Wat is een gedistribueerd systeem?
Een overzicht van gedistribueerde systemen en microservice-architecturen

Kev Zettler
Full Stack Web Developer
Een gedistribueerd systeem is een verzameling computerprogramma's die computingbronnen gebruiken van meerdere, afzonderlijke computingnodes om een gemeenschappelijk doel te bereiken. Gedistribueerde systemen zijn bedoeld om knelpunten of centrale storingspunten van een systeem te verwijderen.
Wat gebeurt er als je een toepassing maakt als een enkele, implementeerbare eenheid die redelijk goed werkt, maar die in de loop van de tijd steeds groter en complexer wordt? Het wordt vaak steeds lastiger om die toepassing te onderhouden, de ontwikkelingssnelheid vertraagt en het risico op storingen neemt toe. In dit geval is het gebruikelijk dat de monoliet evolueert naar een gedistribueerd systeem. Meestal is dit een microservice-architectuur.

Compass gratis uitproberen
Verbeter je ontwikkelaarservaring, catalogiseer alle services en verbeter de gezondheid van je software.
Wat is een gedistribueerd systeem?
Een gedistribueerd systeem is een verzameling computerprogramma's die computingbronnen gebruiken van meerdere, afzonderlijke computingnodes om een gemeenschappelijk doel te bereiken. Dit wordt ook wel distributed computing of gedistribueerde databases genoemd. Hierbij vertrouwt het systeem op afzonderlijke nodes om te communiceren en te synchroniseren via een gemeenschappelijk netwerk. Deze nodes staan doorgaans voor afzonderlijke fysieke hardwareapparaten, maar kunnen ook afzonderlijke softwareprocessen of andere recursieve ingekapselde systemen zijn. Gedistribueerde systemen zijn bedoeld om knelpunten of centrale storingspunten van een systeem te verwijderen.
Gedistribueerde computersystemen hebben de volgende kenmerken:
Gedeelde resources — Een gedistribueerd systeem kan hardware, software of gegevens delen
Gelijktijdige verwerking — Meerdere machines kunnen dezelfde functie tegelijkertijd verwerken
Schaalbaarheid — De computer- en verwerkingscapaciteit kan waar nodig worden geschaald wanneer extra machines worden toegevoegd
Foutdetectie — Storingen kunnen gemakkelijker worden opgespoord
Transparantie — Een node kan toegang krijgen tot en communiceren met andere nodes in het systeem
gerelateerd materiaal
Microservices vs. monolithische architectuur
Oplossing bekijken
Verbeter je DevEx met Compass
Wat is het verschil tussen een gecentraliseerd systeem en een gedistribueerd systeem?
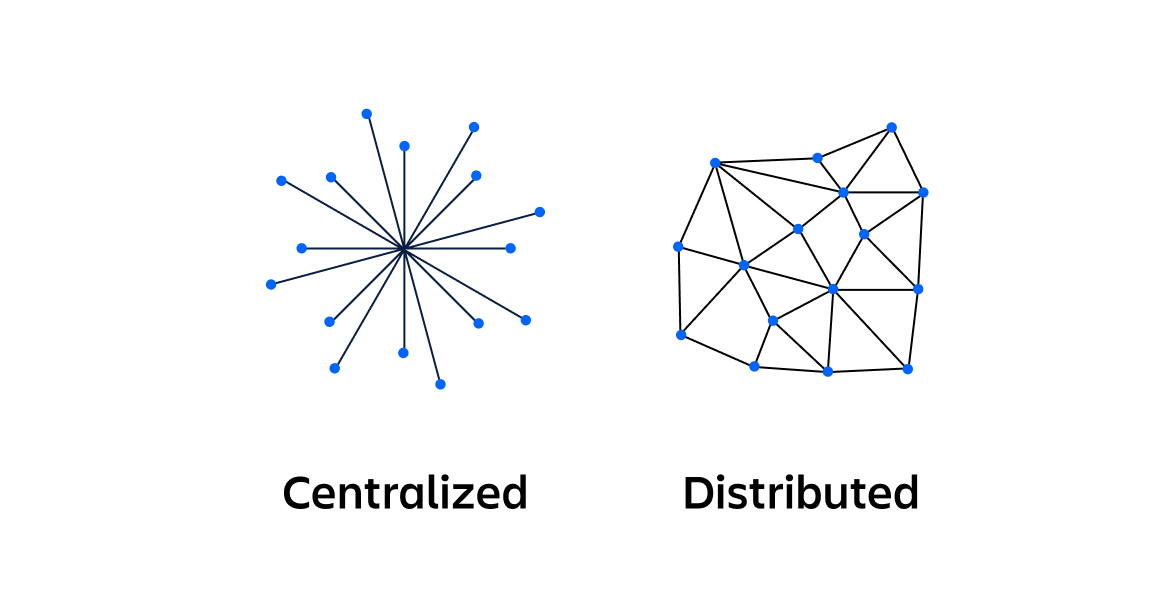
Bij een gecentraliseerd computersysteem wordt alle computing uitgevoerd door één computer op één locatie. Het belangrijkste verschil tussen gecentraliseerde en gedistribueerde systemen is het communicatiepatroon tussen de nodes van het systeem. De status van een gecentraliseerd systeem bevindt zich in een centrale node waar clients toegang toe krijgen aan de hand van hun rechten. Nodes van een gecentraliseerd systeem hebben allemaal toegang tot het centrale knooppunt, wat kan leiden tot verstoppingen en traagheid van het netwerk. Een gecentraliseerd systeem heeft één point of failure, terwijl een gedistribueerd systeem geen enkele point of failure heeft.
