Monorepository in Git
Cos'è un monorepository?
Le definizioni variano, ma i monorepository vengono definiti come segue:
- Il repository contiene più di un progetto logico (ad esempio un client iOS e un'applicazione Web)
- Questi progetti sono verosimilmente non correlati, debolmente collegati o possono essere collegati tramite altri mezzi (ad esempio tramite gli strumenti di gestione delle dipendenze)
- Il repository è di grandi dimensioni sotto molti punti di vista:
- Numero di commit
- Numero di branch e/o tag
- Numero di file monitorati
- Dimensioni dei contenuti monitorati (calcolate esaminando la directory .git del repository)
Facebook possiede uno di questi esempi di monorepository:
Con migliaia di commit a settimana su centinaia di migliaia di file, il repository sorgente principale di Facebook ha dimensioni enormi ed è molto più grande persino del kernel Linux, che nel 2013 ha registrato 17 milioni di righe di codice e 44.000 file.
materiale correlato
Come spostare un repository Git completo
Scopri la soluzione
Impara a utilizzare Git con Bitbucket Cloud
E durante i test delle prestazioni, i repository di test utilizzati da Facebook avevano la configurazione seguente:
- 4 milioni di commit
- Cronologia lineare
- Circa 1,3 milioni di file
- Dimensione della directory .git di circa 15 GB
- Dimensione del file di indice di 191 MB
Sfide concettuali
La gestione di progetti non correlati in un monorepository in Git presenta molte sfide concettuali.
Innanzitutto, Git tiene traccia dello stato dell'intero albero in ogni singolo commit effettuato. Questo va bene per progetti singoli o correlati, ma diventa difficoltoso nel caso di un repository contenente molti progetti non correlati. In poche parole, i commit in parti non correlate dell'albero influiscono sul sottoalbero rilevante per uno sviluppatore. Questo problema è accentuato su larga scala con un numero elevato di commit che fanno avanzare la cronologia dell'albero. Poiché la punta del branch cambia continuamente, per eseguire il push delle modifiche occorre effettuare merge o riassegnazioni frequenti a livello locale.
In Git, un tag è un alias denominato per un determinato commit, che fa riferimento all'intero albero. Ma l'utilità dei tag diminuisce nel contesto dei monorepository. Poniti questa domanda: se stai lavorando su un'applicazione Web che viene distribuita continuamente in un monorepository, che rilevanza ha il tag del rilascio per il client iOS con versione?
Problemi relativi alle prestazioni
Oltre a queste sfide concettuali, ci sono numerosi problemi di prestazioni che possono influire su una configurazione con monorepository.
Numero di commit
La gestione di progetti non correlati in un unico repository su larga scala può rivelarsi problematica a livello di commit. Nel tempo, ciò può portare a un elevato numero di commit con un tasso di crescita significativo (Facebook menziona "migliaia di commit a settimana"). Ciò diventa particolarmente problematico poiché Git utilizza un grafo aciclico diretto (Directed Acyclic Graph, DAG) per rappresentare la cronologia di un progetto. Con un numero elevato di commit, le prestazioni di qualsiasi comando che metta in pratica il grafo potrebbero rallentare man mano che la cronologia diventa più profonda.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Numero di riferimenti
Un numero elevato di riferimenti (ad esempio branch o tag) nel monorepository influisce sulle prestazioni in molti modi.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
Tempo utente (secondi): 146,44*
*Questo valore varia a seconda delle cache delle pagine e del livello di archiviazione sottostante.
Numero di file monitorati
L'indice o la cache della directory (.git/index) tiene traccia di tutti i file nel repository. Git usa questo indice per determinare se un file è stato modificato eseguendo stat(1) su ogni singolo file e confrontando le informazioni sulle modifiche del file con le informazioni contenute nell'indice.
Pertanto, il numero di file monitorati influisce sulle prestazioni* di molte operazioni:
- Le prestazioni di
git statuspotrebbero essere lente (vengono create statistiche per ogni singolo file, le dimensioni del file dell'indice saranno elevate) - Anche le prestazioni di
git commitpotrebbero essere lente (anche qui vengono create delle statistiche per ogni singolo file)
*Ciò varia a seconda delle cache delle pagine e del livello di archiviazione sottostante ed è visibile solo quando c'è un numero elevato di file, nell'ordine di decine o centinaia di migliaia di file.
