
Summary
- Atlassian created a new router in Jira and shipped it to 100 percent of customers
- This resulted in some great performance wins
- We are now moving on to adopt the router across our product suite
Background
Over the past six months, a mixed team of JavaScript engineers from both platform and product worked together to create a new router for Jira Cloud’s modern frontend experience, which had been powered by Facebook’s React framework for close to three years.
This work was initiated because, while Jira did have an existing solution, React Router, it was becoming increasingly clear that the design patterns it encouraged were not a good fit for a server-side rendered (SSR), single page application (SPA) of Jira’s size. Due to this, engineers started working around React Router to improve performance, but these workarounds themselves caused some side effects. These included needless negative performance impacts, increased React tree complexity, and an encroaching incompatibility with a new core React feature, React Hooks, and by extension, React’s Concurrent Mode.
As we recognized this emerging need, it became clear that the path to building a new router would be paved with risk and scrutiny. The router underpins much of the customer-facing functionality of an SPA; it is literally what takes customers from one page to another. Any small feature or performance disparity would be unacceptable. On top of this, routers have always been a hot topic of discussion in React (there are four or five fairly popular implementations) and, understandably, there were questions around why Jira needed to invent its own solution.
Ultimately, though, we decided these problems needed to be addressed. We proposed that coupling data fetching for a page with route matching could improve performance, and we kicked off a time-boxed experiment based on that premise. Our first goal was to tackle the negative performance resulting from the existing implementation and its interoperability with server-side rendering. After establishing that other routing libraries were unfit for our purposes, we pushed forward with a rough in-house implementation, and the results were seen as promising enough to greenlight a formalized experiment. This took the form of an entirely new router, with the final goal of improving Jira Cloud’s front-end architecture, performance, and future React compatibility while also ensuring it was platform-agnostic enough to be used in other Atlassian products.
In this blog, I’ll try to go through all the concerns that were expressed to us, the problems we faced, the solutions and results we achieved, and finally, what’s next for Jira’s (soon Atlassian’s) new SPA Router: React Resource Router.
The problem
So what exactly was wrong with React Router? This was of course the first hard question we had to face; why exactly was React’s most popular router implementation wrong for Jira? In fact, I believe the exact question we asked in the very first demo for this work, back in March 2019, was
“Why is Jira such a special snowflake that it needs its own custom router?”
This was a completely fair and reasonable question. The answer comes from a feature the React Router team calls Dynamic Routing. From their documentation:
“When we say dynamic routing, we mean routing that takes place as your app is rendering, not in a configuration or convention outside of a running app”
This is opposed to Static Routing, where
“…you declare your routes as part of your app’s initialization before any rendering takes place”
For most, this seems fine, and aligns with React’s preference for declarative code. However, combined with the way data fetching was being handled in Jira, and the fact that it all needed to work on both client and server, the pattern was slightly problematic.
In order to request the critical data required to render the component for a specific page, the Jira SPA’s SSR bootstrap code needed to know certain things about the path that the client had requested. This meant that matching a route and mapping it to a specific route config object was the most logical and efficient way to enable SSR data fetching.
For this requirement, Jira developed something similar to the Apollo Query component called PrefetchQuery which simply encapsulated fetch requests and did not render any UI. These components were mounted throughout the React tree and, on the server, a third-party library called React Tree Walker was used to
- Render the entire React tree once
- Find all the
PrefetchQuerycomponents - Collect their fetch functions into an array of Promises
- Await them all to get the data required to render the tree correctly (ie., without loading spinners)
- Render the entire React tree once again with the “prefetched” data gathered by
PrefetchQueryand return this to the client as HTML markup
While this did work, here is a tweet from React core contributor Dan Abramov on this topic:
In addition to this, due to Jira’s React tree being so heavy, a TreeWalkerStopper component was created, which would prevent the tree walker from traversing any further nodes once it was encountered. Despite this, tree walking was costing us. It was measured that, on average, the tree walker took 20 – 50ms to traverse Jira to get data. In some cases, it took far longer.
In addition to these issues, React Tree Walker was deprecated and would never support React Hooks, which meant that coupling Jira’s SSR service to its use was blocking a core React feature. This became a significant pain point, as developers were eager to tap into the new API to improve performance and lighten tree density.
