Our company made a strategic decision to migrate from IBM RTC Jazz (RTC) to Atlassian’s suite of products – Jira, Confluence and Bitbucket. The challenge was how do we move 1000+ developers from one platform to another
This post was written by Bitbucket user Istvan Verhas.
Our company made a strategic decision to migrate from IBM RTC Jazz (RTC) to Atlassian’s suite of products – Jira, Confluence and Bitbucket. The challenge was how do we move 1000+ developers from one platform to another without much interruption to work. In this post, I am going to focus only on the Bitbucket/Git migration and leave the Jira story for another blog.
Here’s how we did it.
Entity/Concept mapping
We started by mapping entities across the two platforms.
| RTC | Git |
| Project | Project |
| Stream | Branch |
| Component | Folder/Repository |
| Changeset | Commit |
| Baseline | Tag |
| Snapshot | Tag |
| Flow target | Gitflow |
| Repository Workspace | Branch |
| Local Workspace | local repository |
Gathering requirements
Since different teams in the company used RTC differently, each team needed a separate migration strategy. I developed and introduced an assessment template in Confluence.
The assessment page was the starting point for each team’s project to be migrated. We called it the contract between the team and us i.e. my team who was managing the migration.
For Bitbucket, this contract detailed the Streams (similar to Git’s branches) and Components (a kind of container) to use as source and Git repository names as a destination. To avoid any name collision, we decided to migrate each stream’s component into its own Git repository. After the migration, the client, of course, could merge the repositories as they needed. This solution ensured our role was purely the migration and the client would manage the process after that.
Tool selection
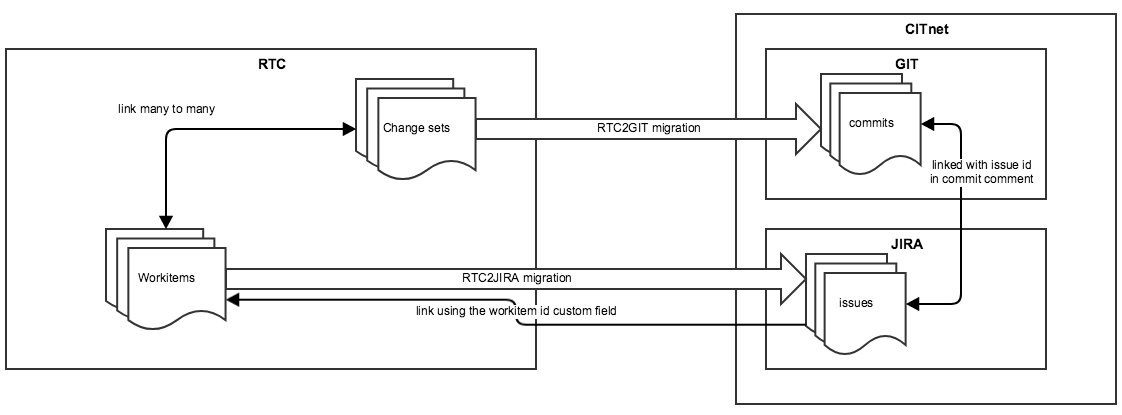
User migration was easy since both systems used the same user directory. After reviewing the available tools to migrate from RTC to Git, I picked rtc2gitcli. Its functionality is based on the RTC source control command line interface (scm cli) and is written in Java as a scm cli plugin. The only missing feature was the link creation between the Git commit and the related Jira issue. This information is stored similarly in RTC to link a changeset with one or more work items as it can be seen on the following figure.

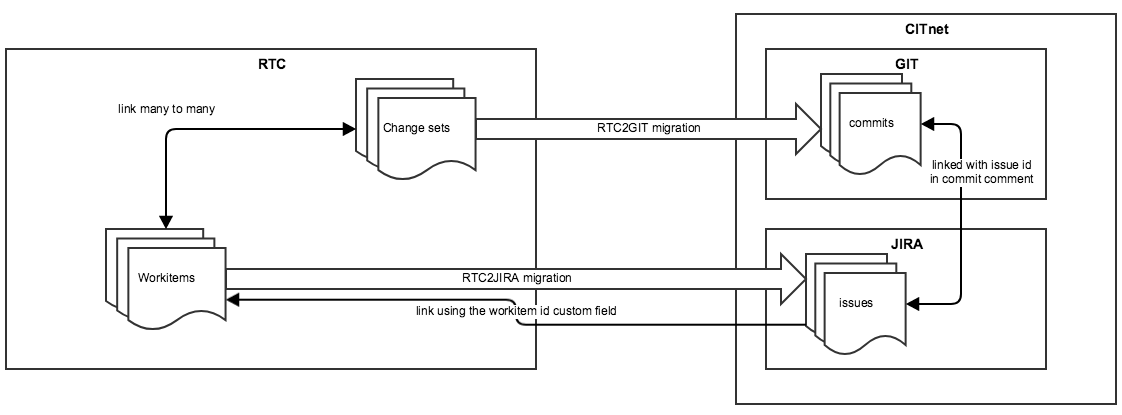
From the Jira point of view, this required us to include the issue id in the comment of the git commit. If the Jira – Bitbucket application link is configured properly then there is no other requirement from the Git point of view.
