

Introduction
Organizations use multiple project management tools to track work, leading to fragmentation, collaboration barriers, increased complexity, and higher costs. As organizations face macroeconomic challenges, there’s a push to consolidate work into fewer project management tools to rationalize costs.
To support our customers in consolidating their work in Jira, we have developed an advanced external migration platform that enables the migration of data from other project management tools to Jira. Moving data to Jira Cloud has previously been challenging due to the limitations and scalability issues of the legacy data importer.
This blog post will delve into the architectural evolution and engineering enhancements of our new external migration platform, which have significantly optimized the migration process for Jira users. With this new platform, migrations are now 20 times faster and achieve a data throughput that is 30 times better than the legacy data importer. Furthermore, we’ve realized a 95% improvement in the reliability rate of migrations, ensuring a smoother and more dependable process for all users.

Understanding the importer feature
Before we explore the technical architecture of our new external migration platform, let’s take a moment to view the migration feature from a user’s perspective. Many of you may already be familiar with the “CSV import” feature in Jira, which serves as a critical tool for migrating data from other project management platforms into Jira.
The CSV import feature in Jira allows users to bring their existing data from various platforms into Jira Cloud. This is particularly useful for teams transitioning their project management activities to Jira, ensuring a seamless continuation of their work without losing valuable historical data.
Legacy importer UI
User journey: importing data with CSV
For those unfamiliar with the process, here’s a step-by-step outline of what a user typically does:
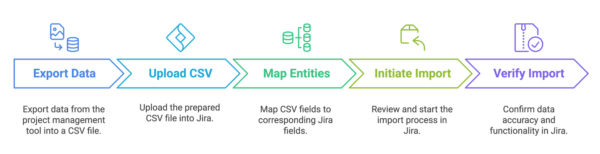
Architectural overview of the legacy importer
To gain a better understanding of our journey, let’s understand where we started. The legacy importer was our initial attempt at facilitating migrations into Jira. Built as part of the Jira platform, its architecture was tightly integrated with Jira’s core, limiting scalability and flexibility. Despite its utility in handling Jira-to-Jira migrations, it faced challenges in scalability, feature richness, and handling migrations from external platforms.
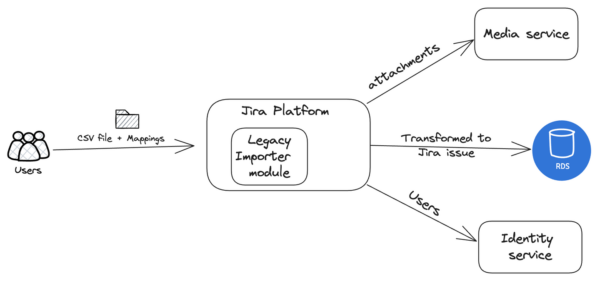
Legacy importer execution diagram
Key components
The Jira Importer Module serves as the entry point for migration requests within the Jira platform. Users provide a CSV file containing issue data and entity mapping data specifying how external entities should map to Jira equivalents. This module is responsible for parsing the CSV data, applying the mappings, and coordinating the transformation process before integrating the data into Jira Cloud.
The Media Service handles attachments associated with Jira issues. It efficiently manages file storage, upload, and download, ensuring that attachment URLs provided in the CSV file are correctly linked to the corresponding Jira fields. This service works in coordination with the Importer Module to ensure attachments are reliably processed during migration.
The Identity Service manages the migration of user-related data. As CSV files often include fields like assignees, this service ensures these are accurately matched with existing users in the target Jira project. It maintains consistency and integrity across the project by verifying and migrating all user-related information into Jira Cloud.
Limitations
Scalability and performance
- The legacy importer struggled with handling large-scale migrations due to its insufficient import speed and data size limits.
- It could only process about 6,000 issues per hour, which was far too slow for projects involving millions of issues. This caused long delays and downtime, preventing many customers from transferring their data from other project management tools to Jira Cloud.
- Because the importer was deeply integrated into Jira’s monolithic architecture, we couldn’t scale it independently. Any improvements required scaling the entire Jira platform, which wasn’t efficient.
Reliability and technical debt
- The success rate of migrations was relatively low, between 70% and 80%, and it was even worse for larger migrations and those with attachments.
- Frequent failures meant users often needed to step in manually, leading to a significant number of support issues—around 200-250 each month.
- The root of these problems was the significant technical debt that had built up over time, making maintenance difficult due to known bugs that slowed down debugging and testing.
