

本ブログは、こちらに掲載されている英文ブログの意訳です。万が一内容に相違がある場合は、原文が優先されます。また、PDF版をダウンロードいただけます。
はじめに – 共同創業者兼共同最高経営責任者より
2022年4月上旬に発生した障害により、お客様へのサービス提供が中断されたことをお詫び申し上げます。私たちは、当社の製品がお客様のビジネスにとってミッションクリティカルであることを理解しており、その責任を重く受け止めています。今回の全責任は私たちにあり、影響を受けたお客様の信頼を回復するために尽力しています。
アトラシアンのコア バリューの 1 つに「オープンな企業文化、デタラメは無し (Open company, no bullshit)」というものがあります。この価値を実現する取り組みの一環として、インシデントについてオープンに議論し、学びにつなげています。そして、このインデント事後レビュー (以下、PIR) をお客様、アトラシアン コミュニティ、より広範な技術コミュニティ向けに公開しています。
アトラシアンは、大規模かつ信頼できるサービスを提供する上では、非難しない文化と技術的なシステムとプロセスの改善に注力することが重要であると強調している当社のインシデント管理プロセスに誇りを持っています。当社は、あらゆる種類のインシデントを回避するために最善を尽くしながら、インシデントを今後の改善につなげるべく強力な学びに転換しています。
アトラシアンのクラウドプラットフォームは、あらゆる規模や業界の20万人を超えるお客様にご利用いただき、その多様なニーズに対応しています。今回のインシデント発生まで、当社のクラウドサービスは着実に 99.9% のアップタイムを提供し、SLA を上回っていました。当社では、スケーラブルなインフラストラクチャと定常的なセキュリティ強化と共に、プラットフォームや多数の中央集中型プラットフォームの機能に長期的な投資を行っています。
お客様およびパートナーの皆様には、継続的な信頼とご協力に御礼申し上げます。アトラシアンはあらゆるチームのニーズを満たすべく、引き続き、世界レベルのクラウドプラットフォームと強力な製品ポートフォリオを提供してまいりますことを、本ドキュメントで説明する詳細内容と取り組みを通してお伝えできましたら幸いです。
– Scott Farquhar、Mike Cannon-Brookes
エグゼクティブサマリー
2022 年 4 月 5 日(火) 7:38 UTC より、775 社のお客様がお使いのアトラシアン製品へのアクセスを失いました。このアクセス停止は、一部のお客様においては最大 14 日間に及び、最初にいくつかのお客様サイトが 4 月 8 日に復旧され、その後 4 月 18 日までにすべてのお客様のサイトが段階的に復旧されました。
これはサイバー攻撃の結果ではなく、お客様データへの不正アクセスもありませんでした。アトラシアンには包括的なデータ管理プログラムが用意されていると共にSLAも公開しており、これまで SLA を上回る実績を記録していました。
今回のインシデントは重大なものではありましたが、5 分以上のデータ損失を伴ったお客様は確認されませんでした。さらに復旧作業中も、99.6% 以上のお客様とユーザーはその影響を受けることなく、アトラシアンのクラウド製品を継続して利用されていました。
本ドキュメントにおいて、今回のインシデントの一環でサイトが削除されたお客様を「影響を受けたお客様」と表します。この PIR では、インシデントについての正確な詳細と、復旧のために実施した手順の概要、そして今後の再発を防止するための対策についてご説明します。この章ではインシデントの概要に触れ、詳細はドキュメントの残り章で解説します。
発生事象
当社は、2021 年に「Insight – Asset Management」と呼ばれる Jira Service Management および Jira Software のためのスタンドアロンのアトラシアン アプリを買収し、統合しました。これに伴い、このスタンドアロンアプリの機能はJira Service Management に内包され、Jira Software では利用できなくなったため、当該アプリをインストールされていたお客様サイトから、レガシーとなったスタンドアロンアプリを削除する必要がありました。当社のエンジニアリング チームは、既存のスクリプトとプロセスを使用して当該アプリのインスタンスを削除しようと計画していましたが、次の 2 つの問題が発生しました。
- コミュニケーション ギャップ: 削除を依頼したチームと、削除を実行したチームの間にコミュニケーションのギャップがあり、削除の対象となっているアプリの ID を提供する代わりに、アプリを削除するクラウド サイト全体の ID を提供しておりました。
- 不十分なシステム警告: 削除を実行するために使用された API は、サイト ID とアプリ ID の両方の識別子を受け入れ、入力された値が正しいことを前提としていました。つまり、サイト ID が渡されるとサイトが削除され、アプリ ID が渡されるとアプリが削除される状態で、リクエストされている削除の種類 (サイトなのか、またはアプリなのか) の確認を促す警告は発生されませんでした。
実行されたスクリプトは、どのエンドポイントがどのように呼び出されているかに焦点を当てた当社の標準的なピアレビュープロセスに従ったものでした。提供されたクラウドサイト ID が Insight アプリまたはサイト全体を参照しているかの検証をするための照合は行われず、問題はスクリプトにお客様のサイト全体の ID が含まれていたことでした。その結果、2022 年 4 月 5 日(火) 7:38 UTC から 8:01 UTC の間に 883 件のサイト (775 社のお客様に相当) が即座に削除されました。詳細へのリンク
当社の対応
4 月 5 日 8:17 UTC にインシデントが確認されると、当社は重大インシデントの管理プロセスを開始し、部門横断型のインシデント管理チームを結成しました。グローバルのインシデント対応チームは、すべてのサイトが復元、検証され、お客様の元に戻るまで、インシデント期間中は 24 時間体制で取り組みました。さらに、インシデント管理リーダーは 3 時間ごとに打ち合わせを持ち、ワークストリームを調整しました。
取り組みの早い段階で、複数製品を利用する数百社のお客様に対して同時に復旧を実行するには、多くの課題があることがわかりました。
インシデントの開始時点で、当社は影響を受けたサイトを正確に把握しており、当該サイトの承認された所有者に連絡を取り、サイト停止に関してお知らせすることが優先事項となっていました。
