Atlassian Cloud
Arquitectura y prácticas operativas de Atlassian Cloud
Conoce mejor la arquitectura de Atlassian Cloud y las prácticas operativas que ejercemos
Introducción
Atlassian cloud apps and data are hosted on industry-leading cloud provider Amazon Web Services (AWS). Our products run on a platform as a service (PaaS) environment that is split into two main sets of infrastructure that we refer to as Micros and non-Micros. Jira, Confluence, Jira Product Discovery, Statuspage, Guard, and Bitbucket run on the Micros platform, while Opsgenie and Trello run on the non-Micros platform.
Arquitectura de los servicios distribuidos
With this AWS architecture, we host a number of platform and product services that are used across our solutions. This includes platform capabilities that are shared and consumed across multiple Atlassian products, such as Media, Identity, and Commerce, experiences such as our Editor, and product-specific capabilities, like Jira Work Item service and Confluence Analytics.
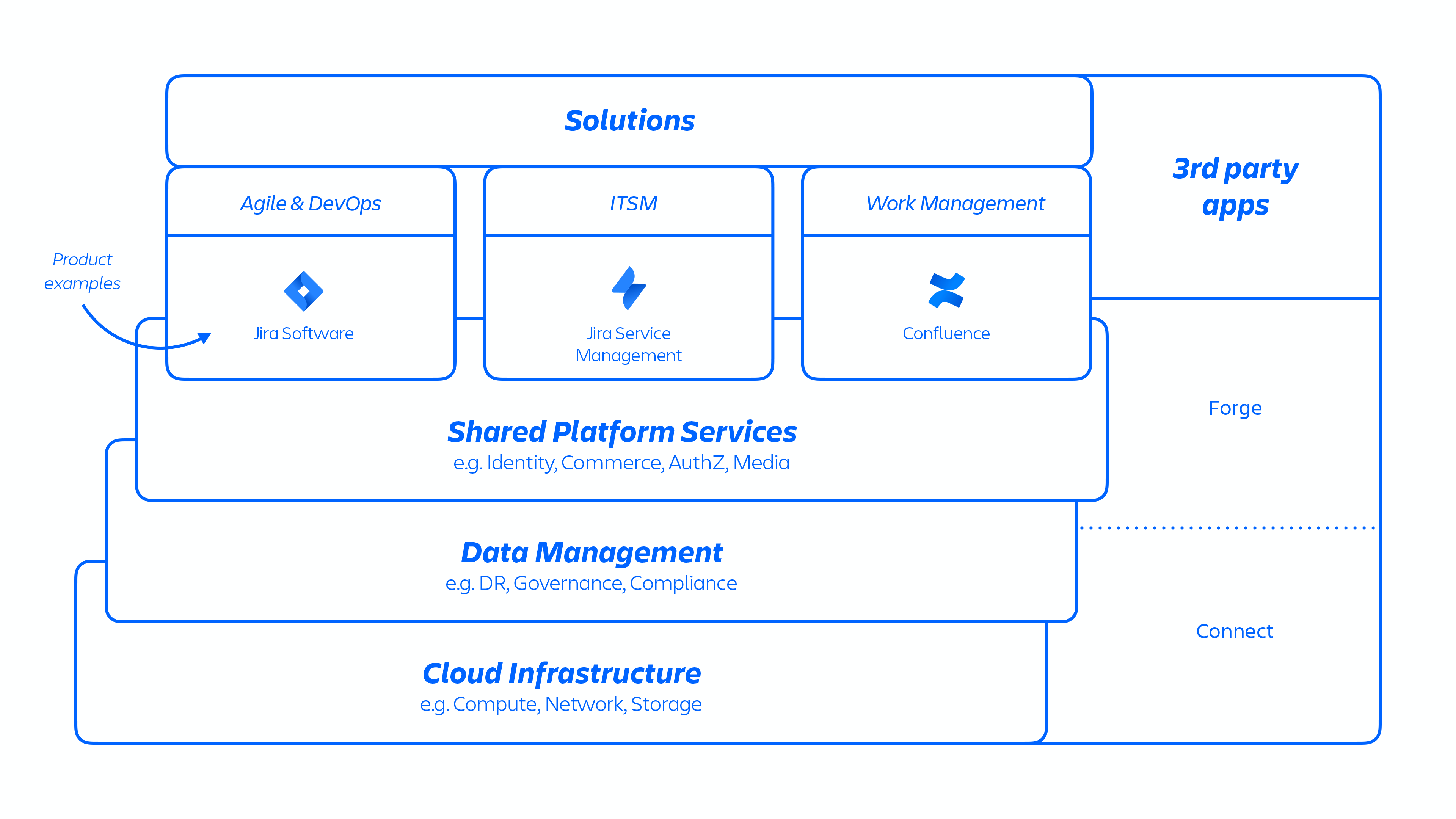
Imagen 1
Los desarrolladores de Atlassian proporcionan estos servicios a través de kubernetes o de una plataforma como servicio (PaaS) desarrollada internamente, llamada Micros. Ambas opciones organizan automáticamente la implementación de servicios compartidos, infraestructura, almacenes de datos y sus capacidades de gestión, incluidos los requisitos de control de seguridad y