Dépôts monolithiques dans Git
Qu'est-ce qu'un dépôt monolithique ?
Les définitions varient, mais nous définissons un dépôt monolithique comme suit :
- Le dépôt contient plusieurs projets logiques (par exemple, un client iOS et une application web).
- Ces projets sont très probablement indépendants, peu connectés ou peuvent être connectés par d'autres moyens (par exemple via des outils de gestion des dépendances).
- Le dépôt est volumineux à différents égards :
- Nombre de commits
- Nombre de branches et/ou tags
- Nombre de fichiers suivis
- Taille du contenu suivi (mesurée en regardant le répertoire .git du dépôt)
Facebook a un tel exemple de dépôt monolithique :
Avec des milliers de commits par semaine sur des centaines de milliers de fichiers, le principal dépôt source de Facebook est extrêmement volumineux, bien plus volumineux que le noyau Linux, qui comptait 17 millions de lignes de code et 44 000 fichiers en 2013.
Ressource connexe
Comment déplacer un dépôt Git complet
DÉCOUVRIR LA SOLUTION
Découvrir Git avec Bitbucket Cloud
Et lors des tests de performance, le dépôt de tests utilisé par Facebook était le suivant :
- 4 millions de commits
- Historique linéaire
- Environ 1,3 million de fichiers
- La taille du répertoire .git était d'environ 15 Go
- La taille du fichier d'index était de 191 Mo
Défis conceptuels
Dans Git, la gestion de projets indépendants dans un dépôt monolithique pose de nombreux défis conceptuels.
Tout d'abord, Git suit l'état de toute l'arborescence dans chaque commit effectué. Cela convient parfaitement aux projets individuels ou connexes, mais devient difficile à gérer pour un dépôt contenant de nombreux projets indépendants. Pour faire simple, les commits dans des parties indépendantes de l'arborescence affectent le subtree qui intéresse un développeur. Ce problème est particulièrement accentué lorsqu'un grand nombre de commits font évoluer l'historique de l'arborescence. Lorsque la pointe de la branche change en permanence, il faut fréquemment merger ou rebaser localement pour pusher les changements.
Dans Git, un tag est un alias nommé pour un commit particulier, qui fait référence à l'arborescence entière. Mais l'utilité des tags diminue dans le contexte d'un dépôt monolithique. Posez-vous la question suivante : si vous travaillez sur une application web déployée en continu dans un dépôt monolithique, quelle est la pertinence du tag de version pour le client iOS versionné ?
Problèmes de performance
Outre ces défis conceptuels, de nombreux problèmes de performance peuvent affecter la configuration d'un dépôt monolithique.
Nombre de commits
La gestion d'un nombre important de projets indépendants dans un dépôt unique peut s'avérer problématique au niveau des commits. Au fil du temps, cela peut entraîner un grand nombre de commits avec un taux de croissance significatif (Facebook cite « des milliers de commits par semaine »). Cela devient particulièrement gênant lorsque Git utilise un graphe orienté acyclique (DAG) pour représenter l'historique d'un projet. Avec un grand nombre de commits, toute commande qui parcourt le graphe peut être ralentie au fur et à mesure que l'historique s'agrandit.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Nombre de réfs
La présence de nombreuses réfs (c'est-à-dire des branches ou des tags) dans votre dépôt monolithique affecte les performances de plusieurs manières.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
User time (seconds): 146.44*
* Cela varie en fonction des caches de pages et de la couche de stockage sous-jacente.
Nombre de fichiers suivis
L'index ou le cache du répertoire (.git/index) suit tous les fichiers de votre dépôt. Git utilise cet index pour déterminer si un fichier a été changé en exécutant stat(1) sur chaque fichier et en comparant les informations de changement du fichier avec les informations contenues dans l'index.
Ainsi, le nombre de fichiers suivis a un impact sur les performances* de nombreuses opérations :
- La commande
git statuspeut être lente (avec des statistiques pour chaque fichier unique, le fichier d'index sera volumineux). - La commande
git commitpourrait également être lente (avec des statistiques également pour chaque fichier unique).