しかし、一部のお客様の連絡先情報が削除されてしまったため、該当するお客様は通常どおりにサポート チケットを起票できず、当社はお客様の主要連絡先情報にすぐにアクセスすることができませんでした。詳細へのリンク
再発防止への取り組み
既に多くの措置を講じており、今後、同様の事態を回避するための変更を行うべく尽力しています。大幅な変更を行った/変更を予定している 4 つの領域は次のとおりです。
- すべてのシステムにおいて共通して「論理削除」を確立します。概して、今回のような種類の削除は、エラーを避けるために禁止するか、複数の層で保護することが必要とされ、これには段階的なロールアウトや「論理削除」のテスト済みロールバック計画などが含まれます。論理削除のプロセスを経ていないお客様のデータおよびメタデータの削除をグローバルで防止します。
- ディザスタ リカバリ (DR) プログラムを加速し、より多くのお客様を対象に複数サイト・複数製品の削除イベントの復元を自動化します。自動化や本インシデントからの教訓を元に、DR プログラムへの取り組みを前倒しして、当社のポリシーで定義しているこの規模のインシデントに対する目標復旧時間 (RTO) の達成を目指します。大規模なサイトにおいて、すべての製品の復元を含む DR の演習を定期的に実施します。
- 大規模なインシデントのためのインシデント管理プロセスを見直します。大規模なインシデントの標準業務手順を改善し、今回の規模を想定したシミュレーションを実践します。多くのチームが並行して対応できるよう、トレーニングとツールを改めます。
- 大規模なインシデント コミュニケーション プレイブックを作成します。複数のチャンネルを通じて、インシデントを早期に認識し、インシデントに関する広報を数時間以内に公開します。また、影響を受けたお客様に速やかに連絡するために、主要連絡先のバックアップとサポート ツールを改善し、有効な URL または Atlassian ID をお持ちでないお客様が、当社の技術サポート チームに直接連絡できるようにします。
取り組みの全項目については、以下、PIR 完全版で詳細をご確認いただけます。
目次
アトラシアンのクラウド アーキテクチャの概要
本ドキュメントを通して取り上げているインシデントの要因を把握するのに役立つ、アトラシアン製品、サービス、そしてインフラストラクチャのデプロイ アーキテクチャの概要を解説します。
アトラシアンのクラウド ホスティング アーキテクチャ
アトラシアンは、クラウド サービス プロバイダーとして Amazon Web Services (AWS) を採用しており、世界中の複数リージョンにある AWS の高い可用性を備えたデータ センター施設を使用しています。各 AWS リージョンは、アベイラビリティゾーン (AZ) として知られる複数の独立かつ物理的に分離されたデータ センター群を備えた、個別の地理的な場所を指します。
当社は、AWS のコンピューティング、ストレージ、ネットワーク、データ サービスを活用して、製品およびプラットフォームのコンポーネントを構築しており、これにより AWS が提供するアベイラビリティゾーンやリージョンといった冗長性機能の利用が可能になっています。
分散型サービス アーキテクチャ
この AWS アーキテクチャには、当社のソリューション全体で使用される多数のプラットフォームや製品サービスがホストされています。これには、メディア、アイデンティティ、コマースや、エディターのようなエクスペリエンスなど、複数のアトラシアン製品で共有および利用されるプラットフォーム機能のほか、Jira 課題のサービスや Confluence アナリティクスといった製品固有の機能が含まれます。

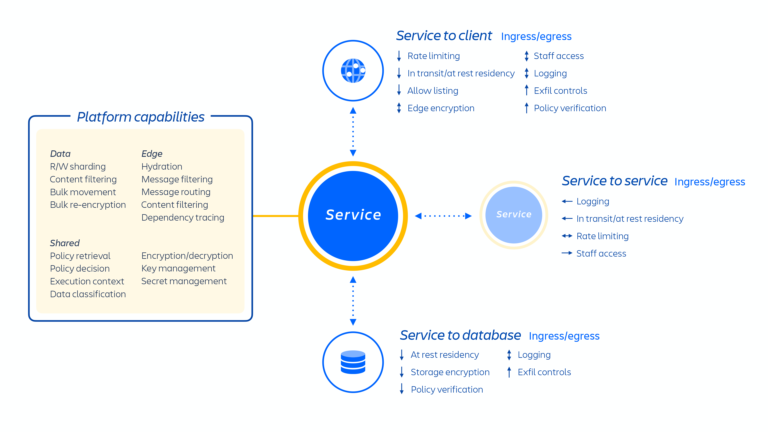
アトラシアンの開発者は、Micros と呼ばれる社内で開発された PaaS (Platform-as-a-Service) を通じて、これらのサービスをプロビジョニングします。これにより、共有サービス、インフラストラクチャ、データ ストア、セキュリティやコンプライアンス制御の要件を含む管理機能のデプロイが自動的に行われます (上の図1を参照)。通常、アトラシアン製品は、Micros を使用して AWS にデプロイされる複数の「コンテナ化」されたサービスで構成されています。アトラシアン製品では、リクエストのルーティングからバイナリ オブジェクトの格納、認証/承認、トランザクションのユーザー生成コンテンツ (UGC) やエンティティ リレーションシップの格納、データ レイク、共通ロギング、リクエスト追跡、オブザーバビリティ、分析サービスに至るコア プラットフォーム機能が使用されています (下の図2を参照)。そしてこれらのマイクロサービスは、プラットフォーム レベルで標準化された承認済みの技術スタックを使用して構築されています。
マルチテナント アーキテクチャ
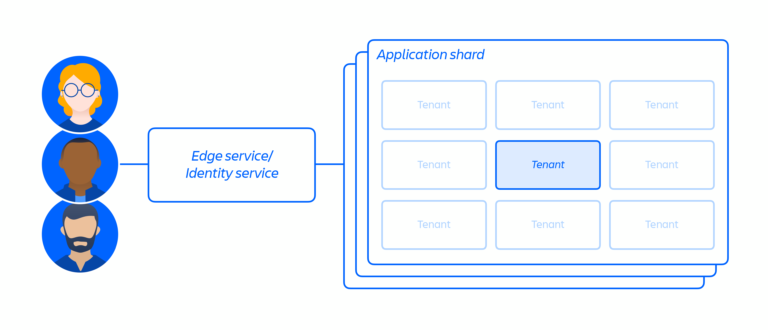
アトラシアンでは、クラウドインフラストラクチャに加え、製品をサポートする共有プラットフォームを備えたマルチテナントのマイクロサービスアーキテクチャを構築し、運用しています。マルチテナント アーキテクチャでは、単一のサービスが複数のお客様に利用されており、これにはクラウド製品の運用に必要なデータベースやコンピューティング インスタンスなどが含まれます。各シャード (基本的にはコンテナ、下の図3を参照) には複数のテナントのデータが含まれますが、各テナントのデータは分離されており、他のテナントからはアクセスできません。
テナントのプロビジョニングとライフサイクル
新規のお客様がプロビジョニングされると、一連のイベントによって分散型サービスの連携とデータ ストアのプロビジョニングがトリガーされます。これらのイベントは通常、ライフサイクルの 7 つのステップのいずれかにマッピングできます。
1. コマース システムでは、当該のお客様についての最新のメタデータとアクセス制御情報がすぐに更新され、その後プロビジョニング連携システムで、一連のテナントおよび製品イベントを通じて「プロビジョニングされたリソースの状態」がライセンスの状態と統一されます。
テナント イベント
テナント全体に影響を与えるイベントで、次のいずれかに当てはまります。
- 作成: テナントが作成され、新しいサイトに使用される
- 破棄: テナント全体が削除される
製品イベント
- アクティブ化: ライセンス製品またはサードパーティ アプリのアクティブ化の後
- 非アクティブ化: 特定の製品またはアプリの非アクティブ化の後
- 一時停止: 特定の既存製品の一時停止後、所有する特定のサイトへのアクセスを無効にする
- 一時停止の解除: 特定の既存製品の一時停止の解除後、所有するサイトへのアクセスを可能にする