Integration and dependency challenges
- The importer was closely tied to Jira’s core, introducing multiple dependencies. This tight coupling made the system vulnerable to bugs whenever changes were made to Jira’s core components.
- Furthermore, integrating new third-party services posed a challenge due to different authentication methods, data formats, and API versions, requiring custom solutions and heightening the risk of system instability.
Building a scalable migration platform for Jira
To address the limitations of the legacy importer, we initiated a comprehensive redesign of our existing systems. This transformation involved developing advanced CSV importers and implementing microservices to enhance scalability and flexibility. By leveraging AWS services, we significantly boosted performance and reliability. Our phased approach systematically tackled specific challenges, leading to a more robust and adaptable migration solution. This strategic evolution not only improved the migration process’s efficiency and reliability but also enriched the overall user experience.
Phase 1: Building scalable CSV importers
The journey of this platform began with the introduction of CSV-based migrations for Jira projects. This initial step was important for us to explore the process, understand the complexities of data migration, and collect valuable feedback from early users. CSV importers established the foundation for more sophisticated integrations and set a standard for ease of use and efficiency.
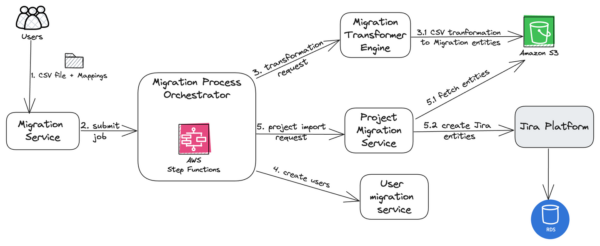
CSV importer execution flow
Key components
The Migration service serves as the entry point for CSV-based migrations, handling user requests that include CSV files and the necessary field mappings for data transformation. Upon receiving a request, the Migration Service validates the input and submits the migration job the the orchestrator.
Central to the process is the Migration process orchestrator, which ensures that each step in the migration is executed in the correct sequence. By coordinating between services like the Migration Transformer Service and the Project Import Service, it facilitates reliable execution, enabling error recovery and providing clear visibility into the migration’s progress and state.
AWS Step Functions facilitate workflow design, defining the migration process as a series of configurable steps. AWS SQS triggers asynchronous events, enabling services to process tasks independently and concurrently, enhancing scalability and performance.
The Migration transformer engine plays a vital role in converting CSV data into Jira-specific entities. By applying user-provided field mappings, it transforms the data into a format suitable for import. This transformed data is then temporarily stored, often in an intermediary solution like an S3 bucket, awaiting further processing.
Before the main project data is imported, the User migration service manages the creation of new users specified in the CSV. It processes user data, checks for existing users, and creates new accounts as necessary, ensuring all user-related information is correctly integrated into Jira.
Once user data is prepared, the Project migration service retrieves the transformed project data and integrates it into the Jira platform. This service ensures that all entities and relationships are correctly established, completing the migration process and making the imported project available in the Jira Cloud instance.
Finally, the Jira platform itself provides migration-specific APIs that are used in various migration scenarios, such as Jira Cloud to Cloud and Jira Server to Cloud migrations. These APIs ensure consistent data validation and integrity checks, facilitating precise and secure interactions with the Jira database to accurately store the transformed data.
Cloud to Cloud migration refers to the process of transferring data and configurations from one instance of Jira Cloud to another. This might be necessary when consolidating multiple Jira Cloud accounts into a single one or when moving to a different cloud region.
Server to Cloud migration involves moving data and configurations from a Jira Server instance, which is hosted on-premises to a Jira Cloud instance. This transition allows organizations to leverage the benefits of cloud, such as reduced maintenance and automatic updates.
Steps in the migration process
User input and configuration
The migration process initiates when a user provides the necessary inputs. During this initial phase, the user submits a CSV file and associated field mappings to the Migration Service. Following this, there is validation. The Migration Service validates the input, ensuring the CSV file is formatted correctly and the field mappings are accurate.
Orchestration
In the Coordination phase, the Migration Process Orchestrator receives the validated request and begins coordinating the migration process. It then moves to task assignment, assigning tasks to the relevant services, such as the Migration Transformer Service, User Migration Service, and Project Import Service.
Data transformation
This step involves mapping, where the Migration Transformer Service applies the provided field mappings to the CSV data, converting it into a format suitable for Jira. The Storage sub-step follows, where the transformed data is stored in an intermediary storage solution like S3 for further processing.
User creation
During User data processing, the User migration service processes the user data from the CSV, checking for existing users and creating new accounts as necessary. The next sub-step is User account creation, where new user accounts are created in the Jira platform, ensuring they are ready to be associated with the imported project.
