
How to build an incident response plan
On October 21, 2016 at approximately 4am PST, the internet broke. Ok, ok we know the internet doesn’t “break.” But hundreds of important services powering our modern web infrastructure had outages – all stemming from a DDoS (Distributed Denial of Service) targeting Dyn, one of the largest DNS (Domain Name System) providers on the internet.
Web applications like Dyn are built on top of a network of other web services and technologies. So, whether you’re relying on a DNS provider, a billing platform, or a social media app, you’re also relying on the collective performance of their structural services. You’re expecting them to run – and run well – 24/7.
Life in the cloud & the need for an incident response plan
What’s interesting about this attack is the era we’re in. Cloud web infrastructure has really taken off – especially in the workplace. We’re comfortable using web-based software to store and manage our workplace data in a big way. Think using Salesforce to store customer information, or Dropbox to save documents.
All of these web services help us work, build, and share information faster than ever before. But with this efficiency comes a vulnerability: sometimes a really important domino (like Dyn) in your stack tips over. As more and more cloud services became unavailable the day of the Dyn attack, the domino effect ensued, causing one of the largest internet outages in recent history.
Downtime is inevitable for all cloud services, and it doesn’t need to be caused by a massive DDoS attack. In fact, downtime can be triggered by a one-line-of-code bug in production. In the aftermath of this outage, let’s figure out how – as an industry – we can learn from the incident and think about proper response action plans.
There is no time like the present – especially while incidents are top of mind for many people – to create an incident response plan or hone your existing one. Frequent and open communication during an incident can help turn a bad situation into a great customer service experience and build user trust. There doesn’t have to be a major DDoS attack for it to come in handy (think bugs in production, website issues, login issues, etc.). No matter what the problem is, you’ll never regret some good old-fashioned preparation.
Important incident response considerations:
Define what constitutes an incident:
- How many customers have to be impacted?
- How long does the incident need to last?
- How degraded is the service and how do you determine severity level?
Create your incident communication plan:
- How do you identify the incident commander?
- Who owns the communication plan?
- How will you communicate with users? What channel(s) will be used for different severity levels? (i.e. Statuspage, Statuspage + Jira Service Desk, Twitter)
- Do you have templates for common issues you can pull from to accelerate the time from detection to communication?
- How will you follow-up post-incident and work to avoid similar incidents in the future? Are you prepared for a post-incident review? At what point do you need to write a postmortem?
Incident Response IRL
There are lots of services out there that can help power your incident response such asStatuspage, a tool we recently added to the Atlassian family. Statuspage allows you to easily communicate the status of your services to the right users at the right time.
We want to give some major kudos to the teams at Dyn who worked around the clock to get things up and running again. They did a killer job of communicating clearly and regularly through their status page even in crisis mode, proving how important it is to have a communication plan set before an incident occurs. News outlets like the New York Times were even able to link to Dyn’s status page and quote their status updates during the incident.
Let’s take a closer look:
- Total number of updates: 11
- Average time between updates?: 61 minutes

Dyn also posted an incident report the following day and provided a link to a retrospective blog post that gives readers more information about what happened, how their teams responded, and how grateful they were to the community that came together to help resolve the issue. The frequency and transparency of Dyn’s communication allowed users to stay informed even during a time of great stress and uncertainty.
