
For the past 18 months, we’ve been iterating on and improving a React server-side rendering service to support the frontend in our cloud-hosted Jira offering. During this time, the service has grown fairly organically from a side-project spiking a proof-of-concept, to a performance-critical service with 24/7 on-call support.
This isn’t the story of an ideal SSR implementation, and it’s not a recommendation for how you should adapt SSR into your specific application or use case. This is just the story of how we adapted non-SSR friendly code in a largely legacy frontend architecture into a multi-tenanted service that scales to almost every page in Jira. We’re working within constraints that led us to this solution and improved our Time to First Meaningful Render (TTR) by about three seconds across the board.
Modernising a legacy frontend
Jira started life in 2002 – 17 years ago at the time of writing. Needless to say, web development has changed a bit along the way.
Jira’s backend has gone through major architectural shifts too – we’ve transformed Jira from a single-tenanted single-JVM tomcat webapp hosted in-house by customers, to a composition of multi-tenanted web services operated by Atlassian on AWS (one of the largest and most complex projects in the history of the company).
In terms of introducing React and SSR (or more generally, just modernising the frontend stack), the things we’re worrying about are:
- How to introduce features written in a modern tech stack to a fundamentally legacy architecture (i.e. taking HTML templates rendered in the JVM using stateful Java components, and replacing them with stateless HTML templates generated in a JavaScript environment such as a web browser). Basically how to replace 17 years of JSPs, VMs, and bespoke Backbone/Marionette apps with React components.
- How to ensure React code is compatible and safe to execute in a server-side environment (i.e. adapting browser-specific features to the server-side, and making sure misbehaving renders don’t interfere with the health of the service). And, most importantly for us:
- Ensuring cross-tenant data safety – a web browser provides an isolated sandbox for a JavaScript application to execute in; the same code executing server-side in an SSR environment does not have the same guarantees. For a multi-tenanted system (i.e. the same app code and hardware serving requests for multiple, independent users) containing sensitive customer data (e.g. Jira), ensuring data safety and preventing cross-tenant data leakage is paramount.
In this blog, we’ll try to explain how we’ve addressed each of these problems. The more general question around why or when to undertake a large scale modernisation and tech debt reduction effort like this is out of scope.
Getting started
One of the easiest ways to get started introducing modern frontend code into a legacy codebase is what we refer to as an inside-out model. You start by creating a small island of modern code (e.g. a small feature written in React), and slowly expand it outwards allowing it more and more responsibility over the page.