File di grandi dimensioni
I file di grandi dimensioni in un singolo sottoalbero/progetto influiscono sulle prestazioni dell'intero repository. Ad esempio, le risorse multimediali di grandi dimensioni aggiunte a un progetto del client iOS in un monorepository vengono clonate nonostante ci sia uno sviluppatore (o un agente di compilazione) che lavora a un progetto non correlato.
Effetti combinati
Che si tratti del numero di file, della frequenza con cui vengono modificati o delle loro dimensioni, questi problemi messi insieme hanno un impatto maggiore sulle prestazioni:
- Il passaggio da un branch o da un tag all'altro, particolarmente utile in un contesto di sottoalbero (ad esempio il sottoalbero su cui sto lavorando), aggiorna comunque l'intero albero. Questo processo può risultare lento a causa del numero di file interessati o può richiedere una soluzione alternativa. Se ad esempio viene utilizzato
git checkout ref-28642-31335 -- templates, verrà aggiornata la directory./templatesin modo che corrisponda al branch specificato, ma senza aggiornareHEAD; questo processo ha l'effetto collaterale di contrassegnare i file aggiornati come modificati nell'indice. - Le operazioni di clonazione e recupero rallentano il server e richiedono molte risorse, poiché tutte le informazioni sono condensate in un file di pacchetto prima del trasferimento.
- La garbage collection è lenta e per impostazione predefinita viene attivata su un'operazione di push (se la garbage collection è necessaria).
- L'utilizzo delle risorse è elevato per ogni operazione che comporta la (ri)creazione di un file di pacchetto, ad es.
git upload-pack, git gc.
Strategie di mitigazione
Anche se sarebbe fantastico se Git potesse supportare lo speciale caso d'uso che i repository monolitici tendono ad essere, gli obiettivi di progettazione di Git che lo hanno reso così popolare e di successo a volte entrano in contrasto con il desiderio di usare questo strumento in un modo diverso dal quale è stato progettato. La buona notizia per la stragrande maggioranza dei team è che i repository monolitici davvero grandi tendono ad essere l'eccezione piuttosto che la regola, quindi per quanto interessante spero sia questo post, molto probabilmente non si applica allo scenario che stai affrontando.
Detto questo, ci sono diverse strategie di mitigazione che possono tornare utili quando si lavora con repository di grandi dimensioni. Il mio collega Nicola Paolucci descrive alcune soluzioni alternative per i repository con cronologie estese o risorse binarie di grandi dimensioni.
Rimuovere i riferimenti
Se nel repository sono presenti decine di migliaia di riferimenti, dovresti prendere in considerazione la possibilità di rimuovere quelli che non sono più necessari. Il DAG conserva la cronologia dell'evoluzione delle modifiche, mentre i commit di merge puntano ai relativi elementi principali; in questo modo, il lavoro svolto nei branch può essere tracciato anche se il branch non esiste più.
In un flusso di lavoro basato su branch, il numero di branch di lunga durata da conservare deve essere ridotto. Non aver paura di eliminare un branch di funzioni di breve durata dopo un merge.
Prendi in considerazione la possibilità di rimuovere tutti i branch sottoposti a merge in un branch principale, come quello di produzione. Puoi comunque tenere traccia della cronologia dell'evoluzione delle modifiche, purché un commit sia raggiungibile dal branch principale e tu abbia eseguito il merge del branch con un commit di merge. Il messaggio di commit di merge predefinito spesso contiene il nome del branch, il che consente di conservare queste informazioni se necessario.
Gestione di un numero elevato di file
Se il repository contiene un numero elevato di file (da decine a centinaia di migliaia), può essere utile utilizzare un archivio locale veloce con abbondante memoria che può essere utilizzata come cache del buffer. Questa è un'area che richiederebbe modifiche più significative al client, simili ad esempio alle modifiche implementate da Facebook per Mercurial
L'azienda ha utilizzato le notifiche del file system per registrare le modifiche apportate ai file invece di creare iterazioni su tutti i file per verificare se fossero state apportate modifiche a qualcuno di questi. Un approccio simile (sempre con watchman) è stato discusso per git, ma non è stato ancora realizzato.
