Comment gérer les dépôts volumineux avec Git

Nicola Paolucci
Expert en développement
Git est une alternative fantastique pour suivre l'évolution de votre base de code et pour collaborer efficacement avec vos pairs. Mais que se passe-t-il si le dépôt dont vous voulez faire le suivi est vraiment gigantesque ?
Dans ce billet, je vais vous donner quelques techniques pour gérer cette situation.
Deux catégories de dépôts volumineux
Quand on y pense, les dépôts grossissent considérablement pour deux grandes raisons :
- Ceux-ci accumulent un historique très long (le projet grossit au fil du temps et les éléments s'accumulent).
- Ils incluent des actifs binaires volumineux qu'il faut suivre et apparier avec le code.
… Ou les deux raisons ci-dessus.
Parfois, un autre type de problème se pose : d'anciens artefacts binaires obsolètes sont encore stockés dans le dépôt. Toutefois, il existe un moyen relativement simple, mais pénible, pour corriger ce bug (voir ci-dessous).
Les techniques et les solutions de contournement pour chaque scénario sont différentes, bien que parfois complémentaires. Je vais donc les aborder séparément.
Clonage des dépôts avec un historique très long
Même si le seuil pour qualifier un dépôt de « massif » est assez élevé, il est toujours difficile de le cloner. Et vous ne pouvez pas toujours éviter les longs historiques. Certains dépôts doivent être conservés pour des raisons juridiques ou réglementaires.
Une solution simple : un clone Git superficiel
La première solution pour réaliser un clonage rapide, et pour faire gagner du temps et de l'espace disque aux développeurs et aux systèmes est de ne copier que les révisions récentes. L'option de clonage superficiel de Git vous permet de faire uniquement un pull des n derniers commits de l'historique du dépôt.
Comment faire ? Utilisez simplement l'option --depth, par exemple :
git clone --depth [depth] [remote-url]
Imaginez que vous ayez accumulé dix années d'historique (ou plus) dans votre dépôt. Par exemple, nous avons effectué une migration de Jira (une base de code vieille de 11 ans) vers Git. Les gains de temps pour de tels dépôts peuvent s'additionner et devenir substantiels.
Le clone complet de Jira pèse 677 Mo (avec un répertoire de travail de 320 Mo supplémentaires), ce qui représente plus de 47 000 commits. Un clone superficiel du dépôt prend 29,5 secondes, contre 4 minutes 24 secondes pour un clone complet avec tout l'historique. L'avantage augmente proportionnellement au nombre d'actifs binaires que votre projet a intégrés au fil du temps.
Ressource connexe
Comment déplacer un dépôt Git complet
DÉCOUVRIR LA SOLUTION
Découvrir Git avec Bitbucket Cloud
Conseil : le développement de systèmes connectés à votre dépôt Git bénéficie également des clones superficiels !
Les clones superficiels étaient souvent considérés comme des moutons noirs dans le monde de Git, car certaines opérations étaient à peine prises en charge. Toutefois, les versions récentes (1.9 et versions ultérieures) ont grandement amélioré la situation, et vous pouvez à présent réaliser des opérations de pull et de push efficaces sur les dépôts, même à partir d'un clone superficiel.
Une solution chirurgicale : la commande git filter-branch
Pour les dépôts volumineux dans lesquels des fichiers binaires inutiles ont été commités par mégarde ou qui contiennent d'anciens actifs inutiles, l'utilisation de git filter-branch est la solution idéale. La commande permet de parcourir l'historique entier du projet en filtrant, en modifiant et en ignorant des fichiers en fonction de modèles prédéfinis.
C'est un outil très puissant une fois que vous avez identifié les emplacements où votre dépôt est lourd. Des scripts d'aide sont disponibles pour identifier les gros objets. Cette partie devrait donc être assez facile.
La syntaxe est la suivante :
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'git filter-branch présente un léger inconvénient : lorsque vous utilisez la commande _filter-branch_, vous réécrivez en fait tout l'historique de votre projet. Cela signifie que tous les identifiants de commit changent et que tous les développeurs doivent de nouveau cloner le dépôt mis à jour.
Par conséquent, si vous prévoyez d'effectuer un nettoyage avec git filter-branch, avertissez votre équipe, planifiez une brève interruption pendant l'opération, puis prévenez tout le monde qu'il est nécessaire de cloner à nouveau le dépôt.
Conseil : vous trouverez plus d'informations sur git filter-branch dans ce billet sur le découpage de votre dépôt Git.