This is a great way to get started with React quickly, but the complexity increases as the new code starts to replace more and more of the existing experience. We’ll explain this approach in more detail, as well the alternative outside-in model, in a future blog.
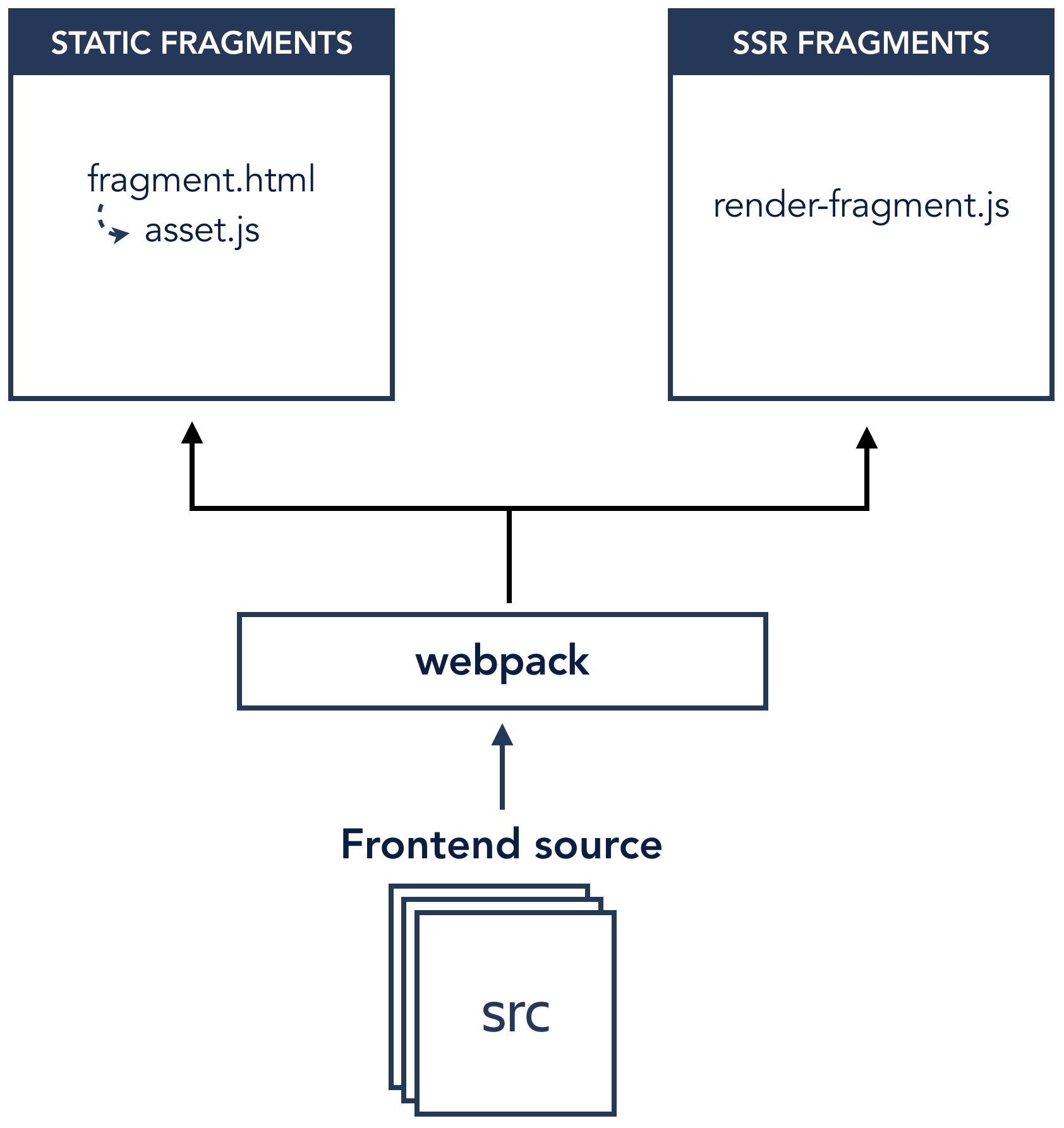
We implemented this initially with a system we’ll refer to as fragments. We started in a new repository, introduced React, and emitted:
- Assets: Compiled JavaScript and CSS files, named with a content hash (e.g
2fc5cdc978f3739d61d1.js); and, - Fragments: HTML files with a fixed name (e.g.
issue-view.html) containing links to some set of assets, and representing an incomplete segment of another HTML page.
We deploy these artifacts by uploading the fragments in place to an S3 bucket behind a Cloudfront CDN. When we go to render a page in our existing application, we make a request to our CDN to fetch a fragment, compose it with the legacy JVM rendered HTML we already have, and return it the browser.

Building from scratch in a new repository gave us the space to set up a frontend-focused development pipeline using tools familiar to frontend developers, and allowed us to develop and deploy new frontend features independently of the existing monolithic Jira codebase, which was a big dev speed win.
Shortly after we had migrated a few larger features to the new service, people started asking about SSR. The new system worked well, but one of its main limitations was that it was completely static – we download a pre-generated HTML file into part of the page, we send it to the user’s browser, then the Javascript is downloaded and executed.
We needed a JavaScript runtime somewhere between us and the user’s browser to support server-side rendering, so we added a new node-based service on top of our existing fragments system. The API was largely the same, but now, in addition to our existing fragments and assets, we also emitted a special SSR-compatible JavaScript bundle (which we’ll explain in more detail in the next section). We first call out to our SSR service to try and render a fragment server-side using that bundle, and fallback to our existing static fragments if it fails or times out.

Getting any code to even render initially was a challenge. Our frontend code wasn’t necessarily written with SSR compatibility in mind, which means we hadn’t remained mindful of things like safe platform-agnostic access to APIs like window or document, or avoiding global side-effects such as scheduling timers during a render.
One solution to this compatibility problem – arguably, a better solution – is to refactor all frontend code for both server-side and client-side rendering, but that’s a difficult cost to justify when we weren’t even sure what the benefits of SSR would be for our use case. We decided instead to provide a compatibility-layer that could adapt our existing non-SSR-friendly code to an SSR environment.
