Atlassian Cloud
Praktyki operacyjne i architektura Atlassian Cloud
Dowiedz się więcej na temat stosowanych przez nas praktyk operacyjnych i architektury Atlassian Cloud
Wstęp
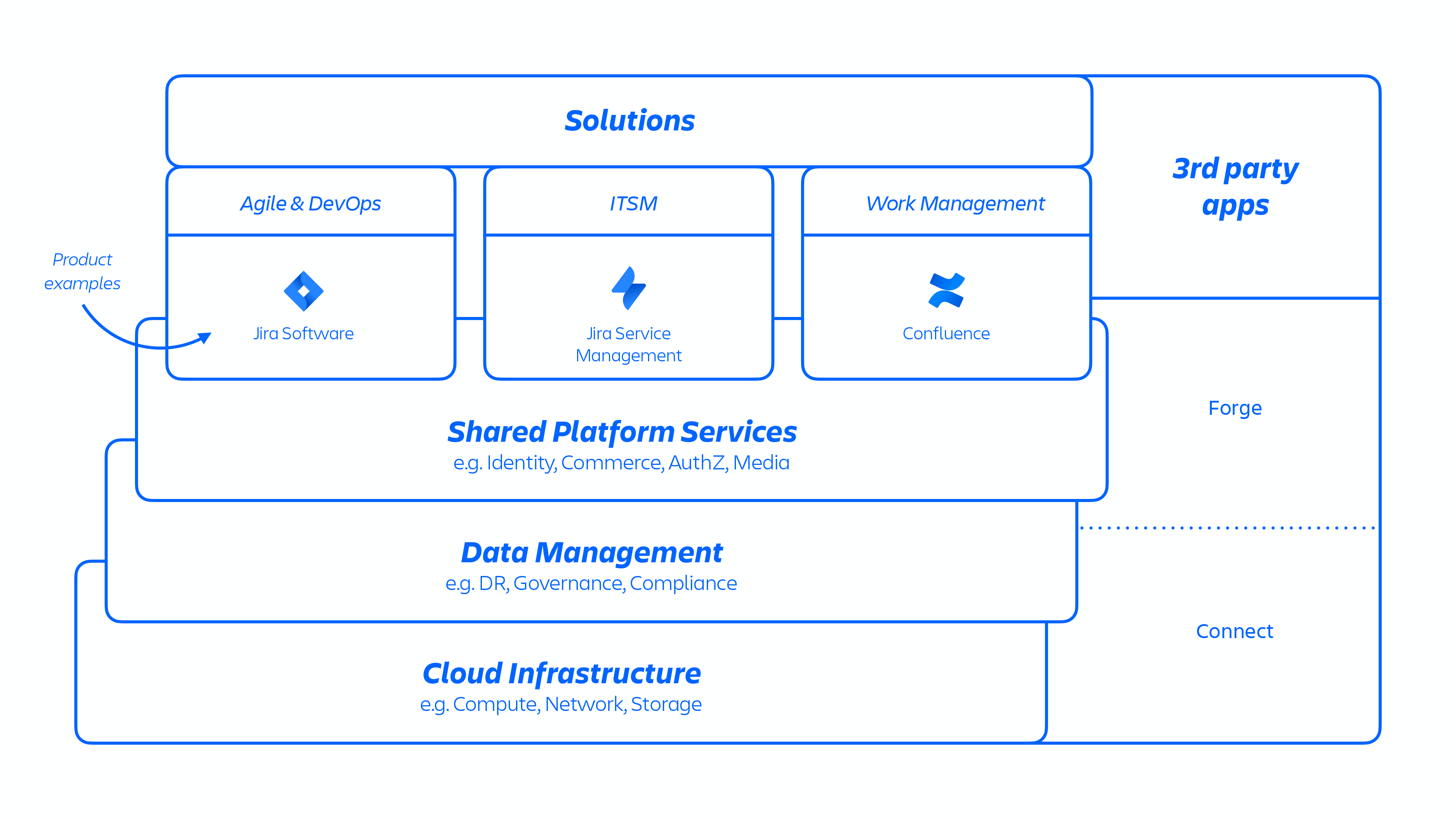
Produkty oraz dane Atlassian Cloud są hostowane przez przodującego w branży dostawcę usług w chmurze — Amazon Web Services (AWS). Nasze produkty działają w środowisku PaaS (Platform as a Service) podzielonym na dwa główne zbiory infrastruktury, które określamy jako Micros i inny niż Micros. Produkty Jira, Confluence, Jira Product Discovery, Statuspage, Guard i Bitbucket działają na platformie Micros, a Opsgenie i Trello na innej niż Micros.
