Atlassian Cloud
Atlassian Cloud-Architektur und betriebliche Praktiken
Erfahre mehr über die Atlassian Cloud-Architektur und die von uns verwendeten betrieblichen Praktiken
Einführung
Atlassian Cloud-Produkte und -Daten werden vom branchenführenden Cloud-Anbieter AWS (Amazon Web Services) gehostet. Unsere Produkte laufen in einer PaaS-Umgebung (Platform as a Service), die in zwei Hauptinfrastrukturgruppen aufgeteilt ist, die wir als Micros und Nicht-Micros bezeichnen. Jira, Confluence, Jira Product Discovery, Statuspage, Guard und Bitbucket laufen auf der Micros-Plattform, während Opsgenie und Trello auf der Nicht-Micros-Plattform ausgeführt werden.
Architektur für verteilte Services
Mit dieser AWS-Architektur hosten wir eine Reihe von Plattform- und Produktservices, die in unseren Lösungen zum Einsatz kommen. Dazu gehören Plattformfunktionen, die von mehreren Atlassian-Produkten wie Media, Identity, Commerce und unserem Editor gemeinsam genutzt werden, sowie produktspezifische Funktionen wie Jira-Issue-Service und Confluence Analytics.
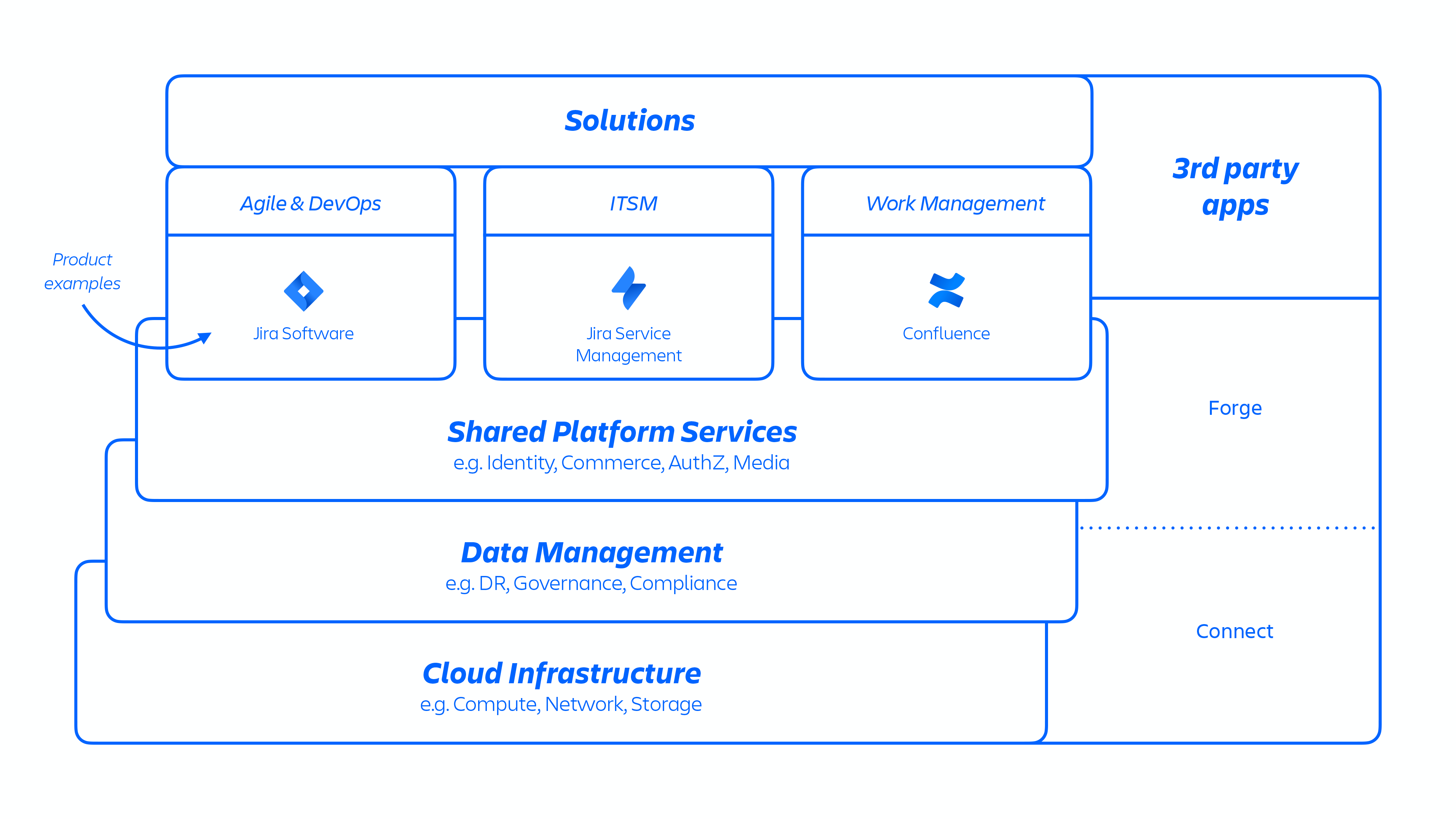
Abb. 1
Atlassian-Entwickler stellen diese Services entweder über Kubernetes oder eine intern entwickelte Platform as a Service (PaaS) namens Micros bereit, die automatisch die Bereitstellung von Shared Services, Infrastruktur, Datenspeichern und deren Verwaltungsfunktionen, einschließlich Sicherheits- und Compliance-Kontrolle, orchestriert (siehe Abbildung 1 oben). Typischerweise besteht ein Atlassian-Produkt aus mehreren "containerisierten" Services, die mithilfe von Micros oder Kubernetes auf AWS bereitgestellt werden. Atlassian-Produkte verwenden Kernplattformfunktionen (siehe Abbildung 2 unten), die vom Anforderungsrouting bis hin zu binären Objektspeichern, Authentifizierung/Autorisierung, transaktionalen benutzergenerierten Inhalten (UGC) und Entitätsbeziehungsspeichern, Data