Работа с большими репозиториями в Git

Николя Паолуччи
Консультант по разработке
В Git можно эффективно отслеживать эволюцию базы кода и вести разработку совместно с коллегами. Но как быть, если вы хотите отслеживать огромный репозиторий?
В этой статье я предлагаю несколько решений для такой проблемы.
Две категории больших репозиториев
Репозитории могут сильно разрастаться по одной из двух главных причин:
- В них накапливается очень длинная история (за долгосрочным проектом тянется большой шлейф данных).
- В них находятся огромные двоичные файлы, которые нужно отслеживать и сопоставлять с кодом.
А иногда бывает и то, и другое.
Вторая проблема иногда может усугубляться тем, что из репозитория вовремя не удаляют устаревшие двоичные артефакты. Решение здесь довольно простое, хотя и утомительное (см. далее).
Методы и обходные пути будут разными в каждом сценарии, но в некоторых случаях они могут и дополнять друг друга. Я опишу каждый по отдельности.
Клонирование репозиториев с очень длинной историей
По-настоящему крупные репозитории — редкость, но это не отменяет того, что клонировать их очень сложно. А избежать длинной истории удается не всегда: порой репозиторий нельзя сократить из-за нормативных или юридических требований.
Простое решение: поверхностное клонирование git
Первый способ быстрого клонирования, позволяющий сэкономить время разработчиков и системы, а также место на диске, заключается в том, чтобы копировать только недавние версии. При поверхностном клонировании Git из истории репозитория извлекается только заданное количество последних коммитов.
Как это делается? Просто используйте параметр –depth. Например:
git clone --depth [глубина] [удаленный-url]
Допустим, что репозиторий содержит историю проекта длиной в 10 лет или больше. Например, мы перенесли в Git базу кода Jira, накопившуюся за 11 лет. Экономия времени для таких репозиториев в сумме может давать ощутимую цифру.
Размер полного клона Jira составляет 677 МБ, а рабочего каталога, содержащего более 47 000 коммитов, — еще 320 МБ. Поверхностное клонирование репозитория займет 29,5 секунды, в то время как полное клонирование с копированием всей истории отнимет 4 минуты 24 секунды. И экономия времени возрастает пропорционально количеству двоичных файлов, накопившихся в проекте.
Связанные материалы
Перемещение полного репозитория Git
СМ. РЕШЕНИЕ
Изучите Git с помощью Bitbucket Cloud
Совет: поверхностное клонирование с той же пользой можно применять и в системах сборки, подключенных к репозиторию Git.
Поскольку раньше некоторые операции имели скудную поддержку, поверхностное клонирование в Git применялось ограниченно. С последними версиями (1.9 и новее) дело обстоит гораздо лучше: теперь полноценная загрузка содержимого и его отправка в репозиторий возможна даже для поверхностных клонов.
Ювелирная точность: git filter-branch
Для наведения порядка в огромных репозиториях с большим количеством созданного по ошибке двоичного «мусора» и старых, ненужных файлов отлично подойдет команда git filter-branch. Она шаг за шагом проверяет всю историю проекта, фильтруя, изменяя или пропуская файлы по заданному алгоритму.
Это очень мощный инструмент, с которым вам потребуется лишь определить, какую часть репозитория нужно проредить. Это несложно, поскольку есть доступные скрипты, помогающие обнаружить крупные объекты.
Синтаксис имеет следующий вид:
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'При всей пользе у команды git filter-branch есть незначительный недостаток: фактически переписывается вся история проекта, поэтому изменяются все идентификаторы коммитов. Из-за этого каждому разработчику придется еще раз клонировать обновленный репозиторий.
Если вы собираетесь выполнить очистку с помощью git filter-branch, предупредите об этом команду и приостановите работу на время выполнения операции, а затем попросите коллег создать новый клон репозитория.
Совет: подробнее о команде git filter-branch можно узнать в этой статье, посвященной тому, как разделить репозиторий Git на части.