Polyfilling SSR compatibility
There are two main parts to our compatibility layer:
- Build time: A separate JavaScript bundle compiled with some SSR specific modules (the entrypoint to this script runs the same render function that would be executed by default when it’s loaded in a browser, returning an HTML string); and,
- Run time: A context object providing the server-side replacement for browser-only APIs, and isolation of any global state or side-effects.
There’s plenty of good resources online about the differences between running in a browser and running on a server with regards to React. The typical recommendation is to write your components in a such a way that is aware of the differences in environments and to guard against them (e.g. checking for the existence of browser globals like window and document before trying to use them). The alternative is to produce a separate JavaScript output specially for server-side execution with some key global variables redefined and some modules replaced. The obvious drawback with the latter approach is that your server-side code diverges further from your client-side code, which can lead to obscure bugs, but the benefit is it enables you to retrofit large amounts of existing code and its dependencies – which was never intended to work with SSR – relatively easy.
Some changes, we make at build time (Webpack’s NormalModuleReplacementPlugin is your best friend here):
- We replace client-side analytics with empty stub functions since there’s no real user behaviour we want to track before we reach the browser, and we can prevent some unnecessary network requests;
- We replace modal dialogs and open dropdowns with stub implementations that do nothing since these can’t be opened without user interaction in the browser (this assumes you don’t deep link through to open panels);
- We reimplement functions to inject page bootstrap data – the non-SSR process is to generate a set of
