Git CI/CD: 5 porad dotyczących repozytoriów Git przyjaznych względem CI
Obierz kurs na sukces — wszystko zaczyna się od repozytorium.

Sarah Goff-Dupont
Główna autorka tekstów
Git i ciągłe dostarczanie można porównać do połączenia czekolady i masła orzechowego — to dwa wspaniałe smaki, które razem są jeszcze lepsze. Takie połączenia czasami spotykamy również w świecie oprogramowania. Chcę podzielić się kilkoma poradami, które pomogą Ci sprawić, by Twoje kompilacje w Bamboo współgrały z Twoimi repozytoriami w Bitbucket. Większość ich interakcji ma miejsce w fazach kompilowania i testowania ciągłego dostarczania, więc będę omawiała głównie proces CI, a nie CD.
1. Przechowuj duże pliki poza repozytorium
Jedną z rzeczy, które można często usłyszeć o Git, jest to, że należy unikać umieszczania dużych plików w repozytorium: plików binarnych, plików multimedialnych, zarchiwizowanych artefaktów itp. To dlatego, że po dodaniu pliku zawsze będzie się on znajdował w historii repozytorium, co oznacza, że za każdym razem, gdy będziesz klonować repozytorium, ten ogromny plik będzie klonowany wraz z nim.
Wydobycie pliku z historii repozytorium jest trudne — proces ten można porównać do wykonania lobotomii na bazie kodu. Taka chirurgiczna ekstrakcja plików zmienia całą historię repozytorium, więc nie masz już jasnego obrazu tego, jakie zmiany zostały wprowadzone i kiedy miały one miejsce. To dobre powody, aby przyjąć ogólną zasadę unikania dużych plików. Co więcej...
Niewprowadzanie dużych plików do repozytoriów Git jest szczególnie ważne z punktu widzenia CI
Za każdym razem, gdy tworzysz kompilację, serwer CI musi sklonować repozytorium do roboczego katalogu kompilacji. Jeśli repozytorium jest przepełnione wieloma dużymi artefaktami, spowalnia to proces i wydłuża czas, przez jaki programiści muszą czekać na wyniki kompilacji.
OK, w porządku. Ale co, jeśli Twoja kompilacja jest zależna od plików binarnych z innych projektów lub dużych artefaktów? To bardzo powszechna sytuacja i prawdopodobnie zawsze tak będzie. Powstaje więc pytanie: jak sobie z nią skutecznie poradzić?
Poznaj rozwiązanie
Tworzenie i obsługa oprogramowania za pomocą Open DevOps
Materiały pokrewne
Dowiedz się więcej o tworzeniu oprogramowania opartym o gałąź główną
Zewnętrzny system przechowywania plików, taki jak Artifactory (dostępny jest dodatek do Bamboo), Nexus lub Archiva, może pomóc w przypadku artefaktów generowanych przez Twój zespół lub współpracujące z Tobą zespoły. Pliki, których potrzebujesz, można ściągnąć do katalogu kompilacji na początku jej tworzenia — tak samo jak biblioteki innych firm, które ściągamy za pomocą Maven lub Gradle.
Dobra rada: jeśli artefakty często się zmieniają, unikaj conocnego synchronizowania dużych plików z serwerem kompilacji — taka opcja może być kusząca, ponieważ wtedy trzeba je przenieść na dysk tylko w czasie kompilacji. Jednak conocne synchronizacje doprowadzą do tego, że kompilacja będzie obejmować nieaktualne wersje artefaktów. Ponadto programiści i tak potrzebują tych plików do tworzenia kompilacji na swoich lokalnych stacjach roboczych. Ogólnie rzecz biorąc, najlepszym podejściem jest po prostu włączenie pobierania artefaktów jako części kompilacji.
Jeśli nie masz jeszcze w sieci zewnętrznego systemu przechowywania plików, najłatwiej skorzystać z obsługi dużych plików (ang. large file support, LFS) oferowanej przez Git.
Git LFS to rozszerzenie, które przechowuje wskaźniki do dużych plików w repozytorium, zamiast przechowywać same pliki. Same pliki są przechowywane na serwerze zdalnym. Jak można sobie wyobrazić, drastycznie skraca to czas klonowania.
