Monorepos in Git
Was ist ein Monorepo?
Monorepos werden unterschiedlich definiert – unsere Definition lautet folgendermaßen:
- Das Repository enthält mehr als ein logisches Projekt (z. B. einen iOS-Client und eine Webanwendung).
- Diese Projekte stehen höchstwahrscheinlich in keinem Zusammenhang, sind lose miteinander verbunden oder können auf andere Weise verbunden werden (z. B. mithilfe von Tools für das Abhängigkeitsmanagement).
- Das Repository ist in vielerlei Hinsicht groß:
- Anzahl der Commits
- Anzahl der Branches und/oder Tags
- Anzahl der verfolgten Dateien
- Größe des verfolgten Inhalts (gemessen am .git-Verzeichnis des Repositorys)
Facebook verfügt über ein solches Beispiel für ein Monorepo:
Mit Tausenden von Commits pro Woche für Hunderttausende von Dateien ist das Hauptquell-Repository von Facebook enorm groß – sogar um ein Vielfaches größer als der Linux-Kernel, der 2013 17 Millionen Codezeilen und 44.000 Dateien verzeichnete.
Zugehöriges Material
Verschieben eines vollständigen Git-Repositorys
Lösung anzeigen
Git kennenlernen mit Bitbucket Cloud
Bei der Durchführung von Leistungstests sah das von Facebook verwendete Test-Repository folgendermaßen aus:
- 4 Millionen Commits
- Linearer Verlauf
- ~1,3 Millionen Dateien
- Ein ungefähr 15 GB großes .git-Verzeichnis
- Eine 191 MB große Indexdatei
Konzeptionelle Herausforderungen
Es gibt viele konzeptionelle Herausforderungen bei der Verwaltung nicht verwandter Projekte in einem Monorepo in Git.
Zunächst verfolgt Git bei jedem einzelnen Commit den Status des gesamten Baums. Dies ist in Ordnung für einzelne oder verwandte Projekte, wird jedoch für ein Repository mit vielen nicht verwandten Projekten unhandlich. Einfach ausgedrückt wirken sich Commits in nicht verwandten Teilen des Baums auf den Teilbaum aus, der für einen Entwickler relevant ist. Dieses Problem wird insbesondere in großem Maßstab deutlich, wenn eine große Anzahl von Commits den Verlauf des Baums wachsen lässt. Da sich die Branch-Spitze ständig ändert, ist ein häufiges Merging oder lokales Rebasing erforderlich, um Änderungen zu pushen.
In Git ist ein Tag ein benannter Alias für einen bestimmten Commit, der sich auf den gesamten Baum bezieht. Im Zusammenhang mit einem Monorepo sind Tags jedoch weniger nützlich. Du solltest dich Folgendes fragen: Wenn du an einer Webanwendung arbeitest, die kontinuierlich in einem Monorepo bereitgestellt wird, welche Relevanz hat das Release-Tag für den versionierten iOS-Client?
Probleme mit der Leistung
Neben diesen konzeptionellen Herausforderungen gibt es zahlreiche Leistungsprobleme, die sich auf eine Monorepo-Einrichtung auswirken können.
Anzahl der Commits
Die Verwaltung nicht verwandter Projekte in einem einzigen Repository in großem Maßstab kann sich auf Commit-Ebene als problematisch erweisen. Im Laufe der Zeit kann dies zu einer großen Anzahl von Commits mit einer erheblichen Wachstumsrate führen (laut Facebook "Tausende von Commits pro Woche"). Dies ist besonders problematisch, da Git einen gerichteten azyklischen Graphen (DAG) verwendet, um den Verlauf eines Projekts darzustellen. Bei einer großen Anzahl von Commits kann mit zunehmender Größe des Verlaufs jeder Befehl, der den Graphen ausführt, langsam werden.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Anzahl der Referenzen
Eine große Anzahl von Referenzen (d. h. Branches oder Tags) in deinem Monorepo wirkt sich in vielerlei Hinsicht auf die Leistung aus.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
Benutzerzeit (Sekunden): 146,44*
* Dies hängt von den Seiten-Caches und der zugrunde liegenden Speicherebene ab.
Anzahl der verfolgten Dateien
Der Index- oder Verzeichnis-Cache (.git/index) verfolgt jede Datei in deinem Repository. Git verwendet diesen Index, um zu ermitteln, ob sich eine Datei geändert hat, indem es stat(1) für jede einzelne Datei ausführt und Dateiänderungsinformationen mit den im Index enthaltenen Informationen vergleicht.