<meta name=”${key}" name="${key} content="${key}">elements in the head of the page when we render the initial template in the JVM. Client-side scripts can then parse these elements for critical page bootstrap data. Instead of trying to parse a DOM that doesn’t exist, we redefine thePageData.parse(key: string)function to return data from this existing in-memory structure instead; and, - In the browser, we record logs by sending them over the network to our logging service. For server-side execution, we redefine this function to just dump them to the console where they are ingested into Splunk via our existing server-side logging pipeline.
We provide the remaining mechanisms at runtime. Each script is executed in a separate Node VM context. A Node VM is essentially a fancy eval function with some special error handling and a separate global scope. It’s not a security mechanism for running untrusted code in a sandbox. We’re running our own apps, so we trust ourselves to not do anything deliberately malicious, but we do want to guard against mistakes or bugs compromising data isolation. We also need to be able to reliably cancel render jobs if they’re running too long or otherwise misbehaving. We provide a few mechanisms for this through the context object which we inject as the global state for each render VM:
- We provide a new JSDom instance for each render, which provides most browser globals we need. The few that are missing, we can define ourselves;
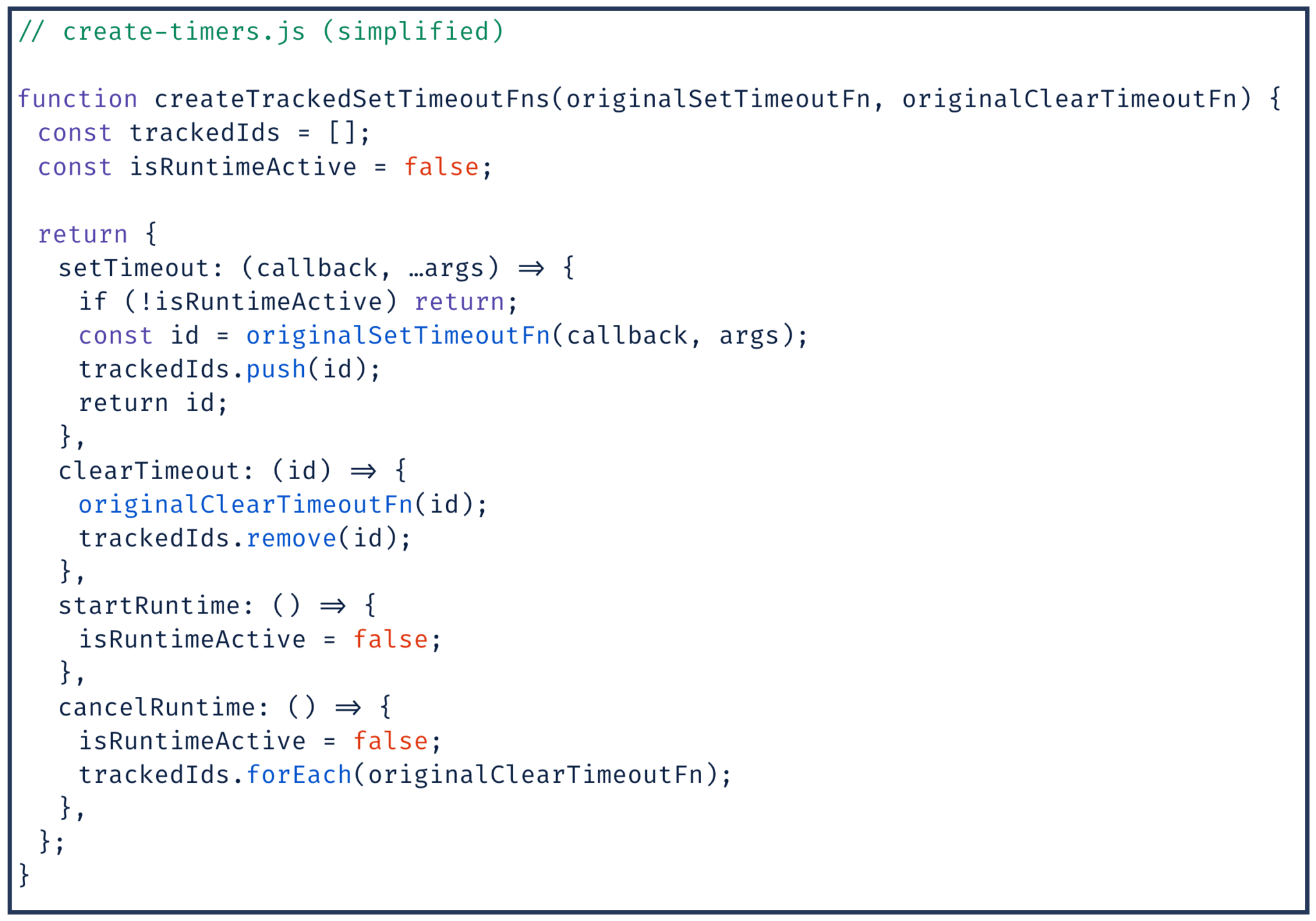
- We redefine scheduling functions like
setTimeoutandsetIntervalso that we can keep track of any callbacks created by a render job; - We inject a decorated Promise which allows cancellation, but also keeps track of any created instances. One critical detail to note is that, due to the implementation of microtasks in node, a promise scheduled inside a context can execute outside of the context after it has been destroyed. We hook into the prototype to catch new instances and try to make sure they get cleaned up at the end of the render (we cancel in-progress fetch requests, and clear any timers);
- For fetch requests in the browser, we don’t need to worry about resolving a base URL; we can use the default hostname provided by
window.location, which we pass back through our global proxy and eventually into our APIs to handle the request. For server-side execution, we inject a different implementation that manually rewrites the URL to point back to the appropriate backend APIs to match what would happen if the request were made from a browser.