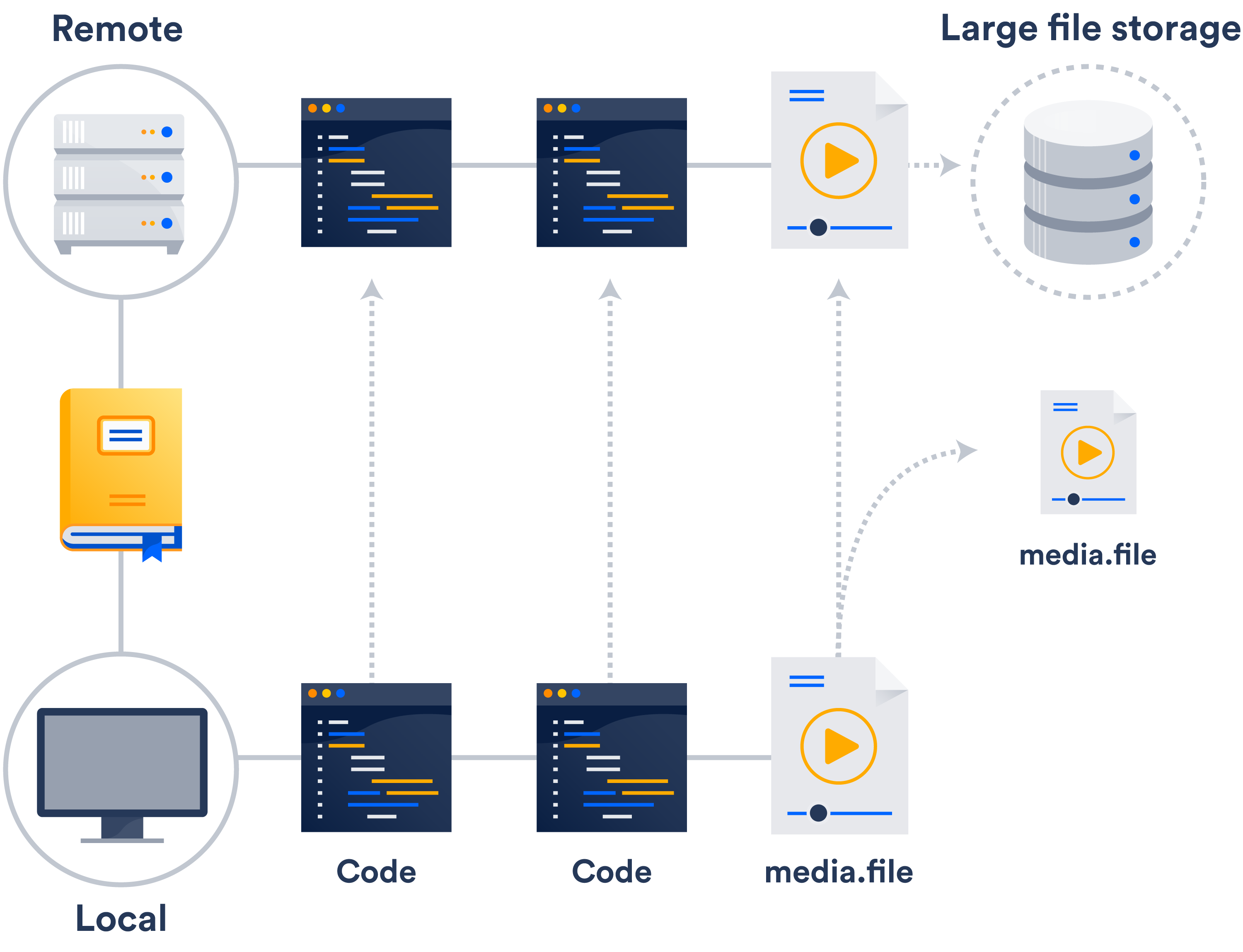
Możliwe, że masz już dostęp do Git LFS — rozszerzenie to obsługują zarówno Bitbucket, jak i GitHub.
2: Używaj płytkiego klonowania na potrzeby CI
Przy każdym uruchomieniu kompilacji serwer kompilacji klonuje repozytorium do bieżącego katalogu roboczego. Jak wcześniej wspomniałam, kiedy Git klonuje repozytorium, domyślnie klonuje jego całą historię. Z biegiem czasu operacja ta będzie naturalnie trwać dłużej i dłużej.
W przypadku płytkiego klonowania zostanie ściągnięta tylko aktualna migawka repozytorium. Może więc ono pomóc w skróceniu czasu kompilacji, szczególnie podczas pracy z dużymi i/lub starszymi repozytoriami.