- ライセンスの更新: 特定の製品のライセンス数およびそのステータス (アクティブ/非アクティブ) に関する情報を含む
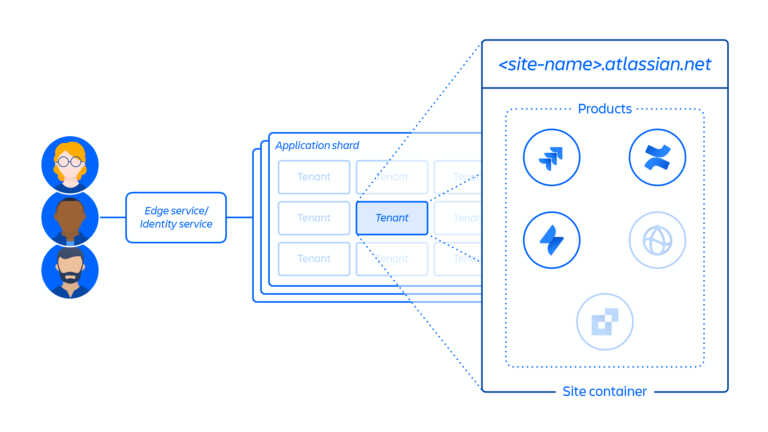
2. お客様サイトを作成し、該当する製品セットをアクティブ化します。サイトとは、特定のお客様にライセンス付与された複数製品のコンテナです (例: <site-name>.atlassian.net の Confluence と Jira Software)。このサイト コンテナが今回のインシデントで削除されたものであり、本ドキュメント全体にわたって扱われることから、この概念 (下の図4を参照) は、本レポートを把握する上で重要なポイントとなります。
3. 指定されたリージョンでお客様サイトの製品がプロビジョニングされます。
製品がプロビジョニングされると、そのコンテンツの大部分はユーザーがアクセスする場所の近くでホストされます。製品のパフォーマンスを最適化するために、グローバルでホストされている場合はデータの移動を制限せず、必要に応じてリージョン間でデータを移動させることがあります。
当社製品の一部では、データレジデンシーも提供されています。これによりお客様は、製品データをグローバルに分散させるか、あらかじめ決められた地理的ロケーションの一つに保持するかを選択できます。
4. お客様サイトおよび製品のコア メタデータと構成を作成して保存します。
5. ユーザー、グループ、権限など、サイトと製品の ID データを作成して保存します。
6. サイト内の製品データベース (例: Jira 製品ファミリー、Confluence、Compass、Atlas) をプロビジョニングします。
7. 製品ライセンスで利用できるアプリをプロビジョニングします。
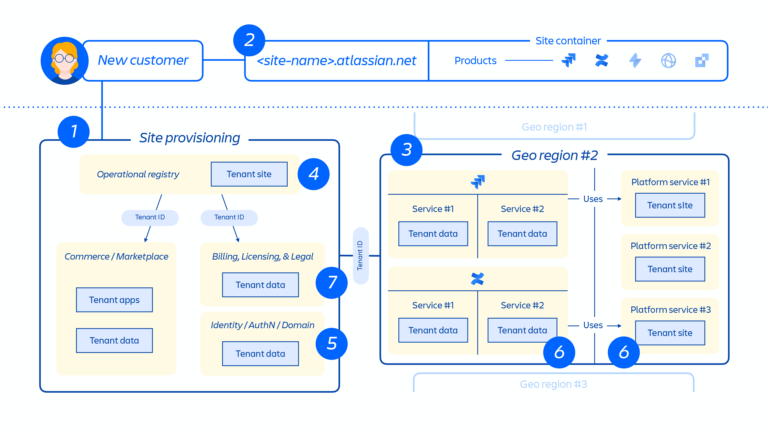
上の図5では、お客様サイトが単一のデータベースや格納場所でなく、分散型アーキテクチャ全体でどのように展開されているかを示しています。これには複数の物理的および論理的な場所が含まれており、メタデータ、構成データ、製品データ、プラットフォーム データ、その他の関連サイト情報が格納されています。
ディザスタ リカバリ プログラム
当社の障害復旧に対する取り組みは、ディザスタ リカバリ (DR) プログラムに網羅されており、インフラストラクチャの障害に対する回復と、バックアップによるサービス ストレージの復元について規定されています。ディザスタ リカバリ プログラムを理解するための 2 つの重要な概念は次のとおりです。
- 目標復旧時間 (RTO): 障害発生時に、いかに迅速にデータを復旧してお客様に返却できるかを示す。
- 目標復旧時点 (RPO): バックアップから復旧されたデータがどの程度新しいか、最後のバックアップ以降に失われるデータがどの程度かを示す。
今回のインシデントでは、RTO は達成されず、RPO のみ達成されました。
レジリエンシー
当社では、データベース全体、サービス、または AWS アベイラビリティ ゾーンの損失など、インフラストラクチャ レベルの障害に備えています。これには、複数の可用性ゾーンにわたるデータやサービスの複製や、定期的なフェイルオーバー テストが含まれます。
サービス ストレージの復元性
ランサムウェア、悪意のある攻撃者、ソフトウェアの欠陥、運用上のエラーといったリスクを想定したサービス ストレージのデータ破損からの回復にも備えています。これには、不変的なバックアップとサービス ストレージ バックアップの復元テストが含まれます。個々のデータ ストアを取得して、以前の時点に復元することができます。
複数サイト・複数製品の自動復元性
今回のインシデント時には、多数のまとまったお客様のサイトを選択し、相互接続されているすべての製品をバックアップから以前の時点に復元することができませんでした。
これまでの当社の機能は、インフラストラクチャ、データ破損、単一サービスのイベント、または単一サイトの削除に焦点が当てられ、これまでもこの種の障害に対処し、テストする必要がありました。サイトレベルの削除において、今回のイベントの規模で迅速に自動化できるランブックが用意されておらず、そのため、すべての製品とサービス全体に対応できるツールの準備と自動化を状況に合わせて行う必要がありました。
次の章では、この複雑さと、大規模にアーキテクチャを維持できるよう進化・最適化するためにアトラシアンが取り組んでいる内容について詳しくご説明します。
発生事象とタイムライン、そして復旧
発生事象
2021 年に「Insight – Asset Management」と呼ばれる Jira Service Management および Jira Software のためのスタンドアロンのアトラシアン アプリを買収し、統合しました。これに伴い、このスタンドアロンアプリの機能は Jira Service Management に内包され、Jira Software では利用できなくなったため、当該アプリをインストールされていたお客様サイトから、レガシーとなったスタンドアロンアプリを削除する必要がありました。当社のエンジニアリング チームは、既存のスクリプトとプロセスを使用して当該アプリのインスタンスを削除しました。
ここで、次の 2 つの問題が発生しました。
- コミュニケーション ギャップ:削除を依頼したチームと、削除を実行したチームの間にコミュニケーションのギャップがあり、削除の対象となっているアプリの ID を提供する代わりに、アプリを削除するクラウド サイト全体の ID を提供しておりました。
- 不十分なシステム警告:削除を実行するために使用された API は、サイト ID とアプリ ID の両方の識別子を受け入れ、入力された値が正しいことを前提としていました。つまり、サイト ID が渡されるとサイトが削除され、アプリ ID が渡されるとアプリが削除されることになり、リクエストされている削除の種類 (サイトなのか、またはアプリなのか) の確認を促す警告は発生されませんでした。
実行されたスクリプトは、どのエンドポイントがどのように呼び出されているかに焦点を当てた当社の標準的なピアレビュープロセスに従ったもので、提供されたクラウドサイト ID がアプリなのか、サイト全体を参照しているかの検証をするための照合が行われていませんでした。このスクリプトは、当社の標準変更管理プロセスに沿ってステージングでテストされたものの、ステージング環境に ID が存在しないため、ID の入力が誤っていることは検出されませんでした。