Альтернатива git shallow-clone: клонирование только одной ветки
Начиная с версии 1.7.10, в Git также можно клонировать отдельные ветки, тем самым ограничивая объем копируемой истории:
git clone [remote url] --branch [branch_name] --single-branch [folder]Этот специальный прием полезен, когда вы работаете с долгосрочными ветками, в которых накопилось много изменений, или когда у вас много веток, но работаете вы только с некоторыми из них. Если у вас мало веток и отличия между ними незначительны, этот способ не даст особых преимуществ.
Управление репозиториями с огромными двоичными файлами
Другой тип больших репозиториев характеризуется двоичными файлами огромных размеров. С ними сталкиваются самые разные команды разработчиков ПО (и не только). Разработчики игр манипулируют крупными 3D-моделями, веб-разработчики отслеживают необработанные изображения, а команды САПР работают с двоичными продуктами и отслеживают их состояние.
Среда Git неплохо приспособлена для работы с двоичными файлами, но особой эффективности ожидать не стоит. По умолчанию Git сжимает и сохраняет все последующие полные версии двоичных файлов, что не оптимально, если файлов много.
Ситуацию можно улучшить с помощью нескольких простых настроек. Так, можно запустить сборщик мусора git gc или настроить использование разностных коммитов для некоторых типов двоичных файлов в .gitattributes.
Но для того чтобы выбрать успешный подход, важно учесть характер двоичных файлов в проекте. Вот несколько подсказок.
- Разностное сжатие, вероятнее всего, окажется бесполезным, если значительно изменяются сами двоичные файлы, а не просто заголовки метаданных. Укажите для таких файлов -delta, чтобы не выполнять разностное сжатие при переупаковке, когда это нецелесообразно.
- В приведенном выше сценарии файлы вряд ли подходят и для сжатия с помощью zlib, поэтому имеет смысл отключить сжатие, указав core.compression 0 или core.loosecompression 0. Это глобальная настройка, поэтому поместите двоичные файлы в отдельный репозиторий, если возможность сжатия нужно сохранить для других файлов, для которых она более актуальна.
- Важно помнить, что команда git gc упаковывает «повторяющиеся» свободные объекты в один файл, однако такой пакет не сэкономит много места без сжатия файлов внутри.
- Попробуйте изменить параметр core.bigFileThreshold. По умолчанию любые файлы размером более 512 МБ не подвергаются разностному сжатию (без внесения изменений в .gitattributes). Возможно, корректировка порогового значения позволит сэкономить ресурсы.
Решение для больших деревьев папок: git sparse-checkout
Смягчить проблему двоичных файлов помогает выборочное переключение — sparse-checkout (доступно начиная с Git 1.7.0). Этот метод позволяет явно указать папки, которые нужно заполнить, и не засорять рабочий каталог. К сожалению, использование sparse-checkout никак не повлияет на общий размер локального репозитория, но зато облегчит работу с «ветвистым» деревом папок.
Для этого можно использовать, например, следующие команды.
- Клонируйте полный репозиторий один раз: git clone
- Активируйте функцию: git config core.sparsecheckout true
- Добавьте нужные папки явным образом, игнорируя папки с файлами:
- echo src/ › .git/info/sparse-checkout
- Считайте дерево таким образом:
- git read-tree -m -u HEAD
После этих действий вы сможете вернуться к выполнению обычных команд Git, но рабочий каталог будет содержать только заданные выше папки.
Решение для управления обновлением больших файлов: подмодули
[ОБНОВЛЕНИЕ] …А еще можно забыть все, что вы прочитали выше, и воспользоваться Git LFS
Если вы регулярно работаете с большими файлами, лучшим выходом может стать поддержка больших файлов (LFS) — решение, разработанное Atlassian совместно с GitHub в 2015 году. (Да, все верно: мы объединились с GitHub, чтобы реализовать проект Git с открытым исходным кодом.)
Расширение Git LFS позволяет хранить в репозитории не сами большие файлы, а только (естественно!) указатели на них. Сами же файлы хранятся на удаленном сервере. Как нетрудно догадаться, время клонирования репозитория благодаря этому значительно уменьшается.