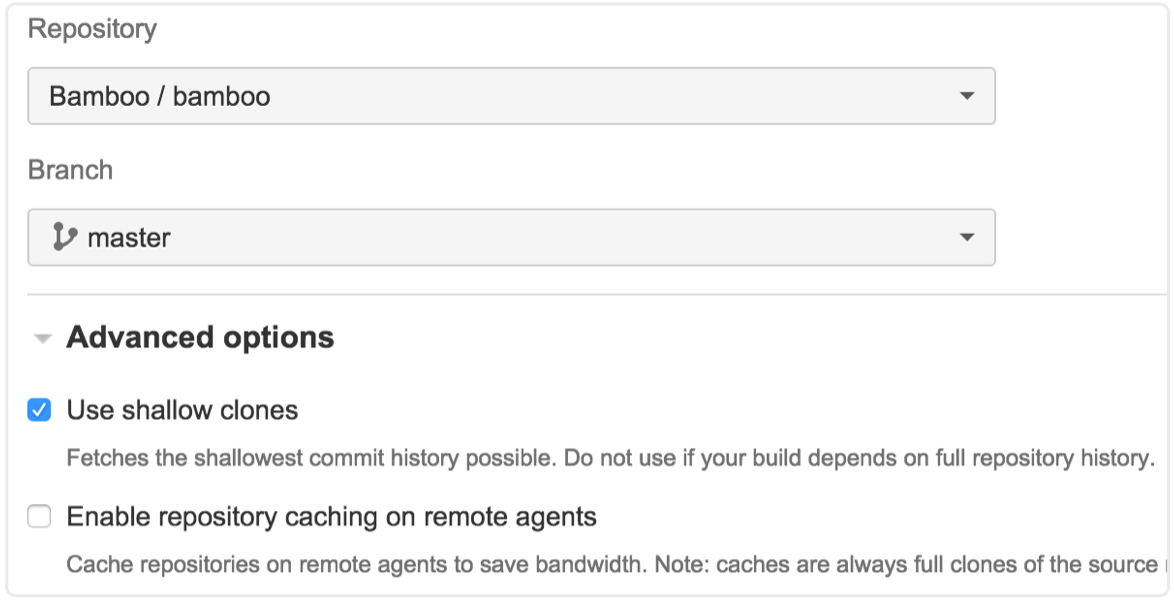
Załóżmy jednak, że Twoja kompilacja wymaga pełnej historii repozytorium — na przykład jeśli podczas jednego z kroków w kompilacji aktualizowany jest numer wersji w POM (lub podobnym rozwiązaniu) lub scalasz dwie gałęzie z każdą kompilacją. W obu tych przypadkach Bamboo musi wypchnąć zmiany z powrotem do repozytorium.
Za pomocą Git proste zmiany w plikach (takie jak aktualizacja numeru wersji) można wypychać bez całej historii. Jednak do scalania nadal potrzebna jest historia repozytorium, ponieważ Git musi spojrzeć wstecz i znaleźć wspólnego przodka dwóch gałęzi — będzie to problem, jeśli Twoja kompilacja używa płytkiego klonowania. Co prowadzi mnie do porady nr 3.
3: Zapisuj repozytorium w pamięci podręcznej agentów kompilacji
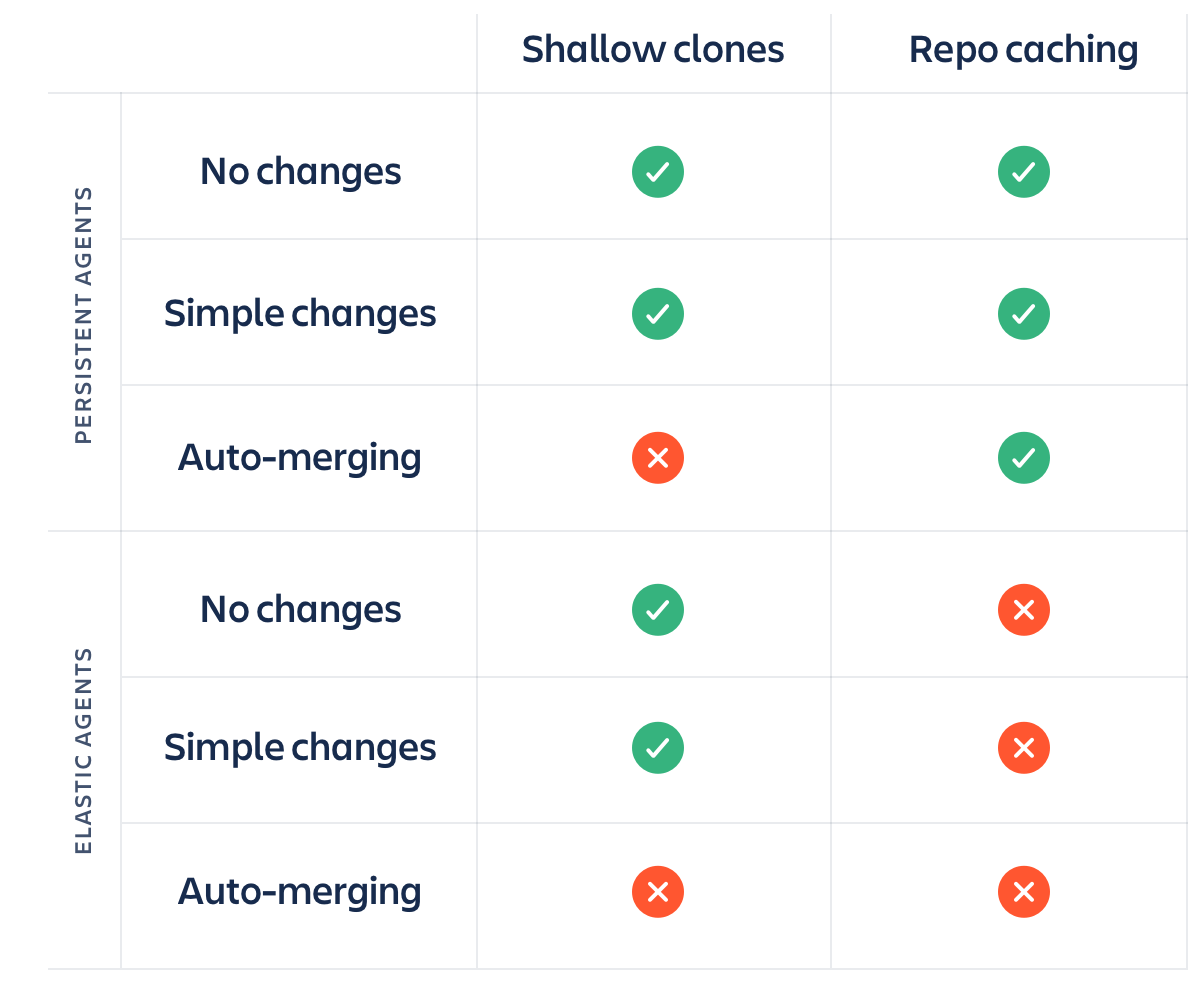
Dzięki temu operacja klonowania jest znacznie szybsza, a Bamboo wykonuje ją domyślnie.
Należy zwrócić uwagę, że zapisywanie repozytorium w pamięci podręcznej przynosi korzyści tylko wtedy, gdy używasz agentów, które utrzymują się od kompilacji do kompilacji. Jeśli tworzysz i usuwasz