本番環境での実行時、初めに 30 件のサイトに対してスクリプトが実行されました。この最初の本番環境での実行は成功し、対象となった 30 サイトの Insight アプリは削除され、他の弊害もありませんでした。この最初の 30 サイトの ID はコミュニケーションの行き違いが発生する前に取得され、正しい Insight アプリの ID が含まれていました。
その後、本番環境で実行されたスクリプトには、Insight アプリ ID の代わりにサイト ID が含まれており、一連の 883 件のサイトに対して実行されました。4 月 5 日 7:38 UTC にスクリプトの実行が開始され、8:01 UTC に完了しました。このスクリプトは入力リストに基づいてサイトを順番に削除したため、最初のお客様のサイトは、7:38 UTC にスクリプトの実行が開始された直後に削除されました。結果的に、883 サイトがすぐに削除され、エンジニアリング チームへの警告もありませんでした。
影響を受けたお客様は、Jira 製品ファミリー、Confluence、Atlassian Access、Opsgenie、Statuspage を利用できなくなりました。
インシデントを認識した後すぐに、当社のチームは影響を受けたすべてのお客様のサイト復元に取り掛かりました。当初、影響を受けたサイトの数は 700 件と推定されていました (合計で 883 件のサイトが影響を受けたものの、アトラシアンが所有するサイトが除外されています)。この 700 サイトのうち、多くが非アクティブ、無料、またはアクティブ ユーザーの数が少ない小規模なアカウントであったため、これに基づき、影響を受けたお客様のおおよその数を約 400 社と推定しました。
現在は正確な状況を把握しており、アトラシアンで規定されている「お客様」の定義に基づくと、775 社のお客様がサービス停止による影響を受けた旨を、透明性を確立すべくここに明記します。ユーザーの多くは、当初推定された 400 社のお客様に含まれています。アトラシアン製品へのアクセス停止は、一部のお客様においては最大 14 日間に及び、最初のお客様サイトが 4 月 8 日に復旧され、その後 4 月 18 日までにすべてのお客様のサイトが復旧されました。
当社の対応
最初のサポート チケットは、影響を受けたお客様によって 4 月 5 日 7:46 UTC に起票されました。サイトは標準のワークフロー経由で削除されたため、社内の監視システムでは問題は検出されませんでした。8:17 UTC に重大インシデントの管理プロセスが開始され、部門横断型のインシデント管理チームを結成しました。7 分後の 8:24 UTC にインシデントの重要度を「重大」に上げました。8:53 UTC に、チームはお客様のサポート チケットとスクリプトの実行が関連していることを確認しました。復旧が複雑になることが認識され、12:38 UTC には本インシデントに最高レベルの重要度を定めました。
インシデント管理チームは、エンジニアリング、カスタマー サポート、プログラム管理、広報など、アトラシアン全社にわたる複数のチームからメンバーが集まり構成されていました。核となるチームは、すべてのサイトが復元、検証され、お客様の元に戻るまで、インシデント期間中は 3 時間ごとに打ち合わせを持ちました。
復元の進捗を管理するために、新たに Jira プロジェクト「SITE」とワークフローを作成し、複数のチーム (エンジニアリング、プログラム管理、サポートなど) が関与してサイトごとに復元を追跡しました。このアプローチにより、すべてのチームが個々のサイトの復元に関する問題を特定し、追跡しやすくなりました。
4 月 8 日 3:30 UTC に、インシデントの期間中はすべてのエンジニアリングのコードフリーズを行うことを決定し、実装しました。これにより、お客様サイトの復旧に集中し、お客様のデータの不整合を引き起こし得る変更のリスクを排除して、他のサービス停止のリスクを最小限に抑え、他の変更によってチームの復旧作業が妨げられる可能性を低減しました。
インシデントのタイムライン

復旧ワークストリームの概要
復旧は、検出、早期復旧、加速という 3 つの主要なワークストリームで実行されました。以下で各ワークストリームについて説明していますが、復旧作業中は、すべてのワークストリームの作業が並行して行われました。
ワークストリーム 1: 検出、復旧の開始およびアプローチの特定
【タイムスタンプ: 1 – 2 日目 (4 月 5 日 – 6 日)】
4 月 5 日 08:53 UTC に、Insight アプリのスクリプトによってサイトが削除されたことを検出しました。これは内部の悪意のある行為やサイバー攻撃の結果ではないことを確認しました。関連する製品チームおよびプラットフォーム インフラストラクチャのチームに連絡し、インシデント対応に参加させました。
インシデントの開始時点で、次のことを認識していました。
- 削除された数百サイトの復元は、複雑でマルチステップのプロセスとなり (詳細は上記のアーキテクチャに関する章を参照)、正常に完了するまで多くのチームと日数が必要となる。
- 単一サイトを復旧する機能はあったものの、大量のサイトをまとめて復旧する機能とプロセスは構築されていない。
その結果、影響を受けたお客様ができる限り早急にアトラシアン製品にアクセスできるようにするには、復元プロセスを大幅に並列化および自動化する必要がありました。
ワークストリーム 1 では、次のアクティビティに従事する多数の開発チームが関与していました。
- パイプライン内にあるサイトを一括で復元できるステップを特定して実行する。
- 一括で多くのサイトの復元手順を実行できるよう自動化を作成・改善する。
ワークストリーム 2: 早期復旧と復元 1 のアプローチ
スクリプトの実行完了後 1 時間以内である 4 月 5 日 8:53 UTC に、サイトが削除された原因が判明しました。また、少数のサイトを本番環境に回復するために以前使用されていた復元プロセスも特定しました。しかし、今回の規模で削除されたサイトを復元するための復旧プロセスは明確に定義されていません。
迅速な対応のために、インシデントの初期段階を次の 2 つの作業グループに分割しました。
- 手動作業グループは、必要な手順を検証し、少数のサイト向けの復元プロセスを手動で実行する。
- 自動化作業グループは、既存の復元プロセスを元に、多くのサイトに対して一括で安全に実行するための自動化を構築する。
復元 1 のアプローチの概要 (下の図7を参照):
- 削除されたサイトごとに新しいサイトを作成した後、データの復元が必要となるすべての製品、サービス、データ ストアを準備する必要がある。
- 新しいサイトには、
