Bitbucket Cloud is a Git based code hosting and collaboration tool that allows you to interact with your repositories over either HTTPS or SSH. The services that host each protocol share many common components and underlying infrastructure, but in the past, SSH has outperformed HTTPS when uploading large amounts of data.
In March 2022, we deployed a fix that made the push speed for HTTPS up to eight times faster! If we take the example of importing a large 2GB repository, this fix could mean the difference between it initially taking two hours and now taking only 15 minutes.
In this post, I’ll take you through how the Atlassian Networking Edge Services and Bitbucket Cloud engineering teams worked together to improve HTTPS push speed.

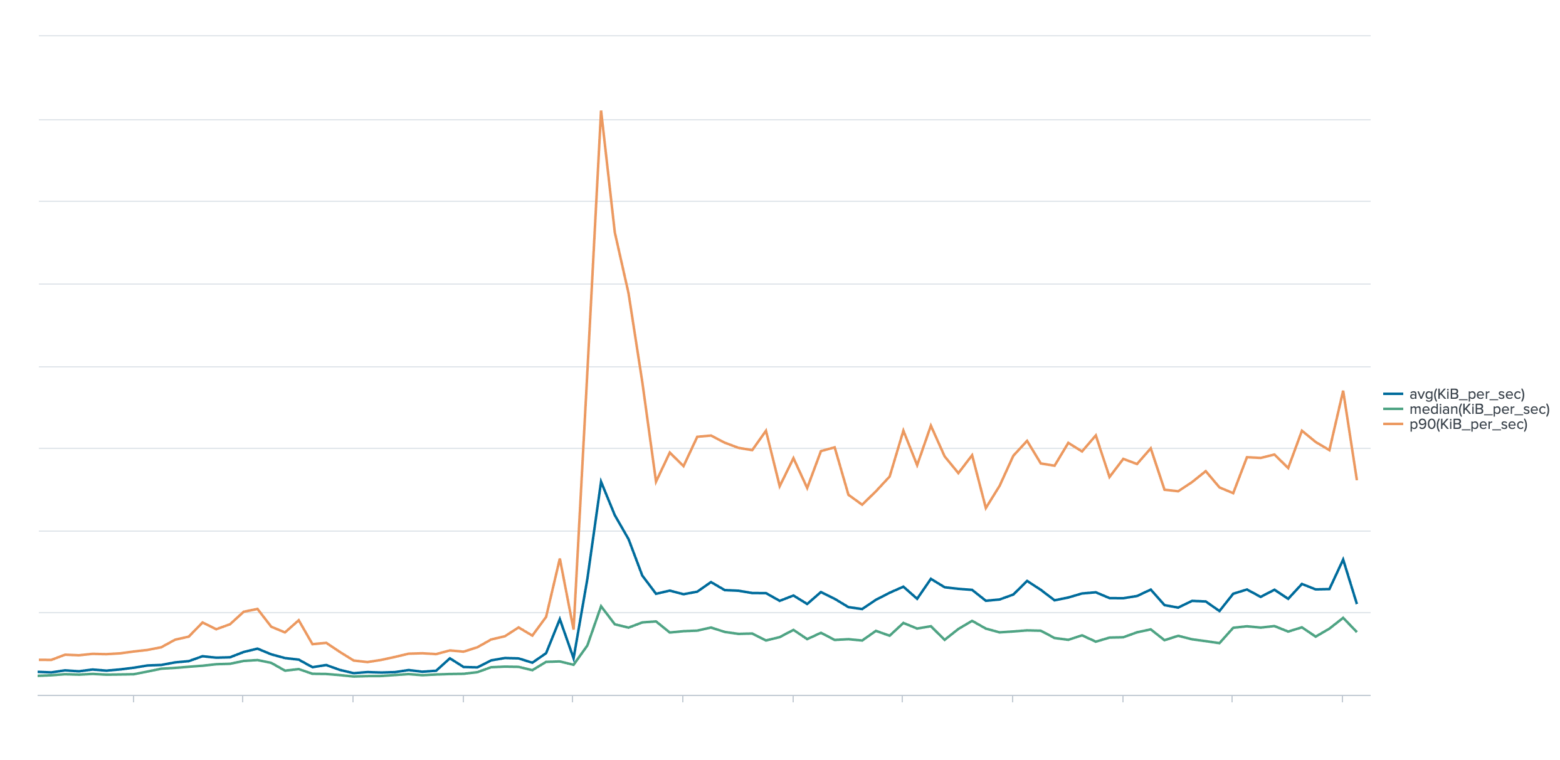
git push speeds (average, median, and p90) over HTTPS for a subset of pushes over a period of four days. The spike shows the change in speed when the fix was implemented.If you’d like to skip the backstory and investigation, you can jump straight to the sections discussing the fix and customer impact.
