Incident management for high-velocity teams
Incident communication best practices
Incidents have always been a fact of life for people in IT and Ops. Today, it’s also DevOps and customer support teams getting a crash course in incident communication.
Incident communication is the process of alerting users that a service is experiencing some type of outage or degraded performance. This is especially important for web and software services, where 24/7 availability is expected.
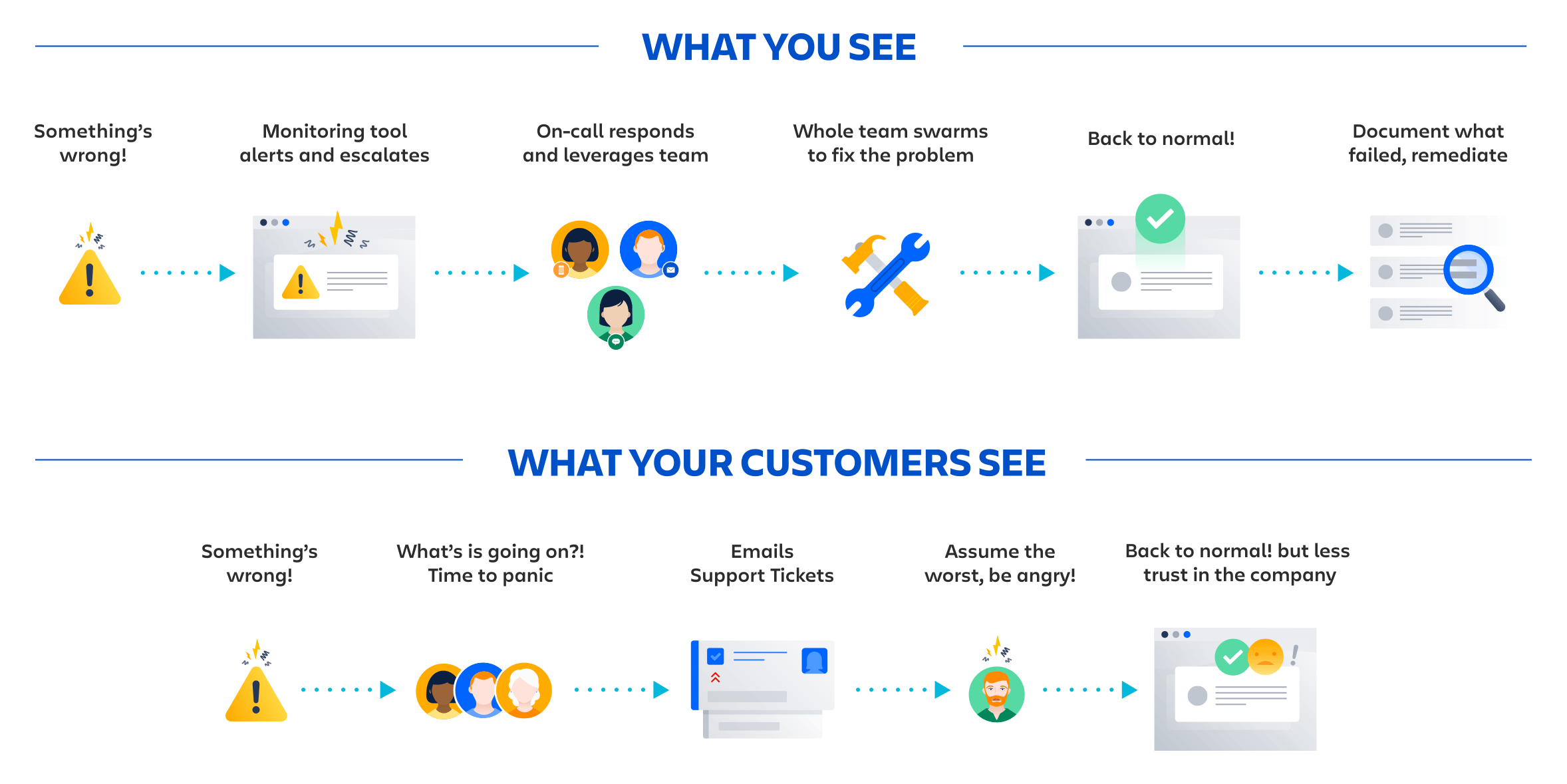
Web scale incident communication is more complex than simply sending a bulk email. There are different audiences to consider. Different thresholds for messaging and response expectations.
Since some downtime is inevitable, it’s best to plan ahead and make sure your team is ready.
This is our guide to incident communication best practices. We’ll cover:
- Why incident communication is important
- How to prep for incident communication
- How incident communication pros handle the task
- Why incident communication doesn’t end after the incident
Incident communication: Who cares?