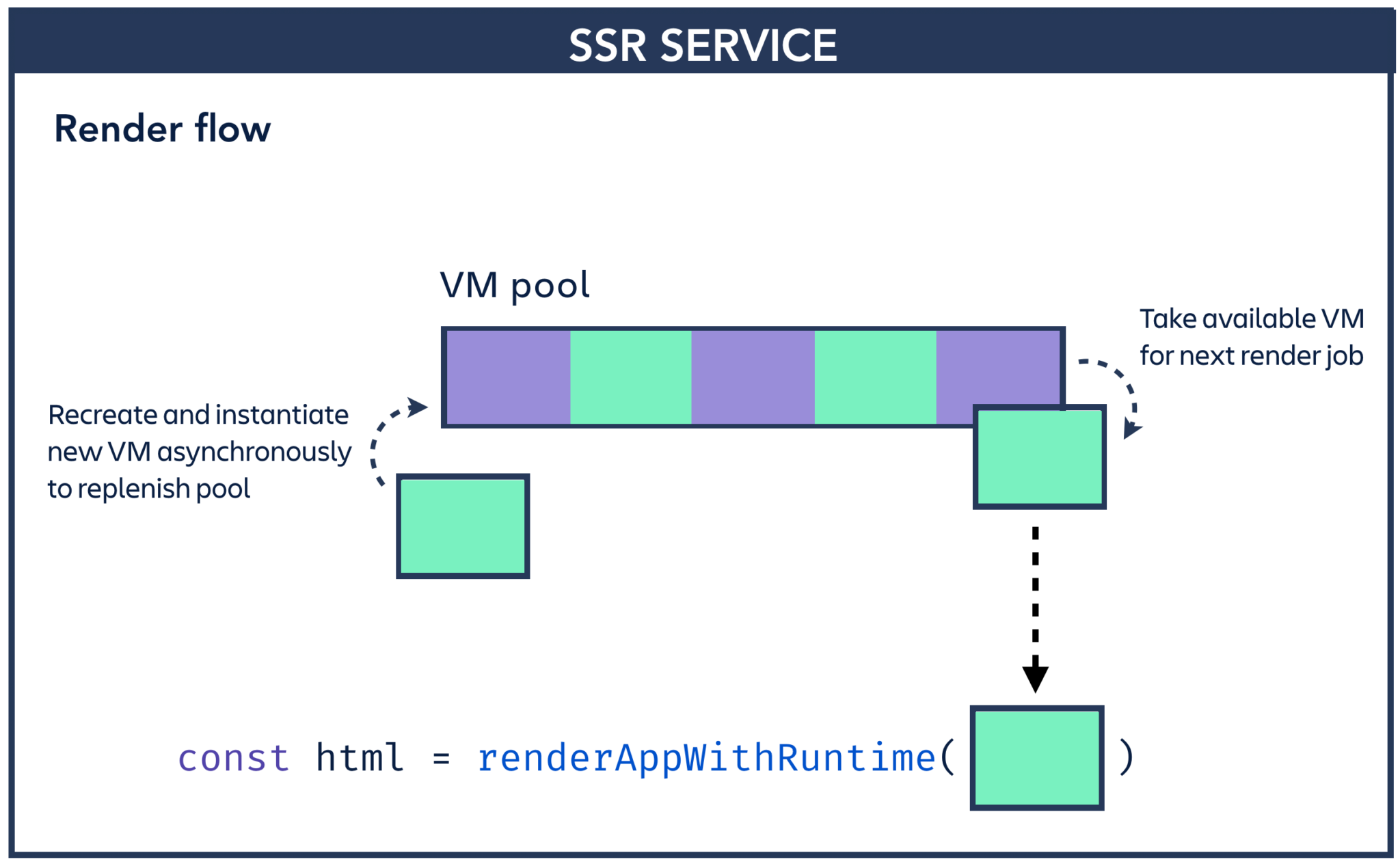
We use a completely new VM and runtime for every render request. This is good for isolation (we get a clean global scope, and a clean scheduler context), but bad for performance (instantiating a new context can take ~200ms, which is too slow to do as part of every request). To mitigate this, we maintain a pool of available VMs for each render job to draw from. We know which scripts we need to render ahead of time, so we can instantiate VMs before we need them and precompile the scripts we need.
This was enough to get going, our next challenge was onboarding more experiences into the service and scaling it up to support Jira-levels of traffic.
Scaling up
We went through a few architecture iterations quickly early on, but eventually settled on:
- A pool of web server nodes to accept incoming render requests (a basic Koa web service);
- A pool of worker nodes to perform the rendering function; and,
- A shared queue connecting the two (implemented with bee-queue on a separate Redis instance).
