What is a distributed system?
An overview of distributed systems and microservices architectures

Kev Zettler
Full Stack Web Developer
A distributed system is a collection of computer programs that utilize computational resources across multiple, separate computation nodes to achieve a common, shared goal. Distributed systems aim to remove bottlenecks or central points of failure from a system.
What happens when you build an application as a single, deployable unit that works quite well, but over time it grows in size and complexity? It often becomes more challenging to maintain, development velocity slows, and risk of failure increases. In this case, the evolutionary path is for the monolith to evolve into a distributed system, typically a microservices architecture.

Try Compass for free
Improve your developer experience, catalog all services, and increase software health.
What is a distributed system?
A distributed system is a collection of computer programs that utilize computational resources across multiple, separate computation nodes to achieve a common, shared goal. Also known as distributed computing or distributed databases, it relies on separate nodes to communicate and synchronize over a common network. These nodes typically represent separate physical hardware devices but can also represent separate software processes, or other recursive encapsulated systems. Distributed systems aim to remove bottlenecks or central points of failure from a system.
Distributed computing systems have the following characteristics:
Resource sharing – A distributed system can share hardware, software, or data
Simultaneous processing – Multiple machines can process the same function simultaneously
Scalability – The computing and processing capacity can scale up as needed when extended to additional machines
Error detection – Failures can be more easily detected
Transparency – A node can access and communicate with other nodes in the system
related material
Microservices vs. monolithic architecture
SEE SOLUTION
Improve your DevEx with Compass
What is the difference between a centralized system and a distributed system?
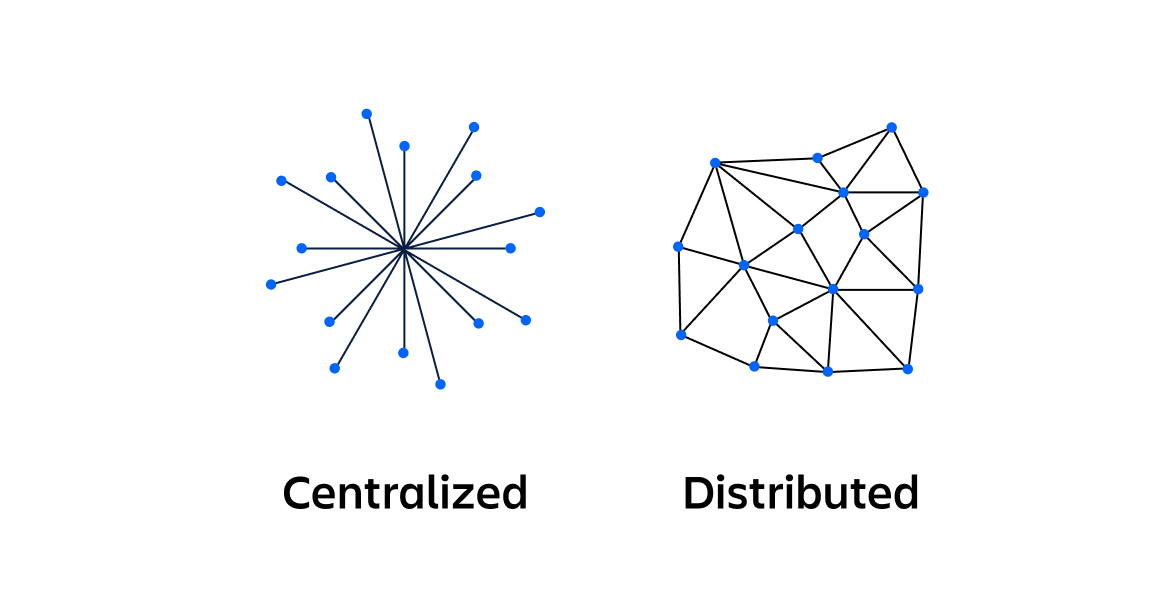
A centralized computing system is where all computing is performed by a single computer in one location. The primary difference between centralized and distributed systems is the communication pattern between the system’s nodes. The state of a centralized system is contained within a central node that clients access in a bespoke manner. Nodes of a centralized system all access the central node, which can lead to network congestion and slowness. A centralized system has a single point of failure while a distributed system has no single point of failure.
Are distributed systems the same as microservices?
A microservices architecture is one type of distributed system, since it decomposes an application into separate components or “services”. For example, a microservice architecture may have services that correspond to business features (payments, users, products, etc.) where each corresponding component handles the business logic for that responsibility. The system will then have multiple redundant copies of the services so that there is no central point of failure for a service.
What is distributed tracing?
Distributed tracing is a method used to profile or monitor the result of a request that is executed across a distributed system. Monitoring a distributed system can be challenging because each individual node has its own separate stream of logs and metrics. To get an accurate view of a distributed system, these separate node metrics need to be aggregated into a holistic view.
Requests to distributed systems generally don’t access the entire set of nodes within the system but instead access a partial set, or a path through the nodes. Distributed tracing illuminates commonly accessed paths through a distributed system and allows teams to analyze and monitor these paths. Distributed tracing is installed in each node of the system and then allows teams to query the system for information on node health and request performance.
Benefits, drawbacks, and risks of distributed systems
Distributed systems often help to improve system reliability and performance. Reliability is improved by removing central points of failure and bottlenecks. The nodes of a distributed system offer redundancy so that if any node fails there are other nodes ready to cover and replace the failure. Performance is improved because nodes can easily be scaled horizontally and vertically. If a system undergoes extensive load, extra nodes can be added to help absorb the load. An individual node’s capacity can also be increased to handle extensive load.
However, the tradeoff to these benefits can be “development sprawl”, where a system becomes overly complex and maintenance becomes challenging. As a system grows in complexity, teams may struggle to effectively organize, manage, and improve these systems. Part of the issue can be understanding how different components relate to each other or who owns a particular software component. This makes it hard to understand how to make changes to components in ways that maximise operational health and avoid causing negative impact to not just dependent components, but customers. When a system has multiple repositories, specialized tools like Atlassian’s Compass may be required to manage and organize the code of a distributed system.