Architektura usług rozproszonych
Wykorzystujemy tę architekturę AWS do hostowania wielu usług platformowych i produktowych stosowanych w naszych rozwiązaniach. Dotyczy to funkcji platformy, które są współdzielone i stosowane w wielu produktach Atlassian, takich jak Media, Identity, Commerce, środowisk takich jak nasz edytor, a także możliwości specyficznych dla konkretnego produktu, takich jak usługa zgłoszeń w systemie Jira i analizy Confluence.
Rysunek 1
Programiści firmy Atlassian świadczą te usługi za pośrednictwem platformy Kubernetes lub wewnętrznie opracowanej platformy jako usługi (PaaS), zwanej Micros, które automatycznie organizują wdrażanie usług współdzielonych, infrastruktury, magazynów danych i ich możliwości zarządzania, w tym wymogów z zakresu bezpieczeństwa i kontroli zgodności (zob. rysunek 1 powyżej). Zazwyczaj produkt Atlassian składa się z wielu usług „kontenerowych”, które są wdrażane w AWS za pomocą platform Micros lub Kubernetes. Produkty Atlassian wykorzystują podstawowe możliwości platformy (patrz rysunek 2 poniżej), od routingu wniosków po magazyny obiektów binarnych, uwierzytelnianie/autoryzację, transakcyjne magazyny treści generowanych przez użytkowników (UGC) i relacje między jednostkami, jeziora danych, wspólne rejestrowanie, śledzenie wniosków, wgląd i usługi analityczne. Te mikrousługi są budowane przy użyciu zatwierdzonych stosów technicznych znormalizowanych na poziomie platformy:
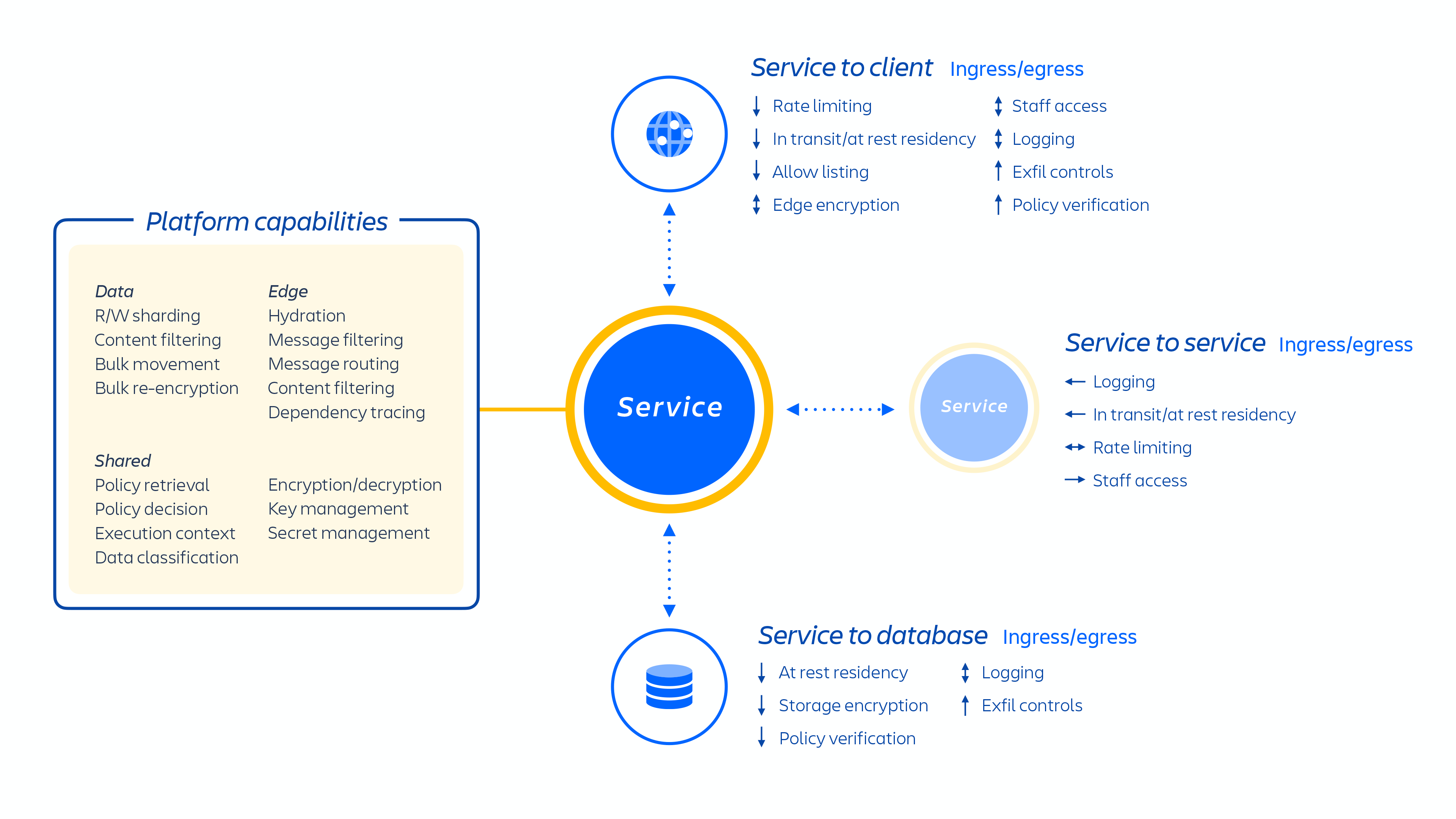
Rysunek 2
Architektura z wielodostępem
Wykorzystując naszą infrastrukturę chmurową, zbudowaliśmy i utrzymujemy wielodostępną architekturę mikrousług ze współdzieloną platformą do obsługi naszych produktów. W architekturze z wielodostępem pojedyncza usługa obsługuje wielu klientów, w tym bazy danych i instancje obliczeniowe wymagane do uruchamiania naszych produktów chmurowych. Każdy shard (zasadniczo kontener — patrz rysunek 3 poniżej) zawiera dane wielu dzierżawców, jednak dane każdego dzierżawcy są odizolowane i niedostępne dla innych dzierżawców. Należy pamiętać, że nie oferujemy architektury z pojedynczym dostępem.
