Atlassian Cloud
Architecture Atlassian Cloud et pratiques opérationnelles
Découvrez-en plus sur l'architecture Atlassian Cloud et nos pratiques opérationnelles
Introduction
Les produits et données cloud d'Atlassian sont hébergés par Amazon Web Services (AWS), le fournisseur cloud leader du secteur. Nos produits fonctionnent sur un environnement PaaS (Platform as a Service) divisé en deux ensembles principaux d'infrastructures que nous appelons « Micros » et « non Micros ». Jira, Confluence, Jira Product Discovery, Statuspage, Guard et Bitbucket s'exécutent sur la plateforme Micros, tandis qu'Opsgenie et Trello s'exécutent sur la plateforme non Micros.
Architecture de services distribuée
Grâce à cette architecture AWS, nous hébergeons un certain nombre de services produit et de plateforme utilisés sur l'ensemble de nos solutions. Ces services incluent les fonctionnalités de la plateforme qui sont partagées et utilisées par plusieurs produits Atlassian (comme Media, Identity et Commerce), des expériences comme notre éditeur, ainsi que des fonctionnalités spécifiques des produits, notamment le service Jira Issue et Confluence Analytics.
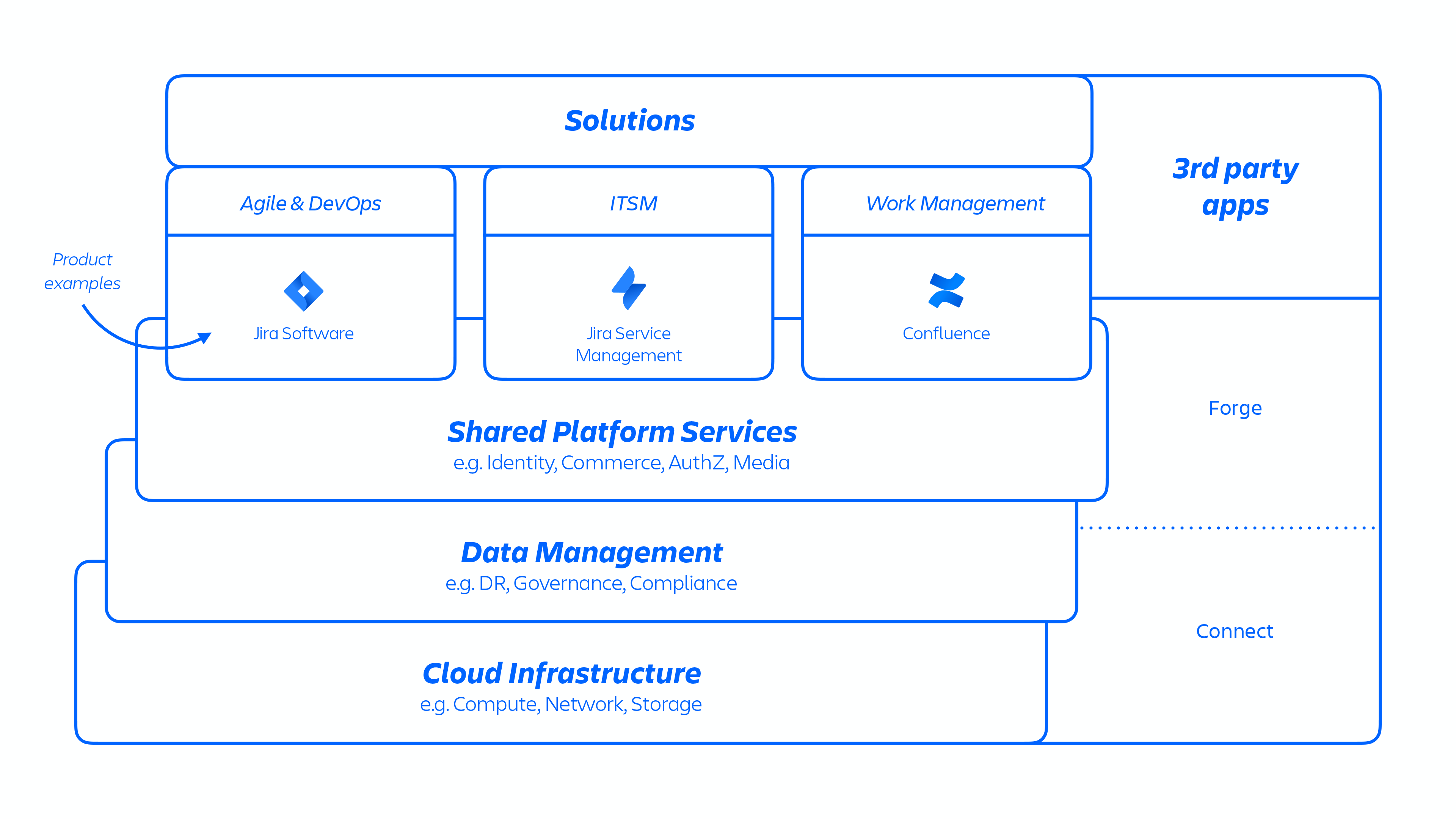
FIGURE 1
Les développeurs Atlassian fournissent ces services via Kubernetes ou une Platform as a Service (PaaS) développée en interne, appelée Micros, qui orchestrent tous deux automatiquement le déploiement des services partagés, de l'infrastructure, des magasins de données et de leurs fonctionnalités