Monorepos in Git
What is a monorepo?
Definitions vary, but we define a monorepo as follows:
- The repository contains more than one logical project (e.g. an iOS client and a web-application)
- These projects are most likely unrelated, loosely connected or can be connected by other means (e.g via dependency management tools)
- The repository is large in many ways:
- Number of commits
- Number of branches and/or tags
- Number of files tracked
- Size of content tracked (as measured by looking at the .git directory of the repository)
Facebook has one such example of a monorepo:
With thousands of commits a week across hundreds of thousands of files, Facebook’s main source repository is enormous—many times larger than even the Linux kernel, which checked in at 17 million lines of code and 44,000 files in 2013.
related material
How to move a full Git repository
SEE SOLUTION
Learn Git with Bitbucket Cloud
And while conducting performance tests, the test repository Facebook used were as follows:
- 4 million commits
- Linear history
- ~1.3 million files
- The size of the .git directory was roughly 15GB
- The size of the index file was 191MB
Conceptual challenges
There are many conceptual challenges when managing unrelated projects in a monorepo in Git.
First, Git tracks the state of the whole tree in every single commit made. This is fine for single or related projects but becomes unwieldy for a repository containing many unrelated projects. Simply put, commits in unrelated parts of the tree affect the subtree that is relevant to a developer. This issue is pronounced at scale with large numbers of commits advancing the history of the tree. As the branch tip is changing all the time, frequent merging or rebasing locally is required to push changes.
In Git, a tag is a named alias for a particular commit, referring to the whole tree. But usefulness of tags diminishes in the context of a monorepo. Ask yourself this: if you’re working on a web application that is continuously deployed in a monorepo, what relevance does the release tag for the versioned iOS client have?
Performance issues
Alongside these conceptual challenges are numerous performance issues that can affect a monorepo setup.
Number of commits
Managing unrelated projects in a single repository at scale can prove troublesome at the commit level. Over time this can lead to a large number of commits with a significant rate of growth (Facebook cites “thousands of commits a week”). This becomes especially troublesome as Git uses a directed acyclic graph (DAG) to represent the history of a project. With a large number of commits any command that walks the graph could become slow as the history deepens.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Number of refs
A large number of refs (i.e branches or tags) in your monorepo affect performance in many ways.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
User time (seconds): 146.44*
*This will vary depending on page caches and the underlying storage layer.
Number of files tracked
The index or directory cache (.git/index) tracks every file in your repository. Git uses this index to determine whether a file has changed by executing stat(1) on every single file and comparing file modification information with the information contained in the index.
Thus the number of files tracked impacts the performance* of many operations:
git statuscould be slow (stats every single file, index file will be large)git commitcould be slow as well (also stats every single file)
*This will vary depending on page caches and the underlying storage layer, and is only noticeable when there are a large number of files, in the realm of tens or hundreds of thousands.
Large files
Large files in a single subtree/project affects the performance of the entire repository. For example, large media assets added to an iOS client project in a monorepo are cloned despite a developer (or build agent) working on an unrelated project.
Combined effects
Whether it's the number of files, how often they're changed or how large they are, these issues in combination have an increased impact on performance:
- Switching between branches/tags, which is most useful in a subtree context (e.g. the subtree I'm working on), still updates the entire tree. This process can be slow due to the number of files affected or requires a workaround. Using
git checkout ref-28642-31335 -- templatesfor example updates the./templatesdirectory to match the given branch but without updatingHEADwhich has the side effect of marking the updated files as modified in the index. - Cloning and fetching slows and is resource intensive on the server as all information is condensed in a packfile before transfer.
- Garbage collection is slow and by default triggered on a push (if garbage collection is necessary).
- Resource usage is high for every operation that involves the (re-)creation of a packfile, e.g.
git upload-pack, git gc.
Mitigation strategies
While it would be great if Git would support the special use case that monolithic repositories tend to be, Git's design goals that made it hugely successful and popular are sometimes at odds with the desire to use it in a way it wasn't designed for. The good news for the vast majority of teams is that really, truly large monolithic repositories tend to be the exception rather than the rule, so as interesting as this post hopefully is, it most likely won't apply to a situation that you are facing.
