

Atlassian has an internal Platform-as-a-Service that we call Micros. It is a set of tools, services, and environments that enable Atlassian engineers to deploy and operate services in AWS as quickly, easily, and safely as possible.
The platform hosts over 1,000 services that range from experiments built during our ShipIt hackathons, to internal tooling supporting our company processes, to public-facing, critical components of our flagship products. The majority of Atlassian Cloud products are either partly or fully hosted on Micros.
Despite its crucial responsibilities, Micros is a relatively simple platform. The inputs it takes to deploy a service are just a Docker image containing the service logic, and a YAML file – the Service Descriptor – that describes the backing resources that the service needs (databases, queues, caches, etc.) as well as various configuration settings, such as the service’s autoscaling characteristics. The system takes care of expanding those inputs into production-ready services, ensuring operational functionality (e.g. log aggregation, monitoring, alerting) and best practices (e.g. cross Availability-Zone resiliency, consistent backup/restore/retention configuration, sensible security policies) are present out-of-the-box.
We haven’t invented much here: nearly everything Micros offers is achieved by using standard AWS features. With this in mind, it is common for engineers to question the need for such a platform: couldn’t we simply open up plain, direct AWS access to all teams, so that they can use AWS’s full and rapidly-expanding functionality?
This is a great question which we’ll explore below, focussing on the following points:
- We believe that there are fantastic economies of scale that come from a platform that strongly encourages consistent technologies, tools, and processes – and that these advantages would likely be degraded if direct access to AWS were the norm.
- We acknowledge that this level of indirection can sometimes result in reduced flexibility, so it’s important to consider how we can mitigate this trade-off.
The benefits of consistent infrastructure
AWS’s breadth of Cloud infrastructure features is extensive to say the least, and only a subset is made available to Atlassian engineers via Micros. This discrepancy isn’t due to Micros being unable to “keep up” with AWS. The limitation exists primarily because we believe in the value of reducing technical sprawl, especially at the bottom of our stacks. There are fantastic benefits that manifest when teams across Atlassian use infrastructure in a consistent manner. To name a few:
- Integrations with standard company tooling and processes are much easier to implement. Our platform provides control points around provisioning. Consequently, integration with logging, metrics, service metadata management, compliance controls, etc. can be baked into the platform rather than being handled by many different teams. Additionally, when we need to change those integrations, a large part of the change effort can be centralised. For example, this has proven valuable when we’ve needed to shift the entire company from one logging or monitoring vendor to another.
- More generally, projects that require sweeping changes to our services are simplified and more predictable. This includes security initiatives, new compliance programs and more. Some concrete examples include efforts to normalise TLS configurations across the company, to enforce consistent access controls relating to SOX compliance, and enabling encryption at rest on our data stores. In the latter project, it was a huge benefit that the vast majority of services use one of the 4 data stores supported by Micros at the time (DynamoDB, Postgres RDS, S3 and Elasticsearch): we were able to devise a small set of migration strategies that apply to all services, and drive the changes in a centralised manner.
- The impact of each engineer’s expertise is multiplied. The relatively small number of PostgreSQL or Elasticsearch experts across the company can have an outsized impact by advising dozens of teams. Engineers who have grown intimate with, say, the quirks of AWS Application Load Balancers, can share and apply those lessons across pretty much every single service and team in the company.
- Relatedly, the impact of tooling built around the platform is multiplied. Side-projects started by engineers who seek to “scratch an itch” become valuable to the entire organisation. We’ve seen several such side-projects evolve into fully supported platform components. Examples include a “linter” which checks for possible configuration issues and missed best-practices, a bootstrap tool that generates skeleton services, and a key management service that provisions new key pairs for service-to-service authentication at deploy time.
- We can ensure any new AWS features made available to teams are configured and integrated to maintain the security, compliance, operational standards, and best practices that have been incrementally achieved over time. In other words, when a new resource becomes available via Micros, we haven’t just “added” it. We have operationalised it as well: we have done our best to determine relevant metrics and backup strategies, and to make sure it fits in with existing compliance and security standards.
These economies of scale are a consequence of using a consistent, controlled interface to provision and manage services in AWS, combined with sensible bounds on the vast array of AWS features available. Both would likely be degraded if direct access to AWS were the norm.
How the PaaS helps
Let’s take a closer look at how Micros achieves some of the above benefits.
