

As part of the Service Collection announcements at Team ’26 Anaheim, we’re excited to introduce new AIOps integrations with Lansweeper, Coralogix, and Honeycomb.
IT Operations teams already rely on best-of-breed tools for asset discovery, log analytics, and distributed tracing — but that intelligence often stays siloed from the workflows where decisions actually get made. With new integrations for Lansweeper, Coralogix, and Honeycomb, teams can bring specialized telemetry and asset context directly into Jira Service Management, while the Atlassian platform connects this data to the Teamwork Graph and makes it accessible to Rovo agents via Atlassian’s remote MCP server.
The result? Faster detection, more confident diagnosis, and less swivel-chair work — powered by automation that IT Ops teams can trust and explain.
Read on to learn how each integration helps bring this vision to life!
Lansweeper: Accurate cyber asset intelligence for safer changes and faster triage
Lansweeper specializes in deep, continuous discovery of hardware, software, and dependencies across on‑premises and cloud environments. Combined with Jira Service Management, that data becomes the backbone of a living configuration and service graph that responders, site reliability engineers, and change managers can rely on.
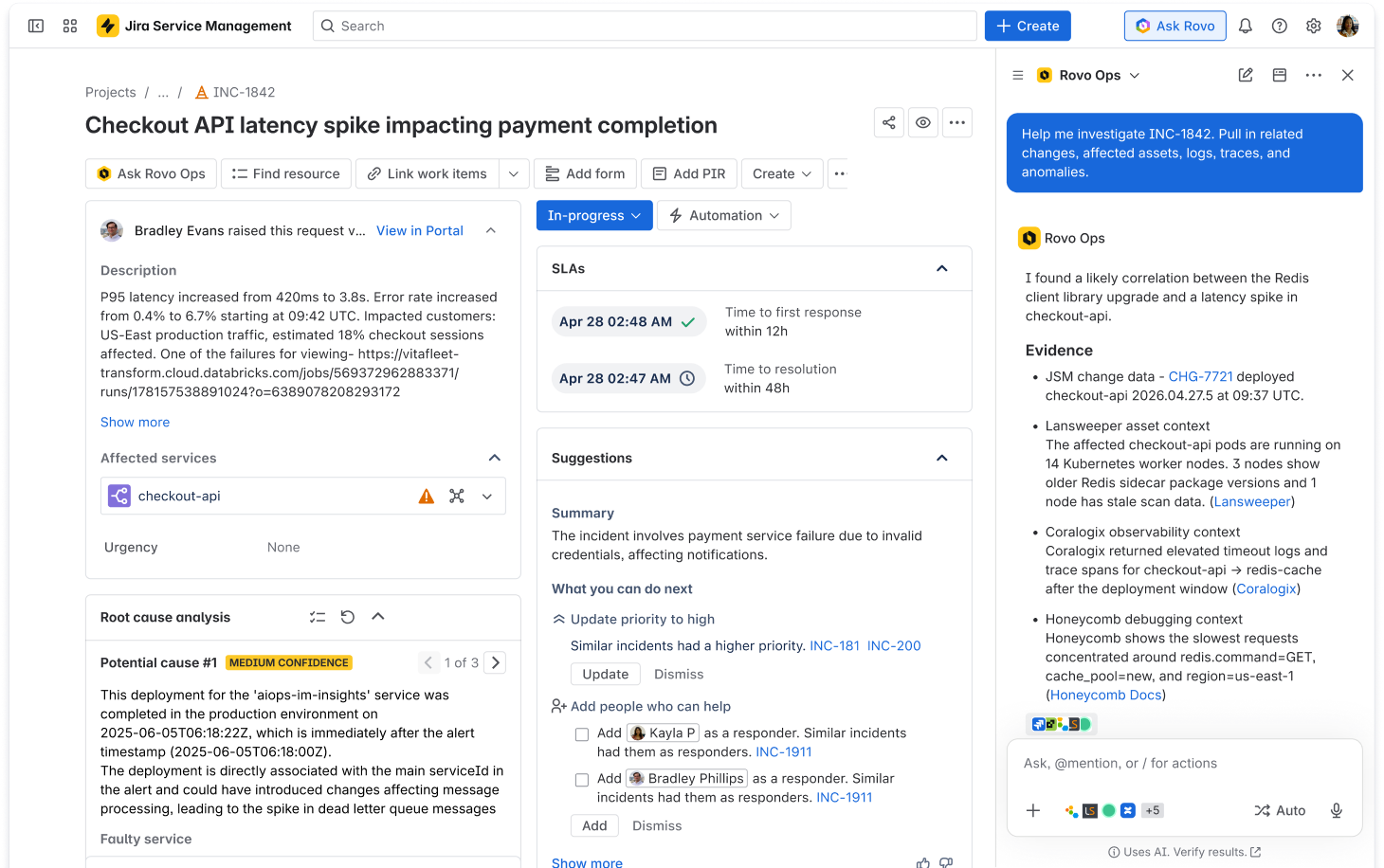
In the first phase of our collaboration, Atlassian’s Rovo Ops agent connects to Lansweeper to bring rich asset context directly into Jira Service Management via MCP:
- Trusted asset context surfaced in incidents and changes
When an alert is created or a change is proposed, the agent can query Lansweeper for impacted devices, installed software, network topology, lifecycle and warranty details, and known vulnerabilities. That information is surfaced right inside the Jira Service Management incident, so responders do not have to swivel between tools. - Change risk assessment and approval recommendations
For change requests, the agent uses Lansweeper asset intelligence to assess which assets and services are impacted, how critical they are, and what related alerts, incidents, or problems exist. It then generates an approval recommendation (approve, conditionally approve, or decline) along with rationale and auto‑populates the risk section in the change record. - Correlation between asset changes and anomalies
When asset change events are detected—such as configuration drifts or unexpected software changes—the agent correlates them with past changes and incidents, using Lansweeper’s context to recommend whether to monitor, create a problem, raise an incident, or dismiss noise. - Zero‑trust access decisioning and operational risk automation
Asset details such as criticality, exposure, and dependencies are used in workflows like break‑glass access approvals and operational risk mitigation, ensuring decisions are both fast and auditable.