Daher wirkt sich die Anzahl der verfolgten Dateien auf die Leistung* vieler Vorgänge aus:
git statuskönnte langsam sein (führt stat für jede einzelne Datei aus, Indexdatei wird groß).git commitkönnte ebenfalls langsam sein (führt auch stat für jede einzelne Datei aus).
* Dies hängt von den Seiten-Caches und der zugrunde liegenden Speicherebene ab und macht sich nur bei einer großen Anzahl von Dateien im Bereich von Zehntausenden oder Hunderttausenden bemerkbar.
Große Dateien
Große Dateien in einem einzelnen Subtree/Projekt wirken sich auf die Leistung des gesamten Repositorys aus. Beispielsweise, wenn große Medienressourcen, die zu einem iOS-Client-Projekt in einem Monorepo hinzugefügt wurden, geklont werden, obwohl ein Entwickler (oder Build-Agent) an einem nicht verwandten Projekt arbeitet.
Kombinierte Effekte
Unabhängig davon, ob es sich um die Anzahl der Dateien handelt, wie oft sie geändert werden oder wie groß sie sind, wirken sich diese Vorgänge in Kombination verstärkt auf die Leistung aus:
- Beim Wechseln zwischen Branches/Tags, was in einem Subtree-Kontext (z. B. dem Subtree, an dem ich gerade arbeite) am nützlichsten ist, wird trotzdem der gesamte Baum aktualisiert. Dieser Prozess kann aufgrund der Anzahl der betroffenen Dateien langsam sein oder erfordert eine Umgehungslösung. Die Verwendung von
git checkout ref-28642-31335 -- templateszum Beispiel aktualisiert das./templates-Verzeichnis, das dem angegebenen Branch entspricht, jedoch ohneHEADzu aktualisieren, was den Nebeneffekt hat, dass die aktualisierten Dateien im Index als geändert markiert werden. - Das Klonen und Abrufen verlangsamt den Server und ist ressourcenintensiv, da alle Informationen vor der Übertragung in einer Packdatei zusammengefasst werden.
- Die Garbage Collection ist langsam und wird standardmäßig bei einem Push ausgelöst (wenn eine Speicherbereinigung erforderlich ist).
- Die Ressourcennutzung ist bei jedem Vorgang hoch, der die (Neu-)Erstellung einer Packdatei beinhaltet, z. B.
git upload-pack, git gc.
Strategien zur Minderung
Natürlich wäre es toll, wenn Git die meist eher speziellen Anwendungsfälle monolithischer Repositorys unterstützen würde. Jedoch stehen die Designziele von Git, die es äußerst erfolgreich und beliebt gemacht haben, manchmal im Widerspruch zu dem Wunsch, es auf eine Weise zu verwenden, für die es nicht entwickelt wurde. Die gute Nachricht für die überwiegende Mehrheit der Teams ist, dass enorm große monolithische Repositorys eher die Ausnahme als die Regel sind. So interessant dieser Beitrag auch (hoffentlich) sein mag, du wirst höchstwahrscheinlich keine Situation erleben, in der Monorepos angewendet werden.
Abgesehen davon gibt es eine Reihe von Minderungsstrategien, die bei der Arbeit mit großen Repositorys hilfreich sein können. Für Repositorys mit langen Verläufen oder großen binären Assets beschreibt mein Kollege Nicola Paolucci einige Workarounds.
Entfernen von Referenzen
Wenn dein Repository über Zehntausende Referenzen verfügt, solltest du evtl. Referenzen entfernen, die du nicht mehr benötigst. Der DAG behält den Verlauf der Änderungen bei, während Merge-Commits auf ihre übergeordneten Elemente verweisen, sodass Arbeiten an Branches verfolgt werden können, auch wenn der Branch nicht mehr existiert.
In einem Branch-basierten Workflow sollte die Anzahl der langlebigen Branches, die du behalten möchtest, gering sein. Scheue dich nicht, einen kurzlebigen Feature-Branch nach einem Merge zu löschen.
Du solltest in Erwägung ziehen, alle Branches zu entfernen, die in einen Main-Branch wie Produktion gemergt wurden. Es ist weiterhin möglich, den Verlauf der Änderungen nachzuverfolgen, solange ein Commit von deinem Main-Branch aus erreichbar ist und du deinen Branch mit einem Merge-Commit zusammengeführt hast. Die standardmäßige Merge-Commit-Nachricht enthält häufig den Branch-Namen, sodass du diese Informationen bei Bedarf beibehalten kannst.