Your customers care. Your colleagues care. You should care. Poorly handled downtime can be a really bad experience for your customers and your teams, which can affect your bottom line. Some of your customers may worry you have more bad experiences up your sleeves and switch to a competitor. You’ll lose future customers due to lack of trust. Team morale can suffer and lead to lower productivity. And say goodbye to all those juicy word-of-mouth referrals.
Luckily, unplanned downtime doesn’t have to turn into a customer service nightmare. It turns out that if you just keep your customers in the loop by communicating what’s happening and what you’re doing to fix the problem, they’ll understand and have a much less negative reaction to the whole situation.
Prepping for incident communication
Proper preparation prevents poor performance. If it’s a good enough slogan for going into battle, it’s good enough for your incident communication strategy. When you’re in the heat of an incident, you’ll thank yourself that you put time into incident communication.
Define what you consider an incident
Before we can communicate incidents, we need to decide what constitutes an incident. Many web companies rely on a standardized 4-tier severity definition system. Here’s a great guide on severity definitions from our own incident handbook.
Whatever your thresholds are for incident severity, it’s important to make a clear line in the sand (ideally around some sort of measurable metric). If you designate an incident at Sev 1, it’s important for anyone on your team to be able to know exactly what that means.
A severity system is also helpful to eliminate the inherent shades of grey that come with downtime.
No matter what system you settle on, we recommend a zero-tolerance communication plan for any incidents involving security issues or data loss.
Pick your communication solutions, channels, and message templates ahead of time
Professional support teams and site reliability engineers don’t decide on the fly what channels to communicate over. They make a plan ahead of time.
There are five main communication channels for incident communication:
- A dedicated status page
- Embedded status
- Workplace chat tool
- Social media
- SMS
Dedicated status page
We recommend teams use a dedicated status page as their primary incident communication solution. Whether you build it yourself or go with a hosted solution like Statuspage, it’s important to give your customers and colleagues a clear source of truth during an incident. Statuspage also gives your users an option to subscribe to get updates the moment they’re posted. This takes the support burden off teams who should be heads-down fixing the problem.
Embedded status
Statuspage also make it easy to embed status information directly onto any website customers operate. We know most visitors are likely to check a provider’s home page or support page before looking for a status page. The embedded widget (here's an example) is an easy way of letting those visitors know if an incident is underway. Visitors can also click through on the widget to get to the status page.
You can give your audience the option to subscribe to email updates with a product like Statuspage at your disposal. Whether you’re sending directly from your email tool, or using a status page to trigger email sends, email a reliable channel for incident communication.
Chat tools
Reduce context switching and information gaps for employees and agents with Jira Service Management chat. Jira Service Management chat will sync conversations in Slack or Microsoft Teams and your tickets. Seamless conversation between popular chat tools and support helps to provide robust context to a problem, leading to a fast resolution.
Social media
Many teams use social channels like Twitter as a means of communication during an incident. It’s good to use this as a piece of your strategy, but not rely on it as your only means of communication.
SMS
Receiving an SMS message, or text message, is often a more immediate way to reach someone, and a preference for many people when it comes to critical inbound alerts like a downtime announcement. It’s also a channel where people can be message fatigued very fast and will unsubscribe if they see too many messages that aren’t relevant to them.
None of these channels are a silver bullet for incident comms. They all have different strengths and the real power comes when you layer them together. For example, at Atlassian, we post incidents to a status page but also push those updates to Twitter. An announcement about the incident is also visible on our Jira Service Management portal. These messages then direct the user back to the status page for more details on the incident. Managing incidents in Jira Service Management allows for multiple points of communication without getting wires crossed or losing your customers' trust in translation.
Tailor alerts and communications to the right audience
When an incident arises, you need to know who to communicate to, how to reach them, and how to do it with the least friction and fewest resources possible in order to avoid a customer service nightmare and/or communication meltdown. It’s best to start internally with an immediate response team and work outward, curating messages for the appropriate audience.
While every organization is different, in general it helps to think of these audiences as 5 distinct groups that need to be communicated with:
- Core on-call team: The first to know something is wrong, almost immediately upon impact (usually from monitoring and alerting tools). Internal teams work behind the scenes to detect, swarm, contextualize, and resolve incidents with collaborative communication tools.
- Front-line support team: Those who will be directly answering questions and giving customers updates during the incident. It’s an incredibly important role, so this team must get the right information to pass along to end users.
- Managers and executive team: The core team needs to communicate with this group so they know what’s going on, the potential impact on the following two groups, and hopefully an estimate of how long it could last.
- General employee population: Employees need to be kept informed as services they rely on go down and up. Proactively communicating with these users means less “what’s the status of this” questions, fewer duplicate IT support tickets, and more focus to fix the problem at hand.
- External customers: If the incident affects external customers some communication must be sent out to explain the problem and when they can expect a fix – or at least an update every nth amount of time. For issues that are still currently affecting your customers’ ability to use your product, we recommend never going more than one hour without sending an update. You should also always indicate when to expect the next update. If it is a severe enough incident – especially one involving security or data loss – you will definitely want to expedite external comms and pull in the necessary other teams (legal, HR, security, etc.)
