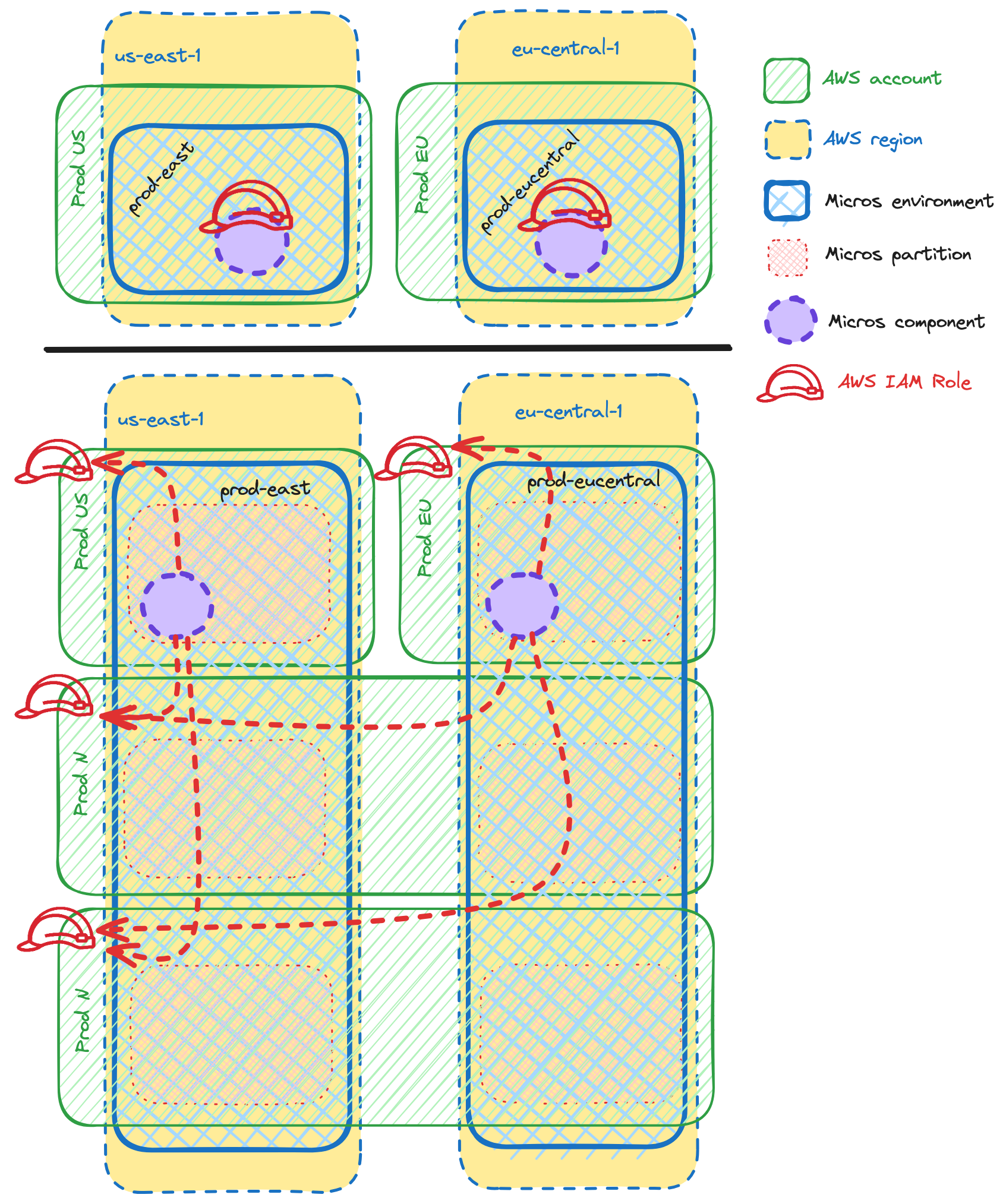
As illustrated above, Micros components can now provision resources in non-local partitions. By applying the same approach to existing partitions, we simplified the architecture by eliminating the need to distinguish between “old” and “new” partitions.