Architectures of distributed systems
There are numerous types of distributed systems. The most common are as follows:
Client-server
A client-server architecture is broken down into two primary responsibilities. The client is responsible for the user interface presentation, which then connects over the network to the server. The server is responsible for handling business logic and state management. A client-server architecture can easily degrade into a centralized architecture if the server is not made redundant. A truly distributed client-server setup will have multiple server nodes to distribute client connections. Most modern client-server architectures are clients that connect to an encapsulated distributed system on the server.
Multi-tier
A multi-tier architecture expands on the client-server architecture. The server in a multi-tier architecture is decomposed into further granular nodes, which decouple additional backend server responsibilities like data processing and data management. These additional nodes are used to asynchronously process long-running jobs and free up the remaining backend nodes to focus on responding to client requests, and interfacing with the data store.
Peer-to-peer
In a peer-to-peer distributed system, each node contains the full instance of an application. There is no node separation of presentation and data processing. A node contains the presentation layer and data handling layers. The peer nodes may contain the entire state data of the entire system.
Peer-to-peer systems have the benefit of extreme redundancy. When a peer-to-peer node is initialized and brought online, it discovers and connects to other peers and synchronizes its local state with the state from the greater system. This feature means the failure of one node on a peer-to-peer system won’t disrupt any of the other nodes. It also means that a peer-to-peer system will persist.
Service-oriented architecture
Service-oriented architecture (SOA) is a predecessor of microservices. The main difference between SOA and microservices is node scope – the scope of microservice nodes exist at the feature level. In microservices a node encapsulates the business logic to handle a specific feature set, such as payment processing. Microservices contain multiple disparate business logic nodes that interface with independent database nodes. Comparatively, SOA nodes encapsulate an entire application or enterprise division. The service boundary for SOA nodes typically includes an entire database system within the node.
Microservices have emerged as a more popular alternative to SOA due to their benefits. Microservices are more composable, allowing teams to reuse functionality provided by the small service nodes. Microservices are more robust and enable more dynamic vertical and horizontal scaling.
Distributed systems use cases
Many modern applications utilize distributed systems. High traffic web and mobile applications are distributed systems. Users connect in a client-server manner, where the client is a web browser or a mobile application. The server is then its own distributed system. Modern web servers follow a multi-tier system pattern. A load balancer is used to delegate requests to many server logic nodes that communicate over message queue systems.
Kubernetes is a popular tool for distributed systems, since it can create a distributed system from a collection of containers. The containers create nodes of the distributed system and then Kubernetes orchestrates network communication between the nodes and also handles the dynamic horizontal and vertical scaling of nodes in the system.
Another good example of distributed systems are cryptocurrencies like Bitcoin and Ethereum, which are peer-to-peer distributed systems. Every node in a cryptocurrency network is a self-contained replication of the full history of the currency ledger. When a currency node is brought online, it bootstraps by connecting to other nodes and downloading its full copy of the ledger. Additionally, cryptocurrencies have clients or “wallets” that connect to the ledger nodes via JSON RPC protocol.
In conclusion…
Distributed systems are widely adopted and used in most modern software experiences. Social media apps, video streaming services, e-commerce sites, and more are all powered by distributed systems. Centralized systems naturally evolve into distributed systems to handle scaling. The use of microservices is a popular and widely adopted pattern for building a distributed system.
While distributed systems are more complex to build and maintain, Atlassian’s Compass addresses this complexity. It’s a developer experience platform that helps you navigate your distributed architecture, bringing disconnected information about engineering output and the teams collaborating on them together in a central, searchable location.
Share this article
Next Topic
Recommended reading
Bookmark these resources to learn about types of DevOps teams, or for ongoing updates about DevOps at Atlassian.

Compass community

Tutorial: Create a component