Umgang mit einer großen Anzahl von Dateien
Wenn dein Repository über eine große Anzahl von Dateien verfügt (in Bereich der Zehn- bis Hunderttausende), ist ein schneller lokaler Speicher mit viel Arbeitsspeicher, der als Puffer-Cache verwendet werden kann, äußerst hilfreich. Dies ist ein Bereich, der bedeutendere Änderungen am Client erfordern würde, ähnlich wie die Änderungen, die Facebook für Mercurial implementiert hat.
Dabei zeichnen Dateisystembenachrichtigungen Dateiänderungen auf, anstatt dass alle Dateien zur Überprüfung auf Änderungen durchlaufen werden müssen. Ein ähnlicher Ansatz (auch unter Verwendung von Watchman) war für Git im Gespräch, wurde aber noch nicht entwickelt.
Verwenden von Git LFS (Large File Storage)
Dieser Abschnitt wurde am 20. Januar 2016 aktualisiert.
Für Projekte, die große Dateien wie Videos oder Grafiken enthalten, ist Git LFS eine Option, um deren Auswirkungen auf die Größe und Gesamtleistung deines Repositorys zu begrenzen. Anstatt große Objekte direkt in deinem Repository zu speichern, speichert Git LFS eine kleine Platzhalterdatei mit demselben Namen, die einen Verweis auf das Objekt enthält, das selbst in einem spezialisierten großen Objektspeicher gespeichert ist. Git LFS bindet sich in die nativen Push-, Pull-, Checkout- und Fetch-Vorgänge von Git ein, um die Übertragung und Ersetzung dieser Objekte in deinem Arbeitsbaum transparent zu handhaben. Das bedeutet, dass du wie gewohnt mit großen Dateien in deinem Repository arbeiten kannst, ohne das Repository aufzublähen.
Bitbucket Server 4.3 (und höher) bettet eine vollständig kompatible Git LFS v1.0+-Implementierung ein und ermöglicht die Vorschau und Unterscheidung großer Bild-Assets, die von LFS verfolgt werden, direkt in der Bitbucket-Benutzeroberfläche.
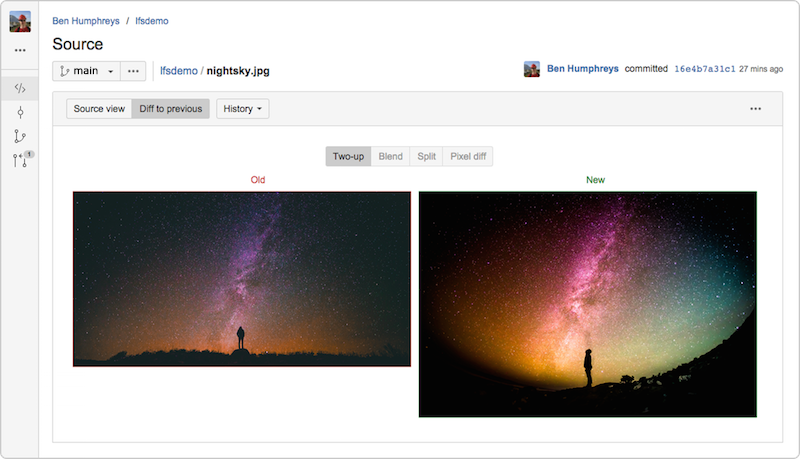
Mein Atlassian-Kollege Steve Streeting ist ein aktiver Mitwirkender am LFS-Projekt und hat kürzlich über das Projekt geschrieben.
Identifizieren der Grenzen und Aufteilen deines Repositorys
Der radikalste Workaround ist das Aufteilen deines Monorepos in kleinere, fokussiertere Git-Repositorys. Versuche, nicht jede Änderung in einem einzigen Repository nachzuverfolgen, und identifiziere stattdessen Komponentengrenzen, indem du vielleicht Module oder Komponenten ermittelst, die einen ähnlichen Release-Zyklus haben. Ein guter Lackmustest für klare Unterkomponenten ist die Verwendung von Tags in einem Repository und ob sie für andere Teile des Quellbaums sinnvoll sind.
Während es großartig wäre, wenn Git Monorepos elegant unterstützen würde, steht das Konzept eines Monorepos leicht im Widerspruch zu dem, was Git in erster Linie äußerst erfolgreich und beliebt macht. Das bedeutet jedoch nicht, dass du auf die Funktionen von Git verzichten solltest, wenn du ein Monorepo hast – in den meisten Fällen gibt es praktikable Lösungen für auftretende Probleme.
Diesen Artikel teilen
Nächstes Thema
Lesenswert
Füge diese Ressourcen deinen Lesezeichen hinzu, um mehr über DevOps-Teams und fortlaufende Updates zu DevOps bei Atlassian zu erfahren.

Bitbucket-Blog

DevOps-Lernpfad
