I stepped into the role of Head of Engineering for Bitbucket Cloud in late 2020, having served as one of the team’s senior engineering managers for several years. It is an honor and a privilege to lead this team, and I couldn’t be prouder of the hard work we’ve done and continue to do each day to make Bitbucket a world-class product empowering teams to build, test, and deploy software to millions of people around the world.
It has been an eventful journey, and the past few weeks are no exception.
Recent performance incidents
Back in October, our previous Head of Engineering Robert Krohn shared a blog post to provide transparency about a recent major incident that had affected customers as well as share some impressive performance improvements the team had delivered. Today I’d like to do the same for some recent incidents in late March and again this month that have been especially trying, for our customers but also for our engineering teams. Fortunately I also have another set of improvements to share, along with plans to continue investing in the reliability and speed of our services.
It would be fair to ask how these recent incidents are any different from past events such as those explained by my predecessor. This is a good opportunity to differentiate between reliability and performance. While these two concerns are highly correlated, they do not always go together. As an example, shifting expensive workloads from high-performance inelastic infrastructure to new infrastructure that sacrifices some speed for scalability could improve reliability while increasing execution time.
Much of our investments on Bitbucket Cloud over the past year have been focused on reliability—investing in better monitoring and alerting, moving to more scalable architecture, etc. Recently our customers experienced severely degraded performance causing pages to load very slowly and Git operations to appear to hang or time out. While our services did not experience outages during these incidents, this performance degradation was nonetheless highly disruptive to developers trying to use Bitbucket, highlighting the importance of treating performance and reliability as equal partners.
Extinguishing the fires
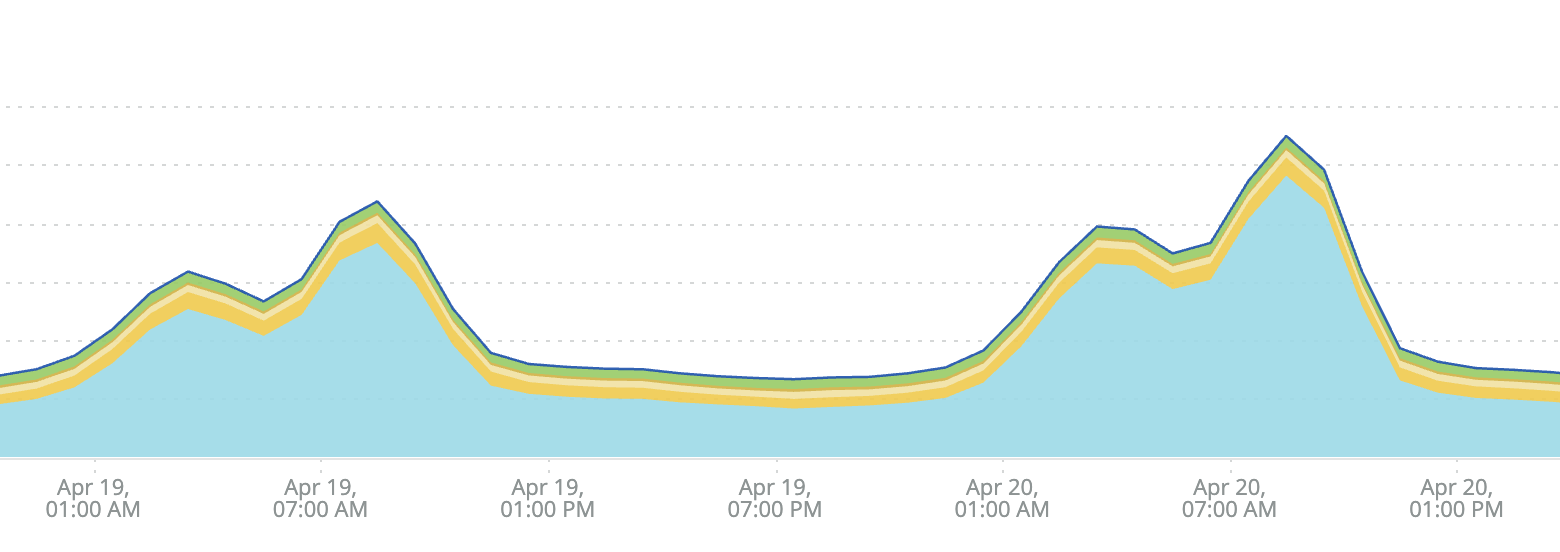
As the team dug in to investigate our performance degradation issues last week, one key discovery emerged early on: by far the biggest contributor was Bitbucket’s file system layer, the piece of our infrastructure responsible for facilitating application access to customers’ source code. This is represented by the blue area in the following graph showing peaks in our response times last Monday and Tuesday.

