
Two weeks ago I had the pleasure of speaking at the Jazoon conference in Switzerland about Git workflows. One particular piece that seemed to resonate well with the audience was the idea of looking at the underlying rules when it comes to branch based workflows.
Workflows
A workflow defines steps that represent how your team agrees to get code into production. The workflow being used needs to support a number of different use cases. How do I fix a bug in an old release, how can I make a hotfix of the code that is running in production, how do I do feature development, is the feature done, is the code compiling, are the tests running against the correct changes and so on? Those are questions involving a number of different concerns but the way developers interact with their version control system is an important piece of that puzzle. Therefore when we talk about workflows here we focus only on the source code management. And specifically how to use branches to help your team deliver software.
There are a number of different branch based workflows out there. There is the well-known Gitflow workflow or feature branch based workflows similar to the way we in the Stash team use branches. Those workflows usually provide a number of useful advantages:
- Rules for branch creation (where do I branch off from) and merging branches (where, when and how do I merge changes back)
- A naming convention for the branches that conveys the purpose of the different branches and gives your team a common vocabulary (“never merge master into the release branch”)
- A shared understanding of what the various branches represent and what their expected life time is (long lived production branch vs. short lived feature branch)
While this is very useful, looking at the underlying rules will help with understanding and more importantly enabling you to create a workflow from scratch or more likely adapt an existing workflow to fit your needs.
Significant branches
Before we try to understand the rules around working with branches in Git it is important to acknowledge that there are different types of branches.
Significant branches map to a concept in the outside world. It may be a past release, a particular environment (staging, production) or a role (integrator). Those branches are long-running and stable whereas feature or more generally development branches are short lived and volatile. Short lived branches can be deleted after they have been merged as they are usually not important for the overall history of the project (and the merge commit will point to the tip of the merged branch anyway).
The merge protocol
The most important contribution the various workflow models have made, is a clear understanding of the merging rules that apply. But underlying all those different workflows is a set of very general rules that govern how branches should be merged.
Those merge rules require an understanding of how one branch relates to another branch. Here we are specifically looking at how one branch relates to its baseline. The baseline is the branch where the new branch was originally branched off of, will be merged back into or more likely both.
For the relationship between those two branches, we use the concept of stableness. Although there is no good concrete definition of stableness, it’s easy to have an intuition for it that applies in most cases. The main idea is that a branch is more stable than another branch if using (or deploying) the software on that branch poses less risk. That usually goes hand in hand with more testing done against that branch, less work in progress and/or mainly stabilizing changes like bug fixes or hardening work.
Taking the relationship between two branches and the concept of stableness, we can define the merge rules between the branches. The following approach is based on the “Flow of changes” presentation from Laura Wingerd and what she calls the “baseline protocol”.
Here I will call it the merge protocol as it really centers around merging branches and the rules around doing that.


If a branch is less stable than its baseline
Let’s look at the case where a branch is less stable compared to its baseline. This applies for example to any feature or development branch. For feature development you would branch off of your main development branch, start development and commiting changes as you go. Most of the time your feature branch would be less stable as it contains work in progress that needs to be finished and then tested and deployed. Merging the feature branch into the baseline would therefore only happen when the code is complete.
Merging from the baseline into the feature branch on the other hand can happen whenever necessary as it will bring in the bug fixes and completed features that are already on master. This may be helpful if master contains changes that are required for the development but isn’t strictly necessary if changes on master are unrelated.
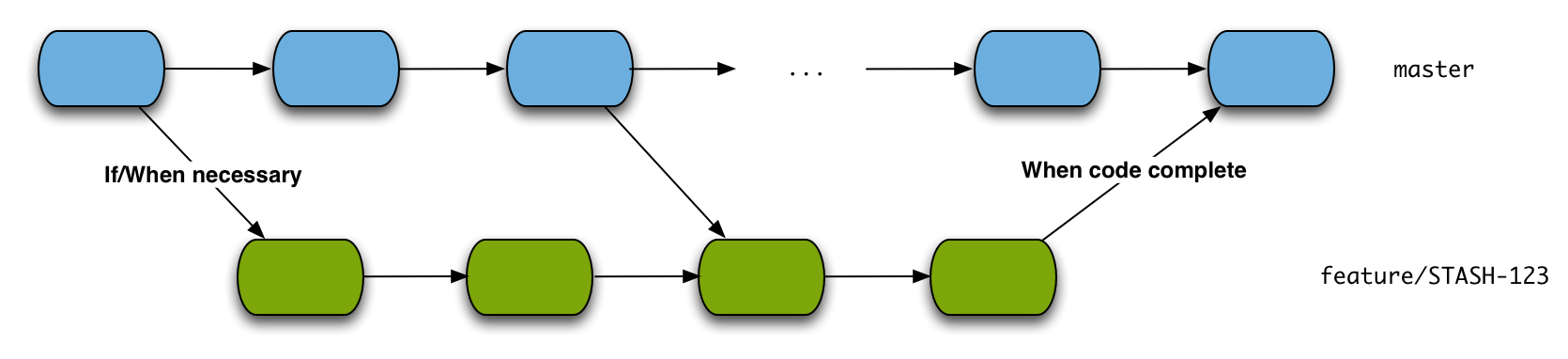

