
Atlassian’s mission is to help unleash the potential of every team, and a critical part of that is to create a world-class cloud platform that can support the needs of our largest customers. For Jira, this means supporting massive numbers of Issues in a single Jira site. A significant part of Jira functionality is implemented in a large monolithic codebase, which is called the Jira Monolith. The Jira Monolith has had 18 years of development, and parts of the design do not scale well in the cloud platform anymore. We have written previously about many of the architectural changes that have been made to the Jira Monolith over the past several years, including the Vertigo Project, performance improvement work, and adding Server Side Rendering to the new Jira React frontend.
One of the next large steps in evolving the Jira Cloud architecture to achieve much greater performance, scale, reliability, and developer velocity is to decompose the Jira Monolith into multiple micro-services with their own responsibilities.
The Issue Service
The Issue Service is the nexus of business logic around viewing and updating issues. It is built using key-value storage that models Issue data in a document format, with the design goal of supporting one billion Jira issues per site. The development of the Issue Service has three main phases:
- Phase 1: The service acts as an eventually consistent cache of Issue data for fast retrieval.
- Phase 2: Issue data is written to both the Issue Service and the Jira Monolith. Issue data is read from Jira Issue Service in most cases, but some cases will still read from Jira Monolith (e.g. site-level exports, permission checking, JQL search).
- Phase 3: Issue data is written only to the Issue Service. Issue data is read only from the Issue Service, or from another service that builds a view of Issue data from updates coming from the Issue Service (e.g. the Search Service that will index Issue data into an Elastic Search cluster).
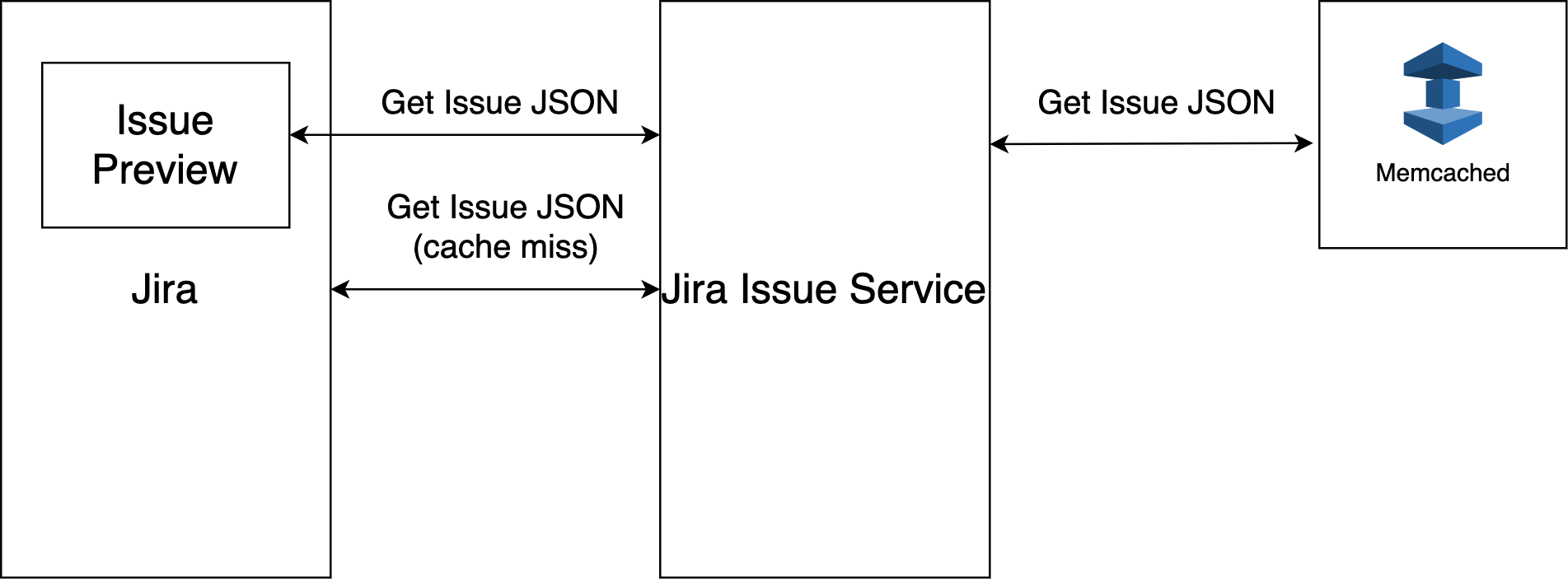
The following is a simplified version of how the Issue Service works in phase 1. The flow is like this:
- A user loads a Jira Issue.