Lakes, allgemeiner Protokollierung, Anforderungsablaufverfolgung, Beobachtbarkeits- und Analyseservices reichen. Diese Microservices basieren auf genehmigten technischen Stacks, die auf Plattformebene standardisiert sind:
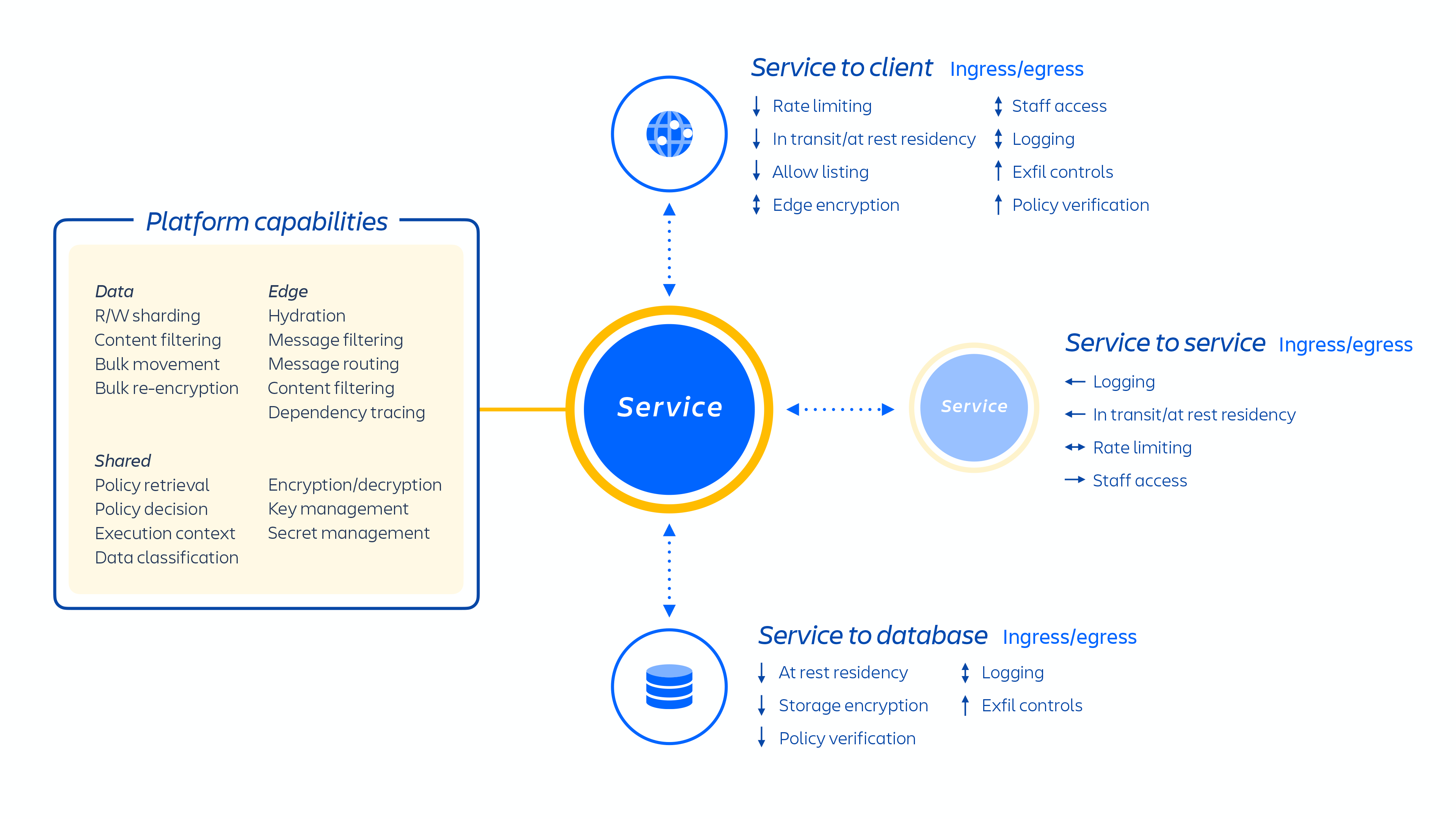
Abb. 2
Mehrmandantenarchitektur
Zusätzlich zu unserer Cloud-Infrastruktur haben wir eine mehrmandantenfähige Microservice-Architektur zusammen mit einer geteilten Plattform, die unsere Produkte unterstützt, aufgebaut und betrieben. In einer Mehrmandantenarchitektur bedient ein einziger Service mehrere Kunden, einschließlich Datenbanken und Recheninstanzen, die für die Ausführung unserer Cloud-Produkte erforderlich sind. Jeder Shard (im Wesentlichen ein Container – siehe Abbildung 3 unten) enthält die Daten für mehrere Mandanten, aber die Daten jedes Mandanten sind isoliert und für andere Mandanten nicht zugänglich. Bitte beachte, dass wir keine Einzelmandantenarchitektur anbieten.