Project import
The process concludes with Data retrieval, as the Project Import Service retrieves the transformed project data from the intermediary storage. Finally, during integration, it integrates the project data into the Jira platform, creating entities and relationships as defined in the CSV and mappings.
Key features and benefits
Optimized scalability and performance: Our microservices architecture allows for horizontal scaling, enhancing performance and resource utilization. Asynchronous processing efficiently handles large datasets through queuing and parallel execution, reducing processing time. An intelligent retry mechanism with Step Functions ensures reliability by managing task failures, maintaining data integrity, and minimizing data loss.
Advanced data transformation: Built-in enrichment features automatically fill missing or incomplete fields using predefined rules or external sources. Robust error handling and recovery mechanisms gracefully manage unexpected errors, ensuring data integrity and minimizing data loss.
High throughput Jira integration: Integration with Jira’s Migration APIs ensures efficient and reliable data migrations, managing entity creation, updates, and relationships. These APIs facilitate both external-to-Jira and Jira-to-Jira migrations, with the capability to support up to 10 million issues per day, providing a streamlined and dependable migration experience.
Phase 2: Enhancing flexibility with API-based integrations
As organizations adopt a wider range of project management tools, it’s important to ensure they integrate well with Jira. The traditional CSV import method, while useful, falls short of providing the flexibility required for direct integration with various platforms, leading to inefficiencies and manual interventions. To overcome these limitations, we have enhanced our migration platform with API-based integrations. This approach allows for direct connectivity with popular tools like Trello, Asana, Monday, and ClickUp, enabling a more automated and comprehensive data migration process that reduces manual effort and enhances workflow efficiency.
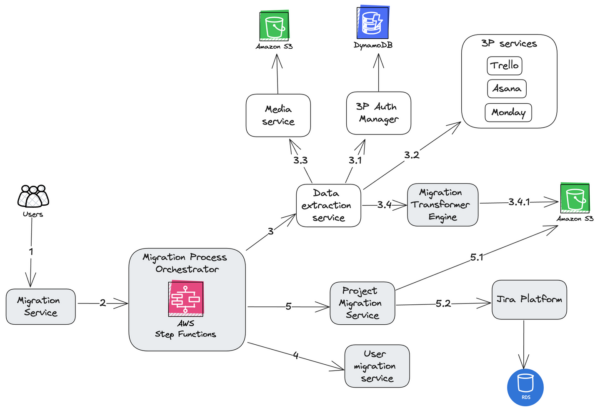
API-based importers execution flow
Key components
The orchestrator initiates the Data extraction service workers to systematically fetch data from third-party services. These workers use API calls to gather necessary data elements, ensuring data integrity and consistency throughout the process. Extracted data is then passed to the Migration Transformer Service Workers, which handle data format conversions required for compatibility with Jira.
The Media service is responsible for managing attachments associated with Jira issues. It offers APIs for uploading and downloading files, with secure storage managed in Amazon S3.
The third-party auth manager is critical for managing authentication and authorization when accessing third-party service APIs. It supports OAuth 2.0 flows, handling token retrieval and refresh to maintain session validity. Additionally, it manages Personal Access Tokens for services that don’t support OAuth, ensuring secure API access by encapsulating and securely storing credentials.
Third-party services are specialized interfaces designed to interact with third-party APIs, such as those from Trello, Asana, Monday, and ClickUp. These interfaces implement API clients that handle pagination, rate limiting, and error handling to efficiently retrieve data like tasks, projects, and metadata. The data fetched is pre-processed by ensuring consistent field naming conventions, normalizing date formats, and resolving any incomplete records through default values or data enrichment. This preparation ensures data consistency and completeness, thereby readying it for transformation and eventual integration into Jira.
Additional steps in the migration process
Authentication and token management
Incorporating the new components into the migration process introduces several important steps that enhance data handling and security. Accessing third-party (3P) APIs requires the use of OAuth or personal access tokens, which are efficiently managed by the 3P Auth Manager. This component handles the entire authentication flow, including token acquisition and renewal. For OAuth, the manager interfaces with the specific authorization servers of the third-party services to obtain access tokens. It also manages token expiration through the use of refresh tokens, ensuring uninterrupted access to the APIs. While the detailed storage mechanism for these tokens is not depicted here, it is securely handled within the 3P Auth Manager.
