Монорепозитории в Git
Что такое монорепозиторий?
Монорепозиторий можно описать по-разному, однако мы выделим следующие критерии.
- Репозиторий содержит более одного логического проекта (например, клиент для iOS и веб-приложение).
- Эти проекты, скорее всего, не связаны или слабо связаны между собой либо связаны другими способами (например, с помощью инструментов для управления зависимостями).
- Репозиторий можно назвать крупным по многим параметрам:
- количество коммитов;
- количество веток и (или) тегов;
- количество отслеживаемых файлов;
- объем отслеживаемого содержимого (определяется по каталогу .git в репозитории).
В компании Facebook есть пример такого монорепозитория.
Главный репозиторий исходного кода Facebook, куда каждую неделю поступают тысячи коммитов для сотен тысяч файлов, просто огромен. Он во много раз превосходит даже ядро Linux, в котором в 2013 году насчитывалось 17 миллионов строк кода и 44 000 файлов.
Связанные материалы
Перемещение полного репозитория Git
СМ. РЕШЕНИЕ
Изучите Git с помощью Bitbucket Cloud
А при тестировании производительности компания Facebook использовала тестовый репозиторий со следующими характеристиками:
- 4 миллиона коммитов;
- линейная история;
- около 1,3 миллиона файлов;
- размер каталога .git — около 15 ГБ;
- размер файла индекса — 191 МБ.
Концептуальные проблемы
При управлении несвязанными проектами в монорепозитории Git возникает множество концептуальных проблем.
Во-первых, Git отслеживает в каждом отдельном коммите состояние всего дерева. Такой подход полезен для отдельных или связанных между собой проектов, но при этом сильно затрудняет работу в репозитории со множеством несвязанных проектов. Иными словами, на поддерево, интересующее разработчика, влияют коммиты в несвязанных частях дерева. Эта проблема многократно возрастает при большом количестве коммитов, продвигающих историю дерева. Поскольку конец ветки постоянно меняется, для отправки изменений требуется частое слияние или локальное перебазирование.
Тег в Git — это именованный псевдоним конкретного коммита, указывающего на целое дерево. Однако в монорепозитории польза от тегов невелика. Спросите себя: если вы работаете над веб-приложением, которое постоянно развертывается из монорепозитория, какое значение для версионного iOS-клиента имеет тег релиза?
Проблемы с производительностью
Помимо этих концептуальных трудностей у монорепозитория может возникнуть множество проблем с производительностью.
количество коммитов;
При управлении несвязанными проектами в одном репозитории могут возникнуть проблемы на уровне коммитов (независимо от масштаба). Со временем может появиться большое количество коммитов, причем их число будет быстро расти (Facebook сообщает о «тысячах коммитов в неделю»). Это создает серьезные трудности, поскольку в Git история проекта представлена с помощью направленного ациклического графа (DAG). При большом количестве коммитов любая команда, проходящая по графу, может выполняться все медленнее по мере удлинения истории.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Количество ссылок
Наличие большого количества ссылок (веток или тегов) в монорепозитории влияет на производительность по многим параметрам.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
146,44 секунды пользовательского времени*.
* Продолжительность операции зависит в том числе от кэша страниц и базовой системы хранения.
количество отслеживаемых файлов;
Индекс, или кэш каталога (.git/index), отслеживает каждый файл в репозитории. С помощью индекса система Git определяет наличие изменений в файле. Для этого она выполняет stat(1) в случае с каждым файлом и сравнивает сведения об изменениях с информацией в индексе.
Таким образом, количество отслеживаемых файлов влияет на скорость выполнения* многих операций.
git statusможет замедлиться (поскольку извлекается статистика по каждому файлу, при этом файл индекса может оказаться крупным).git commitтакже может замедлиться (в этом случае тоже извлекается статистика по каждому файлу).
* Продолжительность операции зависит в том числе от кэша страниц и базовой системы хранения. Снижение скорости заметно только при большом количестве файлов, исчисляемом десятками или сотнями тысяч.
Крупные файлы
Наличие крупных файлов в одном поддереве или проекте ухудшает производительность всего репозитория. Так, крупные файлы мультимедиа, добавленные к проекту iOS-клиента в монорепозитории, клонируются, даже если разработчик (или агент сборки) работает над несвязанным проектом.
Совокупный эффект
Комбинация нескольких факторов — будь то количество файлов, частота их изменения или размер — усиливает негативное влияние на производительность.
- Переключение между ветками или тегами особенно полезно в контексте поддерева (например, такого, с которым взаимодействует разработчик), но в результате этого действия обновляется все дерево целиком. Этот процесс может замедляться, если затронуто большое количество файлов, однако для этой проблемы можно найти обходное решение. Например, команда
git checkout ref-28642-31335 -- templatesобновляет каталог./templates, чтобы он соответствовал указанной ветке, но не обновляет указательHEAD. Побочный эффект заключается в том, что в индексе обновленные файлы помечаются как измененные. - Клонирование и извлечение выполняются медленно и при этом интенсивно задействуют ресурсы сервера, так как вся информация сжимается в pack-файл перед переносом.
- Сбор мусора выполняется медленно и запускается по умолчанию при отправке коммита (если возникает такая потребность).
- Ресурсы интенсивно задействуются во всех операциях, где требуется первичное или повторное создание pack-файла, включая
git-upload-pack и git gc.
