Repozytoria monolityczne w systemie Git
Czym jest monorepo?
Definicje repozytorium monolitycznego są różne, jednak my przyjmiemy następujące kryteria:
- Repozytorium zawiera więcej niż jeden projekt logiczny (np. klienta dla systemu iOS i aplikację sieciową).
- Projekty są najprawdopodobniej niepowiązane ze sobą, luźno połączone lub połączone przy użyciu innych środków (np. za pośrednictwem narzędzi do zarządzania zależnościami).
- Repozytorium jest duże pod wieloma względami:
- liczby commitów,
- liczby gałęzi i/lub tagów,
- Liczba śledzonych plików
- rozmiaru śledzonej zawartości (na podstawie miary katalogu .git repozytorium).
Jednym z przykładów takiego repozytorium monolitycznego jest to, które należy do Facebooka:
Główne repozytorium kodu źródłowego Facebooka wzbogacane o tysiące commitów z setkami tysięcy plików tygodniowo jest ogromne — wielokrotnie większe niż samo jądro Linuxa, które w 2013 roku składało się z 17 milionów wierszy kodu i 44 000 plików.
materiały pokrewne
Jak przenieść pełne repozytorium Git
POZNAJ ROZWIĄZANIE
Poznaj środowisko Git z rozwiązaniem Bitbucket Cloud
Podczas przeprowadzania testów wydajności repozytorium testowe używane przez serwis Facebook cechowały następujące parametry:
- 4 miliony commitów,
- historia liniowa,
- ~1,3 miliona plików,
- rozmiar katalogu .git wynoszący około 15 GB,
- rozmiar pliku indeksu wynoszący 191 MB.
Wyzwania koncepcyjne
Z zarządzaniem niepowiązanymi projektami w repozytorium monolitycznym w systemie Git wiąże się wiele wyzwań koncepcyjnych.
Po pierwsze system Git śledzi stan całego drzewa w każdym opracowanym commicie. To dobre rozwiązania w przypadku pojedynczych lub powiązanych projektów, jednak w repozytorium zawierającym wiele niepowiązanych projektów staje się ono nieporęczne. Upraszczając, commity w niepowiązanych częściach drzewa wpływają na drzewo podrzędne, które jest istotne dla programisty. Problem ten potęgują duże liczby commitów, które rozbudowują historię drzewa. Końcówka gałęzi stale się zmienia, dlatego wypychanie zmian wymaga częstego scalania lub lokalnego zmieniania bazy.
W systemie Git tag jest nazwanym aliasem konkretnego commita odnoszącym się do całego drzewa. Jednak przydatność tagów maleje w kontekście repozytoriów monolitycznych. Wystarczy zadać sobie następujące pytanie: na ile adekwatny jest tag wydania wersjonowanego klienta dla systemu iOS, jeśli pracujesz nad aplikacją sieciową, która jest stale wdrażana w repozytorium monolitycznym?
Problemy z wydajnością
Oprócz tych trudności koncepcyjnych, występują liczne problemy z wydajnością, które mogą wpływać na konfigurację repozytorium monolitycznego.
liczby commitów,
Zarządzanie niepowiązanymi projektami w jednym repozytorium na dużą skalę może okazać się problematyczne na poziomie commita. Z czasem może to prowadzić do powstania dużej liczby commitów o znacznym wskaźniku wzrostu (cytując Facebook: „tysięcy commitów tygodniowo”). Jest to szczególnie kłopotliwe w związku z faktem, że system Git wykorzystuje skierowany graf acykliczny (DAG) do przedstawiania historii projektu. Jeśli liczba commitów jest duża, każde polecenie przechodzące przez graf może ulegać spowolnieniu, im głębiej będzie się sięgać w historię.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Liczba odniesień
Duża liczba odniesień (tj. gałęzi lub tagów) w repozytorium monolitycznym wpływa na wydajność na wiele sposobów.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
Czas użytkownika (w sekundach): 146,44*
* Czas ten będzie się różnił w zależności od pamięci podręcznych stron i podstawowej warstwy pamięci.
Liczba śledzonych plików
Pamięć podręczna indeksu lub katalogu (.git/index) śledzi każdy plik w repozytorium. System Git wykorzystuje ten indeks do ustalenia, czy plik uległ zmianie, przez wykonanie polecenia stat(1) na każdym pliku z osobna i porównanie informacji o modyfikacji pliku z informacjami zawartymi w indeksie.
W ten sposób liczba śledzonych plików wpływa na wydajność* wielu operacji:
- Polecenie
git statusmoże działać powoli (oblicza statystyki każdego pliku, plik indeksu będzie duży). - Polecenie
git committakże może działać powoli (również oblicza statystyki każdego pliku).