agenty kompilacji na EC2 lub u innego dostawcy chmury za każdym razem, gdy uruchamiasz kompilację, zapisanie repozytorium w pamięci podręcznej nie będzie miało znaczenia, ponieważ będziesz pracować z pustym katalogiem kompilacji i za każdym razem będzie trzeba ściągnąć pełną kopię repozytorium.
Procesy płytkiego klonowania i zapisywania repozytorium w pamięci podręcznej — w połączeniu z trwałymi i elastycznymi agentami — tworzą interesującą sieć czynników. Oto tablica, która pomoże Ci w opracowaniu strategii.
4: Mądrze wybieraj wyzwalacze
Nie trzeba dodawać, że dobrym pomysłem jest uruchomienie CI we wszystkich aktywnych gałęziach. Ale czy dobrym pomysłem jest uruchamianie wszystkich kompilacji we wszystkich gałęziach względem wszystkich commitów? Raczej nie. Oto dlaczego:
Weźmy na przykład firmę Atlassian. Zatrudniamy ponad 800 programistów, z których każdy wypycha zmiany do repozytorium kilka razy dziennie — są to głównie zmiany w ich gałęziach funkcji. To dużo kompilacji. Jeśli nie skalujesz swoich agentów kompilacji natychmiast i nieskończenie, oznacza to długie oczekiwanie w kolejce.