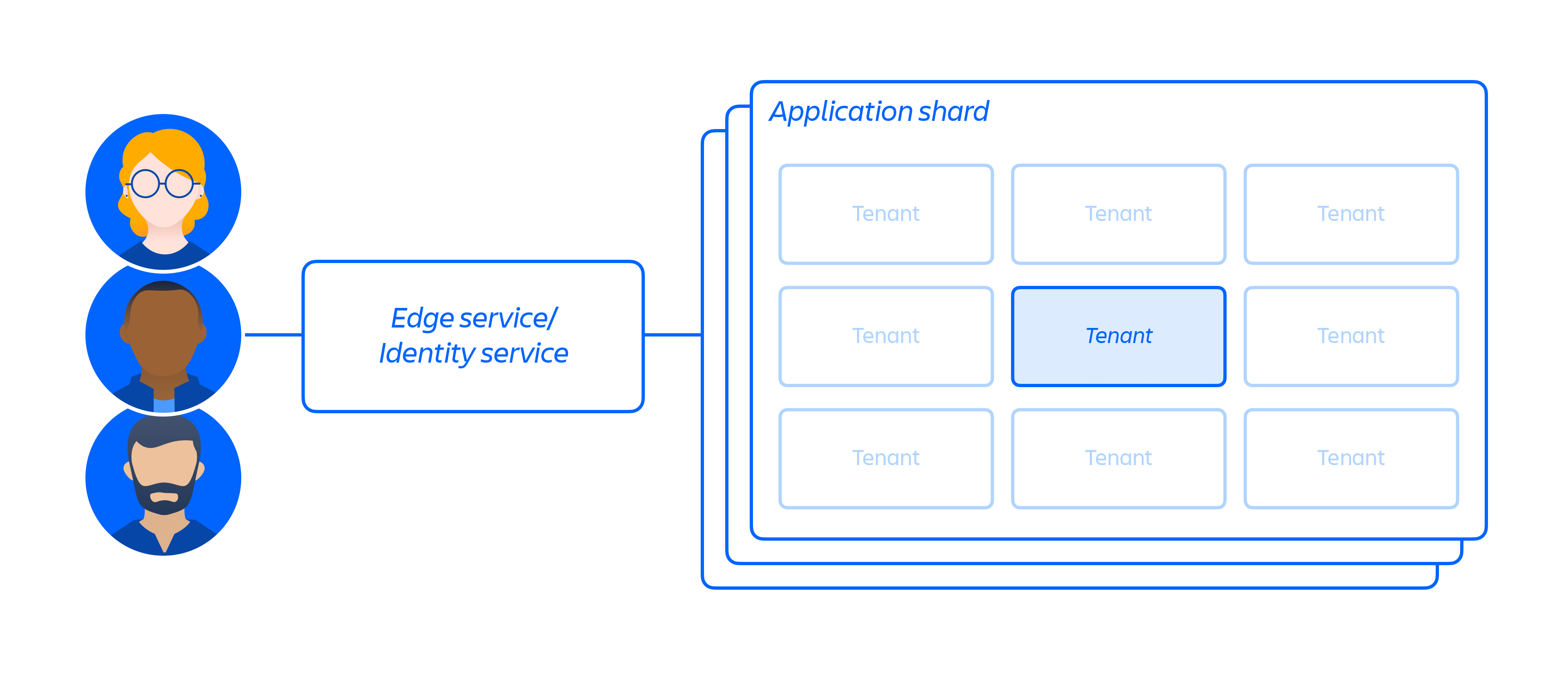
Abb. 3
Unsere Microservices basieren auf dem Prinzip der geringsten Rechte und sollen die Tragweite von Zero-Day-Exploits einschränken, um die laterale Verbreitung innerhalb unserer Cloud-Umgebung zu reduzieren. Jeder Microservice verfügt über seinen eigenen Datenspeicher, auf den nur mithilfe eines Authentifizierungsprotokolls für diesen spezifischen Service zugegriffen werden kann. Das bedeutet, dass kein anderer Service Lese- oder Schreibzugriff auf diese API hat.
Wir haben uns auf die Isolation von Microservices und Daten konzentriert, anstatt jedem Mandanten eine fest zugeordnete Infrastruktur zur Verfügung zu stellen. Denn dies würde für viele Kunden den Zugriff auf den engen Datengeltungsbereich eines einzelnen Systems begrenzen. Die Entkopplung der Logik und die Datenauthentifizierung und -autorisierung auf der Anwendungsebene dienen als zusätzlicher Sicherheitskontrollpunkt, wenn Anforderungen an diese Services gesendet werden. Wenn daher ein Microservice kompromittiert wird, bleibt der erlangte Zugriff auf die Daten beschränkt, die ein bestimmter Service benötigt.