If a branch is more stable than its baseline
An example for a branch that is more stable than its baseline is a release branch.
A release branch will be branched off of the main development branch (e.g. master) prior to a release. After branching off the release branch will only receive bug fixes or hardening changes to stabilize the software on the branch until it is ready to be released (which usually involves tagging a certain commit to be able to easily identify the release version). When looking at the merge rules it doesn’t really matter if the release branch is long-running (i.e. it will still be available after the release was done for further maintenance/bug fix releases) or short lived.
If we look at the first case where changes flow from the more stable branch to its baseline (i.e. from the release branch to master) we can see that we can continually merge the stable release branch into the baseline. This intuitively makes sense. As the release branch only receives bug fixes or more generally stabilizing changes we need to ensure that those changes are also present in the next version. It also poses very little risk to let the stabilizing changes flow into the baseline. Hence merging the release branch into master continually has a number of benefits:
- It ensures that bug fixes are always present in the baseline branch as well (see https://www.atlassian.com/blog/2013/05/git-automatic-merges-with-server-side-hooks-for-the-win/ for an approach that even uses automated cascading merges)
- It lets the SCM (i.e. Git) track this fact for us. There is no need to define processes other than merging regularly to ensure that bug fixes are also applied to the baseline branch.
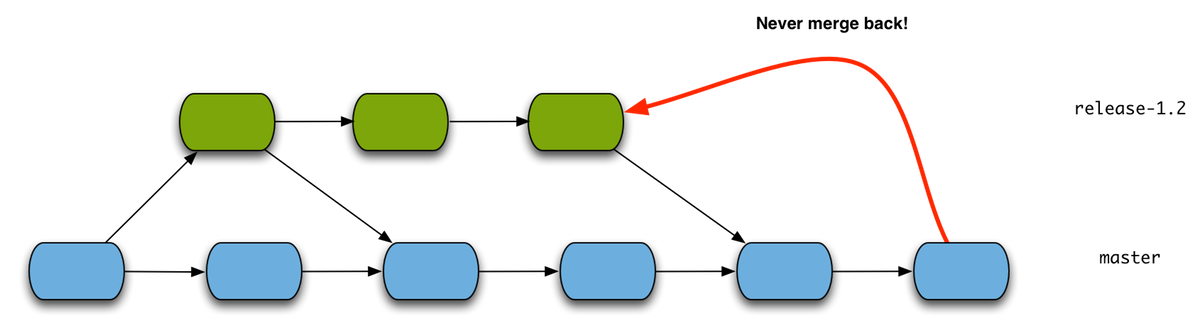

Changes from the baseline to the more stable branch on the other hand are a no-no. You should never merge back from the baseline into the more stable branch! Again, looking at how the changes evolve this makes sense. Consider a long-running release branch that was created to release version 1.1 of your software. Your current development branch “master” will slowly evolve and receive various changes (new features, general development, bug fixes related to the new feature work that is happening) that will ultimately end up in the next version of the software (e.g. 1.2). If you would merge master into the release branch it would receive all those in progress changes and features that are slated for the next release, something you want to avoid at all cost on your release branch for the older version.
Never is a strong word
An additional rule helps with scenarios where changes that happened on master need to be applied to the more stable branch. While following the merge protocol prohibits you from merging the changes, using git cherry-pick can be used to backport changes one by one. This will help you in scenarios where a bug was fixed on master and only after the fact you decide that it should have been applied to older release as well.