de gestion, y compris les exigences de contrôle de la sécurité et de la conformité (voir la figure 1 ci-dessus). En général, un produit Atlassian se compose de plusieurs services « conteneurisés » déployés sur AWS à l'aide de Micros ou de Kubernetes. Les produits Atlassian utilisent les fonctionnalités de base de la plateforme (voir la figure 2 ci-dessous) qui vont du routage des demandes aux magasins d'objets binaires, en passant par l'authentification/autorisation, le contenu généré par l'utilisateur (CGU) transactionnel et les magasins de relations entre entités, les data lakes (lacs de données), la journalisation commune, le suivi des demandes, l'observabilité et les services d'analyse. Ces microservices sont conçus à l'aide de stacks techniques approuvées et standardisées au niveau de la plateforme :
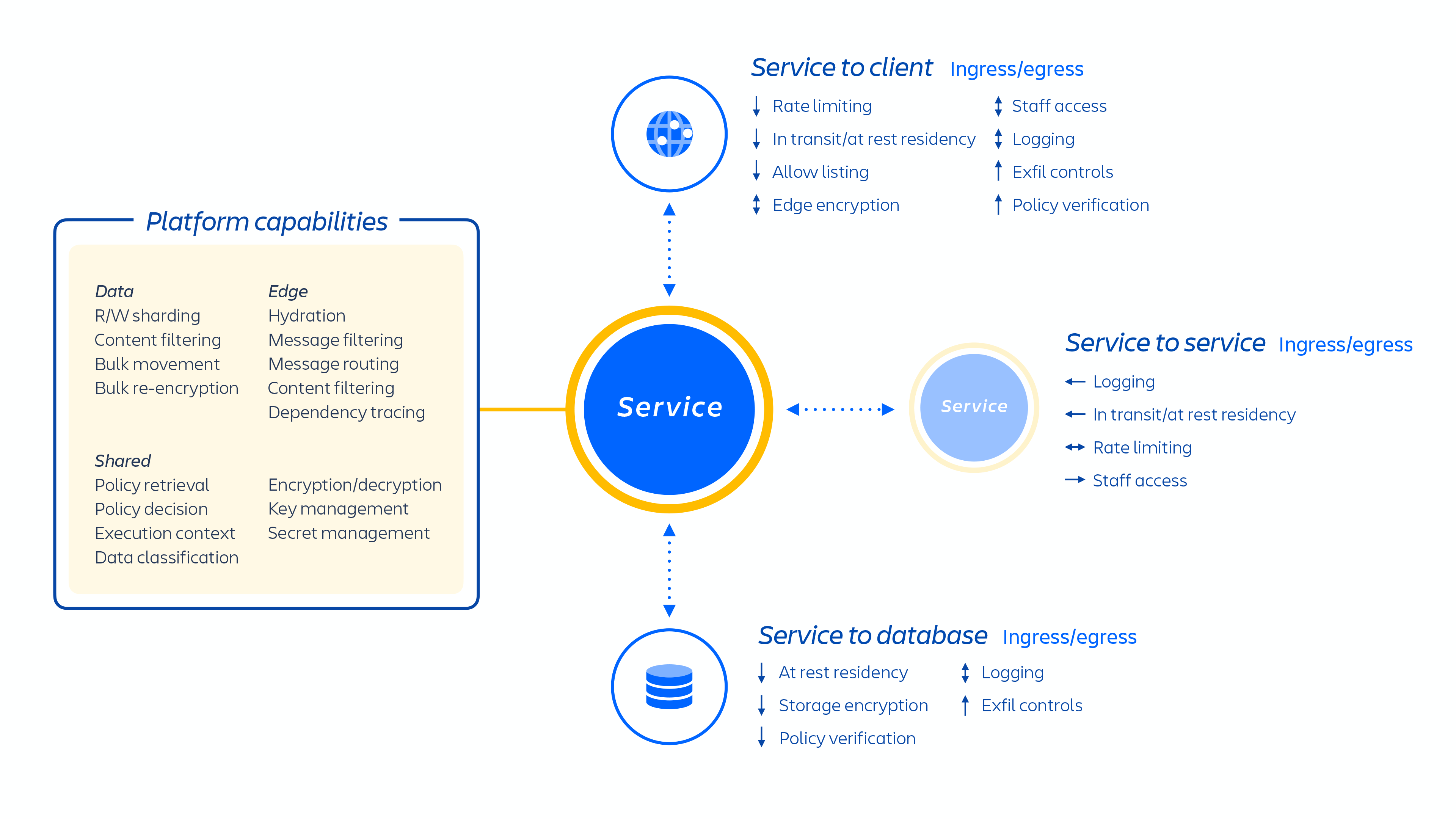
FIGURE 2
Architecture multilocataire
En plus de notre infrastructure cloud, nous avons créé et utilisons une architecture de microservices multilocataire avec une plateforme partagée qui prend en charge nos produits. Dans une architecture multilocataire, un seul service dessert plusieurs clients, y compris les bases de données et les instances de calcul nécessaires à l'exécution de nos produits cloud. Chaque partition (essentiellement un conteneur, voir la figure 3 ci-dessous) contient les données de plusieurs locataires, mais les données de chaque locataire sont isolées et inaccessibles aux autres locataires. Il est important de noter que nous ne proposons pas une architecture à locataire unique.