cloudIdという新しい識別子が追加される。これらの識別子はすべて不変と見なされ、多くのシステムでこれらの識別子がデータ レコードに埋め込まれる。結果として、これらの識別子が変更された場合、大量のデータを更新する必要があり、サードパーティ製アプリでは特に問題となる。 - 新しいサイトを変更することで削除されたサイトの状態を複製すると、手順間において複雑で予期しない依存関係が頻繁に発生した。
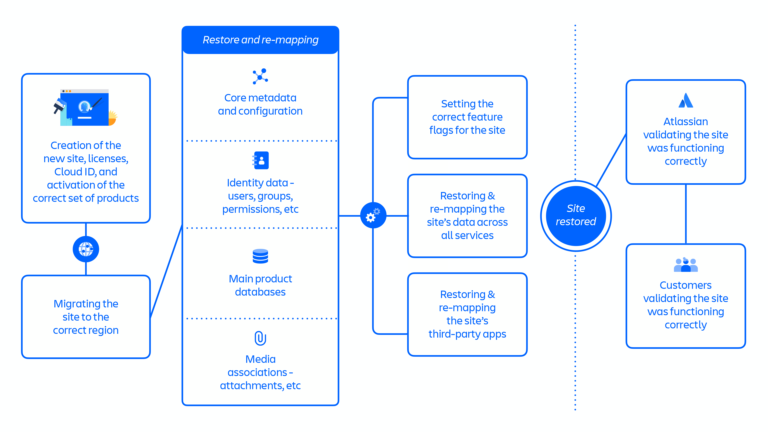
復元 1 のアプローチでは約 70 ステップに及ぶ個別の手順があり、主なポイントに集約すると、下記の一連のフローとなります。
- 新しいサイト、ライセンス、Cloud ID の作成と、適切な一連の製品の有効化
- 正しいリージョンへのサイトの移行
- サイトのコア メタデータと構成の復元および再マッピング
- サイトの ID データ (ユーザー、グループ、権限など) の復元および再マッピング
- サイトの主要な製品データベースの復元
- サイトに関連するメディア (添付ファイルなど) の復元および再マッピング
- サイトへの適切な機能フラグの設定
- すべてのサービスにわたるサイトのデータの復元および再マッピング
- サイトのサードパーティ アプリの復元および再マッピング
- サイトが正常に機能することをアトラシアンが検証
- サイトが正常に機能することをお客様が検証
最適化の後、復元 1 のアプローチは約 48 時間をかけて複数のまとまったサイトを復元し、4 月 5 日から 14 日の間に 112 サイトが復旧されました。これは影響を受けたユーザーの 53% にあたります。
ワークストリーム 3: 復旧の加速と復元 2 のアプローチ
【タイムスタンプ: 4 – 13 日目 (4 月 9 日 – 17 日)】
復元 1 のアプローチでは、すべてのお客様を復元するのに 3 週間かかることが想定されました。そこで、4 月 9 日に新しいアプローチである復元 2 を提案し、すべてのサイトの復元スピードを加速させました (下の図8を参照)。
復元 2 のアプローチでは、復元 1 のアプローチにあった複雑さと依存関係の数を削減することで、復元手順間の並列性が向上されました。
復元 2 では、カタログ サービスの記録から始まり、関連するすべてのシステムでサイトに関する記録の再作成 (または削除の取り消し) を行いました。この新しいアプローチの重要な要素は、古いサイト識別子をすべて再利用することでした。これにより、サイトごとに必要であったすべてのサードパーティ アプリ ベンダーとの調整を含む、以前の古い識別子を新しい識別子にマッピングするプロセスの半分以上の手順を省くことができました。
しかし、復元 1 から復元 2 のアプローチへの移行により、インシデント対応の負担が増大しました。
- 復元 1 のアプローチで確立された自動化スクリプトとプロセスの多くを、復元 2 で変更する必要があった。
- 復元を実行するチーム (インシデント コーディネーターなど) は、復元 2 のプロセスのテストおよび検証を行いながら、両方のアプローチで復元の並行バッチを管理しなければならない。
- 新しいアプローチを使用するには、拡張する前に復元 2 のプロセスをテストして検証する必要があり、復元 1 で完了した検証作業を複製しなければならない。
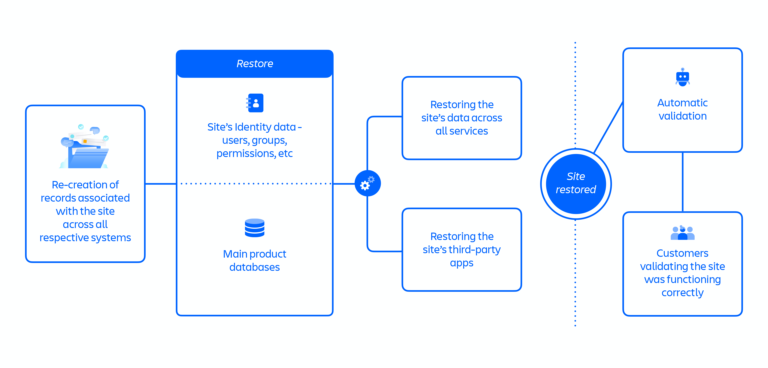
上の図は、復元 2 のアプローチを表しています。30 ステップを超える手順が含まれており、大半は並列したフローで進められました。
- すべての個別システムに及ぶサイトに関する記録の再作成
- サイトの ID データ (ユーザー、グループ、権限など) の復元
- サイトの主要な製品データベースの復元
- すべてのサービスにおけるサイトのデータの復元
- サイトのサードパーティ アプリの復元
- 自動検証
- サイトが正常に機能することをお客様が検証
大規模なバッチ処理向けに手動復元を拡張することができないため、迅速な復旧対策の一環として、フロントロードとサイト復元を自動化する措置も講じました。復旧プロセスのシーケンシャルな特性上、大規模なデータベースおよびユーザー ベース/権限を復元するために、サイト復元に時間を要することになりました。実装した最適化には、次の内容が含まれます。
- データベースの復元や ID 同期のような、フロントロードかつ並行して長時間実行する手順に必要とされるツールや防護策を開発した。これにより他の復元手順に先立ってこれらの作業を完了できた。
- エンジニアリング チームが個々の手順に対して自動化を構築したことで、大量の復元を安全な実行が可能になった。
- すべての復元手順が完了した後にサイトが正常に機能していることを検証する自動化を構築した。
加速された復元 2 のアプローチは約 12 時間をかけてサイトを復元し、4 月 14 日から 17 日の間に 771 サイトが復旧されました。これは影響を受けたユーザーの約 47% にあたります。
削除されたサイトの復元後のデータ損失を最小限に抑える
当社のデータベースは、完全バックアップと増分バックアップを組み合わせてバックアップされています。これにより、特定の「時点」を選択して、バックアップ保持期間 (30 日) 以内にデータ ストアを復元できます。今回のインシデントでは、当社製品の主要なデータ ストアを特定し、大半のお客様に対して、サイトを削除する 5 分前の復元ポイントを安全な同期ポイントとして使用しました。非一次データ ストアは、同じポイントに復元されるか、記録されたイベントを再生することによって復元されました。一次データ ストアには固定復元ポイントを使用することで、すべてのデータ ストアにわたってデータの一貫性を保つことができました。
インシデント対応の早い段階で復元された 57 社のお客様に対しては、一貫したポリシーがなく、データベース バックアップ スナップショットを手動で取得していたため、一部の Confluence および Insight データベースがサイト削除の 5 分以上前の時点に復元されていました。この不整合は、復元後の監査プロセス時に発見されました。その後、残りのデータを復旧し、影響を受けたお客様に連絡して、さらにデータを復元するために変更を適用できるよう対応しています。
以下、要約です:
- 今回のインシデントでは、1 時間の目標復旧時点 (RPO) は達成された。
- 今回のインシデントでは、サイト削除より 5 分前を超えたデータ損失は確認されていない。
- 一部のお客様において、Confluence または Insight データベースがサイト削除の 5 分以上前の時点に復元されたものの、データは復旧可能で、現在お客様とデータ復元の作業を実施中。
インシデント コミュニケーション