cumplimiento (consulta la imagen 1 de arriba). Por lo general, un producto de Atlassian se compone de varios servicios "en contenedores" que se implementan en AWS mediante Micros o kubernetes. Los productos de Atlassian utilizan funciones principales de la plataforma (consulta la imagen 2 más abajo) que van desde el enrutamiento de solicitudes a los almacenes de objetos binarios, la autenticación o autorización, el contenido transaccional generado por usuarios (UGC) y los almacenes de relaciones entre entidades, los data lakes, el registro común, el seguimiento de solicitudes, la observabilidad y los servicios de análisis. Estos microservicios se generan utilizando pilas técnicas aprobadas y estandarizadas a nivel de plataforma:
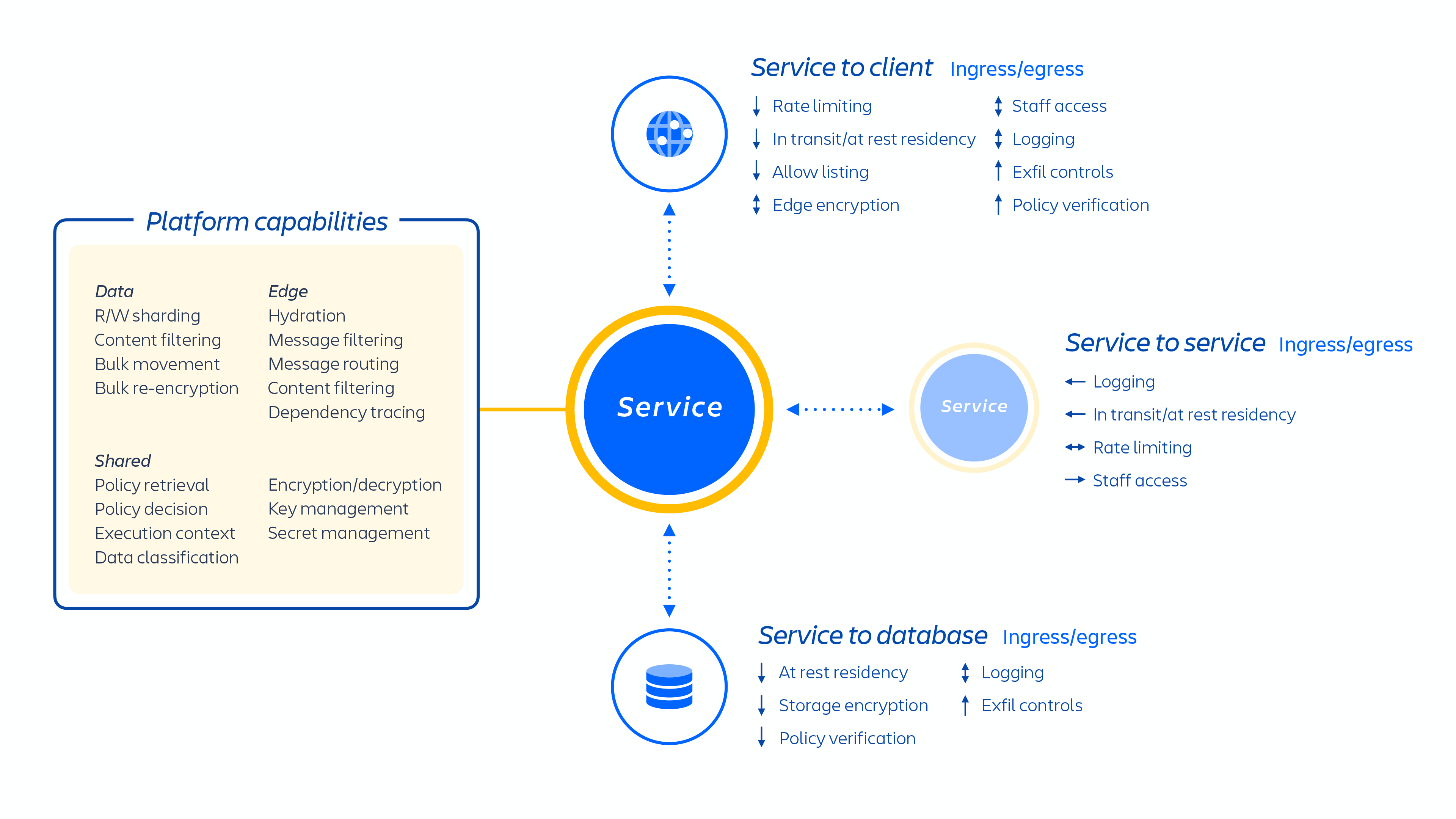
Imagen 2
Arquitectura de varios inquilinos
On top of our cloud infrastructure, we built and operate a multi-tenant micro-service architecture along with a shared platform that supports our products. In a multi-tenant architecture, a single service serves multiple customers, including databases and compute instances required to run our cloud apps. Each shard (essentially a container – see figure 3 below) contains the data for multiple tenants, but each tenant's data is isolated and inaccessible to other tenants. It is important to note that we do not offer a single tenant architecture.
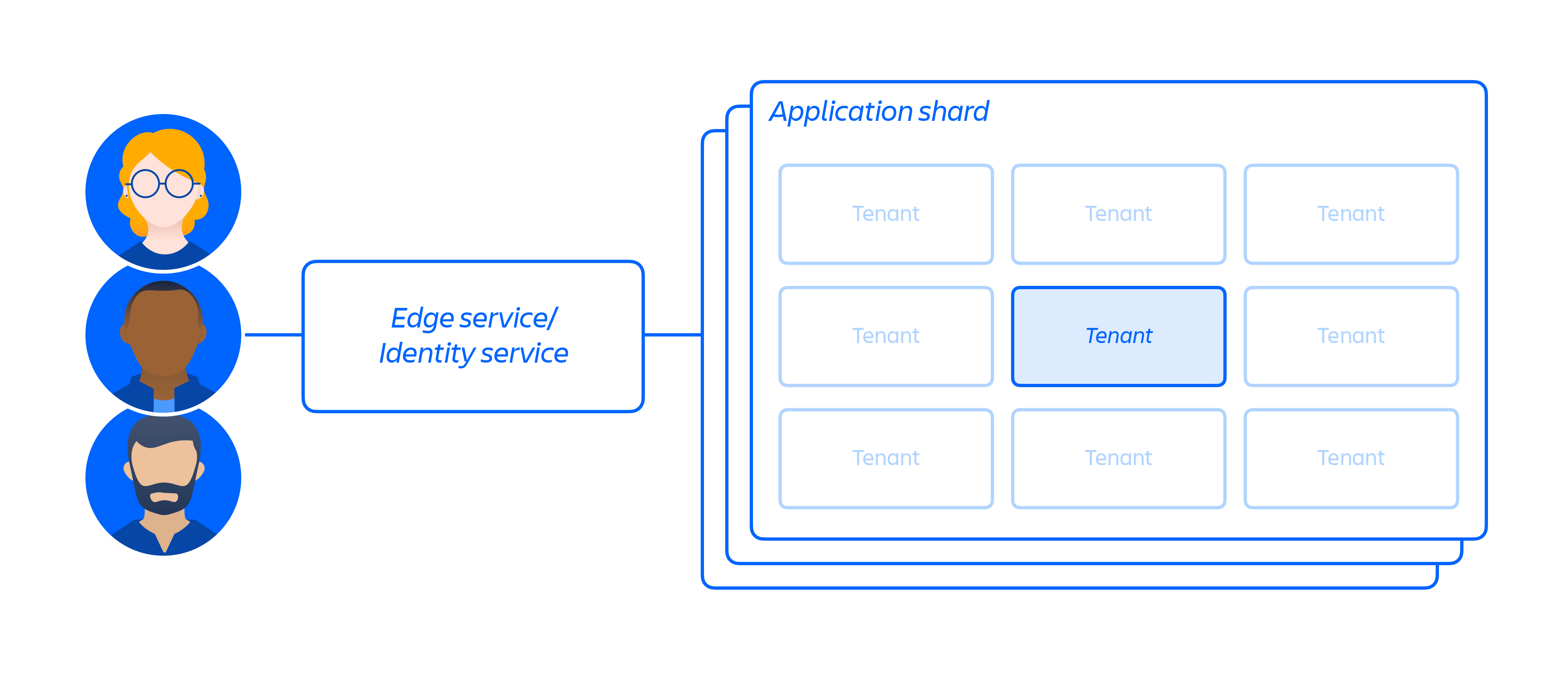
Imagen 3