Bereitstellung und Lebenszyklus von Mandanten
Wenn ein neuer Kunde bereitgestellt wird, löst eine Reihe von Ereignissen die Orchestrierung verteilter Services und die Bereitstellung von Datenspeichern aus. Diese Ereignisse können im Allgemeinen einem von sieben Schritten im Lebenszyklus zugeordnet werden:
1. Commerce-Systeme werden sofort mit den neuesten Metadaten und Zugriffskontrollinformationen für diesen Kunden aktualisiert. Anschließend richtet ein Bereitstellungs-Orchestrierungssystem den "Status der bereitgestellten Ressourcen" durch eine Reihe von Mandanten- und Produktereignissen auf den Lizenzstatus aus.
Mandantenereignisse
Diese Ereignisse betreffen den gesamten Mandanten. Sie können sich auf eines der folgenden Szenarien beziehen:
- Erstellung: ein Mandant wird erstellt und für brandneue Sites verwendet
- Zerstörung: ein ganzer Mandant wird gelöscht
Produktereignisse
- Aktivierung: nach der Aktivierung von lizenzierten Produkten oder Apps von Drittanbietern
- Deaktivierung: nach der Deaktivierung bestimmter Produkte oder Apps
- Aussetzung: nach der Aussetzung eines bestimmten vorhandenen Produkts, wodurch der Zugriff auf eine bestimmte Site deaktiviert wird
