Monorepo's in Git
Wat is een monorepo?
De definities variëren, maar we definiëren een monorepo als volgt:
- De repository bevat meer dan één logisch project (bijvoorbeeld een iOS-client en een webapplicatie)
- Deze projecten hebben waarschijnlijk niets met elkaar te maken, zijn losjes met elkaar verbonden of kunnen op een andere manier met elkaar worden verbonden (bijvoorbeeld via tools voor afhankelijkheidsbeheer)
- De repository is in veel opzichten groot:
- Aantal commits
- Aantal branches en/of tags
- Aantal bijgehouden bestanden
- Grootte van de bijgehouden inhoud (gemeten door te kijken naar de .git-map van de repository)
Facebook heeft zo'n voorbeeld van een monorepo:
Met duizenden commits per week, verdeeld over honderdduizenden bestanden, is de belangrijkste bron-repository van Facebook enorm, vele malen groter dan zelfs de Linuxkernel, die in 2013 17 miljoen regels code en 44.000 bestanden bevatte.
gerelateerd materiaal
Een volledige Git-repository verplaatsen
Oplossing bekijken
Git leren met Bitbucket Cloud
En tijdens het uitvoeren van prestatietests gebruikte Facebook de volgende testrepository:
- 4 miljoen commits
- Lineaire geschiedenis
- ~1,3 miljoen bestanden
- De grootte van de .git-map was ongeveer 15 GB
- De grootte van het indexbestand was 191 MB
Conceptuele uitdagingen
Er zijn veel conceptuele uitdagingen bij het beheren van niet-gerelateerde projecten in een monorepo in Git.
Ten eerste houdt Git bij elke gemaakte commit de status van de hele boomstructuur bij. Dit is prima voor afzonderlijke of gerelateerde projecten, maar wordt lastig voor een repository met veel niet-gerelateerde projecten. Simpel gezegd, commits in niet-gerelateerde delen van de boomstructuur hebben invloed op de substructuur die relevant is voor een ontwikkelaar. Dit probleem is aanzienlijk op grote schaal, waarbij grote aantallen commits de geschiedenis van de boom bevorderen. Aangezien het uiteinde van de branch voortdurend verandert, is regelmatig lokaal samenvoegen of rebasen vereist om wijzigingen te pushen.
In Git is een tag een alias met een naam voor een bepaalde commit die verwijst naar de hele boom. Maar het nut van tags neemt af in de context van een monorepo. Stel jezelf de volgende vraag: als je werkt aan een webapplicatie die continu wordt geïmplementeerd in een monorepo, wat is dan de relevantie van de releasetag voor de iOS-client met versiebeheer?
Prestatieproblemen
Naast deze conceptuele uitdagingen zijn er tal van prestatieproblemen die van invloed kunnen zijn op een monorepo-setup.
Aantal commits
Ongerelateerde projecten op grote schaal beheren in een enkele repository kan op commit-niveau voor problemen zorgen. In de loop der tijd kan dit leiden tot een groot aantal commits met een aanzienlijk groeipercentage (Facebook zei "duizenden commits per week"). Dit wordt pas echt lastig omdat Git een DAG (Directed Acyclic Graph of gerichte acyclische grafiek) gebruikt om de geschiedenis van een project weer te geven. Bij een groot aantal commits kan elke opdracht die in de grafiek wordt weergegeven langzaam worden naarmate de geschiedenis zich uitbreidt.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Aantal refs
Een groot aantal verwijzingen (d.w.z. branches of tags) in je monorepo hebben op veel manieren invloed op de prestaties.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
Gebruikerstijd (seconden): 146,44*
*Dit varieert afhankelijk van de paginacaches en de onderliggende opslaglaag.
Aantal bijgehouden bestanden
De index- of mappencache (.git/index) traceert elk bestand in je repository. Git gebruikt deze index om te bepalen of een bestand is gewijzigd door stat(1) uit te voeren op elk afzonderlijk bestand en informatie over bestandswijzigingen te vergelijken met de informatie in de index.
