Git으로 대규모 리포지토리를 다루는 방법

Nicola Paolucci
개발자 애드보케이트
Git은 코드베이스의 발전을 추적하고 동료와 효율적으로 공동 작업할 수 있는 훌륭한 선택입니다. 하지만 추적하려는 리포지토리가 너무 크면 어떻게 될까요?
이 글에서 몇 가지 해결 방법을 알려드리겠습니다.
대규모 리포지토리의 두 가지 범주
리포지토리가 커지는 이유는 크게 두 가지가 있습니다.
- 매우 긴 기록 축적(프로젝트는 매우 긴 기간에 걸쳐 늘어나고 기록이 축적됨)
- 코드와 함께 추적되고 사용되어야 하는 대규모 바이너리 자산이 포함됩니다.
...또는 둘 다일 수도 있습니다.
때때로 두 번째 유형의 문제는 더 이상 사용되지 않는 오래된 바이너리 아티팩트가 여전히 리포지토리에 저장되어 있다는 사실 때문에 복잡해집니다. 하지만 성가시더라도 비교적 쉽게 해결할 수 있는 방법이 있습니다(아래 참조).
각 시나리오에 대한 기법과 해결 방법은 서로 다르며 때로는 상호 보완적이기도 합니다. 따라서 별도로 다루도록 하겠습니다.
매우 긴 기록의 리포지토리 복제
리포지토리를 “대규모”라고 말하는 기준치는 꽤 높지만 리포지토리 복제는 여전히 어렵습니다. 그리고 긴 기록을 항상 피할 수는 없습니다. 일부 리포지토리는 법적 또는 규제상의 이유로 그대로 보관해야 합니다.
간단한 솔루션: Git 부분 복제
빠르게 복제하고 개발자 및 시스템의 시간과 디스크 공간을 절약하는 첫 번째 솔루션은 최근 수정본만 복사하는 것입니다. Git의 부분 복제 옵션을 사용하면 리포지토리 기록의 최신 n개 커밋만 풀다운할 수 있습니다.
이를 수행하는 방법은 –depth 옵션을 사용하는 것입니다. 예를 들면 다음과 같습니다.
git clone --depth [depth] [remote-url]
리포지토리에 10년 이상의 프로젝트 기록이 축적됐다고 가정해 봅시다. 예를 들어 Atlassian에서는 Jira(11년 된 코드베이스)를 Git으로 마이그레이션했으며 리포지토리에서 절감된 시간이 누적되어 눈에 띄는 효과를 경험할 수 있습니다.
Jira 전체 복제는 677MB이고 작업 디렉터리는 320MB로 47,000개 이상의 커밋을 차지합니다. 리포지토리의 부분 복제는 29.5초가 걸리고 전체 기록을 완전히 복제하면 4분 24초가 걸립니다. 또한 이러한 이점은 시간이 지남에 따라 프로젝트가 흡수한 바이너리 자산의 수에 비례하여 증가합니다.
관련 자료
전체 Git 리포지토리를 이동하는 방법
솔루션 보기
Bitbucket Cloud에서 Git에 대해 알아보기
팁: Git 리포지토리에 연결된 시스템을 구축해도 부분 복제의 이점을 누릴 수 있습니다.
부분 복제는 일부 작업이 거의 지원되지 않았기 때문에 Git 세계에서는 잘 사용되지 않았습니다. 하지만 최신 버전(1.9 이상)에서는 상황이 크게 개선되어 이제 부분 복제에서도 리포지토리로 적절하게 풀 및 푸시할 수 있습니다.
자세한 솔루션: Git 필터 브랜치
실수로 커밋한 많은 바이너리 크러프트를 포함하는 대규모 리포지토리 또는 더 이상 필요하지 않은 오래된 자산의 경우 git filter-branch를 사용하는 것이 좋습니다. 이 명령을 사용하면 사전 정의된 패턴에 따라 파일 필터링, 수정, 건너뛰기 등 프로젝트의 전체 기록을 살펴볼 수 있습니다.
이 명령은 리포지토리가 부담을 받는 부분을 확인한 경우 아주 강력한 도구입니다. 대규모 개체를 식별하는 데 사용할 수 있는 도우미 스크립트가 있으므로 어렵지 않을 것입니다.
구문은 다음과 같습니다.
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'하지만 git filter-branch에는 작은 단점이 있습니다. filter-branch를 사용하면 프로젝트의 전체 기록을 효과적으로 다시 작성할 수 있습니다. 즉, 모든 커밋 ID가 변경됩니다. 그러므로 모든 개발자가 업데이트된 리포지토리를 다시 복제해야 합니다.
따라서 git filter-branch를 사용하여 정리 작업을 수행할 계획이라면 팀에 알리고 작업을 진행하는 동안 단기 동결 계획을 세운 다음 모든 개발자에게 리포지토리를 다시 복제해야 한다는 사실을 알려야 합니다.