Стратегии смягчения последствий
Конечно, было бы здорово, если бы в Git отдельно поддерживался сценарий использования монолитных репозиториев, однако цели разработки Git, благодаря которым эта система стала такой успешной и популярной, иногда мешают использовать ее не по назначению. Хорошая новость для подавляющего большинства команд заключается в том, что по-настоящему крупные монолитные репозитории можно назвать исключением, поэтому вам вряд ли удастся применить сведения из этой статьи на практике, даже если они покажутся вам интересными.
Тем не менее существуют различные стратегии смягчения последствий, которые могут помочь при работе с крупными репозиториями. Мой коллега Никола Паолуччи описал несколько обходных путей для репозиториев с длинной историей или крупными двоичными файлами.
Удаление ссылок
Если ваш репозиторий содержит десятки тысяч ссылок, возможно, следует удалить те из них, которые больше не нужны. DAG сохраняет историю изменений, а коммиты слияния указывают на родительские объекты, поэтому работу в ветках можно отследить, даже если эти ветки больше не существуют.
В рабочем процессе на основе веток не следует хранить много долгосрочных веток. Краткосрочные функциональные ветки можно смело удалить после слияния.
Возможно, вам будет полезно удалить все ветки, которые были объединены с главной веткой, такой как main или production. Историю изменений по-прежнему можно будет отследить, если коммит доступен из главной ветки и объединение выполнено с помощью коммита слияния. По умолчанию в комментарии к коммиту слияния часто указывается имя ветки (эту информацию можно сохранить на будущее).
Работа с большим количеством файлов
Если в репозитории много файлов (от десятков до сотен тысяч), можно использовать быстрое локальное хранилище с большим объемом памяти в качестве буферного кэша. Для этого потребуются существенные изменения в клиенте, подобные тем, которые компания Facebook реализовала для Mercurial.
Вместо того чтобы выполнять перебор всех файлов и проверять, не изменились ли какие-либо из них, компания начала регистрировать изменения с помощью уведомлений файловой системы. Команда хочет внедрить аналогичный подход (в нем также используется Watchman) для Git, однако он пока не реализован.
Использование хранилища крупных файлов Git LFS
Раздел обновлен 20 января 2016 года
В проектах с крупными файлами, например с видеоинформацией или изображениями, можно использовать Git LFS, чтобы ограничить влияние этих файлов на размер и общую производительность репозитория. Вместо того чтобы хранить крупные объекты прямо в репозитории, Git LFS помещает туда небольшой одноименный файл-заполнитель со ссылкой на объект, который находится в специальном хранилище крупных объектов. Git LFS подключается во время операций Git (push, pull, checkout и fetch), чтобы передача и замена таких объектов в рабочем каталоге прошла незаметно для пользователя. Это значит, что вы можете работать с крупными файлами как обычно и без негативных последствий, присущих раздутым репозиториям.
Bitbucket Server 4.3 (и более поздние версии) включает полностью совместимое решение Git LFS версии 1.0 (или более поздней), поэтому пользователи могут предварительно просматривать и сравнивать крупные файлы изображений, которые отслеживаются хранилищем LFS, прямо из пользовательского интерфейса Bitbucket.
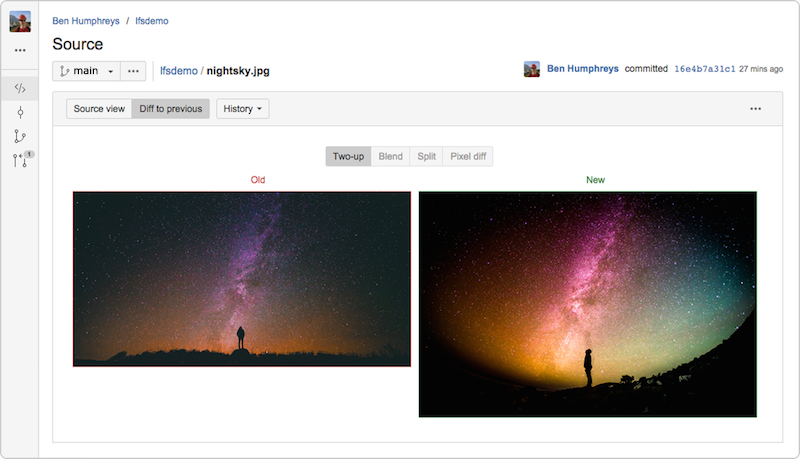
Мой коллега по Atlassian Стив Стритинг является активным участником проекта LFS и недавно написал о нем статью.
Определение границ и разделение репозитория
Вы можете пойти наиболее радикальным путем и разделить монорепозиторий на мелкие специализированные репозитории Git. Попробуйте отказаться от отслеживания всех изменений в одном репозитории и вместо этого определите границы компонентов (например, можно выбрать модули или компоненты с похожим циклом выпуска). Чтобы определить четкие субкомпоненты, разработчики добавляют в репозиторий теги и стараются сделать их логичными в контексте других частей дерева исходного кода.
Конечно, было бы здорово, если бы в Git существовала удобная поддержка монорепозиториев, но их концепция расходится с тем, что в первую очередь делает систему Git такой успешной и популярной. Но большинство проблем можно решить, поэтому вы не должны отказываться от возможностей Git лишь из-за того, что используете монорепозиторий.
Поделитесь этой статьей
Следующая тема
Рекомендуемые статьи
Добавьте эти ресурсы в закладки, чтобы изучить типы команд DevOps или получать регулярные обновления по DevOps в Atlassian.

Блог Bitbucket

Образовательные программы DevOps