By combining Lansweeper’s cyber asset intelligence with Atlassian Assets and the broader Teamwork Graph, Jira Service Management enables teams to move beyond a static configuration database toward a true context graph—one that can power governed, AI‑driven decisions across your operations workflows.
Coralogix: Full-stack observability for organizational intelligence
Coralogix delivers full-stack observability, logs, metrics, traces, and security events, with AI and increased cost efficiency – all without sacrificing visibility. Our joint integration is focused on putting that full organization intelligence directly into Jira Service Management incidents and post‑incident workflows.
In phase one, the Rovo Ops agent connects to Coralogix to support several core use cases:
- Contextual incident correlations and enrichments across all telemetry and security events
During an incident, the agent queries Coralogix for logs, metrics, traces, security events, and anomalies within the relevant time window. Parsed logs—including structured fields—are displayed in a panel alongside the incident, preserving a clean audit trail. - AI‑driven root cause analysis and recommendations (available in Beta)
The agent invokes Coralogix’s streaming analytics to correlate patterns across error logs, metrics, traces, security events, and system changes. It then returns a hypothesized root cause and suggested remediation steps right inside the Jira Service Management issue. - Automated, audit‑ready post‑incident reviews
After resolution, the integration pulls a consolidated log timeline, relevant security events, and incident details into Confluence to generate a post‑incident review that is both operationally useful and compliance‑friendly.
Together, Coralogix and Jira Service Management give IT operations teams full-stack observability, faster investigations, and out‑of‑the‑box support for alert and incident management use cases. By unifying observability across all event types with AI agent investigations and remediation work in a single workspace, teams can move from detection to post‑incident review with far less friction.
Honeycomb: High‑cardinality debugging for complex, microservices‑heavy systems
Honeycomb is the futureproofed observability platform that enables engineering teams to find and solve problems they couldn’t before. It unifies telemetry, returns fast queries, integrates with AI agents, and reveals issues others miss in your ever-evolving tech stack.
Together with Jira Service Management, Honeycomb’s data and analysis become part of the incident workflow itself, making it easier for site reliability engineers and development teams to diagnose “unknown‑unknowns” without leaving their primary incident hub.
The initial phase of our Honeycomb integration focuses on bringing key debugging capabilities into Jira Service Management via the Rovo Ops agent:
- Contextual enrichment with traces, events, and anomalies
When an incident is opened, the agent can query Honeycomb via the Honeycomb MCP Server for relevant high‑cardinality events, traces, and BubbleUp anomalies within the incident window. These results appear directly on the incident, allowing responders to rapidly test new hypotheses. - AI‑assisted root cause and remediation suggestions (available in Beta)
By combining Honeycomb telemetry with past incident patterns, the agent can propose likely root causes and next remediation steps, even for intricate microservices interactions that are hard to spot via traditional application performance monitoring. - Automated post‑incident reviews with SLO impact
After resolution, the integration can pull Honeycomb trace timelines, then combine them with Jira Service Management metadata to auto‑generate post‑incident reports in Confluence.
By pairing Honeycomb’s high‑cardinality, OpenTelemetry-native observability with Jira Service Management’s AI-native incident and change workflows, teams can quickly zero in on the root cause of complex microservices issues without leaving their primary hub. The result is lower mean time to resolution and smoother collaboration between operations and development, all without disrupting existing practices.
Ready to accelerate your incident workflows?
Expanding on our existing AIOps partner ecosystem with New Relic and Dynatrace, these new integrations deliver asset, log, and trace intelligence directly into Jira Service Management so you can catch issues sooner, diagnose more accurately, and close incidents faster. To get a sneak peek into the new integrations as well as stay up-to-date on future integrations, sign up for the Early Access Program. Also, check out our website to learn more about how Atlassian is helping IT Ops teams resolve incidents faster. We’re excited to see how these integrations can help you modernize IT operations for your organization!