Set up templates for incident and outage communication
In the heat of an incident, the last thing you want to worry about is how to wordsmith an incident announcement. Wording the incident the wrong way is a perfect target for non-technical managers who might be looking for any reason to criticize your team’s response process.
Decide on the common language ahead of time, get it approved by your managers, and save it in a template. This makes it easy to plug in the relevant details and fire off an incident the day of.
Here are two of the incident templates we use for our own status page:
- The site is currently experiencing a higher than normal amount of load, and may be causing pages to be slow or unresponsive. We’re investigating the cause and will provide an update as soon as possible.
- Our storage provider for public metrics data is currently experiencing infrastructure issues. Updates will be made available as the situation develops or information is provided to us.
Managing communication like a pro
The lifecycle of an incident will likely include several points of contact. Done well, there’s a familiar three-act structure to an incident: First contact, updates during the incident, resolution and post-mortem.
Prologue: Centralized internal team communication
Before anything else, internal teams on the back end of an incident should have an established communication platform and be ready to swarm when an issue arises.
Centralizing and filtering alerts across monitoring, logging, and CI/CD tools ensures a fast response from your team. With a platform like Jira Service Management, teams can quickly swarm an incident, gain context, and stay in touch throughout the duration of an incident.
Part 1: First contact
The initial update is the most important. Everything from what you say, to how and when you say it sets the tone for how your response will be perceived. This is where it really helps to have a template set up ahead of time.
Your goal should be to quickly acknowledge the issue, briefly summarize the known impact, promise further updates and, if you’re able, alleviate any concerns about security or data loss. It's important to acknowledge there's an issue, even if you don't know the exact details yet.
Part 2: Regular updates during the incident
Mid-incident communication is critical.
The SRE teams at Google list Communication Lead as one of the key roles someone should oversee during an incident.
From Google’s book “Site Reliability Engineering” on the role of communication lead:
This person is the public face of the incident response task force. Their duties most definitely include issuing periodic updates to the incident response team and stakeholders (usually via email), and may extend to tasks such as keeping the incident document accurate and up to date.”
This person will also be in charge of continuing to update the status page or post updates to other channels as the situation evolves. Even an update saying “We’re still working on the problem, nothing new to report,” is better than saying nothing and leaving your audiences hanging. People left in the dark start to expect the worst.
Communication with affected users and other stakeholders is imperative. Use your pre-determined channel(s) to tell users what’s going on. On a homepage, this may be a Statuspage alert to help customers see that your team is aware of the problem and saves agents time from dealing with redundancy. Keep customers in the loop using multiple notification channels, including SMS, email, and mobile push.
Whatever tool you choose to use, we recommend that you identify one as your primary communication vehicle and funnel everyone there from the other channels. Managing incident communications through Jira Service Management ensures the right messages get to the right people.
Part 3: Resolution, post-mortem, what comes next
In 2010, Facebook suffered its largest outage to date. For about 2.5 hours, the social network was unavailable for millions of its then-half-a-billion users.
The timing couldn’t have been worse for the burgeoning tech giant, which was still in the early days of its explosive user growth and still proving to the business world that the service was worth the hype.
When the dust settled, a Facebook engineer posted a 395-word summary to the company’s engineering blog about the incident.
From the blog:
Early today Facebook was down or unreachable for many of you for approximately 2.5 hours. This is the worst outage we’ve had in over four years, and we wanted to first of all apologize for it. We also wanted to provide much more technical detail on what happened and share one big lesson learned.
The outline of the post-mortem is simple:
- Acknowledge the problem, empathize with those affected and apologize
- Explain what went wrong and why
- Explain what was done to fix the incident and what was done to prevent repeat incidents
- Acknowledge, empathize, and apologize once again
There’s no need for flowery language or grandiose claims in communication like this. Keep it simple and direct. For example, from the Facebook blog:
We apologize again for the site outage, and we want you to know that we take the performance and reliability of Facebook very seriously.
Language like this makes it easy for your customers and colleagues to trust that you’re running a level-headed team and keeping your eye on the ball. Browse our own incident response postmortem template for more ideas.
The reality of running always-on services is that sometimes, things unexpectedly break. Effectively communicating during downtime can actually build trust with both colleagues and customers. Responding well can make all the difference. We've also created this simple tool to help you to quickly write effective communications during incidents.
Products Discussed

Easily communicate real-time status to your users.
Learn incident communication with Statuspage
In this tutorial, we’ll show you how to use incident templates to communicate effectively during outages. Adaptable to many types of service interruption.
Read this tutorialIncident communication templates and examples
When responding to an incident, communication templates are invaluable. Get the templates our teams use, plus more examples for common incidents.
Read this article