Nuestros microservicios se desarrollan en base a los privilegios mínimos necesarios y están diseñados para minimizar el alcance de cualquier vulnerabilidad de día cero y reducir la probabilidad de movimiento lateral dentro de nuestro entorno de Cloud. Cada microservicio tiene su propio almacenamiento de datos al que solo se puede acceder con el protocolo de autenticación específico de ese servicio, lo que significa que ningún otro servicio tiene acceso de lectura o escritura a esa API.
Nos hemos centrado en aislar los microservicios y los datos en lugar de ofrecer una infraestructura exclusiva por inquilino, ya que limita el acceso al alcance limitado de los datos de un solo sistema para muchos clientes. Como la lógica se ha desacoplado y la autenticación y autorización de datos se producen en la capa de aplicación, esto actúa como una comprobación de seguridad adicional a medida que se envían solicitudes a estos servicios. Por lo tanto, si se produce la vulneración de un microservicio, solo se obtendrá un acceso limitado a los datos que requiere un servicio determinado.
Aprovisionamiento y ciclo de vida de inquilinos
Cuando se aprovisiona a un cliente nuevo, una serie de eventos desencadenan la orquestación de servicios distribuidos y el aprovisionamiento de almacenes de datos. Por lo general, estos eventos se pueden asignar a uno de los siete pasos del ciclo de vida:
1. Los sistemas de comercio se actualizan inmediatamente con los metadatos y la información de control de acceso más recientes para ese cliente y, a continuación, un sistema de orquestación de aprovisionamiento alinea el "estado de los recursos aprovisionados" con el estado de la licencia a través de una serie de eventos de inquilinos y productos.
Eventos de inquilinos
Estos eventos afectan al inquilino en su conjunto y pueden ser:
- Creación: se crea un inquilino y se utiliza para sitios nuevos
- Destrucción: se elimina todo un inquilino
Eventos de productos
- Activación: tras la activación de productos con licencia o aplicaciones de terceros
- Desactivación: tras la desactivación de determinados productos o aplicaciones
- Suspensión: tras la suspensión de un producto existente determinado, con lo que se deshabilita el acceso de los clientes a un sitio del que son propietarios
- Anulación de la suspensión: tras la anulación de la suspensión de un producto existente determinado, con lo que se habilita el acceso de los clientes a un sitio del que son propietarios
- Actualización de licencia: contiene información sobre el número de licencias de un producto determinado, así como sobre su estado (activo/inactivo)
2. Creación del sitio del cliente y activación del conjunto correcto de productos para el cliente. El concepto de un sitio es el contenedor de varios productos con licencia para un cliente en particular (por ejemplo, Confluence y Jira Software para <site-name> .atlassian.net).