Usare Git LFS (Large File Storage)
Questa sezione è stata aggiornata il 20 gennaio 2016
Per i progetti che includono file di grandi dimensioni come video o grafica, Git LFS è un'opzione che consente di limitare il loro impatto sulle dimensioni e sulle prestazioni complessive del repository. Invece di archiviare gli oggetti di grandi dimensioni direttamente nel repository, Git LFS archivia un piccolo file segnaposto con lo stesso nome contenente un riferimento all'oggetto, che è a sua volta archiviato in uno speciale archivio di oggetti di grandi dimensioni. Git LFS crea un hook alle operazioni di push, pull, estrazione e recupero native di Git per gestire in modo trasparente il trasferimento e la sostituzione di questi oggetti nell'albero di lavoro. Ciò significa che puoi lavorare con file di grandi dimensioni nel repository come di consueto, senza però la penalizzazione rappresentata dalle dimensioni eccessive del repository.
Bitbucket Server 4.3 (e versioni successive) incorpora un'implementazione di Git LFS v1.0+ perfettamente compatibile e consente di visualizzare l'anteprima e le differenze delle risorse di immagini di grandi dimensioni monitorate da LFS direttamente nell'interfaccia utente di Bitbucket.
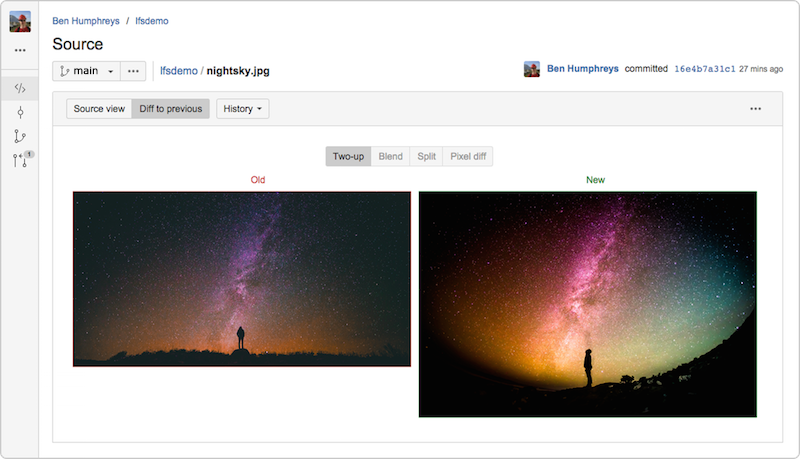
Il mio collega di Atlassian Steve Streeting è un collaboratore attivo del progetto LFS e di recente ha scritto dei contenuti a riguardo.
Identificare i confini e dividere il repository
La soluzione alternativa più radicale è suddividere il monorepository in repository git più piccoli e mirati. Prova ad abbandonare il monitoraggio di ogni modifica in un singolo repository e a identificare invece i confini tra i componenti, magari individuando moduli o componenti con un ciclo di rilascio simile. Un buon banco di prova per ottenere sottocomponenti trasparenti è l'uso dei tag nei repository e la verifica della loro pertinenza rispetto ad altre parti dell'albero di origine.
Anche se sarebbe fantastico se Git potesse supportare i monorepository in modo fluido, il concetto di monorepository è leggermente in contrasto con le caratteristiche che hanno reso Git così popolare e di successo. Tuttavia, ciò non vuol dire che si dovrebbe rinunciare alle funzionalità di Git sol perché si lavora con un monorepository: nella maggior parte dei casi, ci sono soluzioni attuabili per qualsiasi problema che possa presentarsi.
Condividi l'articolo
Argomento successivo
Letture consigliate
Aggiungi ai preferiti queste risorse per ricevere informazioni sui tipi di team DevOps e aggiornamenti continui su DevOps in Atlassian.

Blog di Bitbucket

Percorso di apprendimento DevOps