- Aufheben der Aussetzung: nach der Aufhebung der Aussetzung eines bestimmten vorhandenen Produkts, wodurch der Zugriff auf eine Site ermöglicht wird
- Lizenzaktualisierung: enthält Informationen zur Anzahl der Arbeitsplatzlizenzen für ein bestimmtes Produkt sowie dessen Status (aktiv/inaktiv)
2. Erstellung der Kunden-Site und Aktivierung der richtigen Produktauswahl für den Kunden. Das Konzept einer Site ist ein Container für mehrere Produkte, die für einen bestimmten Kunden lizenziert sind (z. B. Confluence und Jira Software für
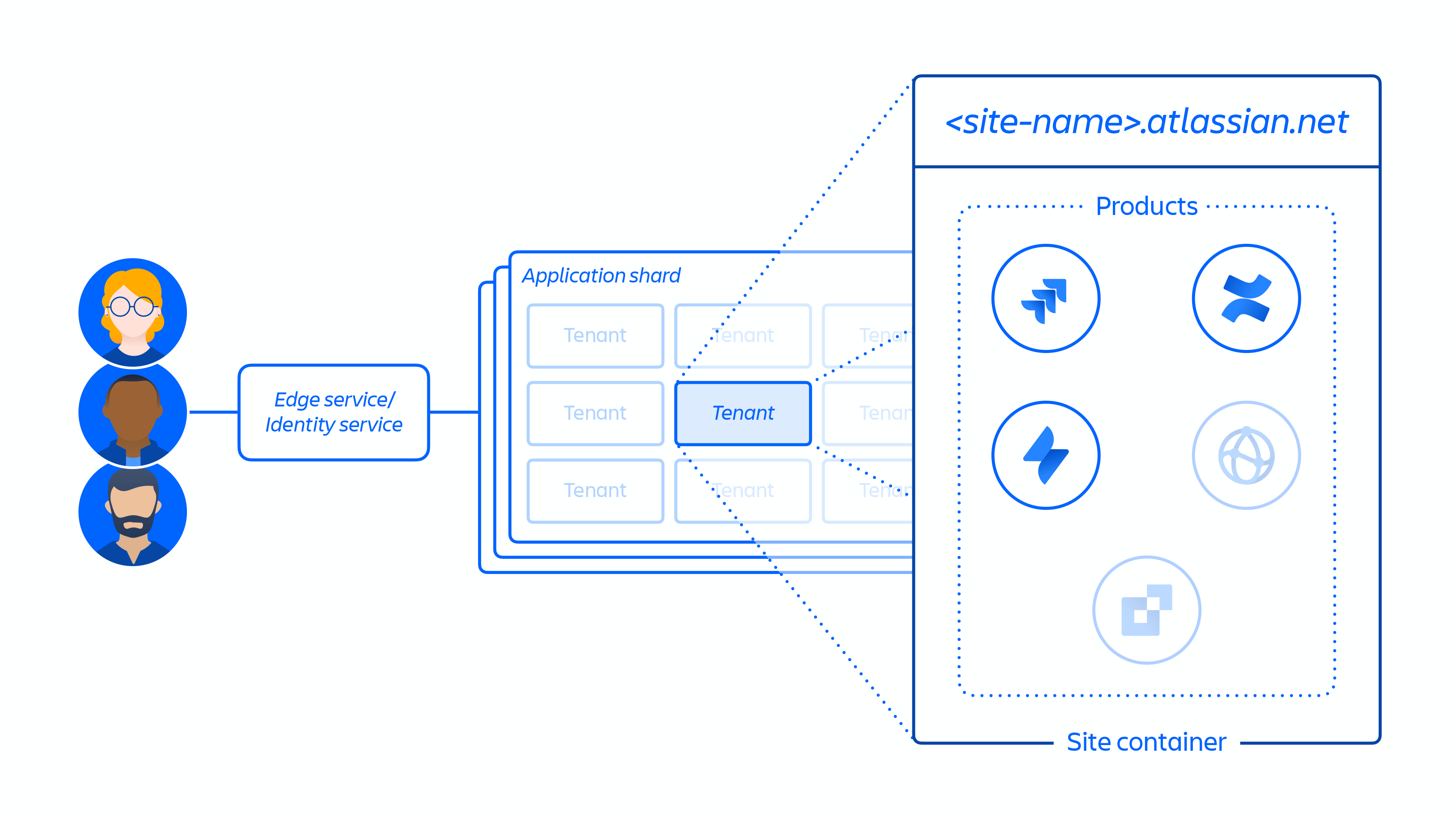
Abb. 4
3. Bereitstellung von Produkten auf einer Kunden-Site in der angegebenen Region.
Wenn ein Produkt bereitgestellt wird, wird der Großteil seines Inhalts in der Nähe des Zugriffsorts der Benutzer gehostet. Um die Produktleistung zu optimieren, schränken wir die Datenbewegung nicht ein, wenn ein Inhalt weltweit gehostet wird. Wir können Daten nach Bedarf zwischen Regionen verschieben.
Für einige unserer Produkte bieten wir auch Datenresidenz an. Datenresidenz ermöglicht es Kunden, zu wählen, ob Produktdaten weltweit verteilt oder an einem unserer definierten geografischen Standorte gespeichert werden.