このインシデント コミュニケーションの章では、お客様、パートナー、メディア、業界アナリスト、投資家、そしてより広範な技術コミュニティとのタッチポイントについて網羅します。
発生事象

【タイムスタンプ: 1 – 3 日目 (4 月 5 日 – 7 日)】
初動
最初のサポート チケットが 4 月 5 日 7:46 UTC に起票され、アトラシアン サポートは 8:31 UTC までにインシデントを確認したことを返答しました。9:03 UTC に最初の Statuspage の更新が投稿され、インシデントについて調査している旨をお客様に通知しました。11:13 UTC に、根本原因を特定し、修正に取り組んでいる旨を Statuspage を通してお知らせしました。4 月 6 日の 1:00 UTC までに、最初のお客様のチケットで、サイトの停止はメンテナンス スクリプトが原因であり、データ損失は最小限であることが予想される旨をお客様にお伝えしました。メディアからの問い合わせに対し、4 月 6 日 17:30 UTC に声明を出して回答しました。また 4 月 7 日 0:56 UTC には、より広範なお知らせとして、インシデントを確認したという最初のメッセージをツイート (アトラシアン本社のアカウント) しました。
【タイムスタンプ: 4 – 7 日目 (4 月 8 日 – 11 日)】
より広範な個別のお客様への連絡を開始
4 月 8 日 1:50 UTC に、影響を受けたお客様に向けて、共同創業者兼共同最高経営責任者である Scott Farquhar から謝罪のメールを送信しました。その後数日間で、削除された連絡先情報を復元し、影響を受けたサイトのうち、サポート チケットが起票されていないお客様のサポート チケットを作成しました。そして、影響を受けたサイトのサポート チケットを介して、復元作業に関する更新情報をサポート チームより定期的にご連絡しました。
【タイムスタンプ: 8 – 14 日目 (4 月 12 日 – 18 日)】
明確な状況把握と復元の完了
4 月 12 日 UTCに、CTO である Sri Viswanath からのアップデートを公開し、発生内容や影響を受けたお客様について、またデータ消失の有無、復旧の進捗状況などの技術的な詳細情報や、すべてのサイトを完全に復元するまでに最長 2 週間を要する可能性があることを説明しました。このブログは同時に、Sri による報道向けの声明としても発表されました。また、エンジニアリング責任者である Stephen Deasy によるアトラシアン コミュニティへの最初の投稿でも Sri のブログが参照されています。その後、このコミュニティの投稿は更新情報の追加と、公の Q&A の場所となりました。4 月 18 日の更新では、影響を受けたすべてのお客様のサイトが完全に復元されたことを発表しました。
なぜ早い段階で発表を行わなかったのか
- 影響を受けたお客様と直接、Statuspage、メール、サポート チケット、1 対 1 のやり取りによってコミュニケーションを取ることを優先したものの、サイトが削除され、お客様の連絡先情報も失われたため、多くのお客様に連絡を取ることができませんでした。影響を受けたお客様やエンド ユーザーに、インシデントへの対応状況と解決のタイムラインについてお知らせするために、より早い段階で広範なコミュニケーションを実施するべきでした。
- すぐにインシデントの原因を把握できたものの、アーキテクチャの複雑さと固有の状況のために、解決までの対応範囲と時間の見積もりに時間がかかりました。全体像を把握するまで待つのではなく、当社が確認済みの内容と未確認の内容について明確にすべきでした。全体的な復元の見積もり (方向性だけであっても) を提供し、より完全な全体像がいつ得られるかを明確にすることで、お客様(特に、組織内の関係者やユーザーを管理する最前線にいる、システム管理者や技術担当者)はインシデントに関して、より適切に計画できたはずです。
サポート体験とお客様への連絡
前述の通り、お客様サイトを削除したスクリプトは、本番環境から顧客 ID と連絡先情報 (例: Cloud URL、サイトのシステム管理者の連絡先) も削除しました。当社の基幹システム (例: サポート、ライセンス管理、請求) はすべて、セキュリティ、ルーティング、優先順位付けの目的で、主要な識別子として Cloud URL とサイトのシステム管理者の連絡先を活用しているため、これは非常に問題となりました。これらの識別子を紛失したことで、インシデント発生時にお客様を体系的に特定して連絡を行うことができませんでした。
影響を受けたお客様へのサポート
まず、影響を受けたお客様の多くは、オンラインのコンタクトフォームから通常の手順でサポート チームへの問い合わせを行えませんでした。このフォームでは、ユーザーが Atlassian ID によるログインと有効な Cloud URL を入力するよう設計されています。有効な URL がなければ、ユーザーは技術サポートのチケットを起票できません。通常の業務では、この検証はサイトのセキュリティとチケットのトリアージのために必要になるものの、今回のインシデントではこの要件のために、影響を受けたお客様による優先度の高いサイトのサポート チケットの起票がブロックされるという、意図しない結果が生じることとなりました。
次に、インシデントによってサイトのシステム管理者のデータが削除されたことで、影響を受けたお客様に当社から先に連絡を行うことができませんでした。インシデント発生から最初の数日間、アトラシアンに登録されている、影響を受けたお客様の請求担当者と技術担当者にメッセージを送信したものの、担当者情報の内、多くが古いものであることがわかりました。各サイトのシステム管理者の情報なしには、有効かつ承認済みの連絡先の確実なリストを用意できず、当社から連絡を行えませんでした。
当社の対応
インシデント発生から最初の数日間で、サイトの復旧を急ぎ、コミュニケーション チャンネルの障害を修復するために、サポート チームにはいずれも等しく重要な 3 つの優先事項がありました。
まず、有効なお客様連絡先の確実なリストを取得すること。当社のエンジニアリング チームがお客様サイトの復元に取り組むにあたり、お客様対応チームは有効な連絡先情報の復元を重視しました。連絡先リストを再構築するために、当社が利用可能なあらゆるメカニズム (請求システム、以前のサポート チケット、その他の安全なユーザー バックアップ、お客様への直接連絡など) を活用しました。影響を受けたサイトごとにインシデントに関するサポート チケットを起票し、直接の連絡と応答時間を効率化することを目標としました。