- The Jira Monolith will make a request to the Issue Service to get the issue data.
- The Issue Service will get the issue data from Memcached and return the data back to the Jira Monolith.
- In case the issue data is not available in Memcached (cache miss), the Issue Service will call back to the Jira Monolith to get the data, put the data into Memcached, and then return back to the Jira Monolith. The callback is required because the Jira Monolith is still the source of truth for Issue data in phase 1. The callback will be no longer required in later phases.
By completing the work for Phase 1 of the Issue Service, we have been able to validate our planned data model & access patterns for this Issue data and get real production data about the performance improvements that we can achieve.
Why migrate to Protobuf?
The Issue data was passed between Jira, the Issue Service, and Memcached via JSON format. We knew that JSON is not efficient in performance or data size, and we wanted to improve that.
In selecting an alternative to standard JSON, there were a number of more efficient serialization formats that we could choose from. There was already an internal benchmark that had compared multiple different Java marshalling frameworks like Protobuf, Thrift, Kryo, Avro, etc. The benchmark found that Protobuf performed very well across all aspects, like un-marshalling performance, marshalling performance, data size, and data schema change. As a result of this testing, Atlassian has been using Protobuf as the default choice for binary serialization of data, and so the Issue Service team decided that Protobuf would be our serialization format of choice.
Performing Service-to-Service (S2S) communication using Protobuf is often done using gRPC. We had initially wanted to move to gRPC as part of this migration, but we found during a spike that gRPC was not compatible with the Application Load Balancers we use in AWS, and would require substantial infrastructure changes to support. We are still interested in using gRPC, but that will have to wait for the future.
Our migration strategy
Migration from JSON to Protobuf is, of course, a non-compatible change, but we still needed to perform this migration in a way that saw zero downtime for users.
At Atlassian, we have a process for performing zero downtime migrations. In our case, this process comprised the following steps, which must be completed in order to perform the migration.
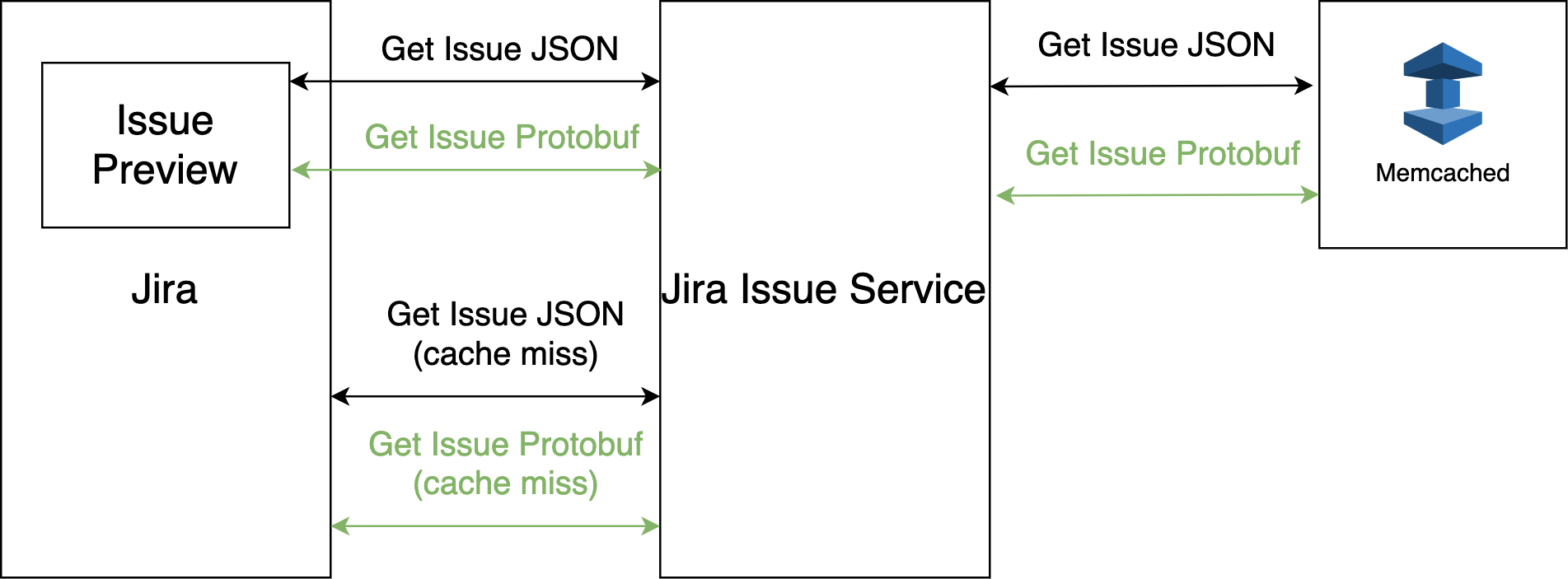
- We created new endpoints in the Jira Monolith to return Issue data to the Issue Service in Protobuf format.