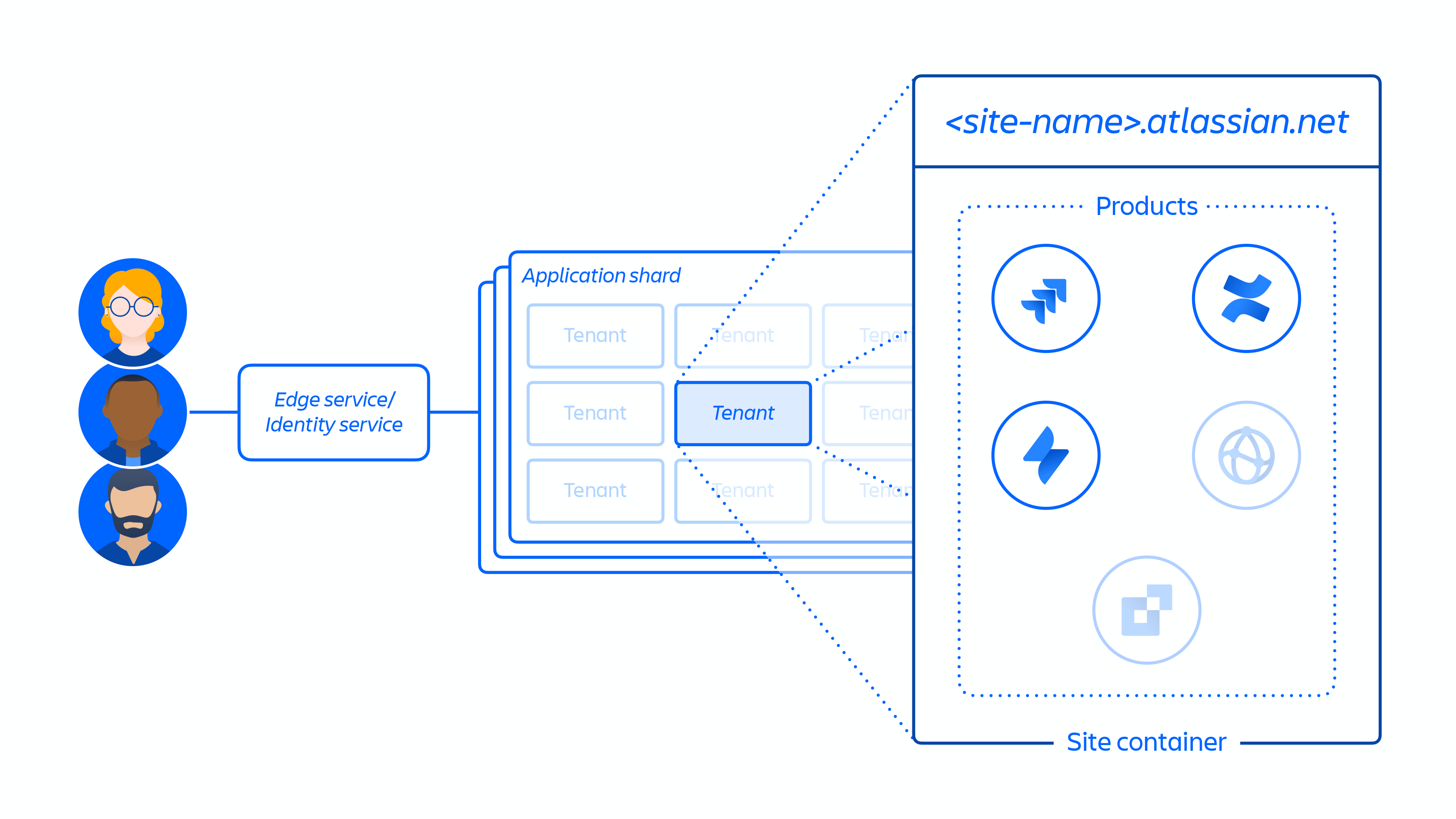
Imagen 4
3. Aprovisionamiento de productos dentro del sitio del cliente en la región designada.
Cuando se aprovisiona un producto, la mayoría de su contenido estará alojado cerca de donde los usuarios acceden a él. Para optimizar el rendimiento del producto, no limitamos el movimiento de datos cuando están alojados en todo el mundo y podemos mover datos entre regiones según sea necesario.
Para algunos de nuestros productos, también ofrecemos un servicio de residencia de datos. La residencia de datos permite a los clientes elegir si los datos de los productos se distribuyen globalmente o se mantienen en una de nuestras ubicaciones geográficas definidas.
4. Creación y almacenamiento de los metadatos principales y de la configuración de los productos y del sitio del cliente.
5. Creación y almacenamiento de los datos de identidad del sitio y de los productos, como usuarios, grupos, permisos, etc.
6. Aprovisionamiento de bases de datos de productos en un sitio, p. ej. la familia de productos Jira, Confluence, Compass y Atlas.