On the client, the tree walker was not needed, but if SSR failed, or in the case of a client-side route transition, the PrefetchQuery components would fetch their data when they were constructed. In these cases, performance could be negatively impacted since data fetching could have happened earlier.
In thinking about how we could tackle these issues, we kept coming back to the browser’s location. This location, and the route that matched it, could actually contain all the information we needed to fetch the data that is critical to render the page requested.
As stated, Jira had already moved away from React Router’s dynamic routing to static routing so that they could statically analyze routes in order to easily render them on the server and run React Tree Walker correctly. We wondered if a route configuration object, which already had a component property, could also have something like a getData property; a function to asynchronously fetch the data required to render the route’s component.
Our solution
Our main objective when designing the router was to have it act as a cohesive encapsulation of all the workarounds, which Jira was already doing with React Router, but without the negative side effects. You can read the official docs for more detail, but for now, here is a high-level overview of its core concepts and features, as well as some pseudo-code examples.
Powered by react sweet state
The router is powered by Atlassian’s state management library, react-sweet-state. It blends the best of context and Redux together with a focus on performance, Redux-like debugging, and testability. It is already the preferred shared state management solution for Jira.
Static routes configuration
The router is powered by a static routes configuration array. This array must be provided to the router as a prop. Each route configuration object within this array is composed of properties that assist us in universally fetching all the correct critical data required to render the component assigned to that route. These include the following:
pathis how we match the current location to a route.queryis the query string that will influence a match.componentis the component that is rendered when the route is matched. This component will be provided a set of props collectively known as RouteContext. This could also be thought of as the “page” component.resourcesis an array of objects that we use to fetch, organize, and cache data.
Immediate execution
On the client, as soon as React mounts the router, all resources for the matched route are immediately requested asynchronously. As they resolve, the hooked/subscribed UI components react to the resource request state and are provided three standardized properties – loading, data, error – which they can use to progressively render. For now, until React Suspense is ready to be used in production on the server, we provide a static method that must be called and awaited imperatively in Node in order to fetch all resources required for the route. The Jira SSR service then makes the resulting data available to the client for the purposes of hydration via a script tag, which is included in the HTML document.
One encouraging piece of information from the React team on this approach came from the page on Suspense linked above, which states:
… Suspense is not currently intended as a way to start fetching data when a component renders. Rather, it lets components express that they’re “waiting” for data that is already being fetched … Unless you have a solution that helps prevent waterfalls, we suggest to prefer APIs that favor or enforce fetching before render.
And this is exactly what the router is doing.
Data storage and caching
Internally, the router stores all resource states in an in-memory cache. This happens automatically when resources are requested (either on mount or on route change) and we provide a suite of APIs including hooks, render prop providers, and HOCs to enable consumer interactions with this state. Memoized selectors are used to avoid re-renders as much as possible, and caching is supported via a resource’s maxAge property.
Progressive migration
Because the router uses the same history implementation as React Router, migrating from one to the other is very simple. It is possible to progressively migrate your app, route by route, with both routers sitting side by side. They simply share the same history instance. Indeed, this is already happening in Bitbucket, another Atlassian product that was using React Router and is now using react-resource-router for some level of production traffic.
However, the router discourages direct access to the history API and provides its own RouterActions subscriber or useRouter hook for imperatively calling history actions like push or replace. This way, we always know which history is being accessed. The goal is to only ever have a single instance of history in your app.
Examples
Here is a quick pseudo-code example of how the router and resources are used. In this example, assume we have a very simple app with two pages: Issues and Profile. They share the same header, which needs critical data from remote to render, but they also have their own data dependencies. All of these are encapsulated in resources, which we will need to use in our components to access the current state of the required resource in the store. Finally, we also want to SSR this app, so we do some setup in a Node environment as well.
