Atlassian Cloud
Architettura e pratiche operative di Atlassian Cloud
Scopri di più sull'architettura di Atlassian Cloud e sulle pratiche operative che utilizziamo
Introduzione
I prodotti e i dati di Atlassian Cloud sono ospitati su Amazon Web Services (AWS), il provider di servizi cloud leader del settore. I nostri prodotti vengono eseguiti su una piattaforma in ambiente PaaS (Platform as a Service) che è suddiviso in due insiemi principali di infrastrutture note come "Micros" e "non Micros". Jira, Confluence, Jira Product Discovery, Statuspage, Guard e Bitbucket vengono eseguiti sulla piattaforma Micros, mentre Opsgenie e Trello su quella non Micros.
Architettura dei servizi distribuiti
Con questa architettura AWS, ospitiamo una serie di servizi di piattaforma e prodotto utilizzati nelle nostre soluzioni. Ciò include funzionalità di piattaforma condivise e utilizzate in più prodotti Atlassian, come Media, Identity e Commerce, esperienze come il nostro Editor, nonché funzionalità di prodotto specifiche, come il servizio Ticket di Jira e Confluence Analytics.
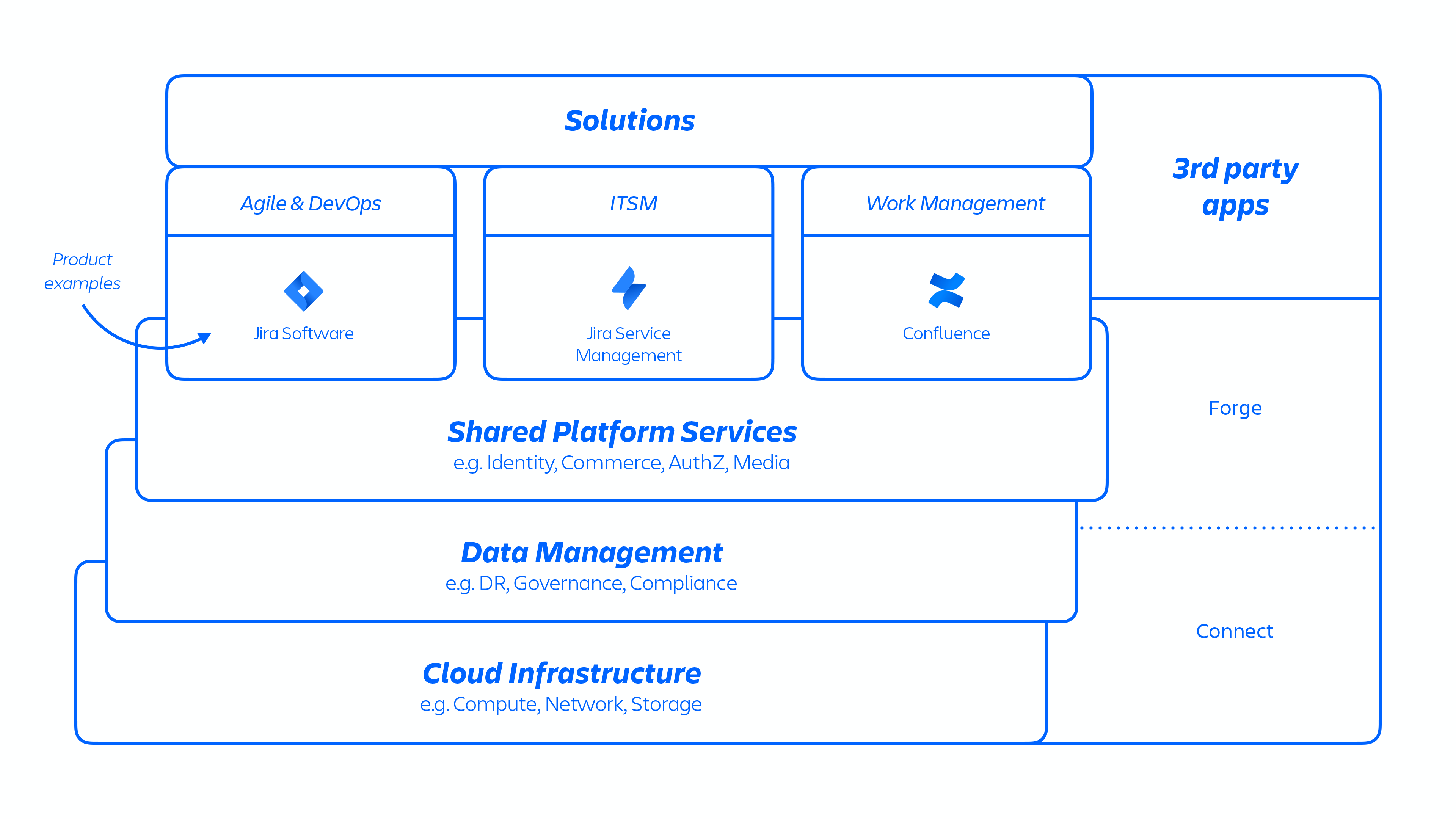
Figura 1
Gli sviluppatori Atlassian eseguono il provisioning di questi servizi tramite Kubernetes o con una piattaforma come servizio (PaaS) sviluppata internamente, denominata Micros; entrambe le opzioni orchestrano automaticamente la distribuzione di servizi condivisi, infrastruttura, archivi dati e relative