Zijn gedistribueerde systemen hetzelfde als microservices?
Een microservices-architectuur is een bepaald type gedistribueerd systeem, omdat het een toepassing opdeelt in afzonderlijke componenten (services). Een microservice-architectuur kan bijvoorbeeld services bevatten voor bedrijfsfuncties (betalingen, gebruikers, producten, enz.) waarbij elke component de bedrijfslogica voor die verantwoordelijkheid verwerkt. Het systeem bevat dan meerdere redundante kopieën van de services, zodat er geen centrale point of failure is voor een service.
Wat is gedistribueerde tracering?
Gedistribueerde tracering is een methode die wordt gebruikt om het resultaat van een aanvraag die wordt uitgevoerd in een gedistribueerd systeem te profileren of te bewaken. Het monitoren van een gedistribueerd systeem kan een uitdaging zijn omdat elke afzonderlijke node zijn eigen afzonderlijke logboeken en statistieken heeft. Om een nauwkeurig beeld te krijgen van een gedistribueerd systeem, moeten deze afzonderlijke nodestatistieken worden samengevoegd in een holistische weergave.
Bij verzoeken aan gedistribueerde systemen wordt over het algemeen geen gebruik gemaakt van de volledige set nodes binnen het systeem, maar in plaats daarvan wordt een deel van deze nodes of een pad door de nodes gebruikt. Bij gedistribueerde tracering worden veelgebruikte paden verlicht via een gedistribueerd systeem, zodat teams deze paden kunnen analyseren en bewaken. Gedistribueerde tracering is ingebouwd in elke node van het systeem. Teams kunnen vervolgens het systeem vragen om informatie over de status van nodes en de prestaties van de aanvraag.
Voordelen, nadelen en risico's van gedistribueerde systemen
Gedistribueerde systemen zorgen vaak voor meer betrouwbaarheid en betere prestaties van het systeem. De betrouwbaarheid wordt verbeterd door centrale points of failure en knelpunten weg te nemen. De nodes van een gedistribueerd systeem bieden redundantie, zodat als een node uitvalt, andere nodes de last van de defecte node kunnen overnemen. De prestaties worden verbeterd omdat nodes eenvoudig horizontaal en verticaal kunnen worden geschaald. Als een systeem zwaar wordt belast, kunnen extra nodes worden toegevoegd om de last te verdelen. De capaciteit van een individuele node kan ook worden uitgebreid om een zwaardere belasting aan te kunnen.
Het nadeel hiervan kan echter een te uitgebreide ontwikkeling zijn, waarbij een systeem te complex wordt en steeds meer en lastiger onderhoud nodig is. Naarmate een systeem complexer wordt, kan het voor teams lastig zijn om deze systemen effectief te organiseren, te beheren en te verbeteren. Een deel van het probleem is het overzicht van hoe verschillende componenten zich tot elkaar verhouden of wie een bepaalde softwarecomponent bezit. Hierdoor is het lastig te zien hoe wijzigingen in componenten kunnen worden aangebracht die zorgen voor een optimale operationele gezondheid en die geen negatieve impact hebben op afhankelijke componenten of klanten. Wanneer een systeem meerdere repository's heeft, kunnen gespecialiseerde tools zoals Atlassian's Compass nodig zijn om de code van een gedistribueerd systeem te beheren en te organiseren.
Architecturen van gedistribueerde systemen
Er zijn talloze soorten gedistribueerde systemen. De meest voorkomende zijn:
Client-server
Een client-serverarchitectuur is opgesplitst in twee primaire verantwoordelijkheden. De client is verantwoordelijk voor de presentatie van de gebruikersinterface, die vervolgens via het netwerk verbinding maakt met de server. De server is verantwoordelijk voor het verwerken van bedrijfslogica en statusbeheer. Een client-serverarchitectuur kan eenvoudig een gecentraliseerde architectuur worden als de server niet redundant wordt gemaakt. Een gedistribueerde client-serverinstallatie bevat meerdere servernodes om clientverbindingen te distribueren. De meeste moderne client-serverarchitecturen zijn clients die verbinding maken met een ingekapseld gedistribueerd systeem op de server.