팁: git filter-branch에 대한 자세한 내용은 Git 리포지토리 파헤치기에 대한 이 글에서 확인하세요.
Git 부분 복제의 대안: 하나의 브랜치만 복제
Git 1.7.10부터 다음과 같이 단일 브랜치를 복제하여 복제하려는 기록의 양을 제한할 수도 있습니다.
git clone [remote url] --branch [branch_name] --single-branch [folder]이 특정 팁은 장기적으로 실행되는 다양한 브랜치에서 작업하거나 브랜치가 많으며 그 중 몇 개에서만 작업이 필요한 경우에 유용합니다. 차이가 거의 없는 브랜치 몇 개만 있다면 이 솔루션을 사용해도 큰 차이를 보지 못할 것입니다.
대규모 바이너리 자산이 있는 리포지토리 관리
대규모 리포지토리의 두 번째 유형은 대규모 바이너리 자산이 있는 리포지토리입니다. 이러한 리포지토리는 여러 유형의 소프트웨어 팀과 소프트웨어 분야 이외의 팀이 마주하게 됩니다. 게임 팀은 대규모 3D 모델을 다루어야 하고, 웹 개발 팀은 원시 이미지 자산을 추적해야 하며, CAD 팀은 바이너리 결과물의 상태를 조작하고 추적해야 할 수도 있습니다.
Git은 바이너리 자산을 다루는 데 딱히 나쁘지는 않지만 특별히 좋지도 않습니다. Git은 기본적으로 바이너리 자산의 모든 후속 전체 버전을 압축하고 저장하므로 바이너리 자산이 많을 경우 최적이라고 할 수 없습니다.
가비지 컬렉션(‘git gc’)을 실행하거나 .gitattributes에서 일부 바이너리 유형에 대한 델타 커밋의 사용 조정과 같이 상황을 개선하는 몇 가지 기본적인 조정이 있습니다.
하지만 성공적인 접근 방식을 결정하는 데 도움이 될 수 있으므로 프로젝트의 바이너리 자산 특성을 되돌아보는 것이 중요합니다. 예를 들어, 고려해야 할 몇 가지 사항은 다음과 같습니다.
- 일부 메타 데이터 헤더뿐만 아니라 크게 변경되는 바이너리 파일의 경우 델타 압축은 아마 쓸모가 없을 것이므로 델타 압축이 리패키징의 일부로 불필요하게 작동하지 않도록 해당 파일에 ‘델타 비활성화’ 를 사용하세요.
- 위 시나리오에서는 파일이 제대로 zlib 압축되지 않을 가능성이 높으므로 ‘core.compression 0’ 또는 ‘core.loosecompression 0’으로 압축을 비활성화할 수 있습니다. 실제로 압축이 잘 되는 바이너리 파일이 아닌 모든 파일에 부정적인 영향을 미치는 전역 설정이므로 바이너리 자산을 별도의 리포지토리로 분할하는 것이 좋습니다.
- ‘git gc’는 "복제된" 느슨한 개체를 단일 팩 파일로 변환하지만 파일이 압축되지 않는 한 결과로 만들어지는 팩 파일과 비교하여 큰 차이가 없다는 사실을 기억해야 합니다.
- ‘core.bigFileThreshold’ 튜닝을 탐색합니다. 512MB보다 큰 것은 .gitattributes 설정 없이는 델타 압축되지 않기 때문에 조정하는 것이 좋습니다.
대규모 폴더 트리를 위한 해결책: Git 스파스 체크아웃
바이너리 자산 문제에 있어서 Git의 스파스 체크아웃 옵션이 도움이 될 수 있습니다(Git 1.7.0부터 사용 가능). 이 기법을 사용하면 채우려는 폴더를 명시적으로 자세히 설명하여 작업 디렉터리를 깔끔하게 유지할 수 있습니다. 안타깝게도 전체 로컬 리포지토리의 크기에는 영향을 미치지 않지만, 대규모 폴더 트리가 있는 경우 도움이 될 수 있습니다.
관련된 명령은 무엇입니까? 예시는 다음과 같습니다.
- 전체 리포지토리 한 번 복제: 'git clone'
- 기능 활성화: ‘git config core.sparsecheckout true’
- 자산 폴더는 무시하고 명시적으로 필요한 폴더를 추가합니다.
- echo src/ › .git/info/sparse-checkout
- 지정된 대로 트리 읽기:
- git read-tree -m -u HEAD
위의 작업을 수행한 후 일반 Git 명령을 다시 사용할 수 있지만 작업 디렉터리에는 위에서 지정한 폴더만 포함됩니다.
대용량 파일 업데이트 시 제어를 위한 솔루션: 하위 모듈
[업데이트]... 또는 모두 건너뛰고 Git LFS 사용
대용량 파일로 정기적으로 작업하는 경우 가장 좋은 방법은 2015년 Atlassian이 GitHub와 공동 개발한 LFS(Large File Storage)를 활용하는 것입니다. (맞습니다. Atlassian은 Git 프로젝트에 오픈 소스 기여를 하기 위해 GitHub와 협력했습니다.)