Data retrieval
Once authenticated, these tokens facilitate data retrieval from third-party services. The data is extracted in batches, utilizing either REST or GraphQL APIs, contingent on the capabilities provided by the respective third party service. This batch processing, along with the control rate of access, helps manage API rate limits and ensures efficient data transfer. In the case of CSV migrations, CSV file chunks are downloaded directly from the S3 bucket.
Media management
The Media Service manages attachments associated with Jira issues. Each attachment is uploaded to Amazon S3, leveraging its scalable storage infrastructure and robust access control features. This ensures that all media files are securely stored and accessible throughout the migration process.
Data transformation
Concurrently, the extracted data undergoes continuous transformation through the Migration transformer engine. This engine applies necessary mappings and conversions to align the data with Jira’s format requirements. The transformed data is then temporarily stored in Amazon S3, providing a reliable and scalable intermediary storage solution until it is ready for integration into Jira.
Key features and benefits
The platform facilitates diverse tool integration and enables data migration from various third-party platforms through direct API connectivity, providing users with flexibility and options.
By implementing a unified interface, consistent data interpretation and smooth communication across different tools are ensured, acting as a universal translator.
Through efficient batch processing, authenticated tokens are utilized for batch data extraction via REST or GraphQL APIs, effectively managing API rate limits and optimizing data transfer.
An adaptable architecture, with its modular design, decouples data extraction and transformation, allowing component reuse across tools to enhance efficiency and flexibility.
The Migration Transformer Engine achieves continuous data transformation. It applies necessary mappings for accurate data integration into Jira and temporary storage in Amazon S3.
Phase 3: Making migrations more efficient with async attachment processing
After the previous phase, we observed that the migration of attachments was consuming the majority of the time in the overall migration process. To address this issue, we implemented asynchronous attachment migrations, which drastically improved both speed and reliability. By decoupling the attachment download process from the main migration flow, we were able to provide a smoother, more efficient migration experience, significantly reducing the overall project downtime. This approach allows users to access their projects in Jira while the attachment migration runs in the background.

API-based importers with efficient attachment migration
Key components
The migration platform’s architecture is designed to optimize efficiency through asynchronous attachment migrations. This phase uses the orchestrator to oversee the workflow and manage the lifecycle of Attachment Uploader Workers. These specialized workers operate independently to download attachments from the source system and upload them to the Media Service. Metadata about attachments, including URLs and media IDs, is stored in DynamoDB, ensuring efficient data handling without immediate file transfers. The decoupled approach allows the main migration process to proceed uninterrupted, enhancing overall performance and reliability.
Additional steps in the migration process
Attachment metadata handling
In our migration architecture, after retrieving attachment data from third-party services, we store the attachment URLs mapped to unique media IDs. This mapping, along with associated metadata, is persisted in DynamoDB. Notably, during this phase, the physical files are not uploaded or downloaded, which optimizes initial data handling and reduces latency.
Attachment uploader process
Once all primary entities have been successfully migrated into Jira, the orchestrator component activates the attachment uploader workers to download from the source system and upload to the media service. By focusing on decoupled processes and asynchronous operations, we delivered a solution that optimally meets both technical and user expectations.
Key features and benefits
Non-Blocking migration: By handling attachments asynchronously, the main data migration process is expedited, preventing delays due to file transfers.
Robust reliability: The decoupled approach allows for independent retries of attachment transfers, minimizing disruptions and maintaining smooth migration workflows.
Optimized performance: Separate handling of attachments and structured data enables the use of specialized resources, enhancing the efficiency and speed of both processes, with potential throughput improvements of up to 3x.
Scalable processing: Decoupled attachment migration supports auto-scaling, optimizing resource use, and reducing costs while effectively handling variable demands.
Enhanced user experience: Users can access migrated projects immediately, as attachments are processed in parallel. For large migrations, this approach reduces downtime by 80% to 90%, significantly improving the user experience.
Phase 4: No-code importers
In the past, converting data to the legacy CSV format was challenging for end users due to complex transformations, requiring detailed configuration and manual mapping, often leading to errors. To address this, we’ve developed a no-code framework that enables our engineers to quickly support a wider array of products. This framework pre-configures data mappings and transformations, packaged by Atlassian into user-friendly importers for common source products. These importers can be easily used by end users, reducing technical barriers. By using this framework, our engineers efficiently create tailored importers for third-party tools, significantly reducing time to market.
