Jak tworzyć mikrousługi
Najlepsze praktyki w zakresie przejścia na architekturę opartą na mikrousługach

Sten Pittet
Menedżer produktu
Załóżmy, że Twoja aplikacja bazuje na jednym kodzie, jest dość duża i monolityczna. Działała doskonale… do czasu. Żałujesz, że aplikacja się nie rozwija, nie jest bardziej odporna, podatna na skalowanie i niezależna pod względem wdrażania. Aby się taka stała, musisz zmienić koncepcję struktury aplikacji na szczegółowym poziomie i przekształcić ją w rozwiązanie oparte na mikrousługach.
Mikrousługi zaczęły zyskiwać na popularności w miarę jak aplikacje stawały się coraz bardziej rozproszone i złożone. Podstawową zasadą mikrousług jest tworzenie aplikacji poprzez podzielenie jej komponentów biznesowych na niewielkie usługi, które można wdrażać i użytkować niezależnie od siebie. Rozdzielenie kontekstów między usługami definiuje się jako „granice usług”.
Granice usług są ściśle powiązane z potrzebami firmy i granicami hierarchii organizacyjnej. Poszczególne usługi mogą być powiązane z odrębnymi zespołami, budżetami i harmonogramami. Wśród przykładowych granic usług można wymienić usługi „przetwarzania płatności” czy „uwierzytelniania użytkowników”. Mikrousługi różnią się od dotychczasowych praktyk w zakresie tworzenia oprogramowania, w których wszystkie komponenty były powiązane ze sobą w jeden pakiet.
W tym dokumencie posłużymy się wymyślonym przykładem startupu — sieci pizzerii o nazwie „Pizzup”, aby zilustrować zastosowanie mikrousług w nowoczesnej firmie zajmującej się tworzeniem oprogramowania.

Wypróbuj Compass bezpłatnie
Ulepsz środowisko programistyczne, skataloguj wszystkie usługi i popraw kondycję oprogramowania.
Jak tworzyć mikrousługi
Krok 1: Zacznij od monolitu
Pierwszą najlepszą praktyką w zakresie mikrousług jest uświadomienie sobie, że prawdopodobnie ich nie potrzebujesz. Jeśli Twoja aplikacja nie ma żadnych użytkowników, może dojść do szybkich zmian wymagań biznesowych w trakcie opracowywania produktu o minimalnej funkcjonalności (MVP). Wynika to po prostu z samej natury procesu tworzenia oprogramowania oraz cyklu informacji zwrotnych, jaki musi zostać wykonany na etapie rozpoznawania kluczowych możliwości biznesowych, jakie Twój system musi oferować. Mikrousługi zwiększają wykładniczo koszty i złożoność zarządzania. W związku z tym w przypadku nowych projektów znacznie tańszym rozwiązaniem będzie utrzymywanie całego kodu i logiki w jednej bazie kodu, gdyż takie rozwiązanie ułatwia przesuwanie granic różnych modułów aplikacji.
Przykładowo w przypadku Pizzup zaczynamy od prostego problemu, który chcemy rozwiązać: chcemy, aby klienci mogli zamawiać pizzę przez Internet.

materiały pokrewne
Porównanie mikrousług z architekturą monolityczną
POZNAJ ROZWIĄZANIE
Ulepsz swoje środowisko programistyczne dzięki narzędziu Compass
Gdy zaczniemy zastanawiać się nad kwestią zamawiania pizzy przez Internet, wskażemy różne możliwości, jakie musi zapewniać nasza aplikacja, aby zaspokoić tę potrzebę. Musimy zarządzać listą różnych dostępnych rodzajów pizzy, umożliwić klientom wybranie jednego lub kilku z nich, dokonanie płatności, zaplanowanie dostawy itp. Możemy zdecydować się na umożliwienie klientom założenia konta, aby ułatwić im ponowne złożenie zamówienia, gdy po raz kolejny zdecydują się skorzystać z oferty Pizzup. Po rozmowie z pierwszymi użytkownikami możemy dojść do wniosku, że przewagę konkurencyjną zapewni nam oferowanie możliwości śledzenia dostawy na żywo i obsługi urządzeń mobilnych.