Discovering the problem: slow data center to cloud migrations
The Bitbucket Cloud team had been working on preparing Bitbucket Cloud Migration Assistant to support the scale of our data center customers.
While performance testing the upload of a large repository from an AWS instance in ap-southeast-2 (Sydney), an engineer noticed that push speeds seemed to be throttled at a speed significantly slower than we expect our infrastructure to be able to serve:
Writing objects: 3% (814501/21340058), 176.92 MiB | 253.00 KiB/sWe know our data center customers have large repositories so slow transfer speeds like these would slow down their migrations.
As a Bitbucket Cloud engineer on the Repository Infrastructure Platform team, I was brought in to investigate this issue. Our team is responsible for the services that handle Git requests, including our HTTPS and SSH infrastructure.
Repository infrastructure platform investigation
Suspect 1: Network filesystem troubles?
At first, I suspected that this could be an issue with our network filesystem that stores our repositories. I wanted to test the hypothesis that a large burst of I/O could trigger throttling at the filesystem level and result in a slow push.
I did a quick test, pushing a test repository to Bitbucket Cloud.
Over HTTPS
Writing objects: 3% (25923/784337), 6.10 MiB | 306.00 KiB/sOver SSH
Writing objects: 29% (227760/784337), 44.30 MiB | 2.05 MiB/sClue 1: A HTTPS and SSH push for the same repository will write to the same filesystem, so this likely eliminated a filesystem throttling issue.
Suspect 2: Sydney internet problems?
The above push test was run from a machine in Sydney, Australia and Bitbucket Cloud is primarily hosted in the United States’ east coast region. Could the issue be related to slower transfer speeds due to the geographic distance?
I tried running the same tests from a number of different clients on separate machines:
| Client | Location | HTTPS Repo Push |
| #1 | ||
| #2 | ||
| #3 | ||
| #4 |

The results were repeatable and consistent for each client.
Clue 2: Something specific to a client was affecting max push speeds, but it doesn’t seem to be the client location.
Suspect 3: The edge?
I took my results to the Atlassian Networking Edge Services team who is responsible for the edge layer infrastructure that exposes Bitbucket Cloud backend services to our customers.
An Edge engineer agreed that the results of my investigation were strange, and I quickly managed to nerd snipe them into helping me solve the problem.
We set up a packet capture on one of our edge load balancers to inspect what was happening at the network layer for a given push operation. We ran push tests from both a fast and slow client, and compared side by side what was different about the packets.
They looked pretty similar, but we did notice three differences:
1. Window size
The window size of the packets for the slow transfer were smaller, and hit a capped limit.
The receive window size is communicated from the edge load balancer to the client in every packet. This defines an upper limit on how much data the client can send at any one time.