funzionalità di gestione, inclusi i requisiti di sicurezza e controllo della conformità (vedi la figura 1 sopra). In genere, un prodotto Atlassian è costituito da più servizi "containerizzati" distribuiti su AWS tramite Micros o Kubernetes. I prodotti Atlassian utilizzano le funzionalità principali della piattaforma (vedi la figura 2 di seguito) che vanno dal routing delle richieste agli archivi di oggetti binari, all'autenticazione/autorizzazione, al contenuto transazionale generato dagli utenti (UGC) e agli archivi di relazioni tra entità, data lake, registrazione comune, tracciamento delle richieste, osservabilità e servizi di analisi. Questi microservizi sono costruiti utilizzando stack tecnici approvati e standardizzati a livello di piattaforma:
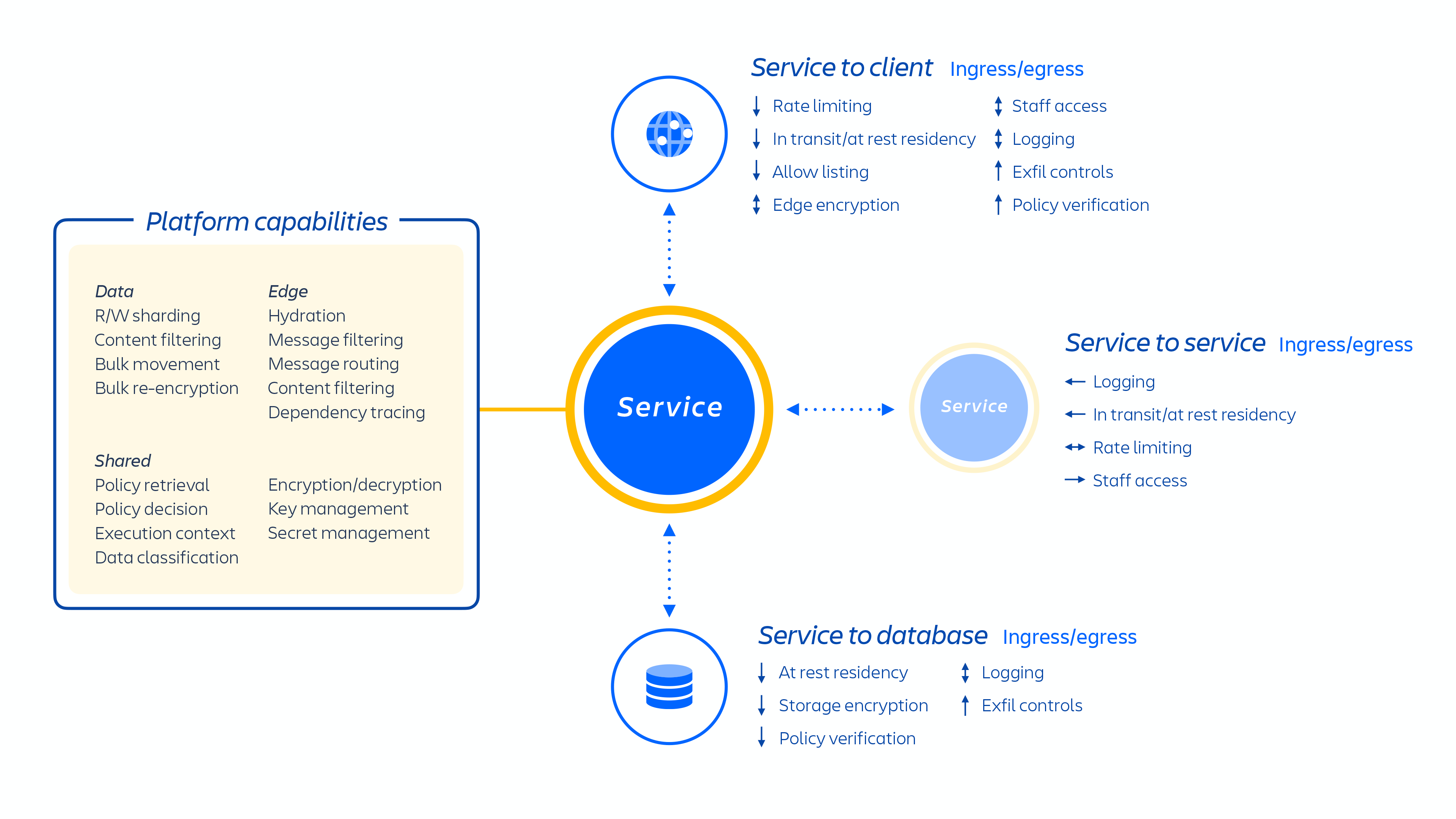
Figura 2
Architettura multi-tenant
Oltre alla nostra infrastruttura cloud, abbiamo creato un'architettura di microservizi multi-tenant con una piattaforma condivisa che supporta i nostri prodotti. In un'architettura multi-tenant, un singolo servizio serve più clienti, tra cui le istanze di database e di calcolo necessarie per eseguire i nostri prodotti Cloud. Ogni partizione (essenzialmente un container, vedi la figura 3 di seguito) contiene i dati relativi a più tenant, ma i dati di ciascun tenant sono isolati e inaccessibili agli altri tenant. È importante notare che non offriamo un'architettura a singolo tenant.