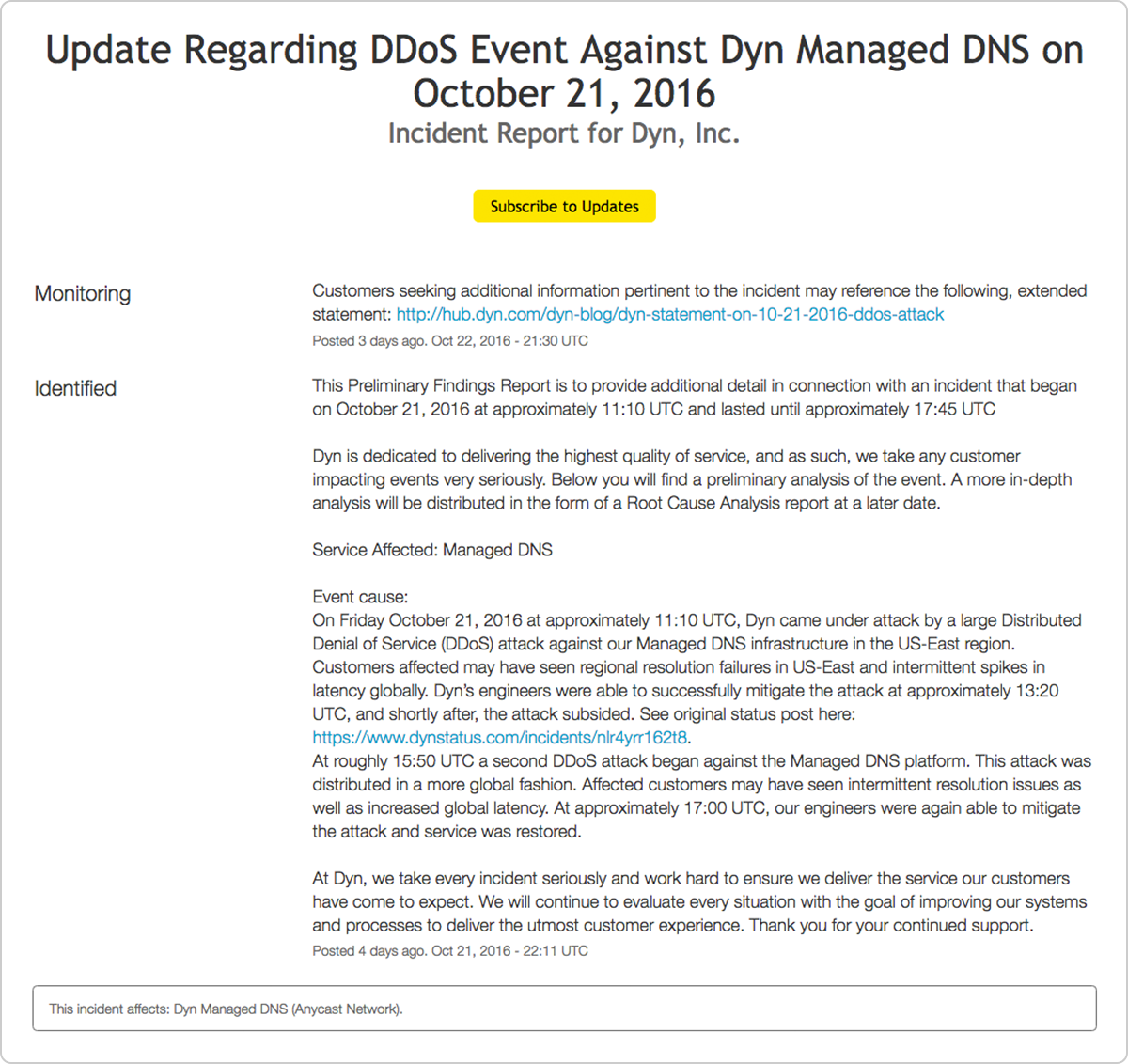
In the end it was a tough day for Dyn, but the open and honest communication built trust within their community.
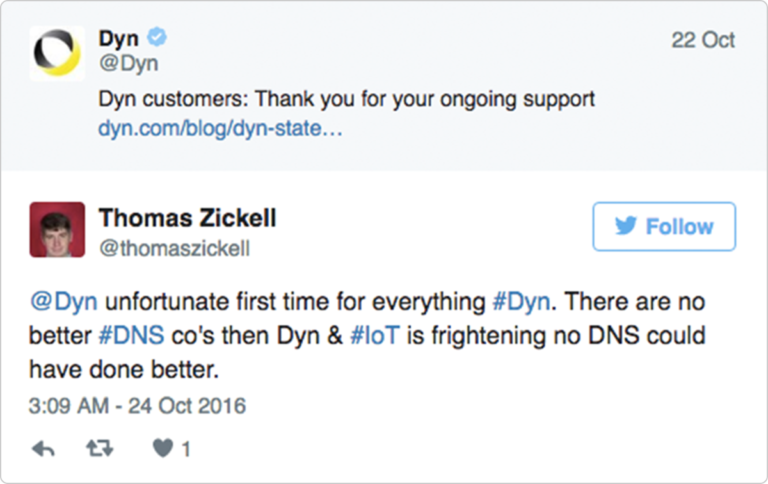
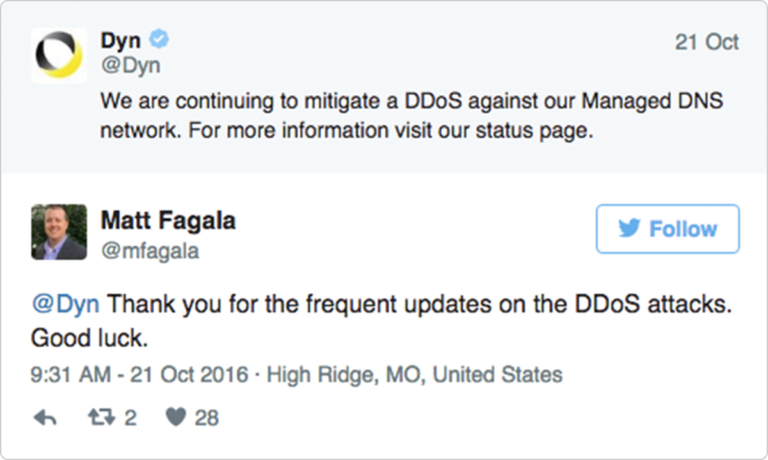
The Domino Effect
Thousands of the top cloud services in tech including Dropbox, Twilio, and Squarespace use Statuspage to keep millions of end users informed during incidents like this. Since we all love a good data-driven infographic, let’s look back on 10/21 when the dominos began to fall