Na jednym z naszych wewnętrznych serwerów Bamboo znajduje się 935 różnych planów kompilacji. Podłączyliśmy 141 agentów kompilacji do tego serwera i użyliśmy najlepszych praktyk, takich jak przekazywanie artefaktów i paralelizacja testów, aby uczynić każdą kompilację tak wydajną, jak to tylko możliwe. Zapisywanie kompilacji po każdym wypchnięciu nadal powodowało problemy z wydajnością.
Zamiast po prostu skonfigurować kolejną instancję Bamboo z ponad 100 agentami, zadaliśmy sobie pytanie, czy to naprawdę konieczne. Odpowiedź brzmiała: nie.
Daliśmy więc programistom możliwość tworzenia kompilacji gałęzi z przyciskiem polecenia — nie muszą być zawsze wyzwalane automatycznie. To dobry sposób na zrównoważenie rygoru testowania z ochroną zasobów. Gałęzie to obszar, w którym odbywa się większość działań związanych ze zmianami, więc istnieje duża szansa na uzyskanie oszczędności.
Wielu programistów ceni dodatkową kontrolę, którą oferują kompilacje z przyciskiem polecenia, i uważa, że naturalnie pasują one do ich przepływu pracy. Inni wolą nie myśleć o tym, kiedy uruchomić kompilację, i trzymać się automatycznych wyzwalaczy. Oba te podejścia mogą się sprawdzić. Ważne jest, aby najpierw przetestować swoje gałęzie i upewnić się, że masz czystą kompilację przed scaleniem jej z gałęzią nadrzędną.

Kluczowe gałęzie, takie jak główne i stabilne gałęzie wydania, to jednak inna historia. W ich przypadku kompilacje są wyzwalane automatycznie — przez odpytanie repozytorium pod kątem zmian lub przez wysłanie powiadomień push z Bitbucket do Bamboo. Gdy prace są w toku, używamy gałęzi deweloperskich, więc jedynymi commitami trafiającymi do gałęzi głównej powinny być (w teorii) scalane gałęzie deweloperskie. Co więcej, są to wiersze kodu, na podstawie których wydajemy i tworzymy nasze gałęzie deweloperskie. Dlatego naprawdę ważne jest, abyśmy w przypadku każdego scalenia otrzymywali wyniki testów na czas.
5: Przestań odpytywać, zacznij hookować
Odpytywanie repozytorium co kilka minut w poszukiwaniu zmian jest w przypadku Bamboo dość tanią operacją. Jednak kiedy skalujesz w górę do setek kompilacji względem tysięcy gałęzi obejmujących dziesiątki repozytoriów, koszty szybko się sumują. Zamiast obciążać Bamboo procesem odpytywania, możesz skonfigurować Bitbucket w taki sposób, aby wywoływał, kiedy zmiana została wypchnięta i musi zostać uwzględniona w kompilacji.
Zazwyczaj robi się to poprzez dodanie hooka do repozytorium, ale integracja między Bitbucket a Bamboo robi wszystko za Ciebie. Gdy produkty zostaną połączone na poziome zaplecza, wyzwalacze kompilacji sterowane przez repozytorium są gotowe do użycia. Nie są wymagane żadne hooki ani specjalne konfiguracje.
Niezależnie od narzędzi, wyzwalacze sterowane przez repozytorium mają tę zaletę, że automatycznie znikają, gdy docelowa gałąź staje się nieaktywna. Innymi słowy, nigdy nie będziesz marnować cykli procesora swojego systemu CI, odpytując setki porzuconych gałęzi, ani marnować czasu na ręczne wyłączanie kompilacji gałęzi. (Warto jednak zauważyć, że Bamboo można łatwo skonfigurować tak, aby ignorował gałęzie po X dniach braku aktywności, jeśli nadal chcesz korzystać z odpytywania).
Kluczem do używania Git w połączeniu z CI jest...
... zachowanie odpowiedniej uwagi. Jeśli chodzi o wszystkie elementy, które działały świetnie, gdy proces CI był realizowany za pomocą scentralizowanego systemu VCS, to w przypadku Git niektóre z nich będą działały gorzej. Sprawdź więc swoje założenia — to pierwszy krok. Dla klientów Atlassian drugim krokiem jest integracja Bamboo z Bitbucket. Sprawdź naszą dokumentację, aby poznać szczegółowe informacje. Życzymy udanego kompilowania!
Udostępnij ten artykuł
Następny temat
Zalecane lektury
Dodaj te zasoby do zakładek, aby dowiedzieć się więcej na temat rodzajów zespołów DevOps lub otrzymywać aktualności na temat metodyki DevOps w Atlassian.

Społeczność DevOps

Przeczytaj blog