4. Erstellung und Speicherung der Kunden-Site und der Kernmetadaten und Konfiguration der Produkte.
5. Erstellung und Speicherung der Site und Produktidentitätsdaten wie Benutzer, Gruppen, Berechtigungen usw.
6. Bereitstellung von Produktdatenbanken innerhalb einer Site, z. B. Jira-Produktfamilie, Confluence, Compass und Atlas.
7. Bereitstellung von lizenzierten Apps für das Produkt/die Produkte.
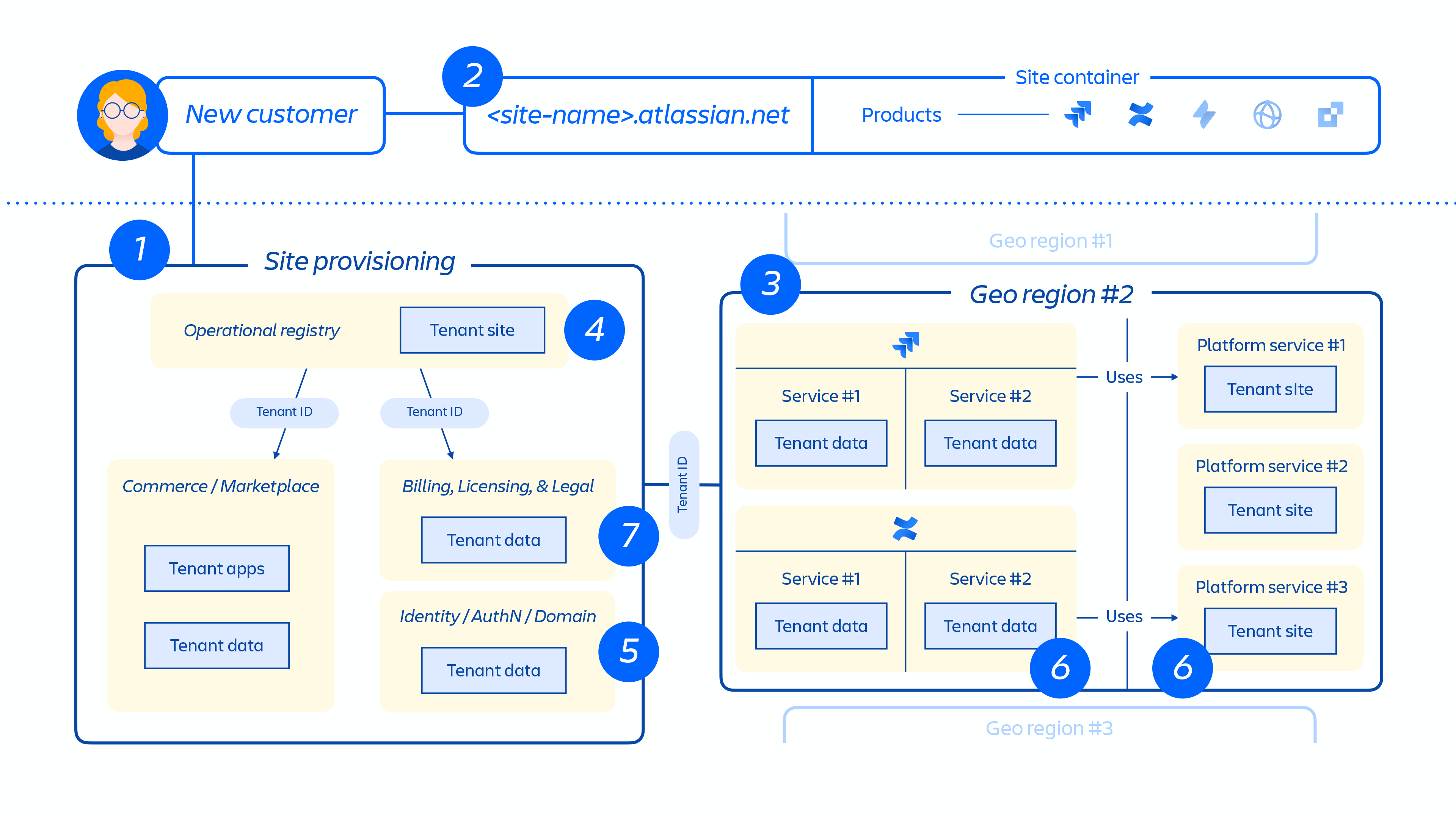
Abb. 5
Abbildung 5 oben zeigt, wie die Site eines Kunden in unserer verteilten Architektur bereitgestellt wird, nicht nur in einer einzigen Datenbank oder einem Speicher. Dazu gehören mehrere physische und logische Speicherorte, an denen Metadaten, Konfigurationsdaten, Produktdaten, Plattformdaten und andere zugehörige Site-Informationen gespeichert werden.