Het aantal bijgehouden bestanden is dus van invloed op de prestaties* van veel bewerkingen:
git statuskan traag zijn (statistieken van elk bestand afzonderlijk, het indexbestand zal groot zijn)git commitkan ook traag zijn (geeft ook statistieken van elk bestand)
*Dit varieert afhankelijk van de paginacaches en de onderliggende opslaglaag, en is alleen merkbaar als er een groot aantal bestanden is, in de buurt van tientallen of in de honderdduizenden.
Grote bestanden
Grote bestanden in één subboom/project hebben invloed op de prestaties van de hele repository. Grote mediabestanden die in een monorepo aan een iOS-clientproject worden toegevoegd, worden bijvoorbeeld gekloond ondanks dat een ontwikkelaar (of buildagent) aan een niet-gerelateerd project werkt.
Gecombineerde effecten
Of het nu gaat om het aantal bestanden, hoe vaak ze worden gewijzigd of hoe groot ze zijn, deze problemen samen hebben een grotere invloed op de prestaties:
- Door te schakelen tussen branches/tags, wat vooral handig is in een subboomcontext (bijvoorbeeld de substructuur waaraan ik werk), wordt nog steeds de hele structuur bijgewerkt. Dit proces kan traag verlopen vanwege het aantal betrokken bestanden of er is een tijdelijke oplossing voor nodig. Met behulp van
git checkout ref-28642-31335 -- templateswordt voor voorbeeldupdates de map./templatesbijgewerkt zodat deze overeenkomt met de opgegeven branch, maar zonderHEADbij te werken, wat als neveneffect heeft dat de bijgewerkte bestanden in de index als gewijzigd worden gemarkeerd. - Klonen en ophalen vertraagt en vergt veel resources op de server, aangezien alle informatie vóór de overdracht wordt gecomprimeerd in een pakketbestand.
- De afvalinzameling is traag en wordt standaard geactiveerd na een push (als afvalinzameling nodig is).
- Het gebruik van resources is hoog bij elke bewerking waarbij een packfile (opnieuw) wordt aangemaakt, bijv.
git upload-pack, git gc.
Mitigatiestrategieën
Hoewel het geweldig zou zijn als Git de speciale usecase zou ondersteunen dat monolithische repository's vaak zijn, staan de ontwerpdoelen van Git die het enorm succesvol en populair hebben gemaakt soms haaks op de wens om het te gebruiken op een manier waarvoor het niet was ontworpen. Het goede nieuws voor de overgrote meerderheid van de teams is dat echt grote monolithische repository's eerder uitzondering dan regel zijn, dus hoe interessant dit bericht hopelijk ook is, het is waarschijnlijk niet van toepassing op een situatie waarmee je in aanraking komt.
Dat gezegd hebbende, er zijn verschillende mitigatiestrategieën die kunnen helpen bij het werken met grote repository's. Voor repository's met een lange geschiedenis of grote binaire bestanden beschrijft mijn collega Nicola Paolucci enkele oplossingen.
Refs verwijderen
Als je repository tienduizenden referenties heeft, zou je moeten overwegen om refs te verwijderen die je niet meer nodig hebt. De DAG bewaart de geschiedenis van hoe de veranderingen evolueerden, terwijl de samengevoegde commits zich verbonden zijn aan de bovenliggende branch zodat het werk dat aan branches is uitgevoerd, kan worden getraceerd, zelfs als de branch niet meer bestaat.
In een op branch gebaseerde workflow moet het aantal branches met een lange levensduur dat je wilt behouden klein zijn. Wees niet bang om een kortstondige functie-branches te verwijderen na een samenvoeging.
Overweeg om alle branches te verwijderen die zijn samengevoegd tot een main-branch, zoals productie. Het is nog steeds mogelijk om de geschiedenis te traceren van hoe veranderingen zijn geëvolueerd, zolang een commit bereikbaar is vanuit je main-branch en je je branch hebt samengevoegd met een merge commit. Het standaard commit-bericht voor samenvoegen bevat vaak de naam van de branch, zodat je deze informatie kunt bewaren als dat nodig is.