So I developed an enhancement for rtc2gitcli to do the following before the commit:
- look up the work item(s) linked to the changeset
- For each work item(s), lookup the Jira issue key(s) as our Jira migration always stores the id of the work item, from which the issue was created
- update the commit comment with the issue key(s), In case the work item is not available in Jira, we just put in the work item id
- optionally, put in the summary of the work item as the users usually do not provide comments to the changeset
The next fix was to convert the baseline names to tag names. The RTC baseline names could not be used directly as Git tag names as they sometimes contains characters that are not allowed in git tag names. We developed a tool to convert baseline names to tag names based on JGit’s Repository’s isValidRefName method. This method validates all the the ref names in Git including the tag names.
Starting from scratch
We proceeded to migrate many projects with this toolset successfully. However, when we tried to migrate some bigger and more complex projects, the process failed because the scm cli was buggy.
We tried to fix it as well as find a workaround with support from IBM. Finally, we realized that the issue was with the scm cli itself. So IBM wasn’t going to fix it. We started from scratch thinking of a full scale solution. All the out of the box tools available were based on the same scm cli, so they all dropped out of consideration.
After a detailed investigation, the only solution was to start with the RTC Web GUI and use the same technology to build a migration tool. However, the Web GUI is built on the private/internal REST API of RTC. Since it was private/internal, it meant that there was no documentation and that it could change without notice in a future version.
But given that the migration tool is a one-time use tool and there was no plan to upgrade RTC from our current version, we decided to move ahead. To overcome the missing documentation of the RTC REST API I monitored the network traffic by browsing the Web GUI of Jazz using Chrome’s Developer tools. This gave me a list of all the REST API calls being made to start the server.
| Filename | Functionality |
| .gitignore | excludes files from commit e.g. credentials.sh |
| checkgitreponame.sh | checks the name of origin of the local repositories |
| convertcomment.sh | replaces the work item id in comment with the looked up JIRA issue key |
| convertjazzignore.groovy | converts the jazz ignore file to git ignore file |
| convertjazzignore.sh | executes the convertjazzignore.groovy and pushes the result to git |
| credentials.sh.TEMPLATE | a template file for the credentials.sh without real usernames and passwords |
| deleteallrepos.sh | helper to delete all the repositories in a Bitbucket project |
| execute.sh.ACC | a template file for the execution file for the ACC environment |
| execute.sh.PROD | a template file for the execution file for the PROD environment |
| finalfix.sh | Fixes the final diff between RTC and the migrated, tags it and pushes all |
| generate-runall.sh | generates the runall-ALL.sh for the project area |
| getbaselines.sh | retrieves the baselines for a component |
| getchangesets.sh | Gather the list of all the changesets in the order as they were added to RTC jazz. |
| getfullchangeset.sh | Retrieve the details of each changeset. |
| getmetadata.sh | Retrieve the metadata of each changeset |
| getsnapshots.sh | retrieves the snapshots for a stream |
| listcomponents.sh | retrieves the list of the components of the streams of the project areas. |
| liststreams.sh | retrieves the list of the streams of the project areas. |
| login.sh | login into the jazz using specific cookies |
| lookupworkiteminjira.sh | looks up the work item id to get the corresponding JIRA issue key |
| migrate.sh | main orchestrating script to execute the migration |
| migratetogit.sh | orchestrates the creation of the git repository |
| mycurl.sh | wrapper for the curl to handle the specific cookies |
| projectareas.txt.SAMPLE | a template file for the list of the project areas |
| pushtogit.sh | sets the remote and push the repository |
| reconvertcomment.sh | one step from the migrate.sh to be able to execute it standalone again after an update of the issue keys |
| sortchangeset.awk | sorts the changes within a change set to handle in the intended order |
| tagbaselines.sh | tags commit(s) based on the baselines |
| tagsnapshots.sh | tags commit(s) based on the snapshots |
| writefastimport.sh | generates the fast-import file to create the git repository |
Speed: This was also a good time to create a faster migration tool as the prior approach would have taken days to execute.
Our migration approach was to execute the full process two or three times. First in the ‘test’ environment. This was mandatory when we started a new project area migration. After the successful proof of concept migration, we do it in the ‘acceptance’ (ACC) environment. When the client accepts the result in ACC, then we would begin migrating in the production (PROD) environment.