and we found ourselves watching over 1 million notifications fire through our system:
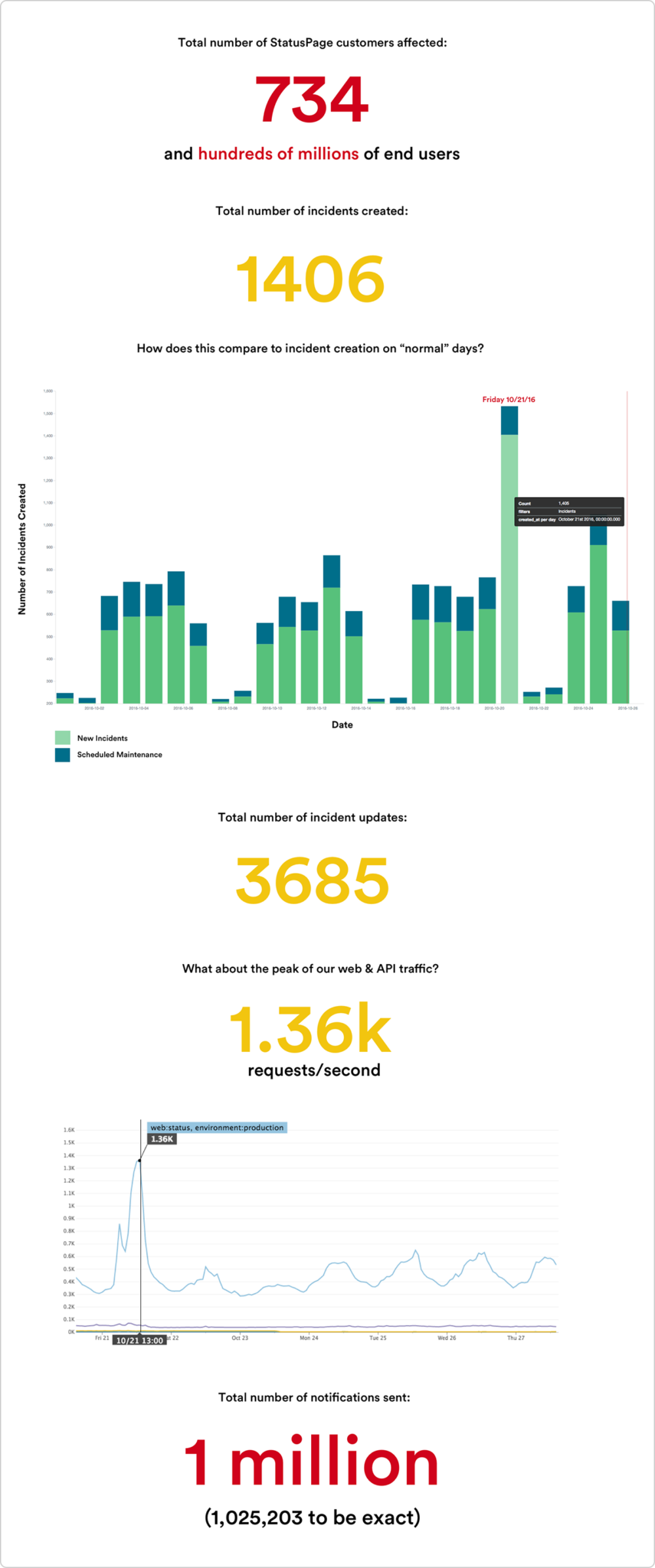
While we hope there is never a “next time,” we know incidents similar to this are an inevitable part of a cloud services centric world. Having a vetted incident response plan in place ahead of time and a dedicated way to communicate with your customers – whether that’s through a status page or other dedicated channels – will let your team focus on fixing the issue at hand while building customer trust.