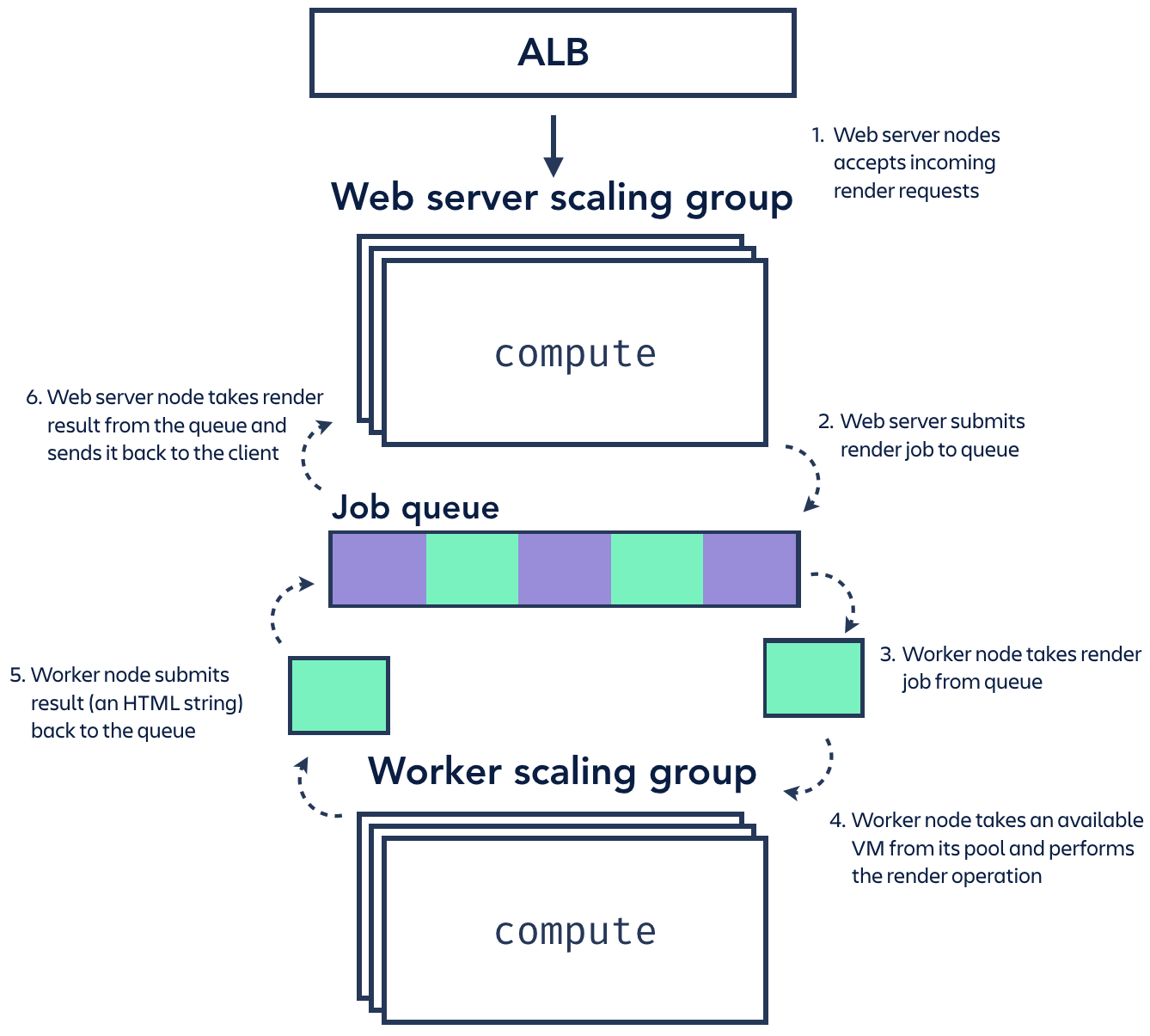
We deployed this stack 1:1 in each of the AWS regions used by Jira, and it hummed along nicely! Separating the web servers and workers made sense intuitively – they had very different compute requirements (the workers had expensive render operations to perform, but the web servers just had to accept and respond to simple HTTP requests), and we liked that we could configure different Ec2 instance sizes and scaling rules for each of them. The job queue between the two provided an extra layer of load balancing, which allowed renders to be distributed fairly consistently across the available compute resources.
Results were good, and we weren’t even close to our scalability limits. Web servers in our busiest shards usually topped out around three instances, and workers would sometimes scale up to eight or nine instances during periods of high traffic.
We ran into problems when we started to onboard a new fragment into SSR – the navigation sidebar. Since the sidebar is present on every page in Jira, this would effectively increase the amount of traffic into SSR by more than 100 percent (+1 render request for every page that already had an SSR’d fragment previously, and +1 for pages that previously had no SSR interactions)! We knew it would be a challenge, but initial performance testing was successful, and we had the capability to increase or decrease the rollout on a per-request basis if we needed to.