* Cela varie en fonction des caches de pages et de la couche de stockage sous-jacente, et n'est perceptible que lorsqu'il y a un grand nombre de fichiers, de l'ordre de dizaines ou de centaines de milliers.
Fichiers volumineux
Les fichiers volumineux d'un seul subtree/projet affectent les performances de l'ensemble du dépôt. Par exemple, les ressources multimédias volumineuses ajoutées à un projet client iOS dans un dépôt monolithique sont clonées même si un développeur (ou un agent de build) travaille sur un projet indépendant.
Effets combinés
Qu'il s'agisse du nombre de fichiers, de leur fréquence de changement ou de leur taille, ces problèmes combinés ont un impact accru sur les performances :
- Le basculement entre les branches/tags, très utile dans un contexte de subtree (par exemple, le subtree sur lequel je travaille), met toujours à jour l'arborescence entière. Ce processus peut être lent en raison du nombre de fichiers concernés ou nécessite une solution de contournement. Par exemple, si vous utilisez
git checkout ref-28642-31335 -- templates, le répertoire./templatesest mis à jour pour correspondre à la branche donnée, maisHEADn'est pas mis à jour, ce qui a pour effet secondaire de marquer comme changés les fichiers mis à jour dans l'index. - Le clonage et le fetch ralentissent et consomment beaucoup de ressources sur le serveur étant donné que toutes les informations sont condensées dans un fichier groupé avant le transfert.
- La commande garbage collection est lente et déclenchée par défaut lors d'un push (si cette commande est nécessaire).
- L'utilisation des ressources est élevée pour chaque opération impliquant la (re)création d'un fichier groupé, par exemple :
git upload-pack, git gc.
Stratégies d'atténuation
Ce serait formidable si Git pouvait prendre en charge le cas d'utilisation particulier que sont les dépôts monolithiques, mais les objectifs de conception de Git qui ont fait son succès et sa popularité sont parfois en contradiction avec le désir de l'utiliser d'une manière pour laquelle il n'a pas été conçu. La bonne nouvelle pour la grande majorité des équipes ? Les dépôts monolithiques de très grande taille sont plutôt l'exception que la règle. Ainsi, aussi intéressant que soit ce billet, il ne s'appliquera probablement pas à une situation à laquelle vous êtes confronté.
Cela dit, il existe une série de stratégies d'atténuation qui peuvent aider lorsque vous travaillez avec de grands dépôts. Pour les dépôts avec de longs historiques ou des actifs binaires volumineux, mon collègue Nicola Paolucci décrit quelques solutions de contournement.
Suppression de réfs
Si votre dépôt contient des dizaines de milliers de réfs, vous devriez envisager de supprimer les réfs dont vous n'avez plus besoin. Le DAG conserve l'historique de l'évolution des changements, tandis que les commits de merge pointent vers leurs parents afin que le travail effectué sur les branches puisse être retracé même si la branche n'existe plus.
Dans un workflow basé sur les branches, le nombre de branches au long cours que vous souhaitez conserver doit être faible. N'ayez pas peur de supprimer une branche de fonctionnalité à courte durée de vie après un merge.
Songez à supprimer toutes les branches qui ont été mergées dans une branche principale comme production. Il est toujours possible de retracer l'historique de l'évolution des changements, tant qu'un commit est accessible depuis votre branche principale et que vous avez mergé votre branche avec un commit de merge. Le message par défaut du commit de merge contient souvent le nom de la branche, ce qui vous permet de conserver cette information si nécessaire.
Gestion d'un grand nombre de fichiers
Si votre dépôt contient un grand nombre de fichiers (des dizaines ou des centaines de milliers), l'utilisation d'un stockage local rapide avec beaucoup de mémoire pouvant être utilisée comme cache tampon peut aider. Il s'agit d'un domaine qui nécessiterait des changements plus importants du client, similaires par exemple aux changements que Facebook a mis en œuvre pour Mercurial.