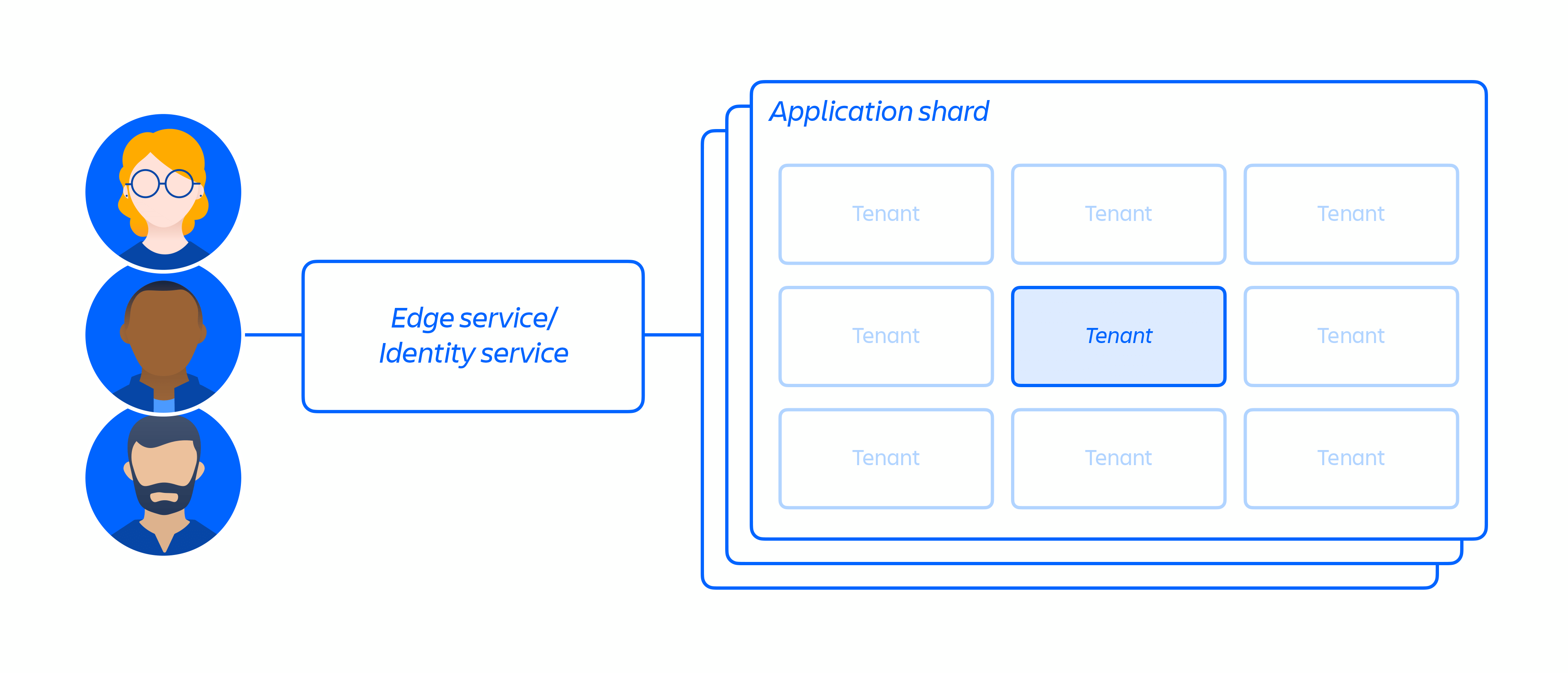
Figura 3
I nostri microservizi sono creati in un'ottica di privilegi minimi e sono progettati per ridurre al minimo l'ambito di qualsiasi exploit zero-day nonché la probabilità di movimenti laterali all'interno del nostro ambiente cloud. Ogni microservizio ha il proprio archivio di dati a cui è possibile accedere solo con il protocollo di autenticazione per quel servizio specifico, il che significa che nessun altro servizio ha accesso in lettura o scrittura a quell'API.
Ci siamo concentrati sull'isolamento di microservizi e dati, invece che sulla fornitura di un'infrastruttura dedicata per tenant, in modo da limitare l'accesso a una ristretta gamma di dati di un singolo sistema tra molti clienti. Poiché la logica è stata disaccoppiata e l'autenticazione e l'autorizzazione dei dati si verificano a livello di applicazione, queste offrono un controllo di sicurezza aggiuntivo quando le richieste vengono inviate a questi servizi. Pertanto, l'eventuale compromissione di un microservizio determinerà soltanto l'accesso limitato ai dati richiesti da un determinato servizio.
Provisioning e ciclo di vita del tenant
Quando viene eseguito il provisioning di un nuovo cliente, una serie di eventi attiva l'orchestrazione dei servizi distribuiti e il provisioning degli archivi di dati. Questi eventi possono essere generalmente ricondotti a uno dei sette passaggi del ciclo di vita:
1. I sistemi Commerce vengono immediatamente aggiornati con i metadati e le informazioni di controllo degli accessi più recenti relativi a quel cliente specifico, quindi un sistema di orchestrazione del provisioning allinea lo "stato delle risorse sottoposte a provisioning" con lo stato della licenza attraverso una serie di eventi tenant e di prodotto.
Eventi tenant
Questi eventi riguardano il tenant nel suo complesso e possono essere i seguenti:
- Creazione: un tenant viene creato e utilizzato per siti completamente nuovi
- Distruzione: un intero tenant viene eliminato
Eventi di prodotto
- Attivazione: dopo l'attivazione di prodotti concessi in licenza o app di terze parti
- Disattivazione: dopo la disattivazione di determinati prodotti o app
- Sospensione: dopo la sospensione di un determinato prodotto esistente che disattiva l'accesso a un determinato sito di proprietà
- Annullamento della sospensione: dopo l'annullamento della sospensione di un determinato prodotto esistente che consente l'accesso a un sito di proprietà
- Aggiornamento della licenza: contiene informazioni sul numero di postazioni di licenza per un determinato prodotto e sul suo stato (attivo/inattivo)
2. Creazione del sito del cliente e attivazione del set corretto di prodotti per il cliente. Il concetto di sito rimanda al container di più prodotti concessi in licenza a un determinato cliente (ad es. Confluence e Jira Software per <nome-sito>.atlassian.net).