Moreover, with platform components now receiving partition details through the API payload, our design is now future-proof. Adding more accounts won’t require any changes in Micros components as they receive partition information via an API and are ready to act as long as appropriate IAM role exists in the target account. In order to add a new account to our system, we’d only need to add it one place – the partition allocation system.
Landing the impact
Fast-forwarding 2.5 years of implementation across multiple teams and services, let’s talk about the end result.
Platform stability
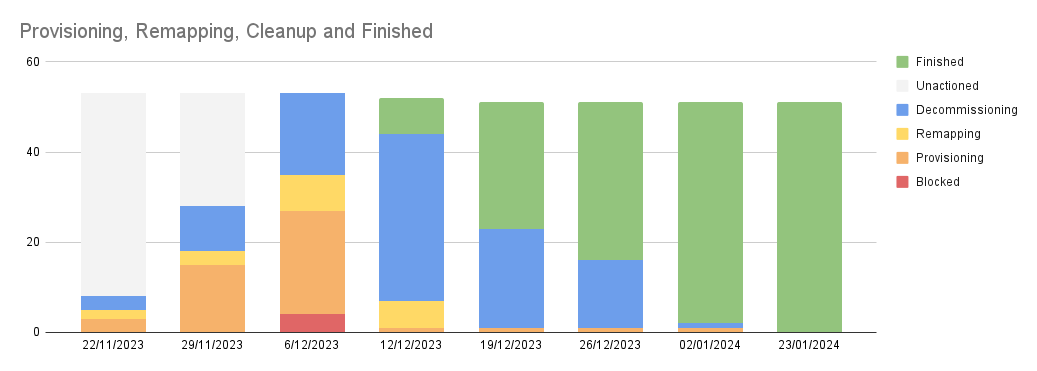
As mentioned earlier, we made an assumption that evacuating some of the Jira shards alone would be enough to bring existing accounts to a stable state. We have collaborated extensively with Jira to make sure that everything is on track. This project has been a definite win-win situation – they benefited from quicker deployments, while we achieved a stable and reliable environment. After migrating just 50 out of ~200 shards, we’ve been able to reduce overall Jira deployment duration by 5(!) times. This also removed pressure for services remaining in old accounts, and increased overall platform stability.
Accelerating platform development
Earlier in this article, we discussed the company-wide initiative to deliver 6 new regions for Data Residency. With the changes to adopt the new network topology and establish a unified design across all platform components, we successfully delivered all 6 regions in just 2 months. This matches the timeframe previously needed to deliver one single region into the platform in pre-account-sharding times.
Setting the stage for future work
In conclusion, I would like to outline the major opportunities Account Sharding brings us going forward. We resolved some past constraints such as the prohibitively high cost of adding new accounts, or requirement for platform components to be in the same account with user services, and can now re-consider previously unfeasible platform features, such as:
- Accounts on demand. As outlined earlier, we limited the initial scope to just 3 more accounts per environment type. We want to gradually move to a wider set of smaller AWS accounts, with an option for dedicated account per service. While we have most of the required changes in high-level platform components, we need substantial rework of our low-level infrastructure provisioning system to accomplish this goal.
- Resource-only accounts. While adopting dedicated accounts for resources was out of scope for the initial project, this topology allows us to further decouple platform teams and their process, thus enabling faster development cycles and innovations.
- Bring-your-own AWS accounts. While most of the Atlassian Cloud Services are running on Micros, our 20 AWS accounts is just a tiny fraction of more than 500 Atlassian AWS accounts. Some teams are running AWS services not supported by our platform, or run their own service which does not fit microservice architecture, or want to have an isolated environment to run a third-party solution. However, we want to make it easier for these teams to start using Micros. Having the ability to deploy services in arbitrary accounts enables us to integrate these accounts into our platform which simplifies these migrations. The same approach can be applied to aquisitions – instead of migrating everything to our accounts, we can integrate new accounts into the platform for gradual adoption.