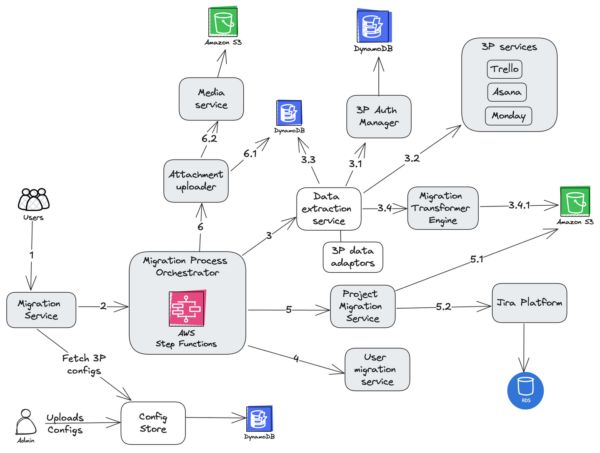
No-code importer execution flow
Key components
The Configuration store is a centralized repository that plays a pivotal role in the management and operation of the no-coder’s data transformation processes. It is designed to securely store the data transformation rules, which primarily include the mappings of data fields, as well as rules for data extraction from the source systems to the target system.
External data adaptors are specialized components within the no-code platform specifically designed to manage data transformation processes. They interpret and transform data according to the rules and parameters defined in the Configuration Store. By accurately processing data, they ensure that the system can efficiently manage complex data structures and formats.
Additional steps in the migration process
Configuration upload by the product team
The internal product team is responsible for uploading specific configurations for third-party services into a configuration store. These configurations are tailored based on the source, which could be any third-party service like GitLab, ClickUp, or Notion, and the destination. For example, the ClickUp configuration below illustrates how such configurations are structured:
Example Configuration for ClickUp

Explanation: In this configuration, each field can specify a dataAdaptor to manage its transformation, such as date conversion and JSON parsing, ensuring data is correctly formatted for Jira.
Data mapping definitions
Configurations, like the ClickUp example provided, define the data mappings from third-party service fields to Jira fields, ensuring that data is transformed correctly during migration. Each configuration includes the names of a specific third-party data adaptor, which assists in parsing complex data types unique to that service.
Conditional configuration deployment
Our database stores each configuration’s state, indicating whether it is enabled or disabled for a specific environment. The Jira UI checks the configuration state at runtime, allowing it to dynamically show or hide importer options based on the current environment settings.
Default and customizable mappings
During a migration request, the predefined mappings are fetched and serve as the default settings. Users have the flexibility to override these default mappings to suit their specific use cases.
Tracking and continuous improvement
Field mapping data is tracked on an analytics platform. Based on analytics data and user feedback, the internal teams continuously update configurations to enhance user experience and accuracy.
Key features and benefits
Intelligent field mappings: Importers are designed to automatically match data from different sources to the appropriate fields in Jira, minimizing manual intervention and enhancing migration accuracy.
Personalized 3P data adaptors: The system includes adaptors specifically engineered to handle complex fields, ensuring smooth and accurate data migration.
Efficiency in launching new importers: The adoption of no-code importers has significantly accelerated our time to market by 70%, enabling us to create custom importers in just one week. This efficiency translates to considerably less development effort, allowing us to support more tools and services. As a result, we’ve launched 10 new importers, including those for GitLab, Notion, and Linear, within a mere two-week timeframe.
Enhanced user experience and success rates: With automated field mapping and seamless processing of complex data formats, users are now 80% more likely to successfully complete their migration once they reach the field mapping screen. This enhanced process minimizes manual intervention and ensures accurate data mapping, significantly improving the overall user experience and success rate.
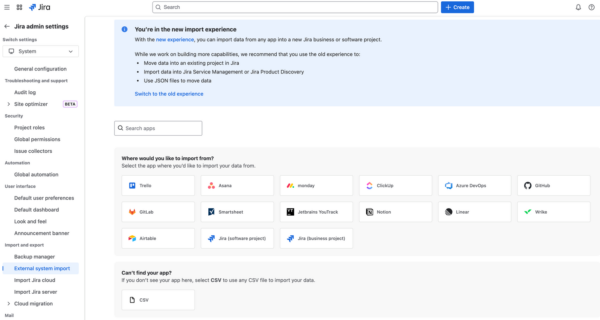
No-code importer UI
What’s next?
As we continue to enhance our migration platform, our focus remains on expanding its capabilities to better serve the needs of our users. We are committed to ongoing improvements in performance, reliability, and integration flexibility. Our roadmap includes further innovations to enhance the user experience and streamline the migration process, with particular attention to expanding the capabilities of our external importers for broader tool integration. We are eager to explore new possibilities and look forward to sharing more details as new features are developed and ready for release.