CI/CD в Git: 5 советов по организации репозиториев Git с поддержкой непрерывной интеграции
Настройтесь на успех: все начинается с репозитория.

Сара Гофф-Дюпон
Главный писатель
Git и непрерывная поставка образуют одно из потрясающих сочетаний, которые иногда встречаются в мире ПО, — подобно маслу и варенью на бутерброде. Две технологии, великолепные сами по себе, отлично дополняют друг друга. Поэтому я хочу поделиться несколькими советами, которые позволяют обеспечить идеальное взаимодействие сборок Bamboo с хранилищами Bitbucket. Главным образом эти компоненты взаимодействуют на тех этапах непрерывной поставки, где происходят сборка и тестирование, поэтому в статье речь будет идти больше о непрерывной интеграции, чем о непрерывной поставке.
1. Храните большие файлы за пределами репозитория
Очень часто приходится слышать о Git такое утверждение: не следует помещать в репозиторий большие файлы: бинарные и мультимедийные файлы, архивные артефакты и т. д. Это связано с тем, что после добавления файла он всегда будет присутствовать в истории репозитория, а значит, при каждом клонировании репозитория огромный файл будет клонироваться вместе с ним.
Извлечь файл из истории репозитория не так просто: это как операция лоботомии на базе кода. Такой хирургический способ извлечения файлов меняет всю историю репозитория, поэтому вы теряете четкую картину того, какие изменения были сделаны и когда. Достаточно причин, чтобы «избегать больших файлов» стало вашим правилом. И поэтому...
Для непрерывной интеграции принципиально важно хранить крупные файлы вне репозиториев Git
При каждой сборке серверу непрерывной интеграции необходимо клонировать репозиторий в рабочий каталог сборки. Если в вашем репозитории слишком много крупных артефактов, этот процесс замедляется, а значит, разработчикам приходится дольше ждать результатов сборки.
Ладно, пусть так. Но что если ваша сборка зависит от бинарных файлов из других проектов или от крупных артефактов? Это очень распространенная ситуация, и, вероятно, она будет существовать всегда. Отсюда вопрос: как мы можем эффективно с этим справиться?
См. решение
Разработка и эксплуатация программного обеспечения с помощью Open DevOps
Связанные материалы
Подробнее о магистральной разработке
Для хранения артефактов, которые создаются вашей командой или командами, взаимодействующими с вами, можно использовать внешнюю систему хранения, например Artifactory (у которой есть аддон для Bamboo), Nexus или Archiva. Нужные файлы можно загружать в каталог сборки в начале процесса сборки — как и сторонние библиотеки, которые вы загружаете через Maven или Gradle.
Профессиональный совет. Если артефакты часто меняются, избегайте соблазна синхронизировать большие файлы с сервером сборки каждую ночь, так чтобы во время сборки они перемещались только в пределах диска. В этом случае в промежутках между ночными синхронизациями сборка будет выполняться с устаревшими версиями артефактов. Кроме того, эти файлы все равно будут нужны разработчикам для сборки на локальных рабочих станциях. Таким образом, самое разумное, что можно предпринять, — просто сделать загрузку артефактов частью сборки.
Если в вашей сети нет внешней системы хранения, проще всего будет воспользоваться поддержкой больших файлов в Git (LFS).
Git LSF — это расширение, которое хранит в репозитории указатели на большие файлы, а не сами файлы. Сами файлы хранятся на удаленном сервере. Вы можете себе представить, насколько это сокращает время клонирования.