Git LFS는 리포지토리의 대용량 파일에 파일 자체를 저장하는 대신 포인터를 저장하는 확장 기능입니다. 실제 파일은 원격 서버에 저장됩니다. 이렇게 하면 리포지토리를 복제하는 데 걸리는 시간이 대폭 줄어듭니다.
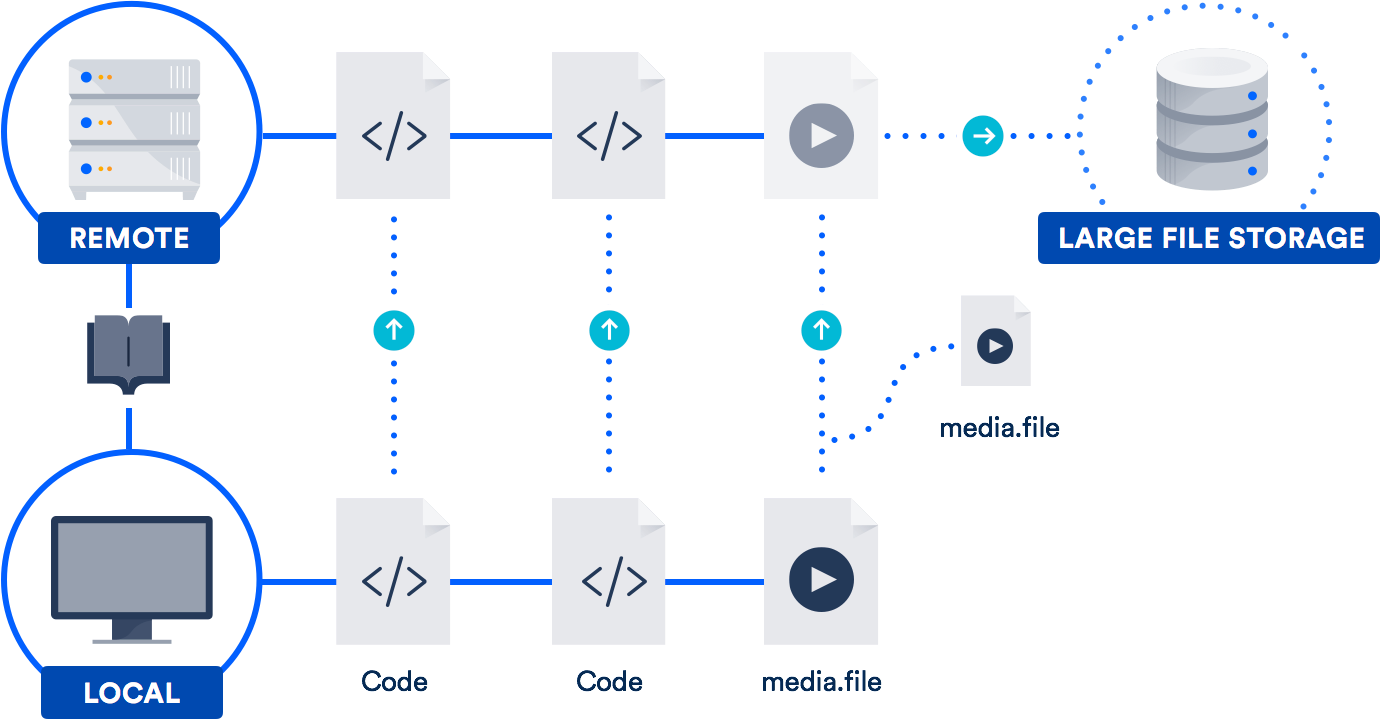
Bitbucket은 Git LFS를 지원하며 GitHub도 마찬가지입니다. 따라서 여러분은 이미 이 기술에 액세스할 수 있는 가능성이 높습니다. 디자이너, 비디오그래퍼, 음악가, CAD 사용자가 있는 팀에 특히 유용합니다.
결론
리포지토리 기록이 크거나 파일이 크다는 이유만으로 Git의 환상적인 기능을 포기하지 마세요. 두 가지 문제에 대한 실행 가능한 솔루션이 있습니다.
하위 모듈, 프로젝트 종속성, Git LFS에 대한 자세한 내용은 위에 링크한 다른 글에서 확인해 보세요. 명령과 워크플로에 대한 복습을 위해 Git 마이크로사이트에 수많은 자습서가 준비되어 있습니다. 즐겁게 코딩하세요!
이 문서 공유
다음 토픽
여러분께 도움을 드릴 자료를 추천합니다.
이러한 리소스에 책갈피를 지정하여 DevOps 팀의 유형에 대해 알아보거나 Atlassian에서 DevOps에 대한 지속적인 업데이트를 확인하세요.

Bitbucket 블로그

DevOps 학습 경로