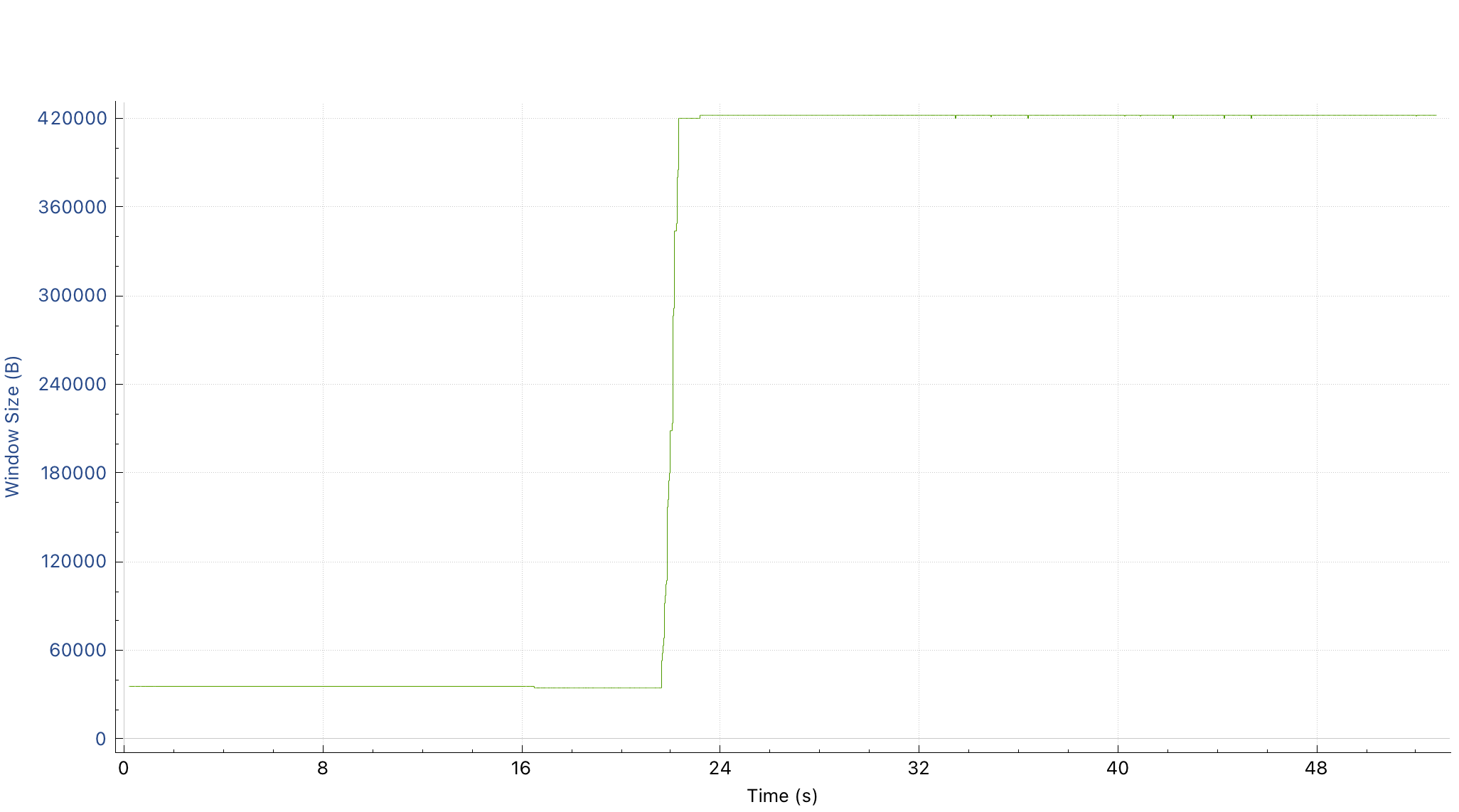
We saw that for a slow push the receive window was flat-lining at a low value and not triggering TCP congestion control.

For a fast push however, we saw that the receive window communicated by the edge load balancers was significantly higher for the fast client. This means—that for some reason—the load balancer was allocating a larger receive buffer, allowing this client to push data much faster.

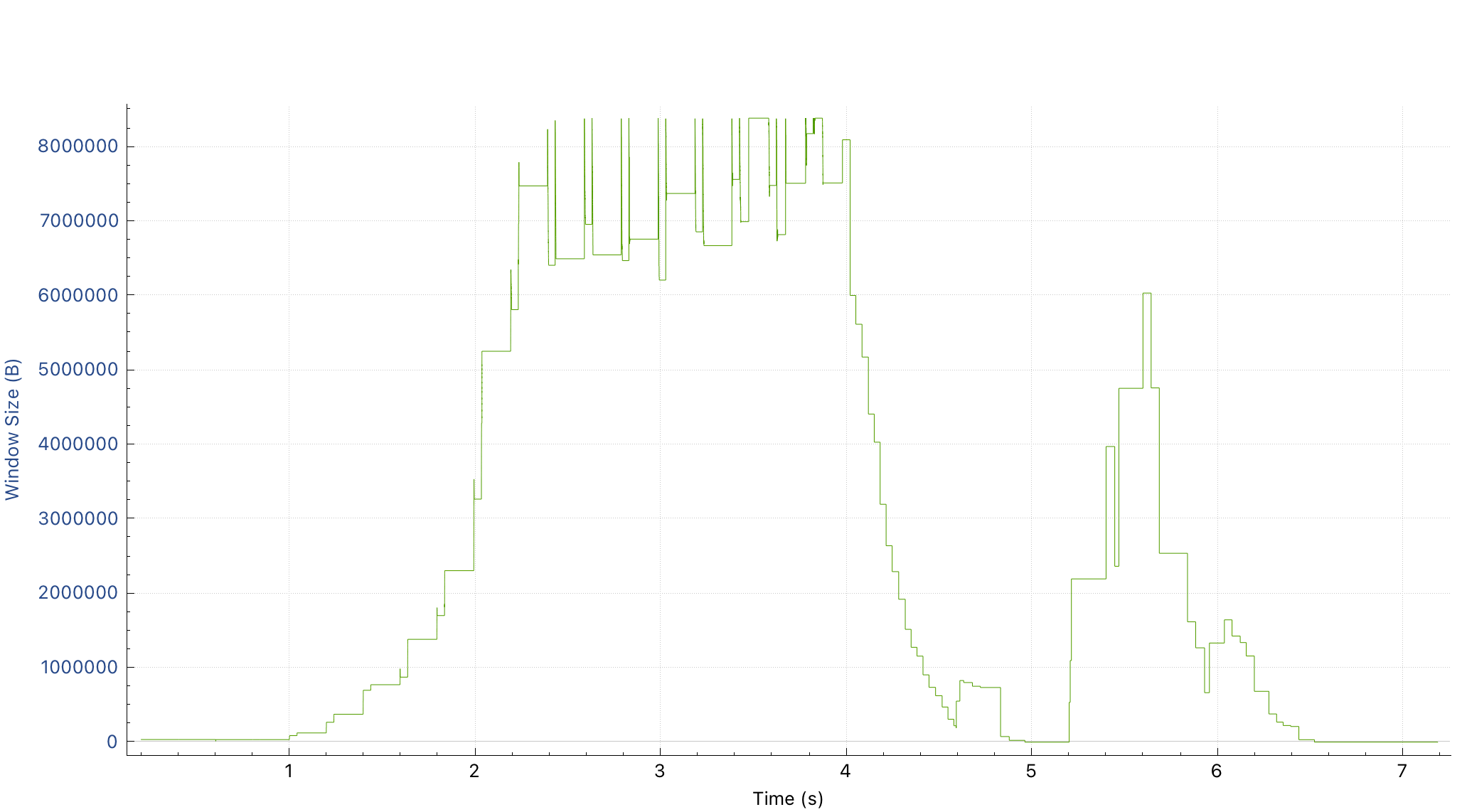
Note the difference in scale—the slow push ceiling would be barely visible on this graph.
This graph also shows the receive window increasing per Linux’s implementation of auto-tuning, and then TCP congestion control taking over.
Clue 3: The window size flat-lining appeared to indicate a limit being imposed somewhere.
2. Git version
The client Git binary version (based on the User-Agent header provided by the client) was slightly different between a fast and slow client. A quick upgrade and retest showed this wasn’t causing the issue.
3. HTTP Protocol
We found that the HTTP Protocol differed. For a fast transfer it was HTTP/1.1, and for a slow transfer it was HTTP/2.
Clue 4: The HTTP Protocol was the first independent variable we’d seen that appeared to influence whether a transfer was fast or slow.
Suspect 4: The HTTP protocol?
We then tested a push from the same client over both the HTTP/1.1 and HTTP/2 protocols:
HTTP/1.1
$ git -c http.version="HTTP/1.1" push ...
Writing objects: 53% (415699/784337), 74.55 MiB | 2.11 MiB/s
HTTP/2
$ git -c http.version="HTTP/2" push ...
Writing objects: 2% (18582/784337), 4.44 MiB | 305.00 KiB/s
We quickly looked at the configuration of our Edge Load Balancer, specifically the settings around HTTP/2 connection buffers and maximum frame sizes.
We noticed that these settings were set to default values which were not optimized for a large scale service.
We reconfigured one of our non-production Edge Load Balancers to test whether these settings were impacting transfer speeds.
Default HTTP/2 settings
$ git -c http.version="HTTP/2" push ...
Writing objects: 2% (19956/785209), 4.86 MiB | 321.00 KiB/s
Updated HTTP/2 settings
$ git -c http.version="HTTP/2" push ...
Writing objects: 79% (620316/785209), 109.06 MiB | 7.46 MiB/s
Our investigation identified that the issue was:
- Not caused by the filesystem.
- Not caused by the network connection.
- Caused by unoptimized defaults for HTTP/2 connections at our edge load balancer.