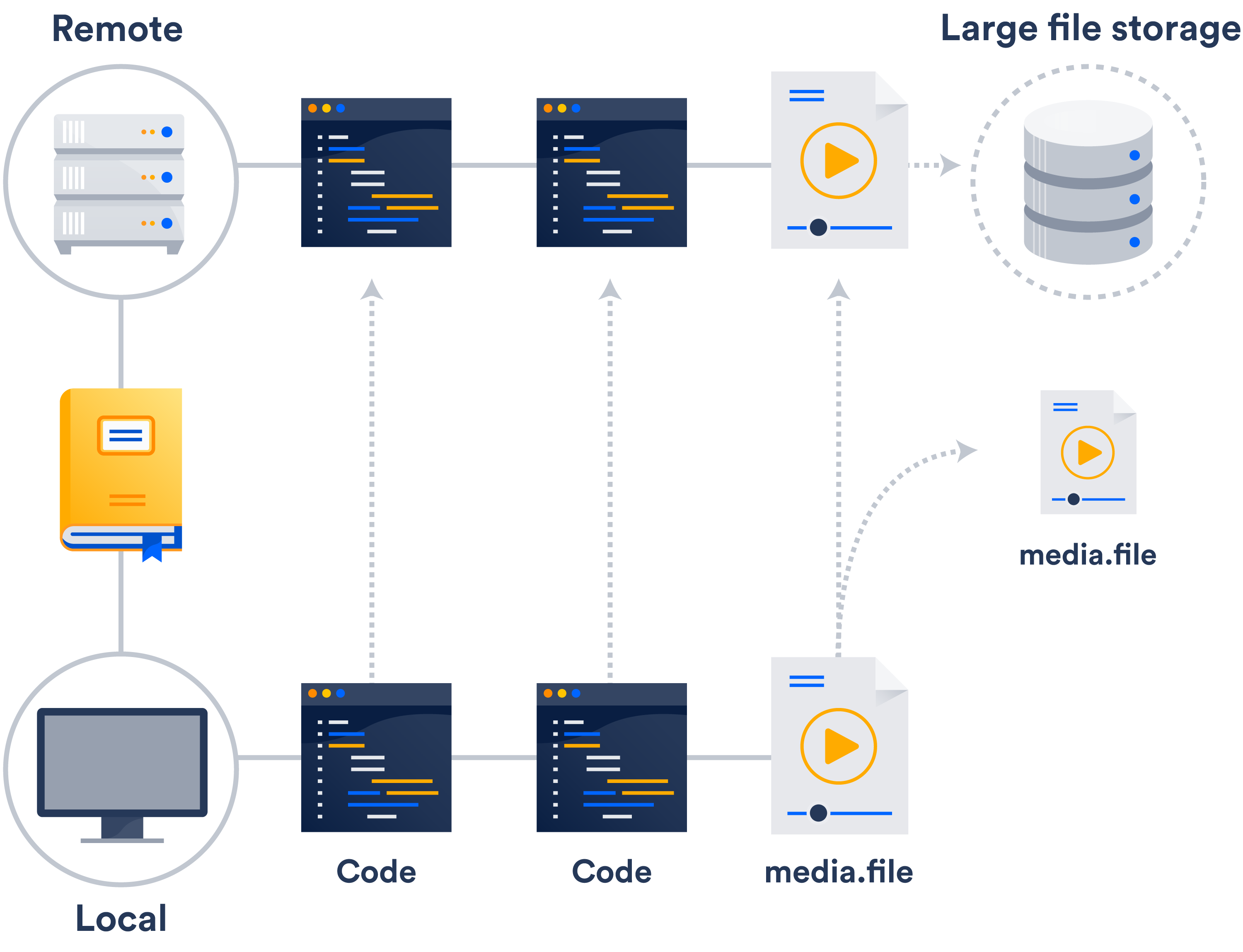
Скорее всего, у вас уже есть доступ к Git LFS: эту технологию поддерживает и Bitbucket, и Github.
2. Используйте поверхностные клоны для CI
При каждом выполнении сборки сервер сборки клонирует репозиторий в текущий рабочий каталог. Как я уже говорила, когда Git клонирует репозиторий, он по умолчанию клонирует всю историю репозитория. Поэтому, естественно, со временем эта операция будет выполняться все дольше.
При использовании поверхностного клонирования копироваться будет только текущее состояние вашего репозитория. Поэтому такой подход может быть весьма полезен для сокращения времени сборки, особенно при работе с большими и/или старыми репозиториями.