Une solution alternative à git shallow-clone : cloner une seule branche
Depuis la version git 1.7.10, vous pouvez également limiter la taille de l'historique cloné en ne clonant qu'une branche. Pour cela, procédez comme suit :
git clone [remote url] --branch [branch_name] --single-branch [folder]Ce hack spécifique s'avère utile lorsque vous travaillez avec des branches longues et divergentes, ou si vous avez de nombreuses branches et que vous n'avez besoin de travailler qu'avec quelques-unes d'entre elles. Si vous n'avez que quelques branches, comprenant un nombre limité de différences, vous ne constaterez probablement pas de grand changement lorsque vous utiliserez cette commande.
Gérer les dépôts comprenant des actifs binaires volumineux
Le deuxième type de dépôt volumineux est celui qui comporte d'énormes actifs binaires. C'est un problème que rencontrent de nombreux types d'équipes logicielles (et non logicielles !). Les équipes de conception de jeux doivent jongler avec d'énormes modèles 3D. Les équipes de développement web peuvent avoir besoin de suivre des ressources d'images RAW. Les équipes de CAO peuvent avoir besoin de manipuler et de suivre le statut de livrables binaires.
Git n'est pas spécialement inadapté à la manipulation d'actifs binaires, mais ce n'est pas non plus sa spécialité. Par défaut, Git compressera et stockera toutes les versions ultérieures des actifs binaires, ce qui n'est évidemment pas optimal si vous en avez beaucoup.
Certains changements basiques améliorent la situation, par exemple, l'exécution du processus de nettoyage « garbage collection » (« git gc ») ou la modification de l'utilisation des commits delta pour certains types binaires dans .gitattributes.
Mais il est important de réfléchir à la nature des actifs binaires de votre projet, car cela vous aidera à déterminer la meilleure approche. Par exemple, voici quelques points à vérifier :
- Pour les fichiers binaires qui changent beaucoup (pas seulement quelques en-têtes de métadonnées), la compression delta sera probablement inutile. Il est donc recommandé d'exécuter la commande delta off pour ces fichiers afin d'éviter l'exécution inutile de la compression delta lors du recompactage.
- Dans le cas ci-dessus, il est probable que la compression zlib de ces fichiers ne soit pas très efficace. Vous pouvez donc désactiver la compression avec « core.compression 0 » ou « core.loosecompression 0 ». Il s'agit d'un paramètre global qui se répercutera sur tous les fichiers non binaires pour lesquels la compression actuelle se déroule parfaitement. Ceci n'est par conséquent pertinent que si vous placez les actifs binaires dans un dépôt distinct.
- Il est important de garder à l'esprit que « git gc » transforme les objets bruts « dupliqués » en un fichier groupé unique. Mais, le fichier groupé ainsi obtenu ne sera pas tellement différent, sauf si les fichiers sont compressés d'une quelconque façon.
- Découvrez la personnalisation de « core.bigFileThreshold ». La compression delta ne fonctionnera quoi qu'il en soit pas pour les fichiers de plus de 512 Mo (sans nécessité de définir .gitattributes), c'est donc une fonctionnalité qu'il serait intéressant de modifier.
Une solution pour les grandes arborescences de dossiers : la commande git sparse-checkout
La commande sparse-checkout contribue à résoudre le problème des actifs binaires (disponible depuis Git 1.7.0). Cette technique permet de nettoyer le répertoire de travail en détaillant précisément les dossiers que vous souhaitez renseigner. Malheureusement, cela n'affecte pas la taille du dépôt local général, mais peut être utile si vous disposez d'une importante arborescence de dossiers.
Quelles sont les commandes impliquées ? Voici un exemple :
- Cloner une fois le dépôt complet : « git clone »
- Activer la fonctionnalité : git config core.sparsecheckout true
- Ajouter les dossiers qui sont explicitement requis, en ignorant les dossiers assets :
- echo src/ › .git/info/sparse-checkout
- Lire l'arborescence comme spécifié :
- git read-tree -m -u HEAD
Vous pouvez ensuite revenir à vos commandes Git habituelles, mais votre répertoire de travail ne contiendra que les dossiers spécifiés auparavant.
Solution pour contrôler la mise à jour des fichiers volumineux : submodules
[MISE À JOUR] …ou vous pouvez oublier tout cela et utiliser Git LFS
Si vous utilisez régulièrement des fichiers volumineux, la meilleure solution est peut-être d'exploiter l'extension Large File Storage (LFS) codéveloppée par Atlassian et GitHub en 2015. (Oui, vous avez bien lu. Nous nous sommes associés à GitHub pour apporter une contribution open source au projet Git.)