Routes setup
import { Posts, Profile } from 'src/pages';
import { fetchAllPosts, fetchProfile } from 'src/api';
import { headerResource } from './common/resources';
export const postsResource = {
type: 'POSTS',
getKey: () => `posts`,
getData: (_, { user, credentials }) => fetchAllPosts({ user, credentials }),
maxAge: 100000,
};
export const profileResource = {
type: 'PROFILE',
getKey: (_, { user }) => `profile-${user.id}`,
getData: (_, { user, credentials }) => fetchProfile({ user, credentials }),
maxAge: Infinity,
};
export default [{
name: 'POSTS',
path: '/posts'
component: Posts,
resources: [headerResource, postsResource]
}, {
name: 'PROFILE',
path: '/profile',
component: Profile,
resources: [headerResource, profileResource]
}];Router setup
import React from 'react';
import { Router, RouteComponent as Page } from 'react-resource-router';
import App from 'src/app'
import userAuthenticationBootstrap from 'src/auth';
import createBrowserHistory from 'history';
import { routes } from 'src/routes';
export default () => (
<Router history={createBrowserHistory()} routes={routes}>
<App>
<Page />
</App>
</Router>
);Route component setup
import React from 'react';
import { useResource } from 'react-resource-router';
import { postsResource } from 'src/routes';
import { Error, Spinner } from 'src/common/components';
import Post from '../components';
export const Posts = () => {
const [{ data, loading, error }] = useResource(postsResource);
if (error) {
return <Error error={error} />;
}
if (loading) {
return <Spinner />;
}
return data.posts.map(post => <Post data={post} />);
}Server-side setup
import React from 'react';
import { renderToString } from 'react-dom/server';
import { StaticRouter, RouteComponent as Page } from 'react-resource-router';
import App from 'src/app';
import { routes } from 'src/routes';
export default async ({ location, user, credentials }) => {
await StaticRouter.requestResources({
location,
routes,
resourceContext: { user, credentials }
});
return renderToString(
<StaticRouter routes={routes}>
<App>
<Page />
</App>
</StaticRouter>
);
}The results
Architecture
Architecture improvement is a difficult thing to measure. However, I think that there are a few ways we can quantify whether a certain approach is better than another from a sensible engineering point of view. Reducing cyclomatic complexity and lines of code while improving code cohesion are strong indicators that your architectural approach is headed in the right direction. Better still if you improve performance at the same time.
In Jira, we removed the need to use the PrefetchQuery (which is quite complex) and TreeWalkerStopper components. On average, we also saw the PRs for each migrated route reducing lines of code by between 50 and 100 lines. Unblocking hooks usage also helped flatten the code a great deal, making it far simpler to parse at a glance.