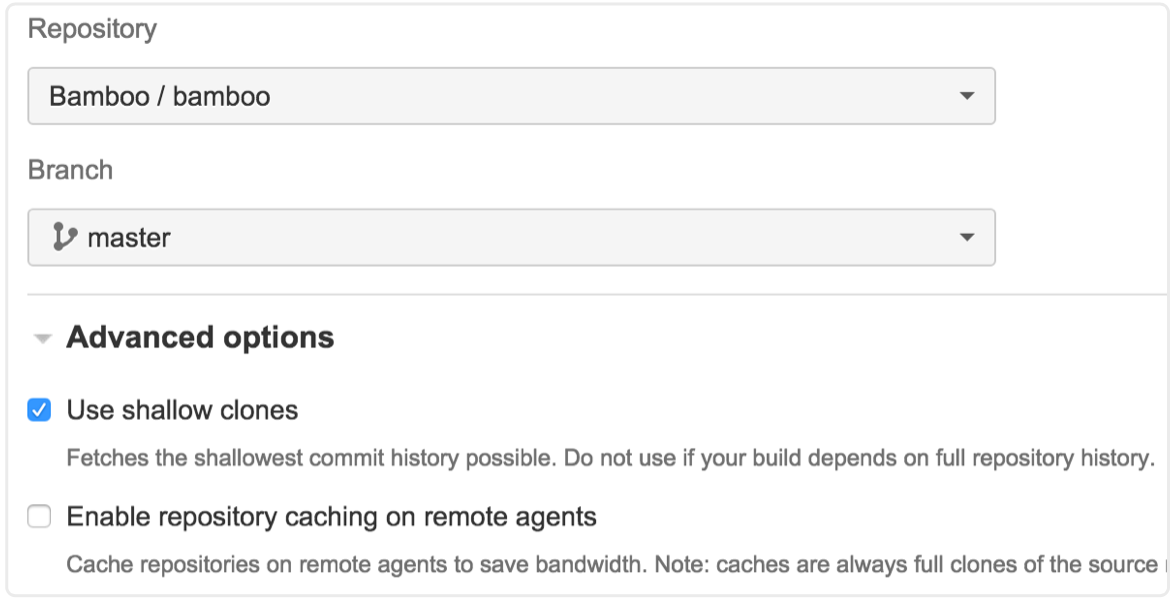
Но допустим, что ваша сборка требует полной истории репозитория. Например, на одном из этапов сборки обновляется номер версии в файле POM (или аналогичном файле) или вы выполняете слияние двух веток при каждой сборке. В перечисленных случаях требуется, чтобы Bamboo отправил изменения обратно в репозиторий.
Благодаря Git простые изменения файлов (например, обновление номера версии) можно отправлять при отсутствии полной истории. Однако для выполнения слияния по-прежнему требуется история репозитория, поскольку системе Git необходимо найти общего предка двух веток. Это будет проблемой, если в вашей сборке используется поверхностное клонирование. И это подводит нас к совету № 3.
3. Кэшируйте репозиторий на агентах сборки
Это также значительно ускоряет операцию клонирования (фактически Bamboo поступает так по умолчанию).