We pushed the rollout along without incident. A few hours after hitting 100 percent, we started to run into problems. We started getting alerts for spikes in request duration, and an increase in jobs failing due to timeout. We decreased the rollout for the navigation fragment (decreasing load), and the service quickly recovered.
After some investigation, we found an interesting correlation between load, network I/O on the job queue, and render performance.
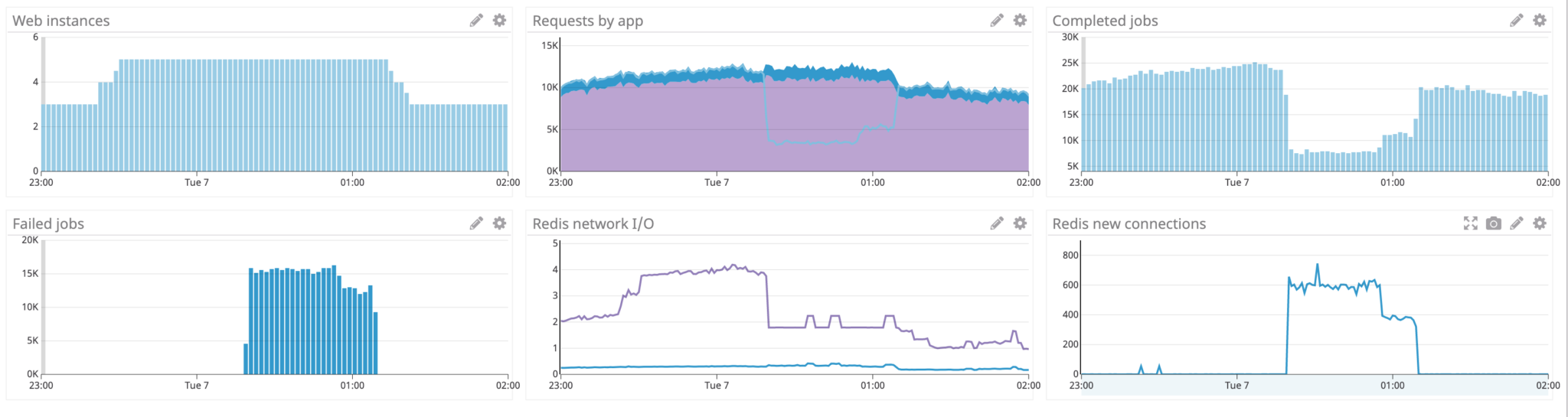
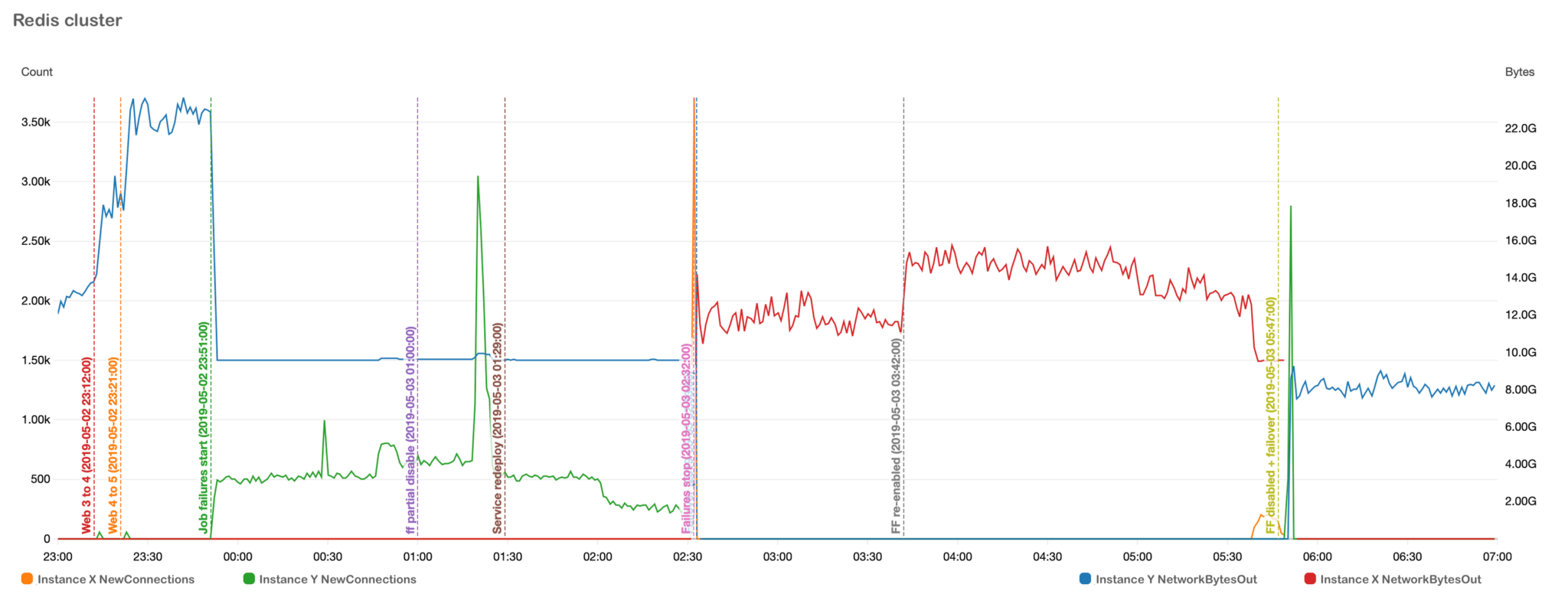
With the additional load from the navigation sidebar fragment:
- Web servers scale up (based on CPU utilisation) to handle more incoming requests;
- The new web servers open new connections to the Redis instance hosting the shared queue;
- The increase in the number of render jobs starts to pump more data onto the queue; and,
- The increased number of web servers start reading more and more data off the queue.
The nature of our queueing solution means that all job results are sent to all available web servers, which means the bandwidth required between webserver and queue is unfortunately quadratic with the number of concurrently completing jobs, multiplied by the size of the job result (the rendered HTML string), multiplied by the number of active webserver nodes!
Eventually, we start to run into our max network-out bandwidth allowance at 10GB/sec for our Redis instance, and get (rightfully) throttled by AWS. With nothing left to connect incoming requests with worker nodes, render requests start to timeout and fail. Our CPU-utilisation-based scaling rules to add more web server nodes to deal with an increasing number of incoming requests actually makes the problem worse by further saturating the network connecting web servers with the queue instance!
Most people would agree that this is sub-optimal.
Despite our horizontal scaling and load balancing capability for web servers and workers, we were being let down by the shared queue in the middle. Fortunately, we were able to reduce customer impact in the immediate-term by limiting the rollout of the server-side rendered navigation fragment. We mitigated in the short-term by vertically scaling our Redis instance to allow for more generous network bandwidth allowances, but it still represented a single point of failure in the architecture that we needed to address.