- The platform enforces consistent use of service metadata. All services on Micros have a metadata record (surfaced in a tool we call Microscope) that includes information such as the service owner, team, on-call roster, SLIs/SLOs – this is invaluable for incident scenarios, in which obtaining this kind of information quickly is essential. Micros also enforces consistent tagging of AWS resources, which helps with cost attribution and setting up filters for automated security, compliance, and best-practices scanning.
- The platform also ensures all services integrate with our standard observability tools. Any service on Micros is automatically configured to flow logs into our standard Splunk cluster, metrics into our SignalFX account, tracing to LightStep and of course alerts to Opsgenie. Every service integrates with our availability and synthetic checking tooling. We never have to question where to look for basic diagnostics for a service.
- Thanks to the platform, most engineers don’t need to worry about network connectivity. Micros manages a set of VPCs and subnets with appropriate peering configuration, so services can access the parts of the internal network that they need. Additionally, the platform now integrates with a centrally managed edge, so that all public-facing services will benefit from the same level of DDoS protection and export controls. We also have components running on every node to add a control point for egress, which is used to enforce export controls and for security controls and monitoring.
- The platform helps us meet the company’s security standards. Micros provides a single point which controls load balancer security settings and security group setup. Furthermore, because all services essentially run on the same AMI, we can easily ensure host OS security patches are up to date. We can also provide audited and controlled channels for operational & diagnostics access to services (we make extensive use of AWS SSM commands), and ensure our entire fleet is provisioned with tooling like osquery to improve overall visibility.
- On compliance, the metadata tool mentioned above also tracks information about services’ use of data: does this service handle customer data? What about personally identifiable information or financial data? This allows us to enforce controls at the platform level where warranted. For example, the binaries of services that handle any kind of sensitive data will fail to deploy to production unless we can confirm they come from a locked-down artifact store, and were built by a restricted CI pipeline. The platform also simplifies audits, by ensuring that there is only a small number of teams who need system-level access, and that this access means the same thing, and is controlled in the same way, across all services.
- On data integrity, the platform ensures that all data stores are set up with the right backup frequency, retention and locality. We’ve also built tooling for the data stores that we support to simplify backup/restore processes, to ensure backups are monitored, to execute periodic restore testing, and to provide additional migration and diagnostics capabilities.
- The platform also helps with overall service resilience. It encourages or enforces some of the essential “12 factor” principles, in particular by ensuring compute nodes are immutable and stateless (for example by integrating with Chaos Monkey-like tooling which periodically shuts down nodes). It also provisions services with sensible defaults for autoscaling and alerts, as well as a mandatory spread across 3 AZs in production. This allows us to run AZ failure simulations, in which we periodically evacuate all nodes in an AZ and measure impact on reliability.
- The platform provides a consistent set of deployment strategies, all of which result in zero-downtime deploys, post-deploy verification with automated rollback, and integration with our change logging tooling (to ensure we maintain visibility into what changed and when).
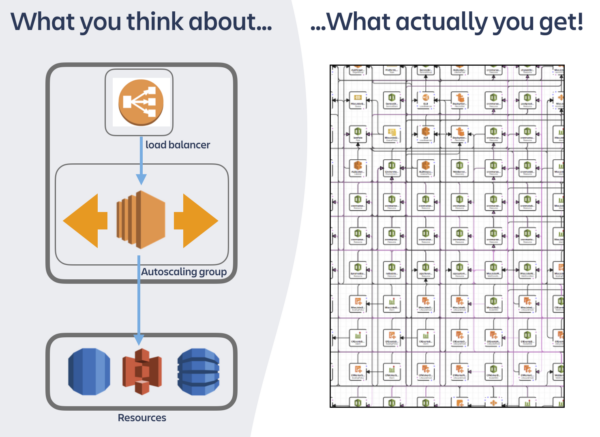
Services on the PaaS can be represented in a simple and homogeneous way: highly available compute combined with whichever backing resources the service needs. However, if you look beneath the covers, you’ll see that the platform has provisioned much more, thereby enforcing sensible defaults for autoscaling, alerting, security, backup policies and more.
The trade-offs of a PaaS – and some mitigations
So, we’ve chosen a strategy which favours a controlled, consistent and hardened subset of AWS features, over free-form access to AWS accounts. This strategy has some trade-offs. For example:
- It may be harder to experiment with and learn new AWS features.