次に、今回のインシデントに固有のワークフロー、キュー、SLA を再確立すること。Cloud ID の削除によりユーザーを適切に認証できなかったことで、通常のシステムでインシデントに関するサポート チケットを処理できず、当社のインシデント対応能力に影響を与えました。チケットは状況を反映した優先度になっておらず、エスカレーション キューやダッシュボードにも正しく表示されませんでした。そこで早急に部門横断型のチーム (サポート、製品、IT) を作成し、追加のロジック、SLA、ワークフローの階層、ダッシュボードを設計し、変更を加えました。これを本番システム内で行う必要があったため、十分な開発、テスト、デプロイをするのに数日を要しました。
第 3 に、サイトの復元を加速するために手動の検証を大規模に拡張すること。エンジニアリングが初期復元から進むにつれて、手動のテストと検証チェックを通じてサイトの復旧を迅速化するには、グローバルなサポート チームのキャパシティが必要であることが明らかになりました。エンジニアリング チームがデータの復元を加速するにつれ、この検証プロセスは、復元したサイトをお客様に提供するための重要な行程になります。標準業務手順 (SOP)、ワークフロー、ハンドオフ、人員配置の独立したストリームを立ち上げ、450 人を超えるサポート エンジニアを動員し、24 時間体制のシフトを組んで検証チェックを実行し、お客様への復元を迅速化しました。
第一週の終わりまでにこれらの主要な優先事項を十分に確立しても、復元プロセスが複雑なためにインシデント解決のタイムラインが明確でなかったことにより、意味のある情報更新を行うには限界がありました。サイトの復元予定日の提示が難しいことをより早い段階で認識し、直接対話する場を設けることで、お客様が状況に応じて計画を立てられるようにすべきでした。
再発防止への取り組み
適切な変更が加えられるまで、当社ではサイトの一括削除を直ちに停止しました。
今回のインシデントから前進し、社内プロセスを再評価するにあたり、インシデントを引き起こすのは人ではないという考えを、改めて認識しています。むしろ、システムが間違いの発生を許容しているのです。この章では、今回のインシデントに至った要因について総括し、これらの弱点や問題の修正への取り組みを促進する計画についても触れます。
教訓 1: 「論理削除」をすべてのシステムにおいて共通にする
概して、今回のような種類の削除は、エラーを避けるために禁止するか、複数の層で保護することが必要です。現在行なっている主な改善では、論理削除のプロセスを経ていないお客様のデータおよびメタデータの削除をグローバルで阻止します。
a) データの削除は、論理削除としてのみ行う
サイト全体の削除は禁止し、論理的な削除はエラーを防ぐために複数のレベルでの保護を必要とします。「論理削除」のポリシーを実装し、外部スクリプトやシステムにより本番環境でのお客様データの削除を防止します。当社の「論理削除」ポリシーでは十分なデータ保持が可能になるため、データ復旧が迅速かつ安全に実行されます。保持期間の終了後にのみ、データは本番環境から削除されます。
アクション
✅ プロビジョニングのワークフローと関連するすべてのデータ ストアに「論理削除」を実装します: さらに、テナント プラットフォーム チームが、データの削除が非アクティブ化後にのみ実行可能であること、加えてスペース内のその他の保護対策を検証します。長期的には、テナント プラットフォーム チームが、テナント データの適切な状態管理をより進展させるための主導的な役割を担います。
b) 論理削除には、標準化および検証されたレビュー プロセスを必要とする
論理削除の実施はリスクの高い操作です。そのため、これらの操作に対処するために、定義されたロールバックとテスト手順を含む、標準化または自動化されたレビュープロセスを必要とします。
アクション
✅ 論理削除の実施は段階的なロールアウトを通して施行します: 削除を必要とするすべての新しい操作は、最初に自社サイト内でテストし、アプローチの有効性と自動化の検証を行います。検証の完了後、同じプロセスによってお客様を段階的に移行し、選択されたユーザー ベース全体に自動化を適用する前に、異常がないか引き続きテストを行います。
✅ 論理削除の実施には、テスト済みのロールバック計画を必要とします: データの論理削除の実施には、本番環境での実行前に、削除されたデータの復元をテストし、テスト済みのロールバック計画を必要とします。
教訓 2: DR プログラムの一環として、より多くのお客様を対象に複数サイト・複数製品の削除イベントの復元を自動化する
アトラシアンのデータ管理では、当社のデータ管理プロセスが網羅されています。高可用性の提供のために、同期型のスタンバイ レプリカを複数の AWS アベイラビリティ ゾーン (AZ) にプロビジョニングし保持しています。AZ のフェイルオーバーは自動化されており、通常は 60 〜 120 秒かかります。データ センターの停止やその他の一般的な中断は、お客様に影響を与えることなく定期的に処理しています。
また、当社では、データ破損イベントに対しても回復するよう設計された不変のバックアップも維持しており、過去の時点にデータを復旧できます。バックアップは 30 日間保持され、復元のためにストレージ バックアップの継続的なテストと監査を行ないます。必要に応じて、すべてのお客様を新しい環境に復元することができます。
これらのバックアップを使用して、個別のお客様や誤ってデータを削除された一部のお客様を定期的にロールバックしています。しかし、サイトレベルの削除において、今回のイベントの規模に合わせて迅速に自動化できるランブックが用意されておらず、状況に合わせて、すべての製品とサービス全体に対応できるツールの準備と自動化を行う必要がありました。
他のお客様に影響を与えることなく、多数のお客様をまとめて既存の (および現在使用中の) 環境に復元するための自動化は、(まだ) 実現されていません。
クラウド環境内では、各データストアに複数のお客様からのデータが保存されています。今回のインシデントで削除されたデータは、他のお客様が継続して利用しているデータストアの一部であるため、バックアップから個別の該当箇所を手動で抽出して復元する必要がありました。各お客様サイトの復旧は、時間を要する複雑なプロセスであり、サイトの復旧時には内部検証とお客様による最終検証が必要です。
アクション
✅ 多くのお客様を対象にした複数製品・複数サイトの復元の取り組みを加速します: DR プログラムは、現行の RPO の基準となっている 1 時間を満たしています。当社は自動化や今回のインシデントからの教訓を元に、DR プログラムへの取り組みを前倒しして、当社のポリシーで定義されているように、今回の規模のインシデントに対する RTO を達成します。