Merge tips
With a simple set of rules, a merge based workflows can be easily understood and more importantly extended. But in addition to thinking about the merge rules, merging itself needs to work for your given project. A couple of Git tips may help you make merge based workflows work for your team.
Merge always
You will hopefully see the benefits of merging a stable release branch into your master. But looking at your current project you may be thinking about challenges that prevent you from applying this merge based workflow to your project. Whether it is meta information that you store in your repository that relates to a particular branch (e.g. version numbers) or specific changes you don’t want to merge into the baseline (e.g. bugs were fixed in features that aren’t even present anymore in the newer version). Sometimes a change cannot be applied or would have to be immediately reverted which prevents you from continually merging your changes.
A specific example of a change that you cannot merge is versioning information (although it’s debatable whether that should be stored as content in the repository). In Stash we use the Maven release plugin which at release time updates all the Maven pom XML files with the new release version (e.g. 2.4.2), commits the change, tags the commit, updates the pom files again with the next development version (e.g. 2.4.3-SNAPSHOT), commits the change and pushes the changes back into the repository.


This is a set of changes you don’t want to merge to the baseline as the baseline is usually ahead (e.g. 2.5.0-SNAPSHOT) and shouldn’t be updated with “older” version numbers.
Merge strategies
Enter merge strategies. Git abstracts the way it merges changes by enabling different merge strategies.
The simplest merge strategy (called resolve) is the traditional three-way merge. When merging a branch foo into master, Git resolves the common ancestor between master and foo and conceptually applies the changes from the common ancestor to the tip of branch foo to master.
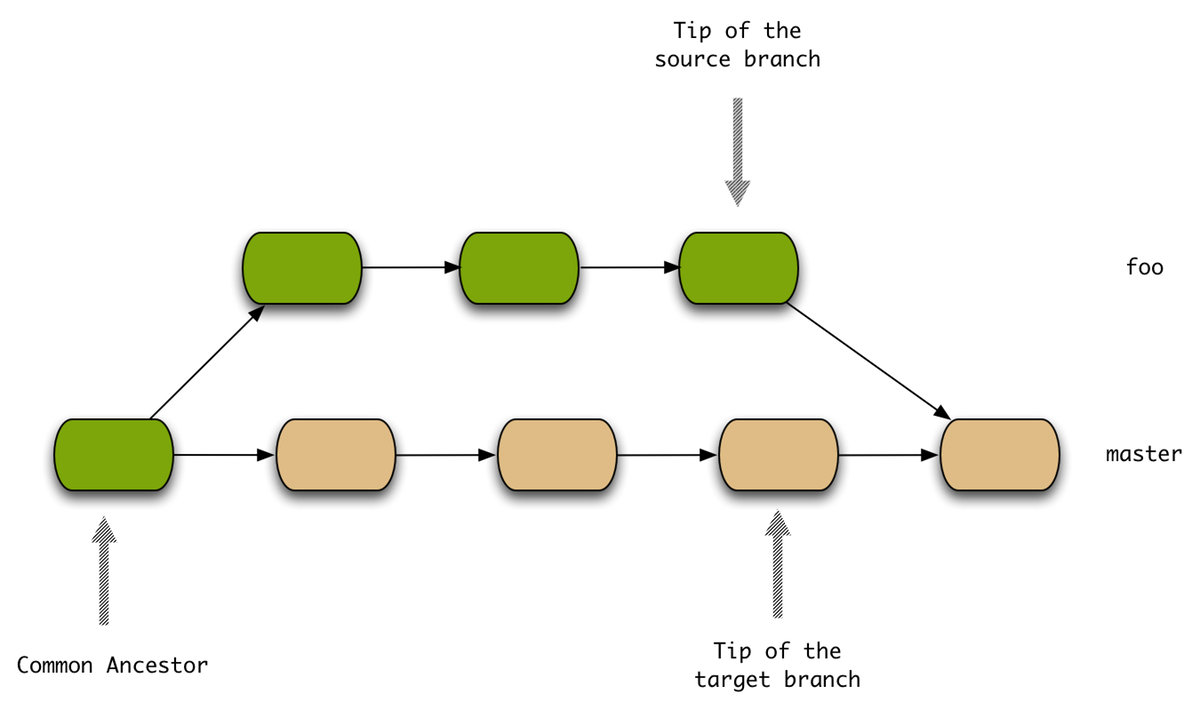