* Efekt będzie różny w zależności od pamięci podręcznych stron i podstawowej warstwy pamięci. Obniżenie wydajności jest zauważalne w przypadku dużej liczby plików liczonych w dziesiątkach lub setkach tysięcy.
Duże pliki
Duże pliki w jednym drzewie podrzędnym lub projekcie wpływają niekorzystnie na wydajność całego repozytorium. Przykładowo duże zasoby multimedialne dodane do projektu klienta dla systemu iOS w repozytorium monolitycznym są klonowane, choć programista (lub agent kompilacji) pracuje nad zupełnie niepowiązanym projektem.
Efekty łączone
Bez względu na to, czy chodzi o liczbę plików, częstotliwość ich zmiany czy też rozmiar, połączenie ze sobą tych problemów dodatkowo zwiększa wpływ na wydajność:
- Przełączanie między gałęziami/tagami, które najlepiej sprawdza się w kontekście drzewa podrzędnego (np. drzewa podrzędnego, nad którym się pracuje), i tak powoduje aktualizację całego drzewa. Proces ten może przebiegać powoli ze względu na liczbę plików uwzględnionych w procesie i wymaga obejścia. Przykładowo polecenie
git checkout ref-28642-31335 -- templatesaktualizuje katalog./templatestak, aby był zgodny z daną gałęzią, ale bez aktualizacji gałęziHEAD, czego skutkiem ubocznym jest oznaczenie zaktualizowanych plików w indeksie jako zmodyfikowanych. - Klonowanie i pobieranie przebiega powoli i zużywa dużą ilość zasobów na serwerze, ponieważ wszystkie informacje zostają przed przesłaniem skondensowane w pliku pakietu.
- Usuwanie zbędnych elementów jest realizowane powoli i domyślnie wyzwalane przy wypychaniu (jeśli konieczne jest przeprowadzenie operacji usuwania zbędnych elementów).
- Użycie zasobów jest duże przy każdej operacji, która uwzględnia (ponowne) tworzenie pliku pakietu, np.
git upload-pack, git gc.
Strategie rozwiązywania problemów
Choć byłoby wspaniale, gdyby system Git obsługiwał szczególny przypadek użycia, jakim są repozytoria monolityczne, jego założenia projektowe, którym zawdzięcza tak ogromne powodzenie i popularność, czasem kłócą się z chęcią zastosowania tego systemu do celów, dla których nie został zaprojektowany. Dla większości zespołów dobra wiadomość jest jednak taka, że ogromne monolityczne repozytoria są raczej wyjątkiem niż regułą, zatem najprawdopodobniej ten post, choć (miejmy nadzieję) interesujący, nie będzie miał zastosowania w Twojej sytuacji.
Mając to na uwadze, można wskazać szereg strategii, które mogą pomóc w ograniczeniu problemów podczas pracy z dużymi repozytoriami. Mój kolega, Nicola Paolucci, opisuje kilka obejść problemów z repozytoriami o długich historiach i dużych zasobach binarnych.
Usuwanie odniesień
Jeśli Twoje repozytorium zawiera dziesiątki tysięcy odniesień, warto rozważyć usunięcie tych, które już nie są potrzebne. DAG zachowuje historię rozwoju zmian, podczas gdy scalane commity wskazują swoje elementy nadrzędne, umożliwiając prześledzenie prac wykonywanych w gałęziach nawet wtedy, gdy gałąź przestanie istnieć.
W przepływie pracy opartym na gałęziach liczba zachowywanych długofalowych gałęzi powinna być niewielka. Nie musisz obawiać się usuwania krótkoterminowych gałęzi funkcji po scaleniu.
Rozważ usuwanie wszystkich gałęzi, które zostały scalone z gałęzią główną, na przykład produkcyjną. Nie tracisz możliwości prześledzenia historii rozwoju zmian, o ile commit będzie osiągalny z poziomu gałęzi głównej, a Twoja gałąź została scalona przy użyciu funkcji scalania commitów. Domyślny komunikat scalonego commita często zawiera nazwę gałęzi, umożliwiając w razie potrzeby zachowanie tej informacji.
Obsługa dużej liczby plików
Jeśli Twoje repozytorium zawiera dużą liczbę plików (liczonych w dziesiątkach lub setkach tysięcy), pomocnym rozwiązaniem może być użycie szybkiego magazynu lokalnego o dużej pamięci w charakterze pamięci podręcznej buforu. Jest to obszar, który wymagałby bardziej znaczących zmian w kliencie, podobnie, jak w przypadku zmian, które Facebook wdrożył dla klienta Mercurial
Zastosowane podejście zakładało wykorzystanie powiadomień systemu plików do rejestrowania zmian w plikach zamiast iteracyjnej analizy wszystkich plików celem ustalenia, czy w którymś z nich wprowadzono zmiany. Prowadzono dyskusje nad przyjęciem podobnego podejścia (także z wykorzystaniem systemu watchman) w systemie Git, jednak nie przełożyły się one na żadne konkretne działania.