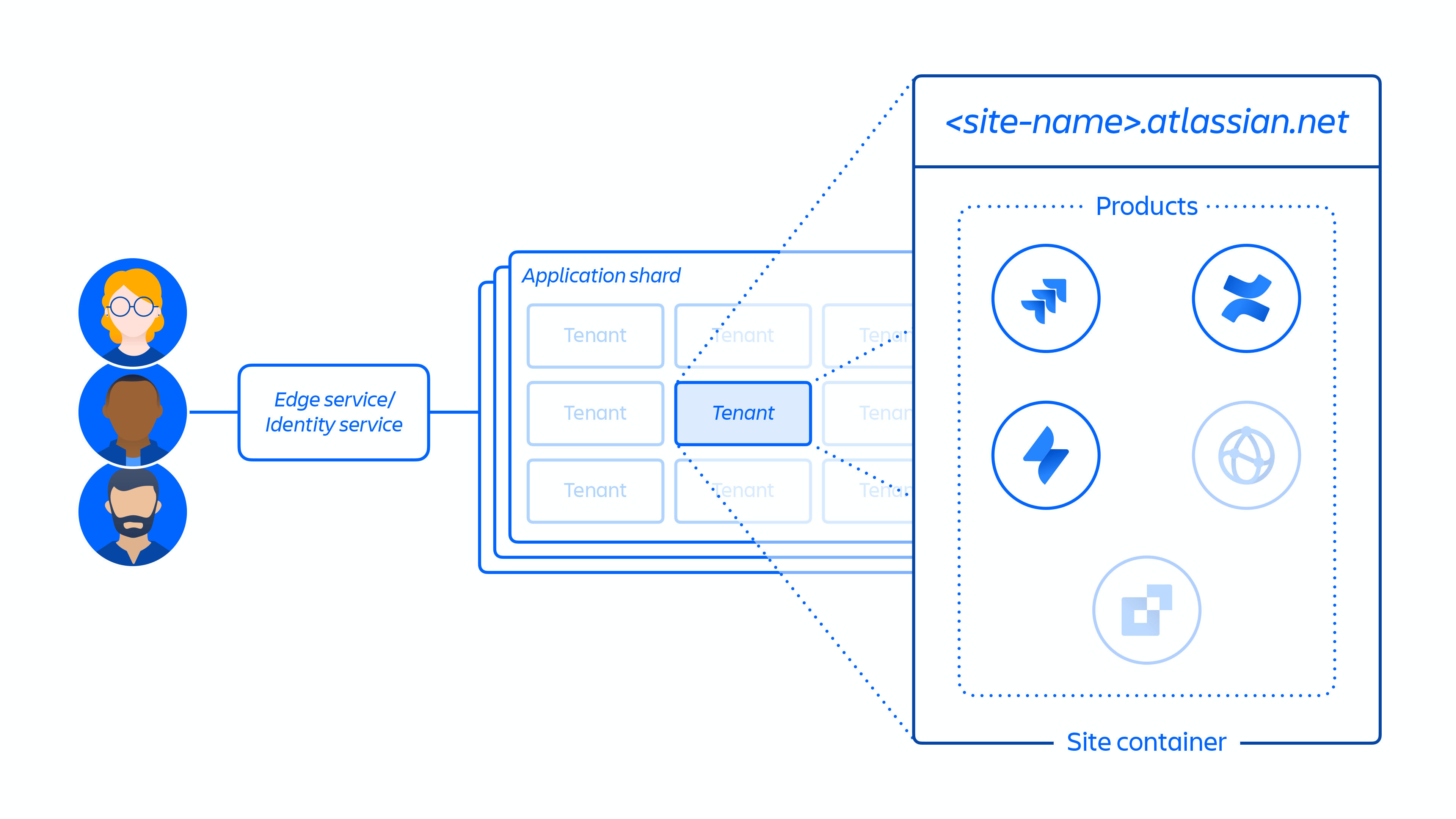
Figura 4
3. Provisioning dei prodotti all'interno del sito del cliente nella regione designata.
Quando viene eseguito il provisioning di un prodotto, la maggior parte dei suoi contenuti sarà ospitata vicino al punto in cui gli utenti vi accedono. Per ottimizzare le prestazioni del prodotto, non limitiamo lo spostamento dei dati quando sono ospitati a livello globale e potremmo spostare i dati da una regione all'altra se necessario.
Per alcuni prodotti, offriamo anche la residenza dei dati, che consente ai clienti di scegliere se i dati di prodotto devono essere distribuiti a livello globale o conservati in una delle nostre posizioni geografiche definite.
4. Creazione e archiviazione della configurazione e dei metadati principali del sito e dei prodotti del cliente.
5. Creazione e archiviazione dei dati di identità del sito e dei prodotti, come utenti, gruppi, autorizzazioni ecc.
6. Provisioning dei database di prodotti all'interno di un sito, ad es. famiglia di prodotti Jira, Confluence, Compass, Atlas.