- We created new endpoints in the Issue Service to return Issue data in Protobuf format. The new endpoints will call back the endpoints created in the first step when Memcached does not have data. We kept the Issue data in Protobuf format under a different cache key, as we wanted to keep both for compatibility purposes.
- We created new logic in the Jira Monolith to call the new endpoints and process Issue data in Protobuf format.
- We combined the new logic with the old one in a way that we could decide which logic would be executed based on a flag. The flag essentially has three modes: OLD, CHECK, and NEW. When it’s OLD, we will only execute and return the result from the old logic. When it’s CHECK, we will execute and return the result from the old logic while also asynchronously executing the new logic, and compare the results. If the results are different, a metric will be recorded so that we can investigate where the inconsistencies are. When it’s NEW, we will only execute the new logic.
- We cleaned up the old logic once the new logic was fully rolled out for all customers. The old JSON cached data would eventually expire in 30 days.
During the rollout in CHECK mode, we found quite a few bugs in the new code path (and some in the old code path as well). We learned about some challenges in the differences between Protobuf and JSON. For example, Protobuf is not NULL friendly, and Protobuf’s default value is NULL when transferred via the wire.
After fixing the inconsistencies in the new code, we switched to NEW mode and removed the code for JSON.
What do we get after this?
A lot! This change improved throughput, resource utilization, and response latency. Following are some visualizations of these benefits:
Protobuf consumes 75% less Memcached CPU
The following chart displays the CPU usage of the Memcached cluster in one of our production clusters.

Because we completely switched to the new Protobuf code path on Nov 19, 2019, there is a drop in the Memcached cluster on that day. By our calculation, it uses approximately 75% less CPU than before.
Serialized Protobuf is ~80% smaller than serialized JSON
The following chart displays the number of bytes that are sent from the Memcached cluster to the Issue Service in prod-east.

There is a drop on Nov 20, and we calculate that it’s ~80% smaller than JSON. With this drop, now we can reduce the number of nodes in our Memcached clusters, which will be discussed further later.
Faster serialization and deserialization
The following charts display the serialization and deserialization time of the cache items. The time for JSON is on the left, and the time for Profobuf is on the right.
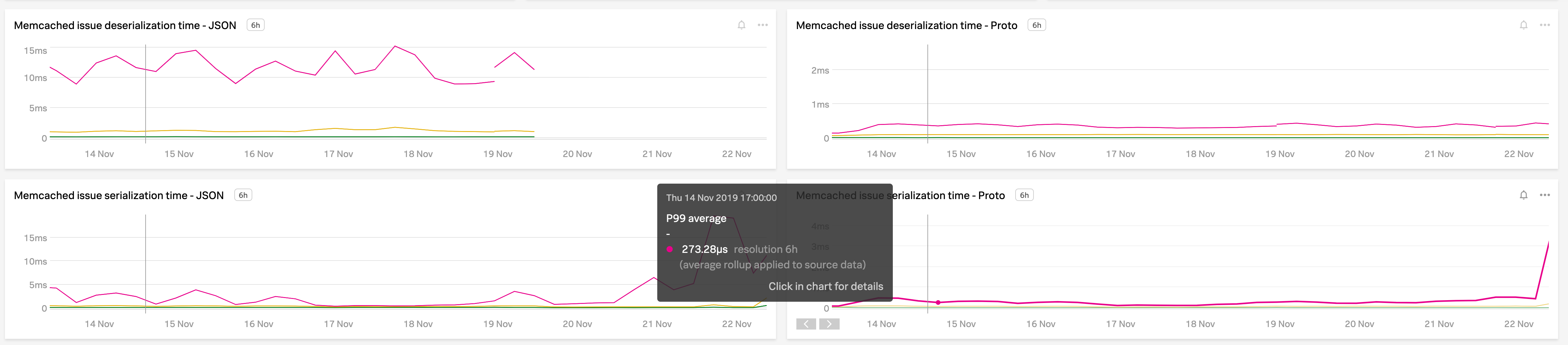
Based on the p99 metrics, we can see that Protobuf is roughly 33 times faster than JSON during Issue deserialization, and 4 times faster during Issue serialization.
