Hoe ga je om met grote repository's met git

Nicola Paolucci
Developer Advocate
Git is een fantastische keuze om de ontwikkeling van je codebase te volgen en om efficiënt samen te werken met je collega's. Maar wat gebeurt er als de repository die je wilt bijhouden echt, maar dan ook echt, gigantisch is?
In dit bericht geef ik je enkele technieken om ermee om te gaan.
Twee categorieën van grote repository's
Als je erover nadenkt, zijn er in grote lijnen twee belangrijke redenen waarom het aantal repository's enorm groeit:
- Ze hebben een zeer lange geschiedenis (het project groeit in een zeer lange periode en de hoeveelheid bagage stapelt zich op)
- Ze omvatten enorme binary assets die moeten worden gevolgd en gekoppeld aan code.
… of beide.
Soms wordt het tweede soort probleem nog verergerd door het feit dat oude, verouderde binaire artefacten nog steeds in de repository zijn opgeslagen. Maar daar is een redelijk eenvoudige, zij het irritante, oplossing voor (zie hieronder).
De technieken en oplossingen voor elk scenario zijn verschillend, maar soms complementair. Dus ga ik ze apart behandelen.
Repository voor het klonen van bestanden met een zeer lange geschiedenis
Hoewel de drempel om een repository als 'enorm te kwalificeren vrij hoog is, is het nog steeds lastig om ze te klonen. En je kunt niet altijd om lange geschiedenissen heen. Sommige repo's moeten om wettelijke of reglementaire redenen intact worden gehouden.
De eenvoudige oplossing: git shallow clone
De eerste oplossing voor een snelle kloon en om tijd en schijfruimte voor ontwikkelaars en systemen te besparen, is door alleen recente revisies te kopiëren. Met de optie shallow clone van Git kun je alleen de laatste n-commits uit de geschiedenis van de repo opvragen.
Hoe doen we dit? Gebruik gewoon de optie --depth. Bijvoorbeeld:
git clone --depth [depth] [remote-url]
Stel je voor dat je tien of meer jaar projectgeschiedenis hebt verzameld in je repository. We hebben bijvoorbeeld Jira (een 11 jaar oude codebase) gemigreerd naar Git. De tijdwinst voor repo's zoals deze kan oplopen en erg merkbaar zijn.
De volledige kloon van Jira is 677 MB en de werkmap is nog eens meer dan 320 MB, bestaande uit meer dan 47.000 commits. Een oppervlakkige kloon van de repo duurde 29,5 seconden, vergeleken met 4 minuten en 24 seconden voor een volledige kloon met de hele geschiedenis. Het voordeel neemt ook toe in verhouding tot het aantal binary assets dat je project in de loop der tijd heeft opgebouwd.
gerelateerd materiaal
Een volledige Git-repository verplaatsen
Oplossing bekijken
Git leren met Bitbucket Cloud
Tip: buildsystemen die gekoppeld zijn aan je Git-repo profiteren ook van oppervlakkige klonen!
Oppervlakkige klonen waren vroeger enigszins de gestoorde burgers van de Git-wereld, aangezien sommige bewerkingen nauwelijks werden ondersteund. Maar recente versies (1.9 en hoger) hebben de situatie enorm verbeterd en je kunt nu zelfs met een oppervlakkige kloon op de juiste pullen en pushen naar repository's.
Precisie-oplossing: git filter branche
Voor de enorme repository's met grote binaire bestanden die per ongeluk zijn gecommit of oude bestanden die niet meer nodig zijn, is het een goede oplossing om git filter-branch te gebruiken. Met deze opdracht kun je de hele geschiedenis van het project bekijken door bestanden uit te filteren, aan te passen en over te slaan volgens vooraf gedefinieerde patronen.
Git is een zeer krachtig hulpmiddel als je eenmaal hebt vastgesteld waar het gewicht van je repo zich bevindt. Er zijn hulpscripts beschikbaar om grote objecten te identificeren, dus dat deel moet eenvoudig genoeg zijn.
De syntaxis luidt als volgt:
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'git filter-branch heeft echter een klein nadeel: als je _filter-branch_ gebruikt, herschrijf je in feite de hele geschiedenis van je project. Dat wil zeggen, alle commit-ID's veranderen. Hiervoor moet elke ontwikkelaar de bijgewerkte repository opnieuw klonen.
Als je van plan bent om een opruimactie uit te voeren met behulp van git filter-branch, moet je je team waarschuwen, een tijdelijke bevriezing plannen terwijl de bewerking wordt uitgevoerd en dan iedereen laten weten dat ze de repository opnieuw moeten klonen.