That said, there are a range of mitigation strategies that can help when working with large repositories. For repositories with long histories or large binary assets, my colleague Nicola Paolucci describes a few workarounds.
Remove refs
If your repository has refs in the tens of thousands, you should consider removing refs you don't need anymore. The DAG retains the history of how changes evolved, while merge commits point to its parents so work conducted on branches can be traced even if the branch doesn't exist anymore.
In a branch based workflow the number of long lived branches you want to retain should be small. Don't be afraid to delete a short lived feature branch after a merge.
Consider removing all branches that have been merged into a main branch like production. Tracing the history of how changes have evolved is still possible, as long as a commit is reachable from your main branch and you have merged your branch with a merge commit. The default merge commit message often contains the branch name, allowing you to retain this information if necessary.
Handling large numbers of files
If your repository has a large number of files (in the tens to hundreds of thousands), using fast local storage with plenty of memory that can be used as a buffer cache can help. This is an area that would require more significant changes to the client similar for example to the changes that Facebook implemented for Mercurial
Their approach used file system notifications to record file changes instead of iterating over all files to check whether any of them changed. A similar approach (also using watchman) has been discussed for git but has not been eventuated yet.
Use Git LFS (Large File Storage)
This section was updated January 20th, 2016
For projects that include large files like videos or graphics, Git LFS is one option for limiting their impact on the size and overall performance of your repository. Instead of storing large objects directly in your repository, Git LFS stores a small placeholder file with the same name containing a reference to the object, which is itself stored in a specialized large object store. Git LFS hooks into Git's native push, pull, checkout, and fetch operations to handle the transfer and substitution of these objects in your worktree transparently. This means you can work with large files in your repository as you normally would, without the penalty of bloated repository sizes.
Bitbucket Server 4.3 (and later) embeds a fully compliant Git LFS v1.0+ implementation, and allows preview and diffing of large image assets tracked by LFS directly within the Bitbucket UI.
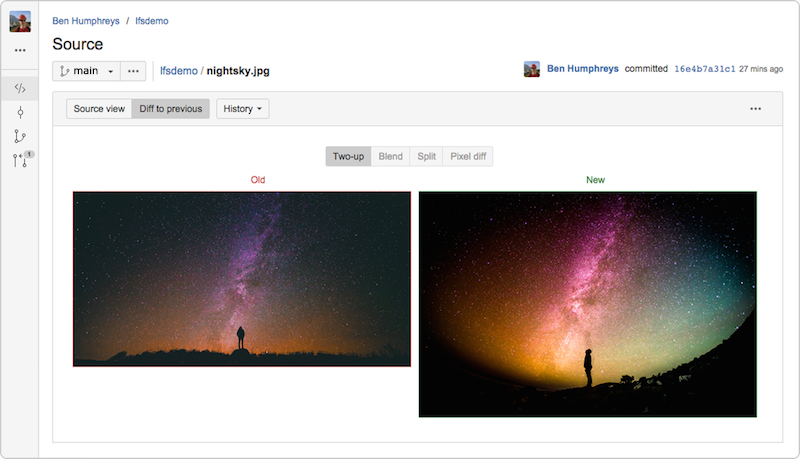
My fellow Atlassian Steve Streeting is an active contributor to the LFS project and recently wrote about the project.
Identify boundaries and split your repository
The most radical workaround is splitting your monorepo into smaller, more focused git repositories. Try moving away from tracking every change in a single repository and instead identify component boundaries, perhaps by identifying modules or components that have a similar release cycle. A good litmus test for clear subcomponents are the use of tags in a repository, and whether they make sense for other parts of the source tree.
While it would be great if Git supported monorepos elegantly, the concept of a monorepo is slightly at odds with what makes Git hugely successful and popular in the first place. However that doesn't mean you should give up on the capabilities of Git because you have a monorepo - in most cases there are workable solutions to any issues that arise.
Share this article
Next Topic
Recommended reading
Bookmark these resources to learn about types of DevOps teams, or for ongoing updates about DevOps at Atlassian.

Bitbucket blog

DevOps learning path