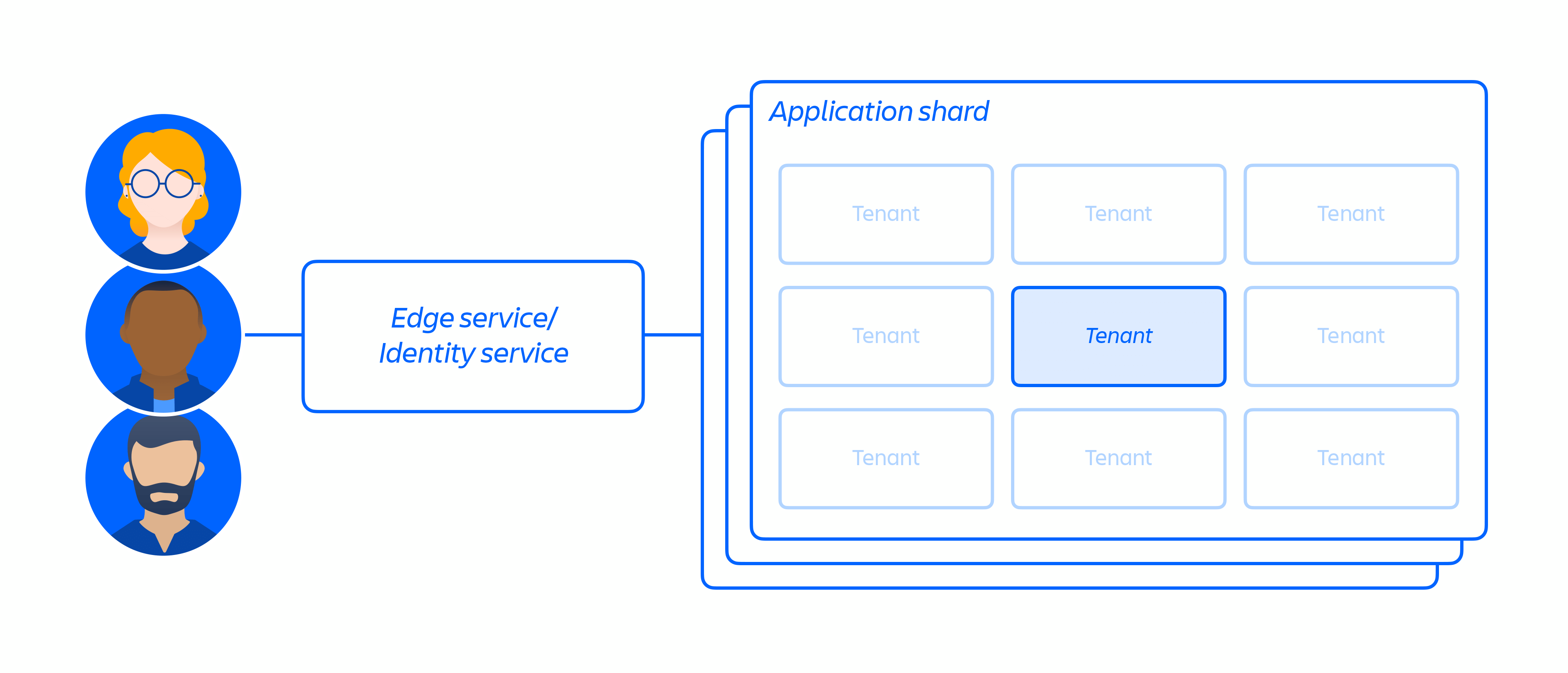
FIGURE 3
Nos microservices sont conçus selon le principe du moindre privilège et de sorte à réduire le périmètre de tout exploit zero-day ainsi que la probabilité de mouvements latéraux au sein de notre environnement cloud. Chaque microservice dispose de son propre stockage de données qui n'est accessible qu'avec le protocole d'authentification pour ce service spécifique, ce qui signifie qu'aucun autre service n'a accès en lecture ou en écriture à cette API.
Nous nous sommes concentrés sur l'isolement des microservices et des données, plutôt que sur la fourniture d'une infrastructure dédiée par locataire, car cela restreint l'accès aux données limitées d'un seul système pour de nombreux clients. Étant donné que la logique a été découplée, et que l'authentification et l'autorisation des données interviennent au niveau de la couche applicative, ce procédé fait office de contrôle de sécurité supplémentaire lorsque des demandes sont envoyées à ces services. Ainsi, si un microservice est compromis, la seule conséquence sera une limitation de l'accès aux données dont un service particulier a besoin.
Provisionnement d'un locataire et cycle de vie
Lorsqu'un nouveau client est provisionné, une série d'événements déclenche l'orchestration des services distribués et le provisionnement des magasins de données. Ces événements peuvent généralement être mappés à l'une des sept étapes du cycle de vie :