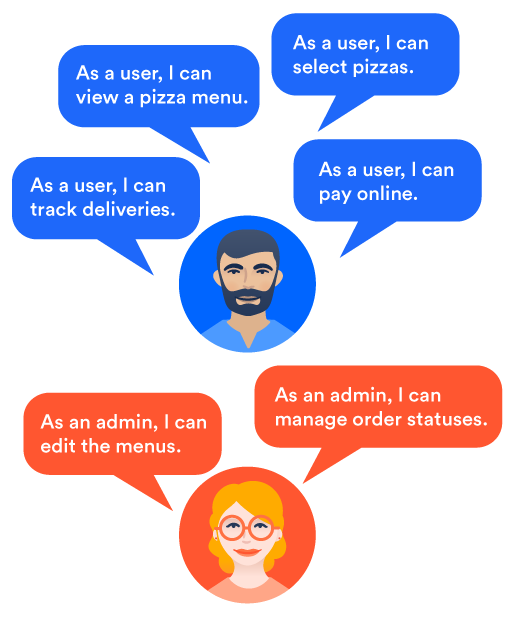
Prosta z początku potrzeba szybko przerodziła się w listę nowych funkcji.
Mikrousługi sprawdzają się najlepiej, gdy wiesz, jakich usług wymaga Twój system. Jednak znacznie trudniej wdraża się je wówczas, gdy podstawowe wymagania aplikacji nie są dobrze zdefiniowane. Przedefiniowanie interakcji między usługami, interfejsów API i struktur danych w mikrousługach jest kosztowne, ponieważ zazwyczaj wymaga ono skoordynowania znacznie większej liczby ruchomych elementów. Dlatego radzimy zachować uproszczone podejście do czasu zebrania wystarczającej liczby opinii użytkowników, aby upewnić się, że podstawowe potrzeby klientów są zrozumiałe i uwzględnione w planach.
Mała przestroga: tworzenie monolitu może szybko doprowadzić do uzyskania złożonego kodu, który trudno będzie podzielić na mniejsze części. Najlepiej precyzyjnie wyznaczyć moduły, które później będzie można wyodrębnić z monolitu. Można również zacząć od wyodrębnienia logiki z interfejsu użytkownika aplikacji i zadbania o to, aby wchodziła ona w interakcję ze środowiskiem backendowym za pośrednictwem interfejsu API REST i protokołu HTTP. Ułatwi to przejście na mikrousługi podczas przenoszenia zasobów API do innych usług.
Krok 2: Zadbaj o właściwą organizację zespołów
Do tego momentu mogło się wydawać, że tworzenie mikrousług jest przede wszystkim kwestią techniczną. Trzeba podzielić bazę kodu na wiele usług, wdrożyć właściwe wzorce, które pozwolą sprawnie obsługiwać awarie i przywracać działanie usług po wystąpieniu problemów z siecią, rozwiązać kwestię spójności danych, monitorować obciążenie usług itp. Będzie trzeba poznać wiele nowych zagadnień. Prawdopodobnie jednak najważniejszą rzeczą, której bezwzględnie nie wolno zignorować, jest konieczność zmiany podejścia do organizacji zespołów.
Prawo Conwaya działa i można je zaobserwować we wszelkiego rodzaju zespołach. Jeśli zespół odpowiedzialny za tworzenie oprogramowania składa się z zespołów pracujących nad backendem i frontendem oraz zespołu operacyjnego, które funkcjonują niezależnie, będzie on zawsze dostarczał monolity frontendu i backendu przerzucane po prostu do zespołu operacyjnego, który wdroży je w środowisku produkcyjnym. Tego rodzaju struktura zespołów nie sprawdzi się w przypadku mikrousług, ponieważ każdą usługę należy potraktować jako odrębny produkt, który musi zostać dostarczony niezależnie od innych.
Zamiast tego tworzy się więc niewielkie zespoły DevOps posiadające wszystkie kompetencje wymagane do opracowania i utrzymania usług, za jakie odpowiadają. Taka organizacja pracy zespołów przynosi wiele korzyści. Po pierwsze, programiści lepiej rozumieją wpływ tworzonego przez siebie kodu na środowisko produkcyjne, co pozwala im opracowywać lepsze wydania i zmniejszyć ryzyko pojawienia się błędów u klientów. Po drugie, wdrożenia stają się rutynowym elementem pracy poszczególnych zespołów, które wspólnie pracują nad udoskonalaniem kodu oraz automatyzacją pipeline'u wdrożeniowego.
Krok 3: Podziel monolit, aby stworzyć architekturę mikrousług
Gdy już wyznaczysz granice swoich usług i opracujesz sposób reorganizacji zespołów, możesz przystąpić do podziału monolitu w celu stworzenia mikrousług. Na tym etapie musisz przemyśleć kilka zagadnień, które przedstawiamy poniżej.
Uproszczenie komunikacji między usługami dzięki interfejsowi API REST
Jeśli jeszcze nie korzystacie z interfejsu API REST, to dobry moment na jego wdrożenie. Jak wyjaśnia Martin Fowler, potrzebujesz „inteligentnych punktów końcowych i głupich rur”. Oznacza to, że protokół komunikacji między usługami powinien być możliwie jak najprostszy i umożliwiać jedynie przesyłanie danych bez ich przekształcania. Cała magia dzieje się w samych punktach końcowych — otrzymują one żądanie, przetwarzają je i przesyłają odpowiedź.