Multi-tier
Een multi-tier architectuur is een uitbreiding van de client-serverarchitectuur. De server in een multi-tier architectuur wordt opgesplitst in granulaire nodes, die extra verantwoordelijkheden loshalen van de backendserver, zoals gegevensverwerking en gegevensbeheer. Deze extra nodes worden gebruikt om langlopende taken asynchroon te verwerken en de resterende back-endknooppunten vrij te maken om te kunnen reageren op clientverzoeken en verbinding te maken met de gegevensopslag.
Peer-to-peer
In een peer-to-peer gedistribueerd systeem bevat elke node de volledige installatie van een toepassing. Er is geen scheiding van de nodes tussen presentatie en gegevensverwerking. Een node bevat de presentatielaag en gegevensverwerkingslagen. De peernodes kunnen de volledige statusgegevens van het hele systeem bevatten.
Het grote voordeel van peer-to-peer-systemen is de extreme redundantie. Wanneer een peer-to-peer-node wordt geïnitialiseerd en online wordt gezet detecteert en verbindt deze node met andere peers en synchroniseert hij de lokale status met de status van het gehele systeem. Dit betekent betekent dat een storing van één node in een peer-to-peer-systeem geen invloed heeft op de andere nodes. Het betekent ook dat een peer-to-peersysteem persistent is.
Servicegerichte architectuur
Een servicegerichte architectuur (SOA) is een voorloper van microservices. Het belangrijkste verschil tussen SOA en microservices is het bereik van nodes; het bereik van microservicenodes bestaat op functieniveau. In microservices bevat een node de bedrijfslogica om een specifieke functieset te verwerken, zoals betalingen. Microservices bevatten meerdere verspreide bedrijfslogicanodes die communiceren met onafhankelijke databasenodes. SOA-nodes omvatten juist een volledige toepassing of bedrijfsdivisie. De servicegrens voor SOA-nodes is doorgaans een volledig databasesysteem binnen de node.
Microservices zijn vanwege hun voordelen een populairder alternatief geworden voor SOA. Microservices zijn veelzijdiger, waardoor teams de functionaliteit van de kleine servicenodes kunnen hergebruiken. Microservices zijn robuuster en maken dynamischer verticaal en horizontaal schalen mogelijk.
Use cases voor gedistribueerde systemen
Veel moderne toepassingen maken gebruik van gedistribueerde systemen. Online en mobiele applicaties met veel verkeer zijn gedistribueerde systemen. Gebruikers maken verbinding met een clientserver, waarbij de client een webbrowser of een mobiele applicatie is. De server is dan zijn eigen gedistribueerde systeem. Moderne webservers volgen een multi-tier systeempatroon. Er wordt een load balancer gebruikt om verzoeken te delegeren aan veel serverlogische nodes die communiceren via een berichtenwachtrijsysteem.
Kubernetes is een populaire tool voor gedistribueerde systemen, omdat het een verzameling containers kan samenvoegen tot een gedistribueerd systeem. De containers maken nodes van het gedistribueerde systeem. Vervolgens orkestreert Kubernetes netwerkcommunicatie tussen de nodes en zorgt het ervoor dat nodes in het systeem horizontaal en verticaal worden geschaald.
Een ander goed voorbeeld van gedistribueerde systemen zijn cryptocurrencies zoals Bitcoin en Ethereum, die peer-to-peer gedistribueerde systemen zijn. Elk node in een cryptocurrency-netwerk is een op zichzelf staande replicatie van de volledige geschiedenis van het grootboek. Wanneer een node online wordt gezet, dan stelt deze zichzelf in door verbinding te maken met andere nodes en het volledige exemplaar van het grootboek te downloaden. Bovendien hebben cryptocurrency's clients of 'wallets' die verbinding maken met de grootboeknodes via het JSON RPC-protocol.
Conclusie...
Gedistribueerde systemen worden op grote schaal gebruikt in de meeste moderne softwaretoepassingen. Sociale media-apps, videostreamingdiensten, e‑-commercesites en nog veel meer worden allemaal aangedreven door gedistribueerde systemen. Gecentraliseerde systemen ontwikkeling zich vanzelf naar gedistribueerde systemen om te kunnen schalen. Het gebruik van microservices is een populaire en algemeen gebruikte manier om een gedistribueerd systeem te bouwen.
Gedistribueerde systemen zijn complexer om te bouwen en onderhouden, maar met Compass van Atlassian streven we ernaar dit zo eenvoudig mogelijk te maken. Compass is een ontwikkelaarsplatform dat je helpt met navigeren door je verspreide architectuur. Deze tool brengt alle losse informatie over engineering-output en de teams die hieraan samenwerken op één centrale, doorzoekbare plek samen.
Deel dit artikel
Volgend onderwerp
Aanbevolen artikelen
Bookmark deze resources voor meer informatie over soorten DevOps-teams of voor voortdurende updates over DevOps bij Atlassian.

Compass-community

Tutorial: Een component aanmaken