The fix
Once we understood the source of the problem, the solution was clear. We tested and updated the HTTP/2 protocol specific settings for frames and streams:
- Max Frame Size: the maximum size of a frame that the client can send.
- Preferred Frame Size: the preferred size of a frame that the client can send.
- Stream Buffer Size: the maximum amount of memory allocated to buffering incoming packets for a stream.
These settings all influence flow control, which is how the load balancer manages contention by setting the receive window. By increasing the value of these settings from their defaults we were able to scale above the artificially capped receive window.
Customer impact
Push size
Most pushes to Bitbucket Cloud are quite small. When changes are committed and pushed to a Git repository only the minimal amount of data is transferred using packfiles. This means pushes are usually a couple hundred kilobytes maximum.
At that scale, slow push speeds usually don’t matter. Which is how this issue has gone mostly unnoticed and unfixed for so long.
When do slow push speeds matter? Cases like the import of a large preexisting repository, which is exactly what happens for our data center and server customers that are migrating to Bitbucket Cloud.
Latency
Customer network latency to bitbucket.org would have influenced just how much throttling a slow push experienced.
This is because the artificially capped receive window meant that more packets would be required to transfer data. A higher network latency would result in greater overheads in the acknowledgement of these packets, and hence a slower transfer speed.
What’s the result? Users close to our infrastructure on the US east coast would have experienced the least amount of throttling. Users with higher latency connections (for example, in Sydney) would have experienced a greater amount of throttling.
What kind of speed increases can customers expect?
For a pathological case (a high latency but high bandwidth connection), we’ve been able to test and observe a peak push speed increase of 70x greater than prior to the fix.
Let’s look at the real improvement that was seen by customers in the week following the rollout of this fix. The following graph shows the proportional increase (how many times faster) pushes were compared the same time 1 week prior.

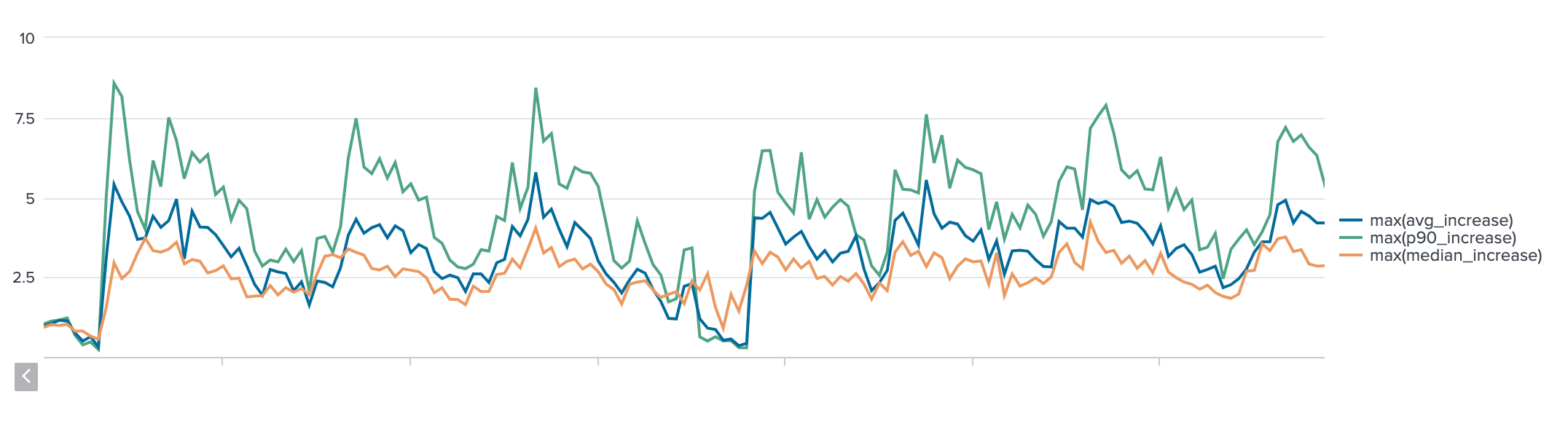
This graph shows that the proportional increase changes depending on the time of the day. This is due to the average latency of customers that are pushing at that time of day, which is correlated with the geographical shift of our traffic.
Depending on where customers are in the world, they will have experienced a 2–8x increase in HTTP/2 transfer speeds for large pushes.