1. Les systèmes commerciaux sont immédiatement mis à jour avec les dernières métadonnées et informations de contrôle d'accès pour ce client, puis un système d'orchestration du provisionnement aligne « l'état des ressources provisionnées » avec l'état de la licence par le biais d'une série d'événements liés au locataire et aux produits.
Événements liés au locataire
Ces événements affectent le locataire dans son ensemble et peuvent prendre deux formes :
- Création : un locataire est créé et utilisé pour de tout nouveaux sites
- Destruction : un locataire entier est supprimé
Événements liés aux produits
- Activation : après l'activation de produits sous licence ou d'apps tierces
- Désactivation : après la désactivation de certains produits ou de certaines apps
- Suspension : après la suspension d'un produit existant, désactivant ainsi l'accès à un site donné dont il est propriétaire
- Annulation de suspension : après l'annulation de la suspension d'un produit existant, permettant ainsi l'accès à un site dont il est propriétaire
- Mise à jour de licence : contient des informations concernant le nombre de postes de licence pour un produit donné ainsi que son état (actif/inactif)
2. Création du site client et activation de l'ensemble de produits approprié pour le client. Le concept d'un site est le conteneur de plusieurs produits concédés sous licence à un client spécifique. (p. ex. Confluence et Jira Software pour <nom-site>.atlassian.net).