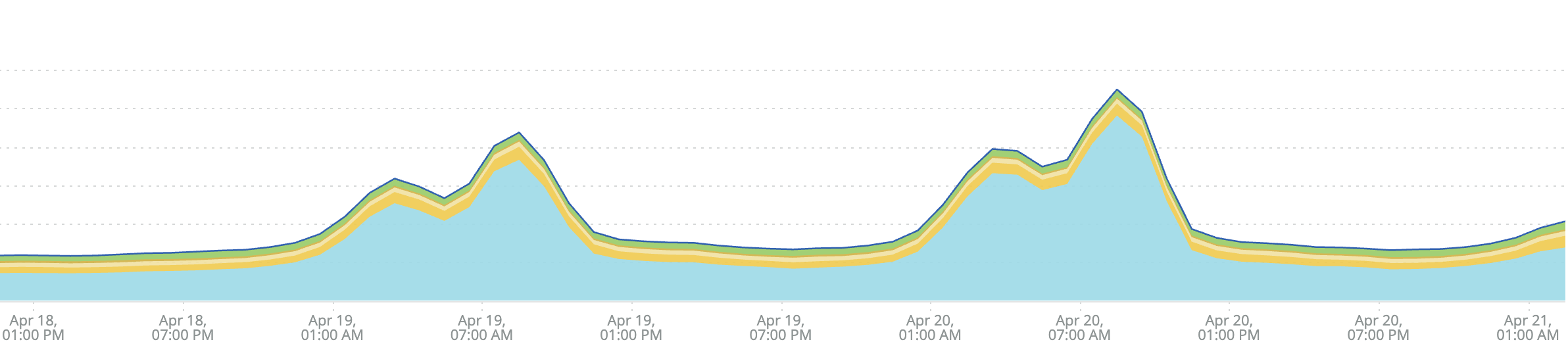
Every other performance factor, such as databases, caches, and external web requests, were relatively stable in comparison to file system operations. (You can see that the other colored areas do not show as much variation as the blue area.)
A thorough explanation of what we ultimately discovered regarding the root cause of these performance issues will have to wait for a future blog post. While the investigation proved challenging, this early signal helped us kick into action right away on a plan to mitigate the impact to customers:
- By offloading as much work as possible away from the file system and onto lower-latency parts of the infrastructure (e.g. caches)
- By identifying expensive operations that depend on the file system that we could stop doing entirely (after all, the fastest code is the code which does not run)
Caching packfiles
One of our greatest sources of file system throughput has always been Git traffic: developers cloning repositories, pulling their teammates’ changes, and pushing their own code. The load of these operations is increased by an order of magnitude by CI tools such as Pipelines, Bamboo, or Jenkins. Customers often have these tools configured to poll Bitbucket for changes, sometimes on aggressive schedules (e.g. every minute!), which can generate huge amounts of file system I/O.
Over the past couple of weeks, our engineers have rolled out an optimization to cache and serve packfiles without touching the file system for repository clones and fetches, which has slashed throughput nearly in half.




While this change does not directly improve the performance of Git operations, it dramatically reduces load on our file system layer, which in turn makes response times faster across all endpoints that perform file system operations.
Custom libgit2 ODB backend
While our Git services have historically been the biggest contributor to our file system throughput, our website and APIs are no slouch either. Rendering source code, commit messages, and especially computing diffs between versions are all expensive and I/O-bound operations.
The services powering Bitbucket’s website and API layers are implemented in Python and use a custom library to handle all access to repositories on disk. This library uses the libgit2 C library under the hood, which has support for pluggable custom backends including an ODB (object database) backend—allowing consumers to specify a data source other than the local file system for looking up Git objects.
A few months ago, a few of our engineers had implemented a proof of concept for a custom backend introducing a high-performance caching layer between libgit2 and the file system. We have had this custom backend enabled in a staging environment for the past couple of months, occasionally identifying minor issues and optimization opportunities along the way before deciding it was ready for production. Over the past week, we have enabled this backend for all users, reducing throughput by more than 30%.

Warming and sharing diff caches
One of the most expensive things the Bitbucket website does is compute and render diffs. Diffs are everywhere in Bitbucket: reviewing a pull request, viewing a commit, and comparing two branches all require the computation of diffs. Even functionality that doesn’t involve showing a diff sometimes requires computing it, for example to produce diffstat information (summary of files and lines added, changed, and removed between versions of a file) or detect conflicts.
We were already caching diffs in many places to speed up response times, but this caching was ad hoc: different code paths that computed the diff would cache it independently, and even the caching backend itself wasn’t consistent in all places; some cached diffs were stored in Memcached, others in temporary files in a shared directory.
Our engineers have started rolling out some major optimizations to these code paths, which consolidate caching (reducing resource usage) and leverage known access patterns to ensure caches are “warmed” prior to being checked. Here’s an example: the pull request view utilizes a diff behind the scenes to detect conflicts between the source and destination branches. By updating the UI to defer the request for these conflicts until after the diff has rendered—which ensures the diff is already cached when it’s time to check for conflicts—our engineers were able to increase the cache hit rate for the conflicts API endpoint to nearly 100%, resulting in a huge drop in response times.

Rebuilding for the future
While I’m thrilled at all of the improvements our engineering teams have been able to make in just the past couple of weeks, I also know from experience that software does not maintain itself (no matter how hard I wish it did!), and that includes performance. Left unchecked, response times will trend upward over time, resource usage will climb, and both reliability and performance will naturally erode.
In order to preserve and build on our recent performance work, we will need to increase our investment in these areas. This investment will take the following 3 forms:
- In addition to the reliability SLOs our teams have been internally tracking for months now, I will work with each of our teams to formalize complementary performance SLOs so that we are holding ourselves accountable to maintaining high-performing services.
- We are already in the process of transitioning to a new ownership model where our engineering teams are empowered to look after a broad set of performance metrics and take appropriate action. This should improve our rate of pursuing proactive measures as well as responding more efficiently to incidents like these in the future, when a system-wide infrastructure issue affects capabilities spanning services owned by multiple teams.
- Finally, we will be taking this opportunity to identify automation we can start building to provide guardrails and build a better defense against future performance bottlenecks. This will include both functional tests to detect common sources of performance regressions as well as programmatic circuit breakers to automate incident response and minimize our TTR (time to recover) wherever possible.
A commitment to transparency
Last but not least, I intend to continue keeping you informed of the challenges we face and the investments we are making to enhance Bitbucket’s performance moving forward. We understand that you have placed your trust in Bitbucket Cloud, and we do not take that trust for granted. An increased focus on transparency is one of the key ways in which I believe we can deepen that trust, while providing an interesting and perhaps educational look at some of the engineering action going on behind the scenes every day to make Bitbucket Cloud the software collaboration and delivery platform of choice for millions of professional teams around the world.