Omgaan met grote aantallen bestanden
Als je repository een groot aantal bestanden bevat (in de tientallen tot honderdduizenden), kan het helpen om snelle lokale opslag met veel geheugen te gebruiken als buffercache. Dit is een gebied dat voor de klant ingrijpendere veranderingen zou vergen, vergelijkbaar met bijvoorbeeld de wijzigingen die Facebook heeft doorgevoerd voor Mercurial
Hun aanpak maakte gebruik van meldingen in het bestandssysteem om bestandswijzigingen vast te leggen in plaats van alle bestanden te herhalen om te controleren of ze waren gewijzigd. Een soortgelijke aanpak (ook via watchman) is besproken voor Git, maar is nog niet tot stand gekomen.
Git LFS (Large File Storage) gebruiken
Deze sectie is bijgewerkt op 20 januari 2016
Voor projecten die grote bestanden bevatten, zoals video's of afbeeldingen, is Git LFS een optie om de impact ervan op de grootte en de algehele prestaties van je repository te beperken. In plaats van grote objecten rechtstreeks in je repository op te slaan, slaat Git LFS een klein placeholder-bestand op met dezelfde naam dat een verwijzing naar het object bevat, dat op zijn beurt wordt opgeslagen in een gespecialiseerde repository voor grote objecten. Git LFS maakt gebruik van de oorspronkelijke push-, pull-, checkout- en fetch-bewerkingen van Git om de overdracht en vervanging van deze objecten in je werkboom transparant af te handelen. Dit betekent dat je met grote bestanden in je repository kunt werken zoals je normaal zou doen, zonder dat dit ten koste gaat van een te grote repository.
Bitbucket Server 4.3 (en hoger) bevat een volledig compatibele Git LFS v1.0+-implementatie en maakt het mogelijk om grote afbeeldingen die door LFS worden bijgehouden rechtstreeks in de gebruikerinterface van Bitbucket te bekijken en te differentiëren.
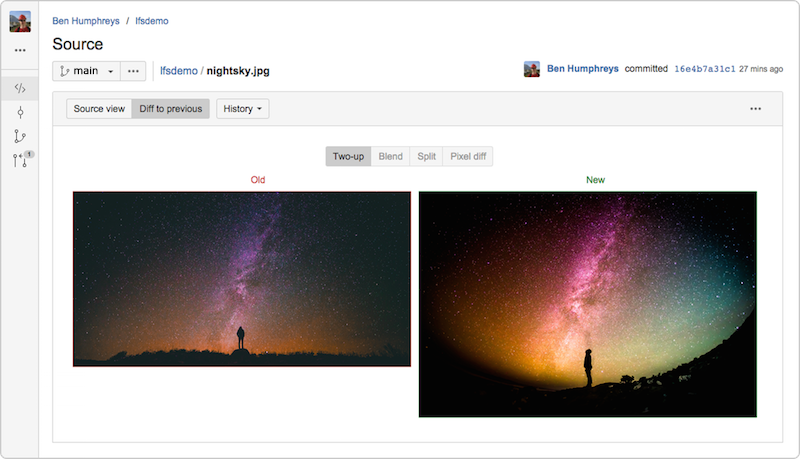
Mijn mede-Atlassian Steve Streeting levert een actieve bijdrage aan het LFS-project en schreef onlangs over het project.
Grenzen identificeren en je repository splitsen
De meest radicale oplossing is om je monorepo op te splitsen in kleinere, meer gerichte Git-repository's. Probeer niet elke wijziging in een enkele repository te volgen en identificeer in plaats daarvan de componentgrenzen, misschien door modules of componenten te identificeren die een vergelijkbare releasecyclus hebben. Een goede test voor duidelijke subcomponenten is het gebruik van tags in een repository en of ze zinvol zijn voor andere delen van de bronstructuur.
Hoewel het geweldig zou zijn als Git monorepo's elegant zou ondersteunen, staat het concept van een monorepo enigszins haaks op wat Git in de eerste plaats enorm succesvol en populair maakt. Dat betekent echter niet dat je de mogelijkheden van Git moet opgeven omdat je een monorepo hebt. In de meeste gevallen zijn er werkbare oplossingen voor eventuele problemen die zich voordoen.
Deel dit artikel
Volgend onderwerp
Aanbevolen artikelen
Bookmark deze resources voor meer informatie over soorten DevOps-teams of voor voortdurende updates over DevOps bij Atlassian.

Bitbucket-blog

DevOps-leertraject