Git LFS est une extension qui stocke des pointeurs (évidemment !) vers des fichiers volumineux dans votre dépôt, au lieu de stocker les fichiers eux-mêmes. Les fichiers réels sont stockés sur un serveur distant. Comme vous pouvez l'imaginer, cela réduit considérablement le temps nécessaire pour cloner votre dépôt.
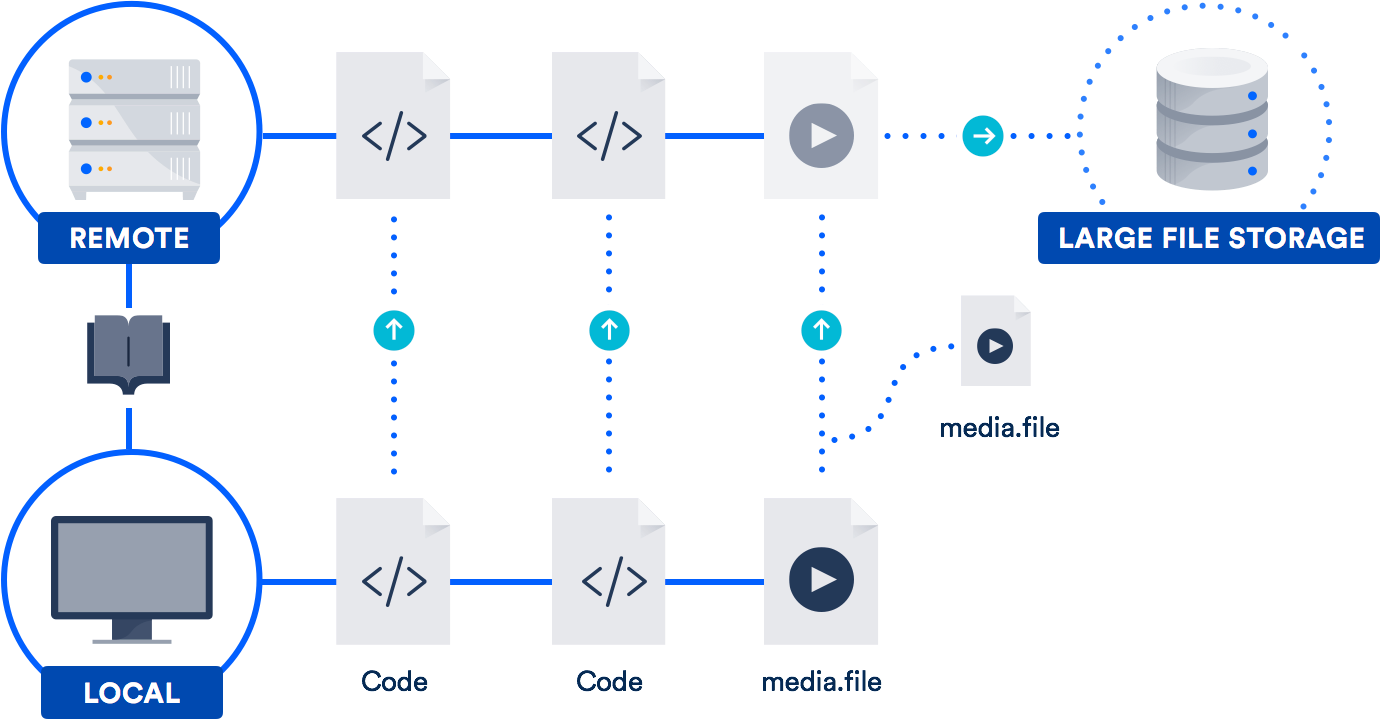
Comme GitHub, Bitbucket prend en charge Git LFS. Il est donc probable que vous ayez déjà accès à cette technologie. Elle est particulièrement utile pour les équipes comprenant des concepteurs, des vidéastes, des musiciens ou des utilisateurs de CAO.
Conclusions
Ne laissez pas le volume de votre historique de dépôt et de vos fichiers vous priver des incroyables fonctionnalités de Git. Il est possible de résoudre chacun de ces problèmes.
Consultez les autres articles auxquels j'ai fait référence ci-dessus pour plus d'informations sur les submodules, les dépendances de projet et Git LFS. Et pour des rappels sur les commandes et le workflow, notre microsite Git propose de nombreux tutoriels. Bon codage !
Partager cet article
Thème suivant
Lectures recommandées
Ajoutez ces ressources à vos favoris pour en savoir plus sur les types d'équipes DevOps, ou pour les mises à jour continues de DevOps chez Atlassian.

Le blog Bitbucket

Parcours de formation DevOps