Cette approche utilise les notifications du système de fichiers pour enregistrer les changements de fichiers au lieu d'itérer tous les fichiers pour vérifier si l'un d'entre eux a changé. Une approche similaire (utilisant également watchman) a été évoquée pour Git, mais n'a pas encore été concrétisée.
Utilisation de Git Large File Storage (LFS)
Cette section a été mise à jour le 20 janvier 2016.
Pour les projets qui incluent des fichiers volumineux tels que des vidéos ou des graphiques, Git Large File Storage (LFS) est une option permettant de limiter leur impact sur la taille et les performances globales de votre dépôt. Au lieu de stocker des objets volumineux directement dans votre dépôt, Git LFS stocke un petit fichier d'espace réservé portant le même nom et contenant une référence à l'objet, lui-même stocké dans un grand magasin d'objets spécialisé. Git LFS s'intègre aux opérations de push, pull, check-out et fetch natives de Git pour gérer le transfert et la substitution de ces objets dans votre arborescence de travail de manière transparente. Cela signifie que vous pouvez travailler avec des fichiers volumineux dans votre dépôt comme vous le feriez normalement, sans être pénalisé par une taille de dépôt trop importante.
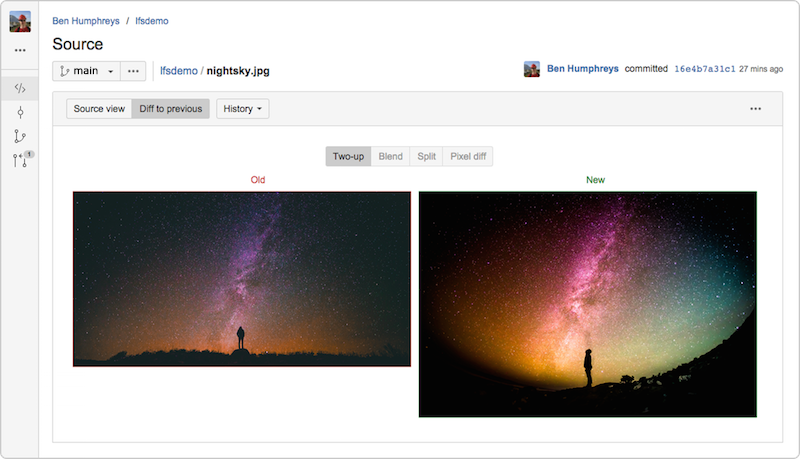
Bitbucket Server 4.3 (et versions ultérieures) intègre une implémentation de Git LFS v1.0+ entièrement conforme, et permet de prévisualiser et de différencier les grandes images suivies par LFS directement dans l'interface utilisateur de Bitbucket.
Mon collègue d'Atlassian Steve Streeting contribue activement au projet LFS et a récemment écrit sur le projet.
Identifiez les limites et scindez votre dépôt
La solution de contournement la plus radicale consiste à scinder votre dépôt monolithique en dépôts Git plus petits et plus ciblés. Essayez de ne pas suivre chaque changement dans un seul dépôt et identifiez plutôt les limites des composants, peut-être en déterminant les modules ou les composants qui ont un cycle de livraison similaire. Un bon test décisif pour identifier clairement les sous-composants consiste à utiliser des tags dans un dépôt et à voir s'ils sont utiles pour d'autres parties de l'arborescence source.
Ce serait formidable si Git prenait en charge les dépôts monolithiques de manière élégante, mais le concept de dépôt monolithique est légèrement contradictoire avec ce qui fait le succès et la popularité de Git. Toutefois, cela ne signifie pas que vous devez renoncer aux capacités de Git parce que vous avez un dépôt monolithique. Dans la plupart des cas, il existe des solutions viables à tous les problèmes qui surviennent.
Partager cet article
Thème suivant
Lectures recommandées
Ajoutez ces ressources à vos favoris pour en savoir plus sur les types d'équipes DevOps, ou pour les mises à jour continues de DevOps chez Atlassian.

Le blog Bitbucket

Parcours de formation DevOps