✅ 今回のケースの検証を自動化して DR テストに追加します: 多数のサイト向けにすべての製品の復元を含む DR の演習を定期的に実施します。これらの DR テストでは、アーキテクチャが進化し、新たなエッジケースへの直面することを想定しながら、ランブックが最新であることを確認します。復元アプローチを継続的に改善し、より多くの復元プロセスを自動化して、復旧時間を短縮します。
教訓 3: 大規模なイベントのインシデント管理プロセスを改善する
当社のインシデント管理プログラムは、長年にわたって発生した重大なインシデントおよび小規模なインシデントの管理に適しています。小規模で期間が短いインシデントへの対応を頻繁にシミュレーションしており、これには通常、少数のメンバーとチームが関与します。
しかし、今回のインシデントのピーク時には、数百人ものエンジニアとカスタマー サポートの従業員がお客様サイトの復旧に同時に取り組みました。当社のインシデント管理プログラムとチームは、今回のように複雑で拡大性があり長期間のインシデントに対処するようには設計されていませんでした (下の図10を参照)。

大規模なインシデント管理プロセスをより明確に定義し、頻繁に実践します
製品レベルのインシデントに関するプレイブックはありますが、会社全体で数百人もの従業員が同時に作業する、今回の規模のイベントには対応していません。インシデント管理ツールには、Slack、Zoom、Confluence のドキュメントなど、コミュニケーション ストリームを作成する自動化機能はありますが、大規模なインシデントが発生した場合に必要とされる復元ストリームを分離するためのサブストリームを作成する機能がありません。
アクション
✅ 大規模なインシデントのプレイブックおよびツールの定義と、シミュレーションに基づいた演習を実施します: 大規模で今回のレベルの対応が必要とされるインシデントの種類を定義して文書化します。主要な調整手順を概説し、ツールを構築して、インシデントマネージャーや他のビジネス機能が対応を効率化し、復旧を開始できるようにします。インシデントマネージャーとチームは、シミュレーション、トレーニング、ツールとドキュメントの改良を定期的に行い、継続的に改善します。
教訓 4: コミュニケーション プロセスを改善する
a) 重要な顧客 ID を削除し、影響を受けたお客様へのコミュニケーションとアクションに影響があった
お客様サイトを削除した同じスクリプトは、本番環境から主要な顧客 ID (例: サイト URL、サイトのシステム管理者の連絡先) も削除しました。その結果、(1) お客様が通常のサポート チャネルを介した技術サポートのチケットを起票できませんでした。(2) 停止により影響を受けたお客様の主要な連絡先 (サイトのシステム管理者など) の有効なリストを取得してこちらから連絡を取るのに数日を要しました。(3) サポート ワークフロー、SLA、ダッシュボード、エスカレーション プロセスは、今回のインシデント特有の状況により、当初は適切に機能しませんでした。
サービス停止時には、お客様のエスカレーションも複数のコミュニケーション チャンネル (メール、電話、CEO チケット、LinkedIn やその他のソーシャル チャンネル、サポート チケット) を介して行われました。お客様対応チーム全体でツールとプロセスが異なるため、対応が遅くなり、これらのエスカレーションの全体的な追跡とレポートがより困難になりました。
b) 今回のレベルの複雑さに十分に対処するインシデント コミュニケーション プレイブックがなかった
部門横断型のインシデントコミュニケーションチームを迅速に動員するにあたり、その原則や、役割と責任がまとめられたインシデントコミュニケーションプレイブックが用意されていませんでした。また、当社がインシデントの発生を確認した旨を、複数のチャンネル、特にソーシャルメディアを通じて迅速に一貫して提供しませんでした。今回のインシデントではデータ損失はなく、サイバー攻撃の結果ではないという重要なメッセージを繰り返すとともに、サービスの停止に関する、より広範なパブリックコミュニケーションが適切なアプローチだったと認識しています。
アクション
✅ 主要連絡先のバックアップの改善: 承認済みのアカウントの連絡先情報を製品インスタンスの外部にバックアップします。
✅ サポート ツールの改善: 有効なサイト URL または Atlassian ID をお持ちでないお客様が、当社の技術サポート チームに直接連絡できるメカニズムを構築します。
✅ お客様のエスカレーション システムとプロセス: 統合されたアカウント ベースのエスカレーション システムとワークフローに投資し、複数の作業オブジェクト (チケットやタスクなど) を単一のお客様アカウントのオブジェクトの配下に保存できるようにすることで、すべてのお客様対応チームにおける調整や可視性を向上させます。
✅ 年中無休のエスカレーション管理の迅速化: エスカレーション管理機能のグローバル規模での拠点拡張計画を実行し、主要な地域ごとに指定されたスタッフが一貫して年中無休で対応できるようにします。また、必要な製品および営業エリアのエキスパートやリーダーシップによる支援も行います。
✅ 新たな教訓を元にインシデントコミュニケーションプレイブックを更新し、定期的に再検討します: プレイブックを再検討して、社内の明確な役割とコミュニケーションの方針を定義します。インシデントの際は DACI フレームワークを使用し、疾病、休暇、または他の不測の事態に備えて、役割ごとに年中無休のバックアップを用意します。四半期ごとの監査を実施し、常に準備状況を検証します。すべてのコミュニケーションにおいてインシデント コミュニケーション テンプレートに従います。発生事象、影響を受けたお客様、復元までのタイムライン、サイト復元率、予想されるデータ損失、関連する信頼レベル、およびサポートへの連絡方法に関する明確なガイダンスにも取り組みます。
終わりに
サービス停止は解消し、お客様サイトの復旧は完了しましたが、当社の作業は続いています。現段階では、上述した変更を実施しており、プロセスを改善し、レジリエンスを向上させ、同様の状況が再発しないよう努めてまいります。
アトラシアンは学習する組織であり、当社のチームは今回の件で多くの厳しい教訓を得ました。これらの教訓を元に、ビジネスを永続的に変革すべく取り組みを進め、より強力な組織となり、より優れたサービスを提供いたします。
今回のインシデントからの教訓が、安定したサービスを提供すべく業務に取り組む他のチームにもお役立ていただければ幸いです。
最後に、本ドキュメントをご覧いただきました皆さま、また広範なアトラシアン コミュニティとチームの一員である皆さまに感謝申し上げます。