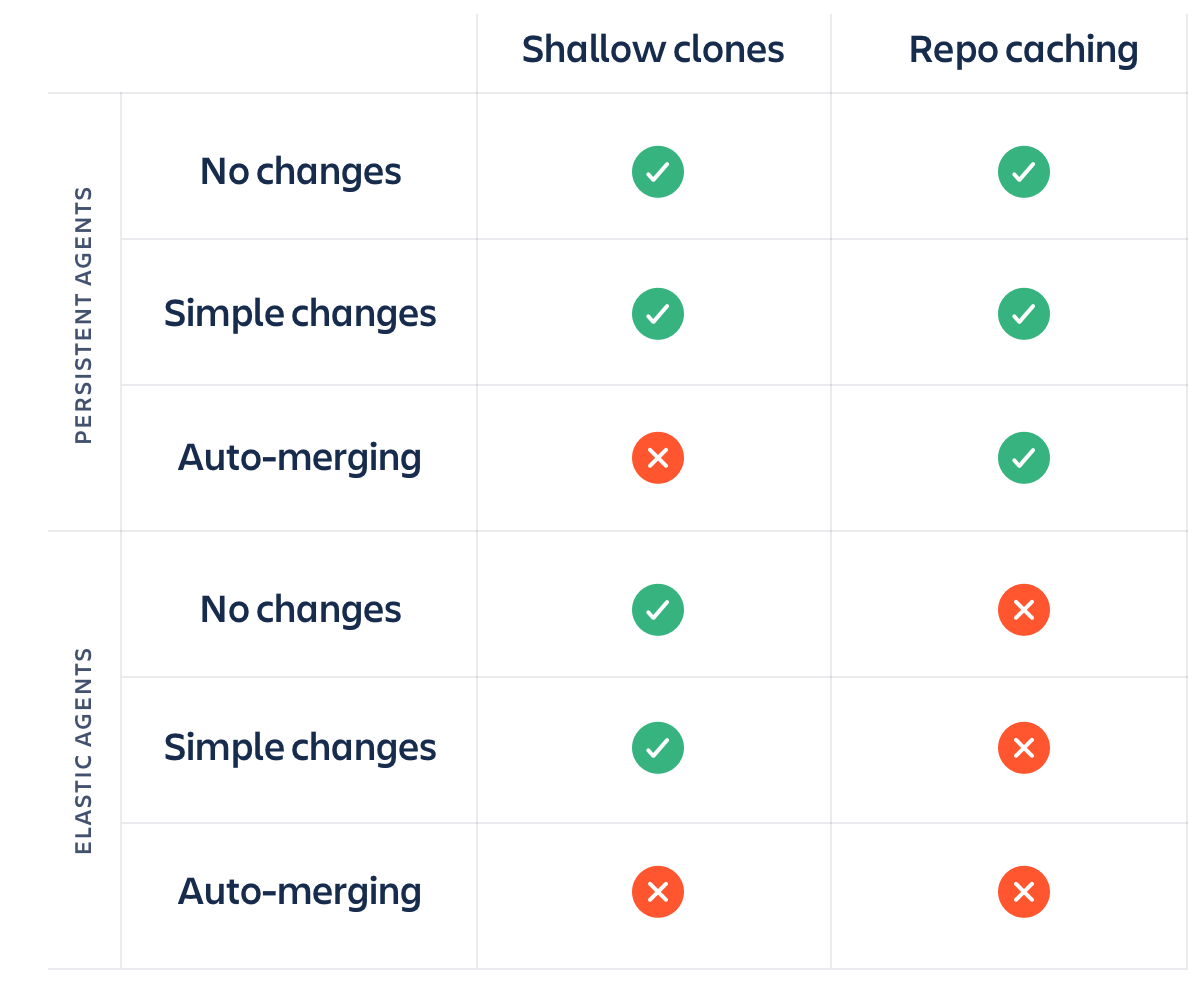
Обратите внимание, что кэширование репозитория дает преимущество только при использовании агентов, которые от сборки к сборке не меняются. Если при каждом запуске сборки вы создаете и уничтожаете агенты сборки в EC2 или другом облачном ресурсе, кэширование репозитория не будет иметь смысла, поскольку работа идет с пустым каталогом сборки, и каждый раз потребуется создавать полную копию репозитория.
Если рассмотреть поверхностное клонирование с кэшированием репозитория и добавить к этому выбор между постоянными или облачными агентами, получится интересная сетка факторов. Вот небольшая матрица, которая поможет вам выработать стратегию.
4. Продумывайте выбор триггеров
Это (почти) само собой разумеется: использование CI на всех активных ветках — хорошая идея. Но стоит ли запускать все сборки на всех ветках при любом коммите? Пожалуй, нет. И вот почему.
Возьмем, для примера, Atlassian. У нас более 800 разработчиков, каждый из которых отправляет изменения в репозиторий несколько раз в день (в основном изменения отправляются в собственные функциональные ветки). А это очень много сборок. И если отсутствует мгновенное и бесконечное масштабирование агентов сборки, это приводит к длительному ожиданию в очереди.