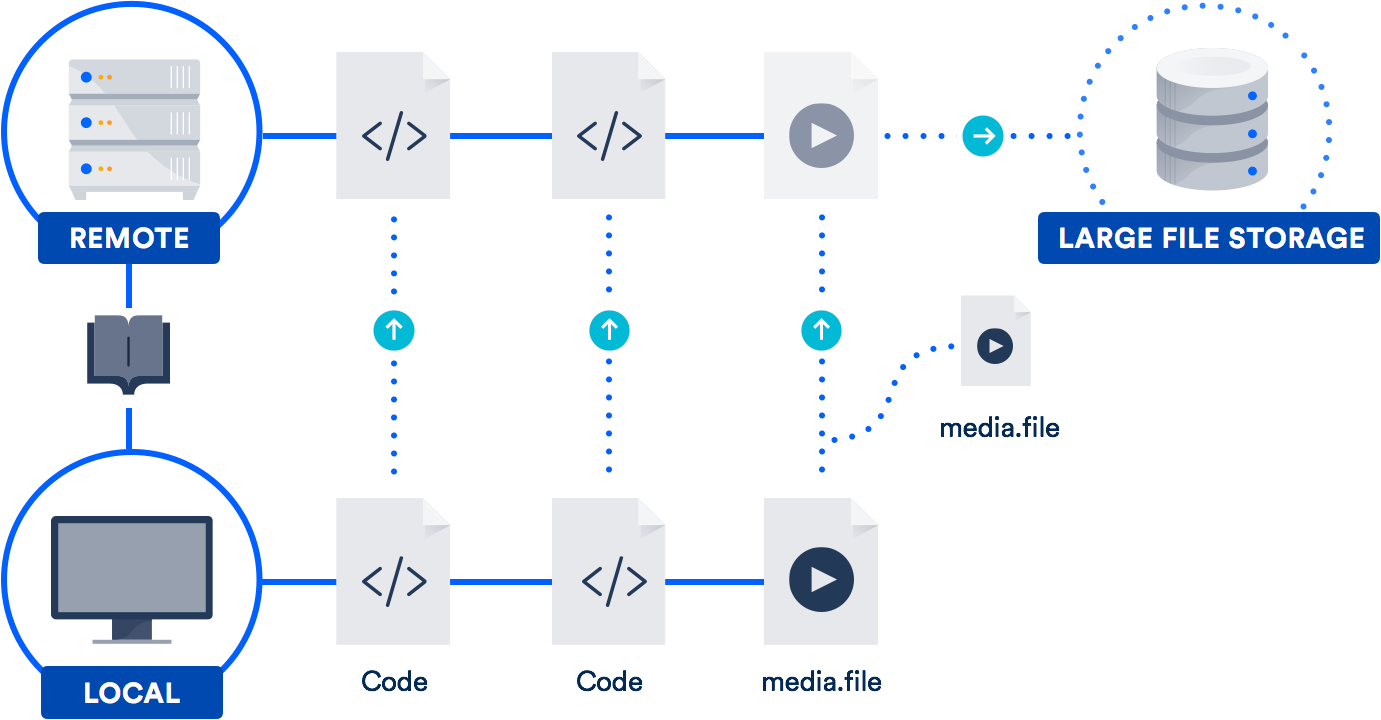
Bitbucket, как и GitHub, тоже поддерживает Git LFS, так что технология вам, скорее всего, уже доступна. Она особенно полезна для команд, в которых трудятся дизайнеры, видеооператоры, музыканты или пользователи САПР.
Заключение
Не отказывайтесь от потрясающих возможностей Git только из-за большой истории репозитория или огромных файлов. Обе эти проблемы можно эффективно решить.
Перейдите по ссылкам в этом тексте, чтобы прочитать другие статьи и узнать больше о подмодулях, зависимостях проектов и о решении Git LFS. А если хотите освежить в памяти команды или рабочий процесс, вам доступно множество учебных руководств на нашем микросайте, посвященном Git. Удачного программирования!
Поделитесь этой статьей
Следующая тема
Рекомендуемые статьи
Добавьте эти ресурсы в закладки, чтобы изучить типы команд DevOps или получать регулярные обновления по DevOps в Atlassian.

Блог Bitbucket

Образовательные программы DevOps