Korzystaj z funkcji przechowywania dużych plików (LFS) w systemie Git
Ta sekcja została zaktualizowana 20 stycznia 2016 roku
W przypadku projektów zawierających duże pliki, takie jak filmy lub grafiki, zastosowanie rozszerzenia Git LFS jest jedną z opcji pozwalających ograniczyć ich wpływ na rozmiar i ogólną wydajność repozytorium. Zamiast przechowywać duże obiekty bezpośrednio w repozytorium, Git LFS przechowuje mały plik zastępczy o takiej samej nazwie zawierający odniesienie do obiektu, który jako taki jest przechowywany w specjalistycznym magazynie dużych obiektów. Rozszerzenie Git LFS łączy się za pomocą skryptów z natywnymi operacjami systemu Git, takimi jak push, pull, checkout i fetch, umożliwiając przesyłanie i podstawianie tych obiektów w drzewie roboczym użytkownika w przejrzysty sposób. To oznacza, że możesz korzystać z dużych plików w repozytorium tak jak zazwyczaj, bez ryzyka nadmiernego rozrostu repozytorium.
System Bitbucket Server w wersji 4.3 (lub nowszej) zawiera osadzoną, w pełni zgodną implementację rozszerzenia Git LFS v1.0+, umożliwiając podgląd i rozróżnianie dużych zasobów obrazów śledzonych przez LFS bezpośrednio z poziomu interfejsu użytkownika Bitbucket.
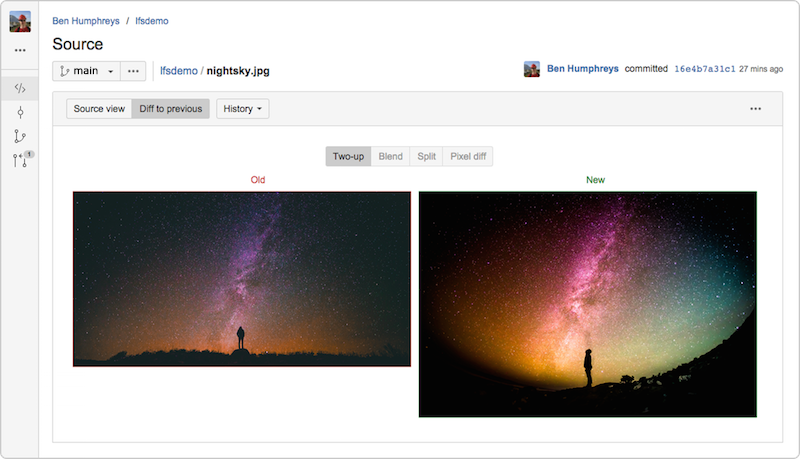
Mój kolega z Atlassian, Steve Streeting, aktywnie uczestniczy w rozwijaniu projektu LFS i ostatnio napisał artykuł na temat tego projektu.
Zidentyfikuj granice i podziel swoje repozytorium
Najbardziej radykalnym obejściem problemu będzie podzielenie monolitycznego repozytorium na mniejsze repozytoria Git o bardziej zawężonym zakresie. Postaraj się odejść od śledzenia każdej zmiany w jednym repozytorium, a zamiast tego wyznacz granice komponentów, na przykład przez ustalenie modułów lub komponentów o podobnych cyklach wydawania. Dobrym rodzajem prostego testu pozwalającego wyróżnić wyraźne komponenty podrzędne jest użycie tagów w repozytorium i ustalenie, czy mają one sens w odniesieniu do innych części drzewa źródłowego.
Choć wspaniale byłoby móc sprawnie zastosować system Git do repozytoriów monolitycznych, koncepcja takich repozytoriów jest nieco sprzeczna z założeniami, którym system Git zawdzięcza swoje powodzenie i popularność. Nie oznacza to jednak, że należy zrezygnować z możliwości, jakie oferuje system Git, tylko dlatego, że ma się repozytorium monolityczne — w większości przypadków istnieją realne rozwiązania pojawiających się problemów.
Udostępnij ten artykuł
Następny temat
Zalecane lektury
Dodaj te zasoby do zakładek, aby dowiedzieć się więcej na temat rodzajów zespołów DevOps lub otrzymywać aktualności na temat metodyki DevOps w Atlassian.

Blog Bitbucket

Ścieżka szkoleniowa DevOps