- If an AWS feature is ideal for a given use-case, but is not supported by Micros, engineers have to make a decision between a “suboptimal” but supported AWS features, versus forgoing the economies of scale mentioned above by hosting their service off-platform.
- Some 3rd party tools that engineers would like to include in their dev loop or deployment flow can’t be used in conjunction with Micros, because they require something that doesn’t fit with the platform.
Let’s look at some mitigations to these trade-offs.
Free-for-all access in a controlled Training Account
If teams would like to experiment with AWS features to validate they fit their use cases, or just to learn more about them, we generally point them to the Training Account.
This account has some notable restrictions: it is not connected to the rest of our internal network, and it is purged on a weekly basis. Nonetheless, it’s an ideal “playground” to experiment, validate assumption and build simple proofs of concept.
Extending the PaaS
The above isolated experimentation is valuable but can only go so far. Fortunately, there’s a range of ways in which the PaaS can be extended.
Many resources that Micros provides are integrated to the platform via a curated set of CloudFormation templates. Teams can branch our repository of templates and add their own CloudFormation templates, which can immediately be referenced by Service Descriptors and therefore be provisioned by services in development environments. This allows for the resource to be tried and tested, and for us to examine in detail what would be required to make the resource available to all teams in production.
Acknowledging that not everything one may wish to provision alongside a service is best represented with a CloudFormation template, Micros also accepts extensions in the form of service brokers that implement the Open Service Broker API. In other words, teams can contribute services which may themselves become part of the provisioning flow for subsequent services, by deploying and managing new types of assets defined in the Service Descriptor. Building and running such services is no small undertaking, and we take care to ensure this extension point isn’t used as a vector to pump out PaaS features that don’t have a high level of ongoing operational support. In practice, we have used this functionality primarily to decompose the core of the PaaS, and to scale the PaaS team. For example, this extension point enabled us to spin out an independent sub-team that owns all the platform’s data stores and their associated tooling (including the components that provide their provisioning logic), and to give our Networking team greater autonomy in the implementation and ownership of the platform’s integration with our company-wide public edge.
Aside from expanding the range of resource types that are available to services, some teams need to extend the PaaS by adding to the components that run alongside their service on their compute nodes. To this end, the platform offers a concept of Sidecars – shareable binaries that service owners can add to the set of processes that are spun up when their service starts. These have been used to provide additional diagnostics functionality, local caching for performance and resilience, a standardised implementation of staff authentication, and more.
“Bending the rules” of the PaaS
While we value consistent infrastructure, we understand that sometimes the boundaries of the PaaS are at odds with other factors that put teams under roadmap pressure. Therefore, we sometimes bend the rules of the platform to unblock teams.
All such cases start with a ticket raised on the Micros team’s Service Desk, and often involve a face-to-face discussion so that we can align on the cost/benefit, risks and ramifications of the exception. Once implemented, most exceptions – especially those that could be risky if used without fully considering the implications – are kept behind a feature toggle so that only specific teams or services can make use of them. Examples include sticky sessions (which we discourage by default to avoid resilience issues brought about by unnecessary statefulness), or the ability to target a specific Availability Zone to achieve affinity with a database for latency gains (thereby trading off on the resilience benefit of our being spread across 3 Availability Zones in production).
We keep track of all exceptions, and periodically review them to ensure they don’t stay in place longer than necessary. In many cases, the requests represent temporary relaxations of the platform rules for specific services, so that service owners can get stuff shipped. In other cases, the requests are an indication that the platform boundaries need to shift – and they therefore evolve into broader feature requests.
Working off-platform
There is no mandate at Atlassian that says services must run on Micros. In fact, there is a well established channel for teams to obtain their own, separate AWS accounts that they manage independently.
This flexibility comes with additional responsibilities and considerations, which echo the list above describing where Micros helps. Here are the questions teams must consider before going off-platform:
- Service metadata: do you have appropriate records in Microscope for your services? Are your AWS resources correctly tagged?
- Observability: how will you get your logs into Splunk, your metrics into SignalFX, your tracing into LightStep? Is your service integrated with OpsGenie?
- Network connectivity: do you need access to the internal network? Do you need to call other Atlassian microservices? How are you implementing DDoS protection and export controls on ingress and egress?