Faster server-side response time
The following chart displays the comparison of the p90 total processing time to get issue data between JSON and Protobuf.
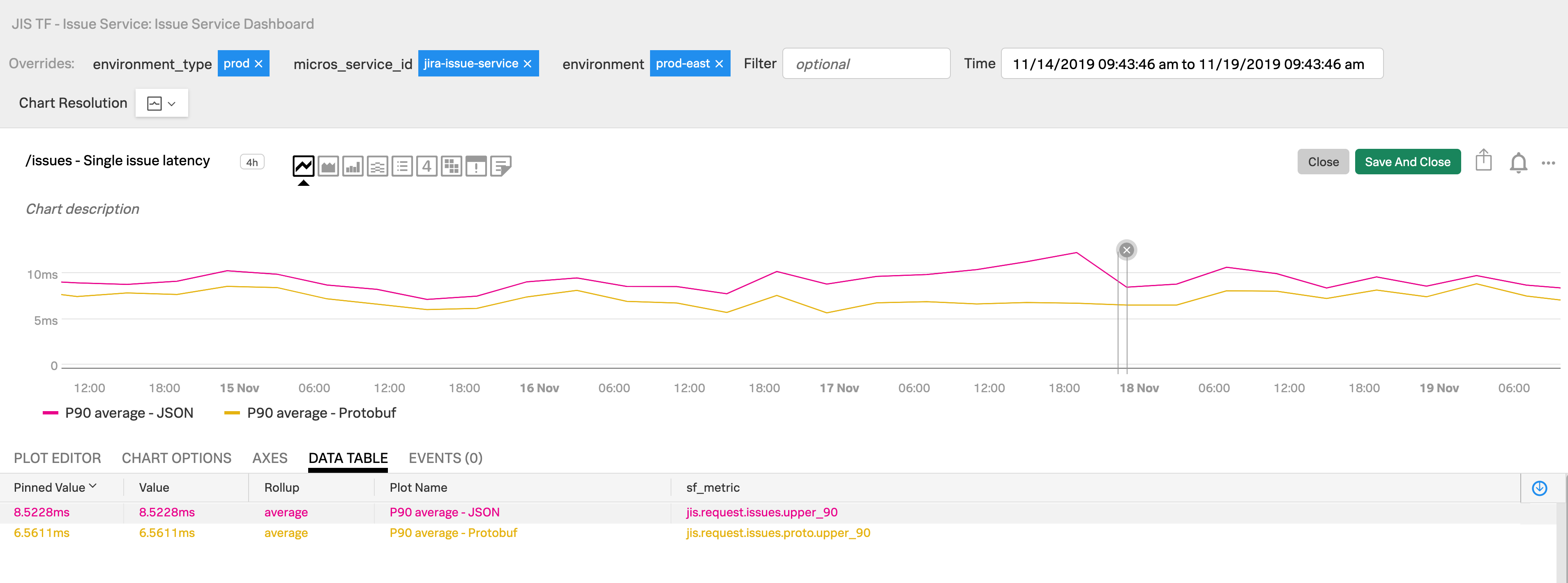
Looking at the values in the data table, the processing time is ~20% faster in Protobuf.
Reduced Memcached infrastructure usage
The size of our Memcached cluster was driven by the memory required to store Issue data. With the smaller size in the cache item, now we can reduce the Memcached cluster size by 55%
Learnings
Protobuf is not NULL friendly
In the Protobuf world, we can’t set a property to be null. But a property can be absent (i.e. no value was set) and a default value will be provided based on the type (e.g., a String type will designate the empty string as the default value, and an Number field will have 0 as a value). That means we have to do extra work if there is a difference between a value being absent and the value being the default value (e.g., it is valid for fields containing a number to contain either the number 0 or no data).
The way that we solved this problem was to explicitly store no data at all about a field if that field has no value. Then during the read of the issue data, if we detect that there is a field in the configuration that does not exist in the data returned from the cache, we create a default empty field for that. This turned out to be a very good optimization that substantially improved our storage efficiency, as fields are often present on an Issue with no associated value. The tradeoff is a relatively negligible CPU overhead at read-time.
Protobuf is not Spring friendly, YET
Atlassian is widely using Spring for existing and future micro-services. The Issue Service is one of those micro-services, and its main stack is Spring, Kotlin, Memcached, DynamoDB, and SQS.