Tip: meer info over git filter-branch vind je dit bericht over het uit elkaar halen van je Git-repo.
Alternatief voor git shallow-clone: kloon slechts één branch
Sinds git 1.7.10 kun je ook de hoeveelheid geschiedenis die je kloont beperken door één branch te klonen. Dit gaat als volgt:
git clone [remote url] --branch [branch_name] --single-branch [folder]Deze specifieke hack is handig als je met langlopende en uiteenlopende branches werkt, of als je veel branches hebt en met maar een paar branches hoeft te werken. Als je maar een handvol branches hebt met heel weinig verschillen, dan zul je waarschijnlijk geen groot verschil zien als je deze bewerking gebruikt.
Repository's met enorme binary assets beheren
Het tweede type grote repository is die met grote binary assets. Dit is iets dat heel verschillende soorten softwareteams (en niet-softwareteams!) tegenkomen. Gameteams moeten verschillende gigantische 3D-modellen gebruiken, teams voor webontwikkeling moeten mogelijk onbewerkte assets volgen en CAD-teams moeten mogelijk de status van de te leveren binaire bestanden manipuleren en volgen.
Git is niet uitzonderlijk slecht in het verwerken van binary assets, maar ook niet bijzonder goed. Git zal standaard alle volgende volledige versies van de binary assets comprimeren en opslaan, wat uiteraard niet optimaal is als je er veel hebt.
Er zijn enkele eenvoudige aanpassingen die de situatie verbeteren, zoals het uitvoeren van de afvalinzameling ('git gc'), of het aanpassen van het gebruik van delta-commits voor sommige binaire types in .gitattributes.
Maar het is belangrijk om na te denken over de aard van de binary assets van je project, want dat zal je helpen de meest succesvolle aanpak te bepalen. Hier zijn bijvoorbeeld een aantal punten die je kunt overwegen:
- Voor binaire bestanden die aanzienlijk veranderen, en niet alleen voor sommige koppen met metagegevens, zal de deltacompressie waarschijnlijk nutteloos zijn. Gebruik dus 'delta off' voor die bestanden om onnodige deltacompressie te vermijden als onderdeel van het opnieuw inpakken.
- In het bovenstaande scenario is het waarschijnlijk dat die bestanden ook niet zo goed worden gecomprimeerd door zlib, dus je kunt compressie uitschakelen met 'core.compression 0' of 'core.loosecompression 0'. Dat is een globale instelling die een negatief effect zou hebben op alle niet-binaire bestanden die daadwerkelijk goed worden gecomprimeerd, dus dit is logisch als je de binary assets opsplitst in een aparte repository.
- Het is belangrijk om te onthouden dat 'git gc' de 'gedupliceerde' losse objecten omzet in enkel pakketbestand. Maar nogmaals, tenzij de bestanden op een of andere manier worden gecomprimeerd, zal dat waarschijnlijk geen significant verschil maken in het resulterende pakketbestand.
- Ontdek de tuning van 'core.bigFileThreshold'. Alles groter dan 512 MB wordt hoe dan ook niet delta-gecomprimeerd (zonder dat je .git-attributen hoeft in te stellen) dus misschien is dat iets wat de moeite waard is om aan te passen.
Oplossing voor grote mappenstructuren: git sparse-checkout
Een milde oplossing voor het probleem met binary assets is de optie sparse checkout in Git (beschikbaar vanaf Git 1.7.0). Met deze techniek is het mogelijk om de werkmap schoon te houden door expliciet aan te geven welke mappen je wilt vullen. Helaas heeft dat geen invloed op de grootte van de totale lokale repository, maar het kan handig zijn als je een enorme structuur met mappen hebt.
Wat zijn de bijbehorende opdrachten? Hier is een voorbeeld:
- De volledige repository één keer klonen: 'git clone'
- Activeer de functie: 'git config core.sparsecheckout true'
- Mappen toevoegen die expliciet nodig zijn, waarbij mappen met assets genegeerd worden:
- echo src/ › .git/info/sparse-checkout
- De boom lezen zoals aangegeven:
- git read-tree -m -u HEAD
Na het bovenstaande kun je teruggaan om je normale Git-opdrachten te gebruiken, maar je werkmap bevat alleen de mappen die je hierboven hebt opgegeven.
Oplossing om te bepalen wanneer je grote bestanden bijwerkt: submodules
[UPDATE] … of je kunt dat allemaal overslaan en Git LFS gebruiken
Als je regelmatig met grote bestanden werkt, is de beste oplossing misschien om gebruik te maken van de ondersteuning voor grote bestanden (LFS) die Atlassian in 2015 samen met GitHub heeft ontwikkeld. (Ja, dat heb je goed gelezen. We werkten samen met GitHub aan een opensourcebijdrage aan het Git-project.)