Our longer-term solution was to keep the general architecture the same but flatten everything into one scaling group. So instead of scaling web servers and workers independently around a single shared queue, one ec2 instance runs a fixed number of web server processes, a fixed number of worker processes, and their own mini job queue between them in a separate Redis container. When we scale up (still based on CPU utilisation), we create another completely isolated group of web servers, workers, and a queue as one unit.
There are many alternative inter-process communication techniques we could have used to connect the web servers and workers, but this approach allowed us to keep the internals of the service mostly untouched and experiment only with the deployment model.

This architecture yielded more stable render times, was cheaper (we end up running more Ec2 nodes total, but we save money on the big Redis instance which was under-utilised in terms of CPU & memory), and handled the increased load from the navigation fragment without issue.
Was it worth it?
SSR, in general, is a trade-off between time-to-render (TTR) — the time taken to display meaningful content to the user (e.g. display relevant issue details), and time-to-interactive (TTI) — the time taken for the page to become clickable (e.g. a user can click through comments, or collapse & expand the sidebar). SSR typically increases TTR at the cost of TTI, so is only really useful for pages where an initial read-only view is more relevant to a user than an interactive experience.
We think the navigation sidebar specifically is a good candidate for this:
- We can provide navigation context to the user quickly, which helps maintain a consistent mental model when navigating around Jira;
- User analytics show that most people don’t even try to interact with the sidebar before it has become interactive; and,
- We provide basic click interaction with HTML anchor tags between TTR and TTI to satisfy that small percentage of early interactions.
So for our specific use-case – yes, I think it was worth it! In addition to the performance benefits, we also have a frontend service that can act as the foundation for future decomposition efforts.