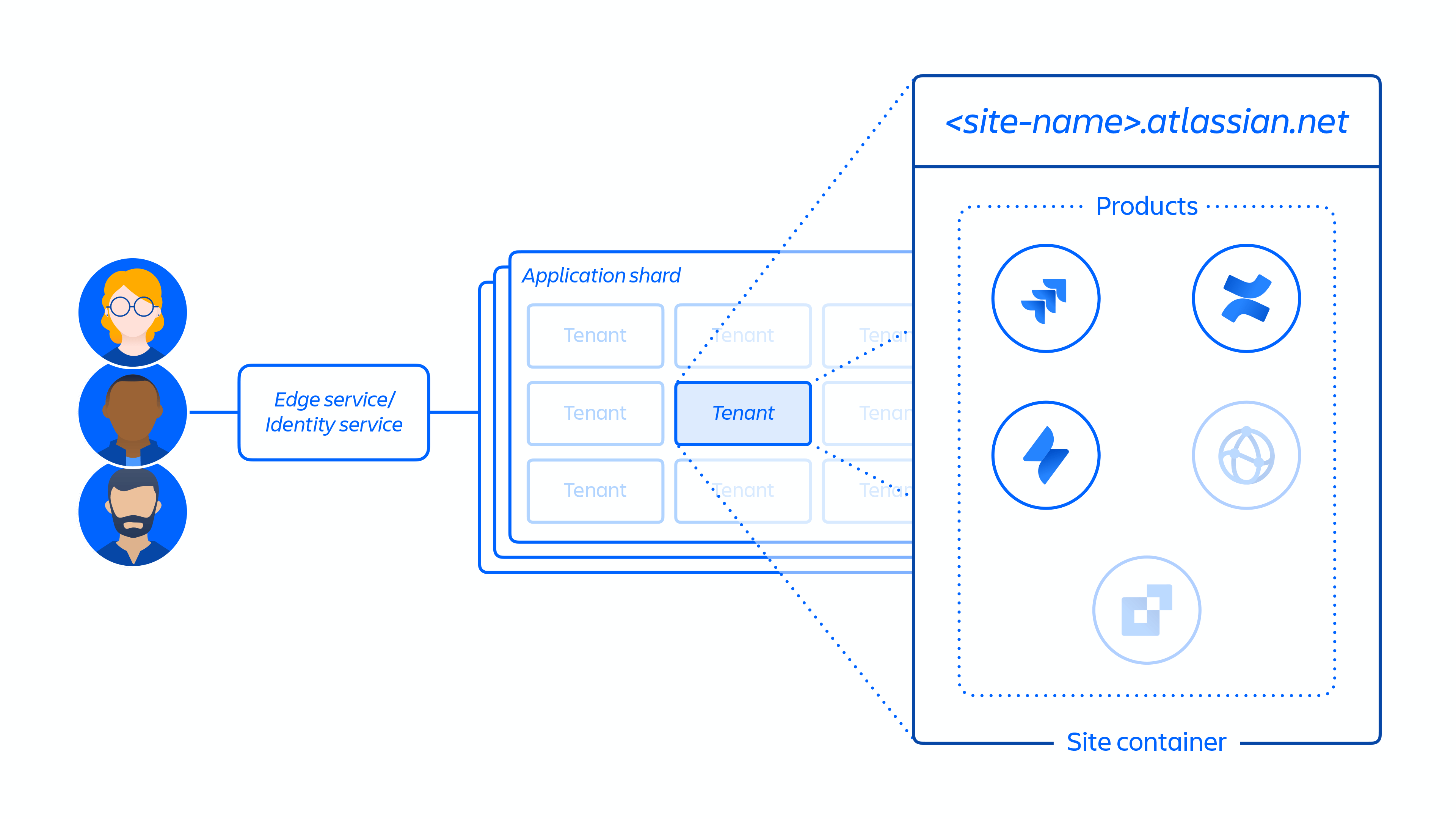
Figure 4
3. Provisionnement de produits sur le site client dans la région désignée.
Lorsqu'un produit est provisionné, la majeure partie de son contenu est hébergée à proximité de l'endroit où les utilisateurs y accèdent. Pour optimiser les performances des produits, nous ne limitons pas le mouvement des données lorsqu'elles sont hébergées dans le monde entier et nous pouvons déplacer des données entre les régions selon les besoins.
Pour certains de nos produits, nous proposons également la résidence des données. Cette dernière permet aux clients de choisir si les données des produits sont distribuées dans le monde entier ou conservées dans l'une de nos zones géographiques définies.
4. Création et stockage de la configuration et des métadonnées de base du site client et des produits.
5. Création et stockage des données d'identité du site et des produits, comme les utilisateurs, les groupes, les autorisations, et bien plus encore.
6. Provisionnement de bases de données de produits sur un site, p. ex. gamme de produits Jira, Confluence, Compass ou Atlas.