Spring has a default error controller that will turn any exceptions in the controller into a response entity with an error status and a map of string to object body. Then Spring has to find a converter that is able to convert that map into an HTTP response. This works well with the JSON response type. However, there is a problem when the response type is Protobuf, as no converter is able to convert a map into a HTTP response with a application/x-protobuf response type. This is because ProtobufHttpMessageConverter only understands Protobuf Message type. When this happens, an exception HttpMediaTypeNotAcceptableException was thrown, and then Spring will return with a status HTTP 406 Not Acceptable.
We wanted to preserve the original response code, so we came up with a work-around solution to register our own exception handler for that exception. That handler will return the original error code, which is kept in the request attributes under the name javax.servlet.error.status_code(RequestDispatcher.ERROR_STATUS_CODE).
Protobuf default value is NULL when transferred via the wire
As mentioned above, we opted to use Protobuf over REST because AWS ALB did not support gRPC for the connections from ALB to the backend. This leads to a few edge cases when we call back to Jira to get the issue data and get back NULL. We investigated and found that it was because somehow the issue is deleted just after it is requested. When Jira can’t find the issue, it just returns the default value, which is an empty issue in our case. The default value here is just an empty array, and when it is transferred back to the Issue Service, it’s actually NULL, as in there is no response body (while in JSON’s case, it’s an empty object). The fix is simple; we just support NULL gracefully in the Issue Service, as follows.
Let’s say we have a controller that may return a default value Protobuf as the following:
@RestController
class TestController {
@GetMapping("/test")
fun get(): ByteArray {
return IssueResponse.newBuilder().build().toByteArray()
}
}And we have a consumer of that controller in the following code:
class TestControllerIntegrationTest : IntegrationTestBase() {
@Test
fun `test return protobuf default value`() {
val responseEntity = testRestTemplate.getForEntity("/test", ByteArray::class.java)
// this will be passed as the request body is null
assertThat(responseEntity.body).isNull()
// this is how to handle it gracefully
val requestBody = responseEntity.body ?: ByteArray(0)
val issueResponse = IssueResponse.parseFrom(requestBody)
// do logic related to IssueResponse
}
}The main point here is that the Protobuf default value will be converted to an empty array, which will be transferred on the wire as NULL. And we have to handle it gracefully by using responseEntity.body ?: ByteArray(0).
Memcached will not immediately handle changes in items’ size, but it will eventually
During the rollout, even though our Protobuf item is smaller and the serialization and deserialization time is faster, we saw that the service response time was higher than before, which was unexpected.
After some investigation, we observed that there was an increase in the cache eviction rate, which was surprising, as the overall memory usage of the cache was not very high.
It turns out that this happens because of how Memcached manages the memory. In short, Memcached will create pages, and each page will be 1Mb in size. Memcached also creates Slab classes, and a Slab class will be used to store items that are smaller than a specific size (e.g., there will be a slab to store items that are less than 100Kb, and another slab to store items less than 200Kb, but greater than 100Kb).
So when we ask to store an item into Memcached, it will:
- Find the Slab class that fits the item.
- In that Slab class, it then checks if there are any pages that have free memory.
- If there are, it will put the items there; if not, it checks if there are any pages that are not assigned to any Slab class yet.
- If there are, it will assign the page into the Slab class, and then put the item into that page. If there aren’t, it will start evicting items from the pages that belong to this Slab class even though there are empty pages in other Slab classes (once the pages are assigned to a Slab class, others can’t use it anymore, even when those pages are free)
As the size of our data is now ~80% smaller than before, they belong to different Slab class. JSON was stored in Memcached long before Protobuf, so the Slab class had allocated pages to fit the data-size distribution of JSON, leaving less room for the smaller Protobuf data. As a result, the Protobuf slab gets more evictions, and that’s why the cache hit rate dropped.
Our initial solution was to restart the Memcached cluster one node at a time, which we did for a single region in order to validate our hypothesis. Then we learn that in the new version of Memcached (1.4.33 or later), there is a slab_automove configuration that will slowly move empty pages between slabs. We had already validated our hypothesis about cache eviction rates being related to slab sizing, so we decided to wait for Memcached to automatically rebalance the pages. After waiting for a few weeks, we have seen cache evictions return to expected levels, and cache hit rates approach 99%!
Conclusion
Moving data serialization format used by the Issue Service to Protobuf resulted in many improvements, including faster response time and reduced resource consumption (CPU, storage). Even though there were some challenges we had to solve during the migration, the final results were absolutely worth the effort. As we continue our work in the Issue Service and progress to handling more traffic and data, the impact of these relative improvements will continue to grow.