Один из наших внутренних серверов Bamboo содержит 935 различных планов сборки. Мы подключили 141 агент сборки к этому серверу и внедрили такие рекомендации, как передача артефактов и параллельное выполнение тестов, чтобы сделать каждую сборку максимально эффективной. Тем не менее сборка после каждой операции push приводила к тому, что работа застревала.
Можно было просто настроить еще один экземпляр Bamboo с дополнительными 100+ агентами, но мы притормозили и задались вопросом, действительно ли это необходимо. Ответ в итоге был отрицательным.
Таким образом мы даем разработчикам возможность запускать сборку принадлежащих им веток нажатием кнопки, а не выполняем сборку автоматически каждый раз. Это хороший способ обеспечить баланс между тщательным тестированием и экономией ресурсов: появляются большие возможности для экономии, поскольку именно в ветках происходит большая часть изменений.
Многим разработчикам нравится дополнительный контроль, который им обеспечивает сборка, запускаемая после нажатия кнопки. По их мнению, это естественным образом вписывается в рабочий процесс. Другие предпочитают не думать о том, когда запускать сборку, и использовать автоматические триггеры. Эффективно использовать можно любой из этих подходов. Важно то, что ветки в принципе нужно тестировать, а перед их слиянием с основным потоком кода необходимо убедиться, что сборка не содержит ошибок.

Однако важнейшие ветки, такие как главная ветка и ветки стабильного выпуска, — это отдельная история. Сборки там запускаются автоматически: либо путем опроса репозитория на предмет изменений, либо путем отправки push-уведомления из Bitbucket в Bamboo. Поскольку мы используем ветки разработки для всей незавершенной работы, единственными коммитами в главную ветку (теоретически) должны быть слияния веток разработки. К тому же это строки кода, из которых мы делаем релизы и создаем ветки разработки. Поэтому очень важно своевременно получать результаты тестов по каждому слиянию.
5. Прекратите опросы, используйте подключения
Опрос репозитория каждые несколько минут для обнаружения изменений — не слишком затратная операция для Bamboo. Но когда вы масштабируете проект до сотен сборок на тысячи веток, задействуя десятки репозиториев, сложность стремительно нарастает. Вместо того чтобы нагружать Bamboo всеми этими опросами, можно сделать так, чтобы из Bitbucket поступали сигналы об отправке изменений и необходимости сборки.
Обычно это делается путем добавления скрипта hook в репозиторий, но интеграция между Bitbucket и Bamboo выполняет настройку внутренних параметров автоматически. После того как эти два продукта будут связаны на серверном уровне, триггеры сборки, инициируемые из репозитория, будут Просто работать™ без лишней настройки. Каких-либо скриптов hook или специальной конфигурации не потребуется.
Независимо от используемых инструментов триггеры, инициируемые из репозитория, имеют преимущество: они автоматически исчезают, когда целевая ветка становится неактивной. Иными словами, вам не придется расходовать ресурсы процессора системы CI на опрос сотен заброшенных веток или напрасно тратить собственное время, вручную отключая сборку веток! (Хотя стоит отметить, что Bamboo можно просто настроить на игнорирование веток после X дней бездействия, если вы все же предпочитаете способ опроса.)
Ключом к использованию Git с CI является...
…просто внимательность. Когда непрерывная интеграция осуществлялась с помощью централизованной системы управления версиями, все прекрасно работало? С Git некоторые моменты будут работать не так идеально. Поэтому на первом этапе необходимо проверить свои исходные предположения. Для клиентов Atlassian вторым этапом является интеграция Bamboo с Bitbucket. Ознакомьтесь с нашей документацией, чтобы узнать подробнее, и удачной вам разработки!
Поделитесь этой статьей
Следующая тема
Рекомендуемые статьи
Добавьте эти ресурсы в закладки, чтобы изучить типы команд DevOps или получать регулярные обновления по DevOps в Atlassian.

Сообщество DevOps

Узнать больше в блоге