7. Provisionnement des apps sous licence des produits.
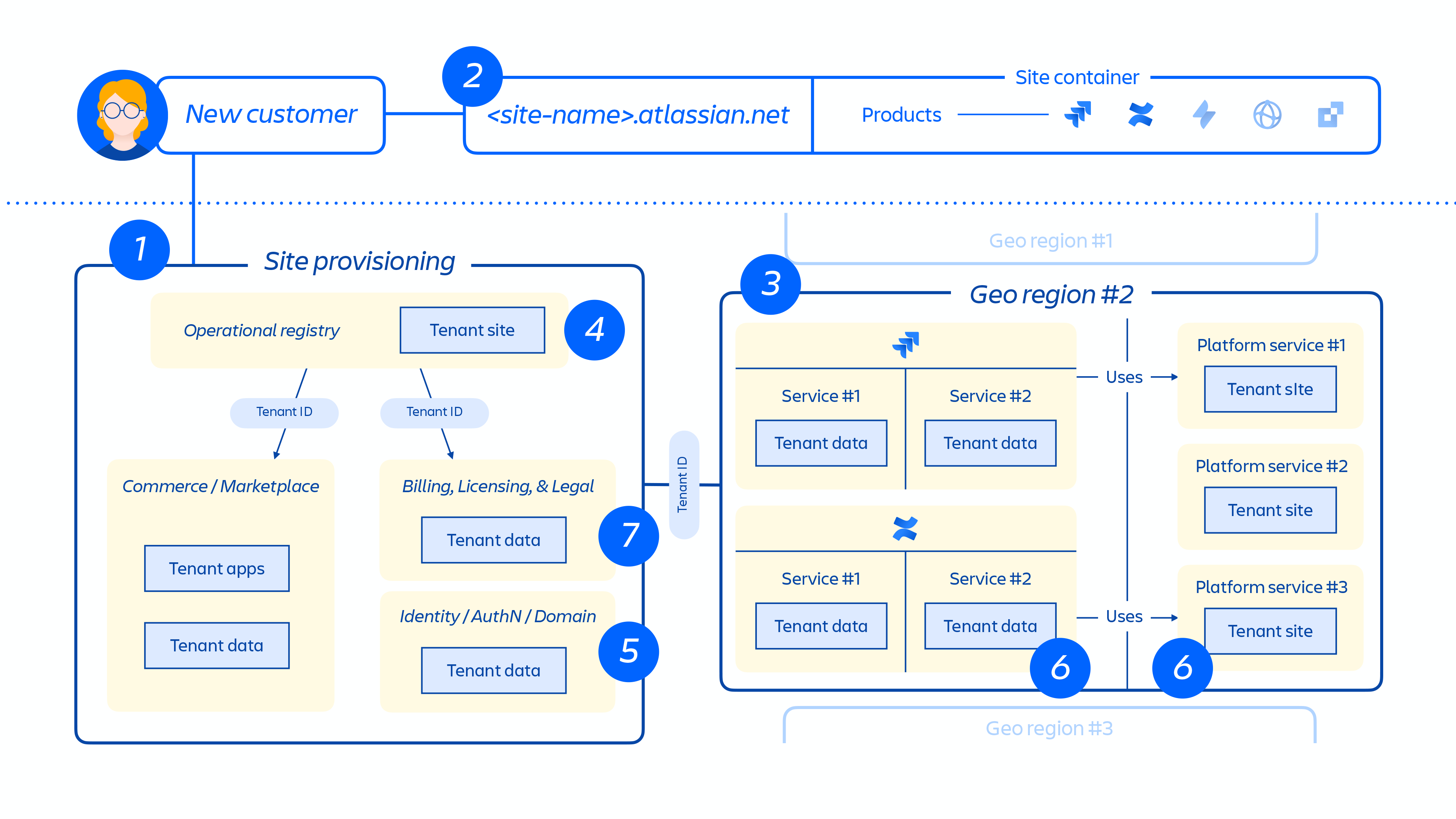
Figure 5
La figure 5 ci-dessus montre comment le site d'un client est déployé dans notre architecture distribuée, et pas uniquement dans une base de données ou un magasin unique. Cela inclut plusieurs emplacements physiques et logiques qui stockent des métadonnées, des données de configuration, des données produit et de plateforme, ainsi que d'autres informations de site connexes.