Git LFS is een extensie die pointers bewaart (natuurlijk!) naar grote bestanden in je repository, in plaats van de bestanden zelf daar op te slaan. De eigenlijke bestanden worden opgeslagen op een externe server. Zoals je je kunt voorstellen, verkort dit aanzienlijk de tijd die nodig is om je repo te klonen.
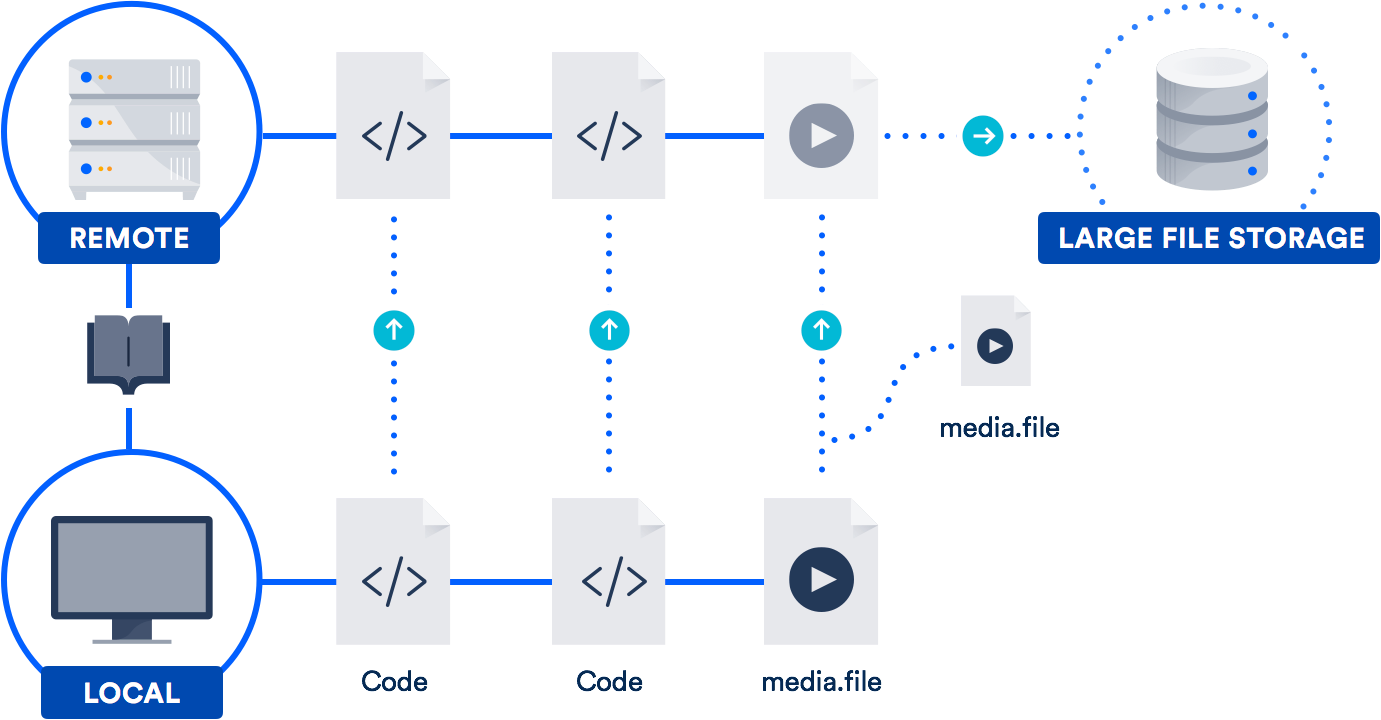
Bitbucket ondersteunt Git LFS, net als GitHub. De kans is dus groot dat je al toegang hebt tot deze technologie. Het is vooral nuttig voor teams met ontwerpers, videografen, muzikanten of CAD-gebruikers.
Conclusies
Geef de fantastische mogelijkheden van git niet op omdat je een enorme repository of enorme assets hebt. Er zijn werkbare oplossingen voor beide problemen.
Bekijk de andere artikelen waar ik hierboven naar heb gelinkt voor meer informatie over submodules, projectafhankelijkheden en Git LFS. En voor een opfriscursusje over opdrachten en workflows staan er op onze Git-microsite heel veel tutorials. Veel plezier met coderen!
Deel dit artikel
Volgend onderwerp
Aanbevolen artikelen
Bookmark deze resources voor meer informatie over soorten DevOps-teams of voor voortdurende updates over DevOps bij Atlassian.

Bitbucket-blog

DevOps-leertraject