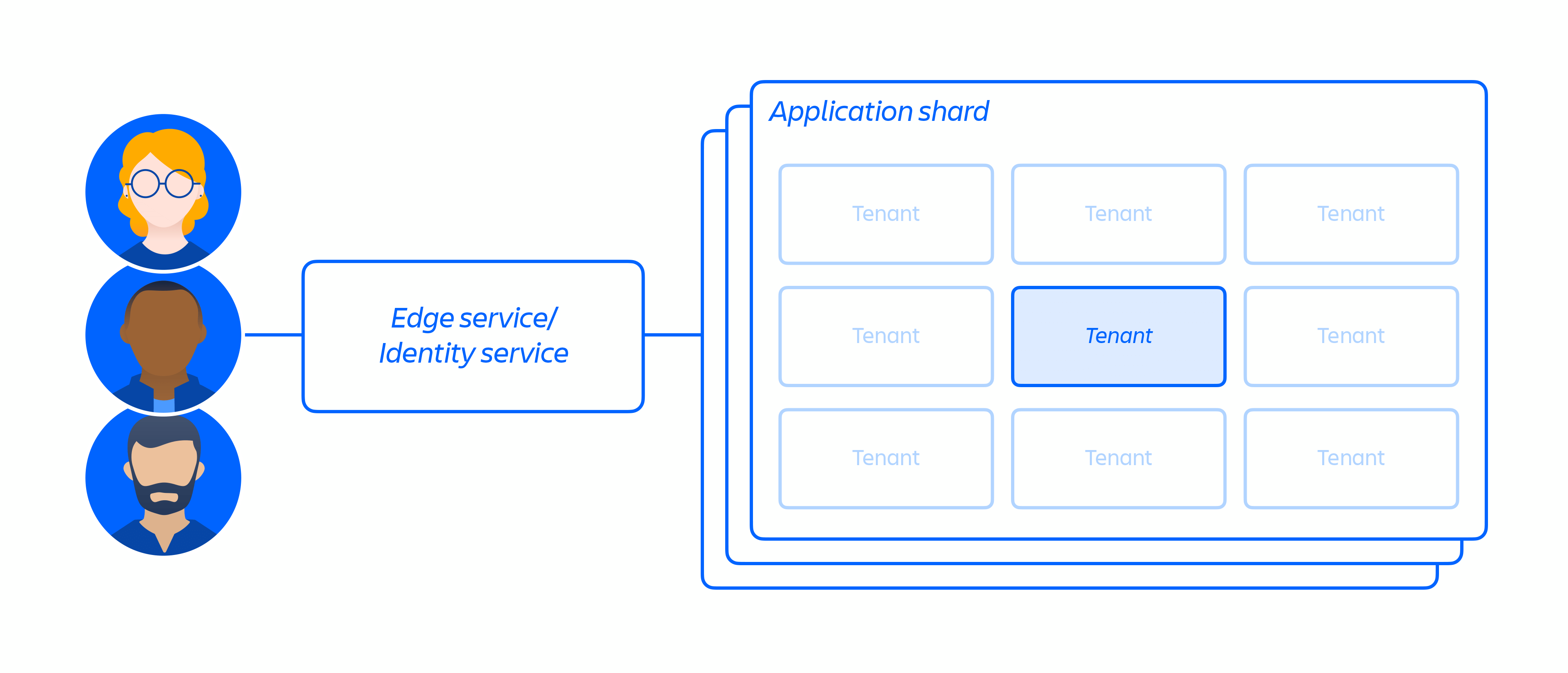
Rysunek 3
Nasze mikrousługi opracowano z uwzględnieniem najniższego poziomu uprawnień tak, aby zminimalizować zakres ataków typu zero-day i ograniczyć prawdopodobieństwo ruchu bocznego (lateral movement) w naszym środowisku chmurowym. Każda mikrousługa ma własny magazyn danych, do którego dostęp można uzyskać wyłącznie przy użyciu protokołu uwierzytelniania przeznaczonego do tej konkretnej usługi, co oznacza, że żadna inna usługa nie ma dostępu do odczytu ani zapisu danego interfejsu API.
Skoncentrowaliśmy się przede wszystkim na odizolowaniu mikrousług oraz danych, a nie dostarczaniu dedykowanej infrastruktury poszczególnym dzierżawcom, ponieważ ogranicza to dostęp wielu klientom do wąskiego zakresu danych pojedynczego systemu. Ponieważ logika została odseparowana, a uwierzytelnianie danych oraz autoryzacja zachodzą w warstwie aplikacji, stanowi to dodatkową kontrolę zabezpieczeń podczas wysyłania żądań do tych usług. W rezultacie, jeśli dojdzie do naruszenia zabezpieczeń mikrousługi, autor ataku otrzyma jedynie ograniczony dostęp do danych wymaganych przez konkretną usługę.