An alternative merge strategy that comes in handy for the particular problem we face is called ours. The ours merge strategy creates a proper merge commit (i.e. the commit points to both the tips of master and branch foo at the time of the merge) but discards all the changes from the source branch. This is important to stress, only use the ours strategy if you don’t want any changes to be merged into the target branch.
In our case we continually merge from the release branch into master to get all the bug fixes, do the release and then merge the two release commits (e.g. the 2.4.2 and 2.4.3-SNAPSHOT changes) using the ours strategy. We, therefore, don’t get the changes we don’t want to apply to the baseline but as Git records a proper merge commit, all the future merges won’t attempt to apply those changes either and we can keep merging the bug fixes we do want.
[cclN_bash]
$ git checkout master
$ git merge -s ours foo # Merge foo into master, discarding any changes on foo
[/cclN_bash]
Make sense of merge history
A common complaint of merge based workflows is the perceived difficulty of making sense of the history. Nicola touched on this in his post on merge vs rebase based workflows.
git log and the --first-parent option cannot only be used to simplify an unwieldy merge history, hence making it easier to understand what happened:
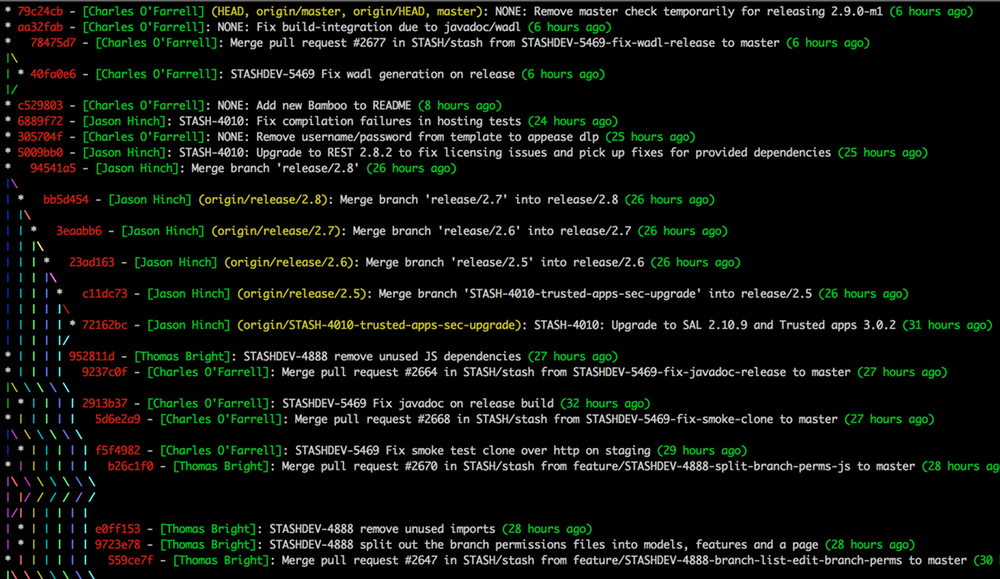

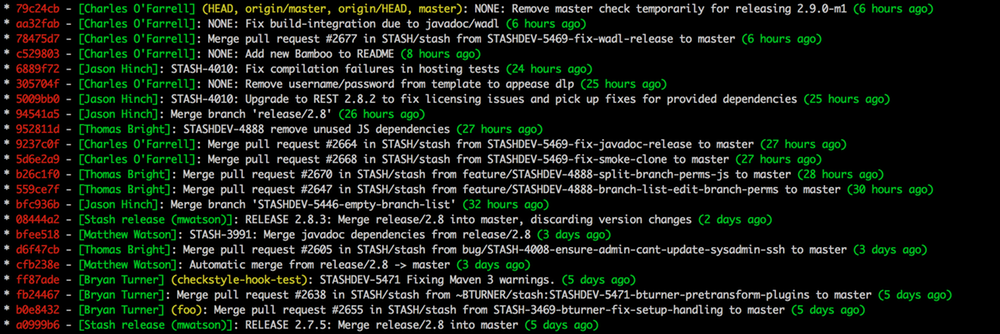

The --first-parent option is also a good tool to check whether you and your team are doing the right thing. In a branch based workflow the history as shown by looking at the first parent only should show you mostly merge commits (e.g. where you merged changes in via pull requests) and only some trivial changes directly applied to the main branch.
Summary
With a simple set of merge rules, you can not only explain the plethora of workflows that are being used, you can also use the rules to extend existing workflows and to adapt them to the needs of your team.
Anyone can be good, but awesome takes teamwork.
Find tools to help your team work better together in our Git Essentials solution.