7. Provisioning delle app dei prodotti concesse in licenza.
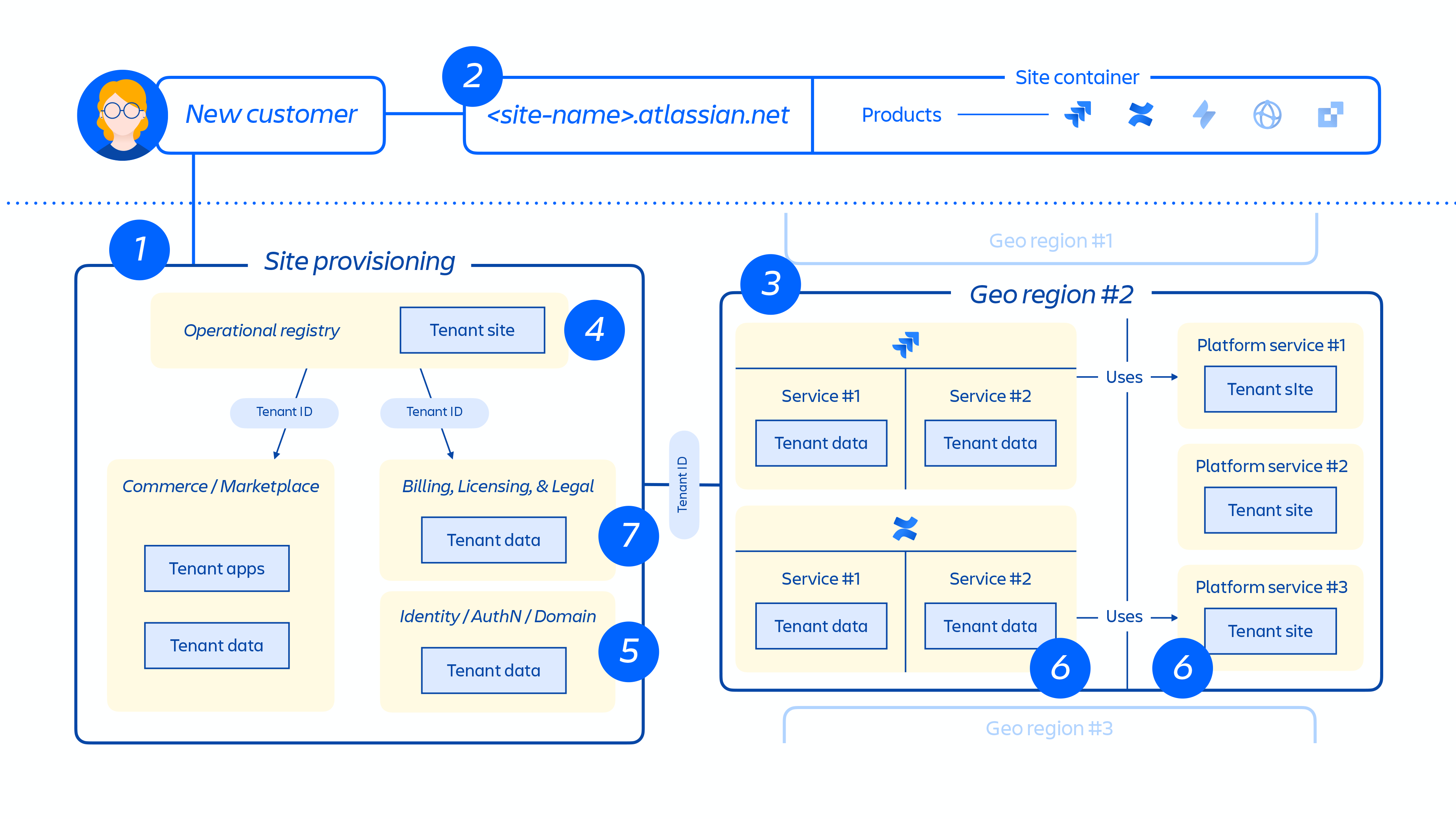
Figura 5
La figura 5 sopra mostra come il sito di un cliente viene distribuito nella nostra architettura distribuita, non solo in un singolo database o archivio. Ciò include più posizioni fisiche e logiche in cui sono archiviati metadati, dati di configurazione, dati di prodotto, dati di piattaforma e altre informazioni sul sito correlate.