Aprowizacja i cykl życia dzierżaw
Po aprowizacji nowego klienta seria zdarzeń wyzwala orkiestrację usług rozproszonych i aprowizację magazynów danych. Te zdarzenia można zasadniczo przypisać do jednego z siedmiu etapów cyklu życia:
1. Systemy handlowe są niezwłocznie aktualizowane o najnowsze metadane i informacje o kontroli dostępu dla danego klienta, a następnie system orkiestracji aprowizacji dopasowuje „stan aprowizowanych zasobów” do stanu licencji poprzez serię zdarzeń związanych z dzierżawą i produktami.
Zdarzenia dotyczące dzierżawy
Zdarzenia, które wpływają na dzierżawę jako całość, i mogą obejmować:
- Tworzenie: dzierżawa jest tworzona i stosowana do zupełnie nowych witryn.
- Likwidacja: cała dzierżawa jest usuwana.
Zdarzenia dotyczące produktów
- Aktywacja: po aktywacji licencjonowanych produktów lub aplikacji innych firm.
- Dezaktywacja: po dezaktywacji niektórych produktów lub aplikacji.
- Zawieszenie: po zawieszeniu konkretnego istniejącego produktu i tym samym zablokowaniu dostępu do posiadanej witryny.
- Wycofanie zawieszenia: po cofnięciu zawieszenia konkretnego istniejącego produktu i tym samym zapewnieniu dostępu do posiadanej witryny.