- Security: does the Security team have suitable insight into your services? How will you implement changes to security requirements and policies? How are you balancing operational & diagnostics access to services with access control requirements?
- Compliance: What are the implications of compliance certifications for your services? How are compliance controls enforced? Do you review access levels to your infrastructure? Does your team need to be involved in audits?
- Data integrity: Is your backup frequency, retention and locality in line with requirements? Are your backups monitored? Do you do periodic restore testing?
- Service resilience: What is the impact of a node failure on your service? Is your service resilient to AZ failures? Do you have periodic testing for this?
- Deployments & change management. Do you have a mechanism to achieve zero-downtime deploys? To be alerted if a deploy is broken? What mechanisms do you have in place for rollback? How will other teams know what has changed with your service and when?

All services deployed to the PaaS automatically get a record in our internal service directory “Microscope”, which presents essential information about services in a concise and discoverable manner.
Our PaaS is not a wall between our engineers and AWS
It’s worth noting that while Micros adds some functionality and integrations around plain AWS, I avoid referring to it as an “abstraction”, because it is intentionally leaky: Micros very deliberately exposes the details of the underlying AWS infrastructure that it provisions and manages.
For example, services descriptor contains fields very similar to those you’d find in an equivalent CloudFormation template. Once resources are deployed, you can examine them directly via the AWS Console. You can get tokens to interact with them via the standard AWS CLI. From your code, you can use the standard AWS SDKs. We use standard AWS constructs to enforce security policies.
Because engineers use most AWS features directly, many enhancements to existing resources (such as DynamoDB Transactions) become available to you as soon as they land in AWS.
By and large, everything works as documented in AWS docs. It is rare that we add layers of in-house invention between Atlassians and AWS.
(An arguable trade-off is that this coupling with AWS would make a theoretical shift to another cloud provider more difficult. We believe that the concrete benefits we achieve now by avoiding heavy abstractions outweigh the hypothetical efforts we’d need for such a future migration.)
Our PaaS won’t stop evolving
The above helps explain why free-form, direct access to AWS is not Atlassian’s current platform strategy, and that having an internal PaaS is valuable… even if it sometimes feels like it gets in the way!
However, while the PaaS is valuable today in its current form, it cannot stand still. There are two main drivers that will continuously push our platform forwards: the evolving needs of Atlassian engineers, and those of our Cloud customers.
The first driver, the needs of Atlassian engineers, means we will keep improving the developer experience we provide, and increasing the speed at which engineers can innovate & get their job done. This involves reducing the operational burden on developers, and polishing the dev loop. We’re implementing a range of features on that front today, including improved Lambda support to reduce the amount of boilerplate code required for services that primarily react to AWS events, adding Kubernetes as a compute environment to speed up deployment & scale-out time, supporting more pre-configured combinations of backing resources that solve common use cases (such as DynamoDB tables pre-configured to stream to Elasticsearch), and externalising a range of common service-to-service communication concerns to a service mesh layer.
The second driver, the needs of Cloud customers, means the platform has a key role to play in Atlassian’s duty to continuously strengthen our Cloud products’ security, reliability and performance. These cross-cutting concerns cannot be delivered upon at the top of the stack alone. The platform will assist by delivering monitoring improvements to maintain our visibility into our systems as they grow ever more sophisticated, more consistent and centrally observable rules for service to service authorization, and better mechanisms for data classification across our fleet of services.
Tips for getting started
Even if you only have a few services for now, it isn’t too early to start thinking about how a service platform can help your fleet evolve and scale. Here are some points to think about early on:
- Ask yourself which design principles you’d like to be embodied by all your services. For inspiration, perhaps consider The 12 Factor App and the AWS Well-architected Framework. Think about which of those principles could be encouraged – and which should be enforced – at the platform level.
- Think up-front about the service metadata you will want to be able to discover quickly when your fleet has evolved into a sophisticated network of interwoven components. For example, will you want to find each service’s owning team? Its on-call roster? Its SLOs? Its dependencies? Its change history? Its cost? As you look at adopting or building the tools that will form your service platform, consider how they will help you gather and control that information as easily as possible.
- Don’t underestimate the value of consistency as you make technology choices. What seems like a compromise today can pay off many times over, when your fleet is using the same set of technologies, thereby multiplying each learning and improvement.