On top of this, the router also improved Time to Render (TTR) and Time to Interactive (TTI) for a number of targeted pages.
Performance
In order to measure the performance impacts of the new router and its updated design, we targeted the six most visited routes in Jira. For each of these routes we:
- Created a specific feature flag
- Created resources
- Replaced the usages of
PrefetchQuerywith ouruseResourcehook - Progressively rolled the feature flag out until we got to a 50/50 split
- Soaked in production for two weeks while we A/B tested the difference in metrics
In all honesty, we were not expecting an enormous boost in terms of performance from the new router. Our goal was to simply shave off the time it took for React Tree Walker to walk the tree when collecting data requests.
However, we were pleasantly surprised when we began our progressive rollouts and noticed some very nice numbers coming through. Here, I’m going to focus on our improvements to the full page Issue View (ie., an Epic, Story, Task, or Bug), although we did see similar gains for other pages.
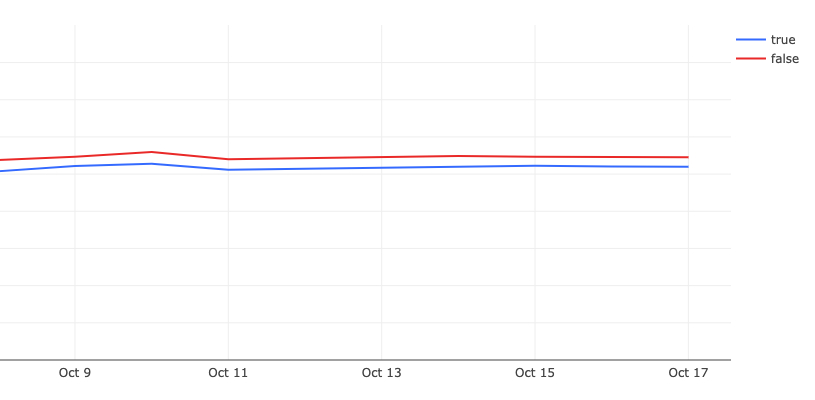
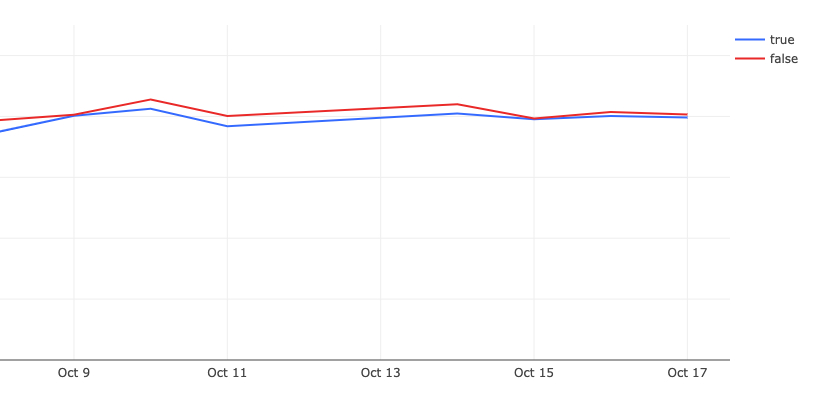
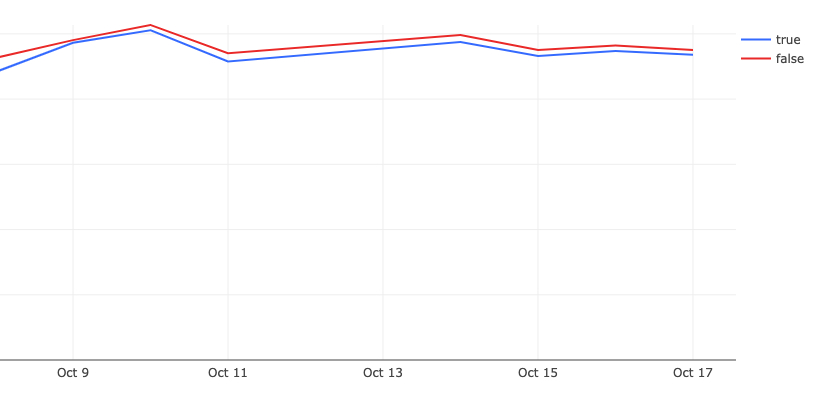
Issue View TTR
In both of these charts, we are A/B testing the TTR with the router enabled (true) and disabled (false). For these charts, lower numbers are better. We recorded a ~100ms TTR improvement for issues on initial loads.
By cohort in p50
By cohort in p90
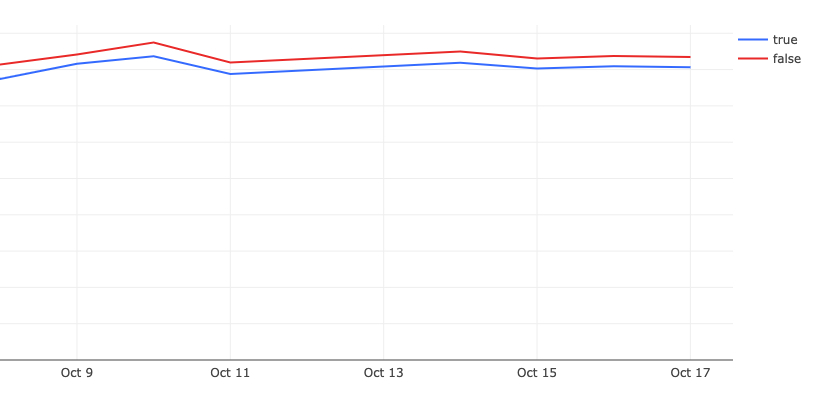
Issue View TTI
In both of these charts, we are A/B testing the TTR with the router enabled (true) and disabled (false). For these charts, lower numbers are better. We recorded a 250-300ms TTI improvement for issues on initial loads.
By cohort in p50
By cohort in p90
Hooks compatibility
As stated, previously our SSR code path relied on React Tree Walker, which was incompatible with hooks. The router and its resources pattern freed us from this dependency. All of Jira has since been migrated, and hooks are now being used without issue throughout the codebase.
The future
On the adoption side, we have already begun work inside Bitbucket to migrate them over to using react-resource-router.
In terms of features, there’s a backlog of cool things we’re working on, such as limits for cached data, support for non-SSR’d resources, and potentially resource pre-loading. We are also going to prioritize making it “React Suspense Ready” so that everyone can start taking advantage of concurrent mode as soon as it is stable in production.
Of course, the router is now open source, so we’re excited to see what the React community thinks about it and what other ideas they might have for its direction.