- Aktualizacja licencji: zawiera informacje dotyczące liczby stanowisk licencyjnych danego produktu oraz jego statusu (aktywny/ nieaktywny).
2. Utworzenie witryny klienta i aktywacja poprawnego zestawu produktów dla klienta. Zgodnie z koncepcją witryna jest kontenerem wielu produktów licencjonowanych przez konkretnego klienta. (np. Confluence i Jira Software w przypadku witryny <site-name>.atlassian.net).
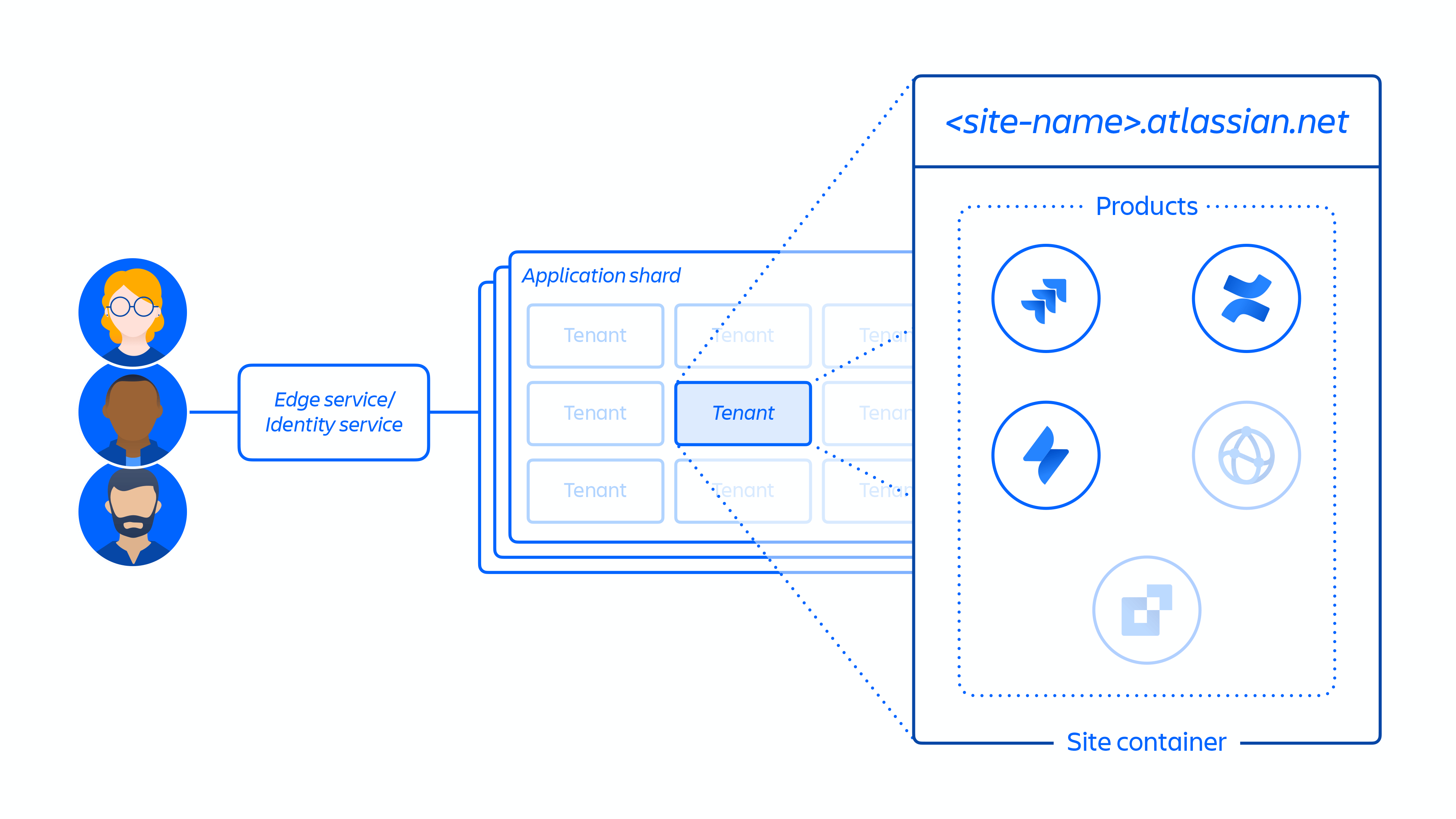
Rysunek 4
3. Aprowizacja produktów w obrębie witryny klienta w wyznaczonym regionie.
Podczas aprowizacji produktu większość związanej z nim zawartości jest hostowana w pobliżu lokalizacji, w której użytkownicy uzyskują dostęp do produktu. Aby zoptymalizować wydajność produktu, nie ograniczamy przepływu danych, gdy są one hostowane globalnie, a w razie potrzeby możemy przenosić dane między regionami.
W przypadku niektórych naszych produktów oferujemy również funkcję jurysdykcji danych. Pozwala ona klientom wybrać, czy dane produktów mają być rozproszone globalnie, czy przechowywane w jednej z naszych zdefiniowanych lokalizacji geograficznych.