To improve migration speed, we reused the results of the acceptance migration during the production migration. This required us to store the intermediate results and be able to continue the process from the stored results.
We needed to find a balance between the time needed to develop this enhancement and the extra time it would take to run (in the slower version). Based on our analysis, we decided to implement this using bash scripting features. We also used the following command line tools:
- GNU Parallel: to execute job parallel for optimal resource usage
- jq: Command-line JSON processor: to process the JSON response from RTC and Jira
- curl: as http client
- git: manage the repositories locally and push the results to Bitbucket
- Groovy: to reuse the already implemented enhancements from the previous tool as mentioned above.
How it works
Here’s how we migrated each streams’ component into its own Git repository. The process is orchestrated by the migrate.sh. In each step, I’ve listed the functionality and the script name responsible to do it.
- Gather the list of all the changesets in the order as they were added to RTC jazz. – getchangesets.sh
- Retrieve the details of each changeset. It results in a list of all the files changed in each changeset. – getfullchangeset.sh
- Download all the files involved in each changeset if not already downloaded. – mycurl.sh
- Retrieve the metadata of each changeset. This results in the list of the work item ids to be converted into Jira keys – getmetadata.sh
- Convert the work item ids into Jira keys taking into account the targeted CITnet environment. First look up the Jira keys in the list of the work item ids. – lookupworkiteminjira.sh Then replace the work item ids in the comments using the results. – convertcomment.sh
- Convert the .jazzignore files into .gitignore files. convertjazzignore.sh and convertjazzignore.groovy
- Generate the fast-import file for Git, iterating over the changesets and applying the downloaded files, the metadata files, and the converted comments. Again taking into account the targeted CITnet environment. writefastimport.sh
- Import the fast-import file into Git and push to the server. pushtogit.sh
- Gather the baselines. Convert the baseline names to tag names, aligned with the tag naming rules in Git. Add tags to the Git repository and push the changes to the server. getbaselines.sh and tagbaselines.sh
- An alternative to the baseline based tagging is snapshot based tagging. In this case the getbaselines.sh, the getsnapshots.sh and the tagsnapshots.sh scripts do the job.
- If there is still a difference to the final state the last commit is generated by the finalfix.sh
Feel the force, use the tools
git fast-import is a versatile and fast tool to import repositories into Git. It was fast both on execution and development. It took only a couple of hours to create a working importer though it was my first exposure to git fast-import. The execution was much faster than committing each changeset one by one.
As an example for simplicity let’s see how to add or modify a file with the following three lines of bash code.
echo "M 100644 inline $2"
echo data $(stat -c '%s' "$1")
cat "$1"Here, the $1 (the first parameter) is the file’s path on the filesystem and $2 (the second parameter) is the file’s path in the repository. The first line tells Git that a modification (creation is also a modification, starting from a non-existing file state) is coming with the appropriate filesystem permission, inline data at the path in the repository. The second line outputs the string data and the size of the file in bytes. The third line adds the content to the file.
Another interesting part of the development was when I realized that the final difference between the repository state (repository1) as I followed all the changes coming from the Web UI and the repository state (repository2) checking out by scm cli. Actually, the scm cli’s checkout was the desired one. So the situation is the following. We have two repositories and we want to “generate” a commit between them. After the first fail using Linux’s diff, I tried to think it over again and I was enlightened by how Git is working. It has a register about the state of the repository in the .git folder and it compares the register with the filesystem. In this context, the task is to compare the register of the repository1 to the filesystem of the repository2. So just copy the .git folder from repository1 to the repository2, add all changes, commit, tag and push changes as you can see here.
cp -r $gitdir $lastversiondir
pushd $lastversiondir
git add --all
git commit --author="$citnetgitauthor" --message "Fixed the final diff between RTC and the migrated."
git tag "RTC2CITnet-migration-finalfix"
git push origin master
git push --tags
popdwhere the $gitdir is the .git folder of repository1, $lastversiondir is the folder of repository2
Performance in numbers
The performance of the overall solution met our expectations. When we migrated a bigger project with about 300 repositories, at first took 160 hours with this new process. However, when we executed again reusing the downloaded data, the execution time reduced to 32 hours. To understand efficiency of resource usage, we measured the time of the run on a machine with 4 cores. The real-time was 13 hours, the user-time was 22 hours and the system-time was 5 hours. This means all the four cores were on about 50% load for a half day.
With this process, we created a next generation migration tool that can be adapted for another client’s specific needs. If you are in a similar situation as us, I hope this process helped get you started.
Author bio: Istvan Verhas is an Atlassian expert with a demonstrated history of working in information technology for more than 15 years. Skilled in JIRA, Confluence and Bitbucket support and app development. You can contact him at istvan@verhas.com