7. Aprovisionamiento de las aplicaciones con licencia de los productos.
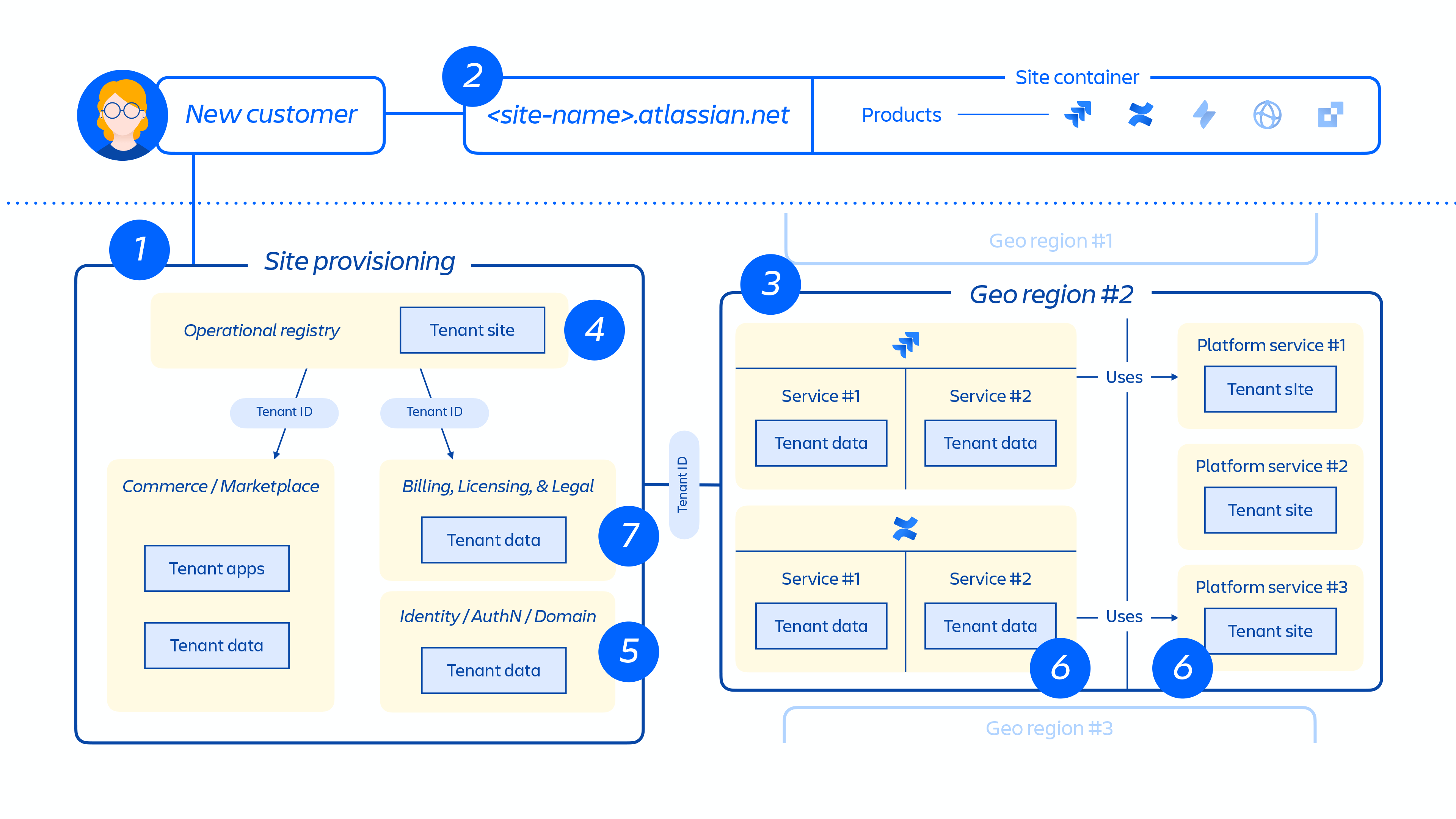
Imagen 5
La figura 5 anterior demuestra cómo se implementa el sitio de un cliente en nuestra arquitectura distribuida, no solo en una única base de datos o almacén. Esto incluye varias ubicaciones físicas y lógicas que almacenan metadatos, datos de configuración, datos de productos, datos de plataformas y otra información relacionada del sitio.