4. Tworzenie i przechowywanie głównych metadanych i konfiguracji witryny oraz produktów klienta.
5. Tworzenie i przechowywanie danych tożsamości witryny i produktów, takich jak użytkownicy, grupy, uprawnienia itp.
6. Aprowizacja baz danych produktów w obrębie witryny, np. rodziny produktów Jira, Confluence, Compass, Atlas.
7. Aprowizacja licencjonowanych aplikacji do produktów.
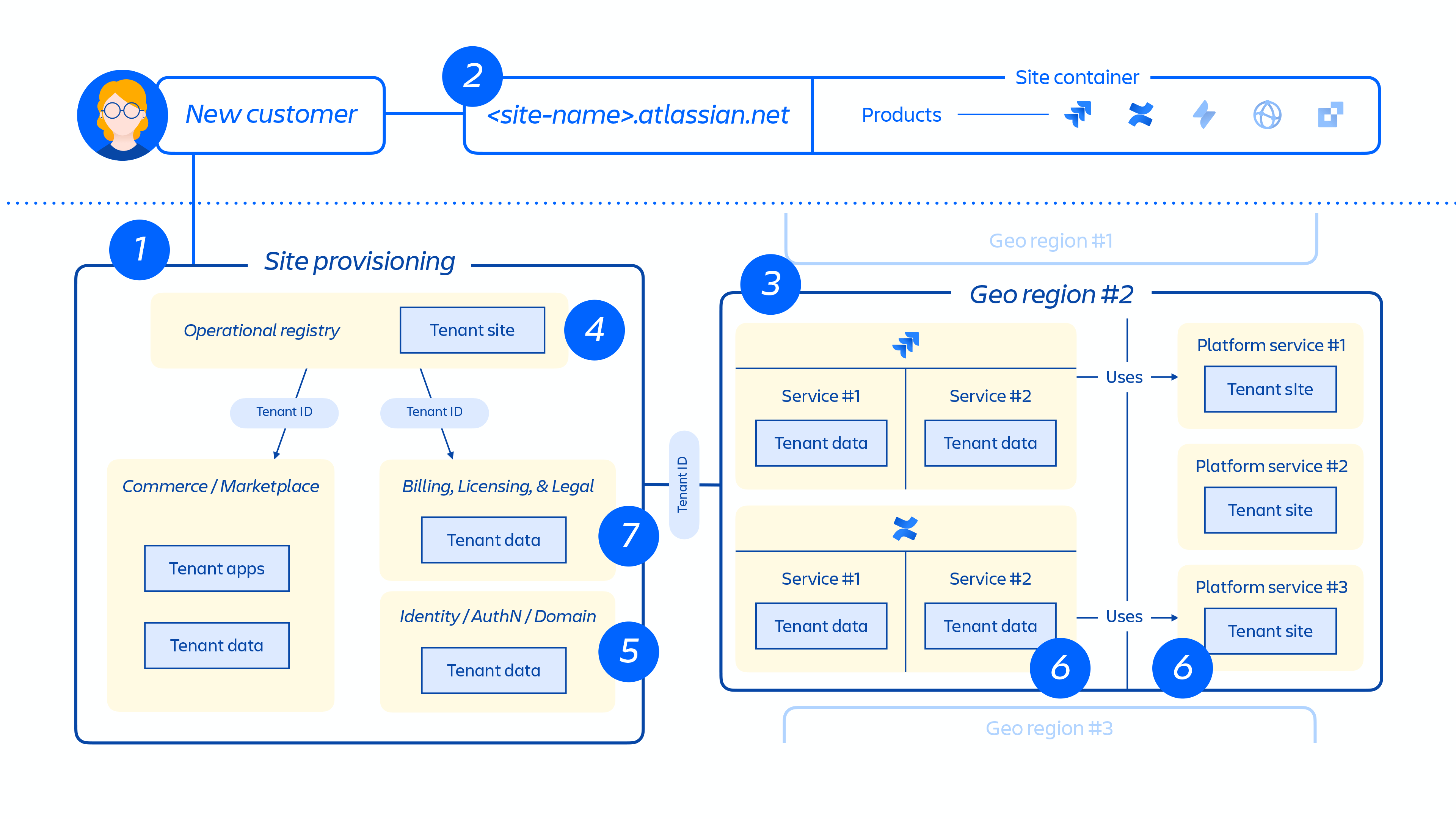
Rysunek 5
Na Rysunku 5 powyżej przedstawiono sposób wdrażania witryny klienta w całej naszej architekturze rozproszonej, a nie tylko w pojedynczej bazie danych lub w pojedynczym magazynie. W procesie uczestniczy wiele lokalizacji fizycznych i logicznych, w których są przechowywane metadane, dane konfiguracji, dane produktu, dane platformy oraz inne powiązane informacje o witrynie.