W architekturach mikrousług nacisk kładzie się na maksymalne uproszczenie, pozwalające uniknąć ścisłych powiązań komponentów. W niektórych przypadkach możesz zdecydować się na korzystanie z architektury opartej na zdarzeniach wspomaganej asynchroniczną komunikacją bazującą na wiadomościach. Jednak w tej sytuacji również warto przyjrzeć się podstawowym usługom obsługującym kolejkę wiadomości, takim jak RabbitMQ, aby uniknąć niepotrzebnego komplikowania wiadomości przesyłanych za pośrednictwem sieci.
Podział danych na ograniczone konteksty i domeny danych
Aplikacje monolityczne wykorzystują jedną bazę danych do obsługi wszystkich funkcji biznesowych aplikacji. Gdy monolit zostanie podzielony na mikrousługi, ta pojedyncza baza danych może utracić sens. Centralna baza danych staje się w ten sposób wąskim gardłem w procesie skalowania ruchu. Jeśli konkretna usługa zyska dostęp do bazy danych i znacznie ją obciąży, może spowodować zakłócenie dostępu innych usług do tej bazy. Ponadto jedna baza danych może stać się wąskim gardłem z perspektywy współpracy, gdy wiele zespołów będzie równocześnie próbowało zmodyfikować schemat. Może to być argument za podziałem bazy danych lub wprowadzeniem dodatkowych narzędzi do przechowywania danych w celu zaspokojenia potrzeb związanych z obsługą danych mikrousług.
Reorganizacja monolitycznego schematu bazy danych może być delikatną operacją. Ważne, aby precyzyjnie wskazać zbiory danych potrzebne poszczególnym usługom i pokrywające się obszary. Do takiego planowania schematu można wykorzystać konteksty ograniczone, będące wzorcem zaczerpniętym z podejścia „domain-driven design”. Ograniczony kontekst wyznacza samodzielny system, z uwzględnieniem elementów, które mogą wchodzić do tego systemu i go opuszczać.
W takim systemie, gdy użytkownik otworzy zamówienie, zobaczy w tabeli dane klienta, które można wykorzystać również do uzupełnienia faktury zarządzanej przez system rozliczeń. Może się to wydawać logiczne i proste, jednak w przypadku mikrousług usługi nie powinny być ze sobą połączone, aby można było korzystać z faktur nawet w przypadku awarii systemu składania zamówień. Ponadto takie rozwiązanie umożliwia optymalizowanie lub doskonalenie tabeli faktur niezależnie od innych. Ostatecznie każda usługa może posiadać magazyn danych, który umożliwi jej dostęp do potrzebnych danych.
To rodzi nowe problemy, ponieważ niektóre dane będą dublowane w różnych bazach danych. Ograniczone konteksty pozwalają wskazać najlepszą strategię obsługi współdzielonych lub zdublowanych danych. Można przyjąć architekturę opartą na zdarzeniach, aby ułatwić synchronizację danych na poziomie wielu usług. Przykładowo usługi rozliczeń i śledzenia dostaw mogą nasłuchiwać zdarzeń generowanych przez usługę konta, gdy klient zaktualizuje swoje dane osobowe. Po otrzymaniu zdarzenia usługi te zaktualizują odpowiednio swój magazyn danych. Taka architektura oparta na zdarzeniach umożliwia uproszczenie logiki usługi konta, ponieważ nie musi ona „znać” innych usług zależnych. System otrzymuje po prostu od tej usługi informację o dokonanej czynności, a inne usługi nasłuchują i podejmują odpowiednie działania.
Można również zdecydować się na przechowywanie wszystkich danych klienta w usłudze konta, a w usłudze rozliczeń i dostaw dodać jedynie odwołanie do obcego klucza. Wówczas usługi te będą nawiązywały interakcję z usługą konta, aby pobrać odpowiednie dane klienta, zamiast dublowania istniejących rekordów. Nie ma uniwersalnego sposobu rozwiązania tych problemów, dlatego musisz przyjrzeć się każdemu z przypadków z osobna i ustalić, jakie podejście będzie najlepsze.
Przygotowanie architektury mikrousług na awarie
Omówiliśmy już, jakie korzyści mogą przynieść Ci mikrousługi w porównaniu z architekturą monolityczną. Są mniejsze i bardziej wyspecjalizowane, dzięki czemu łatwiej je zrozumieć. Są rozłączne, co oznacza, że możesz zmodyfikować usługę bez obaw o uszkodzenie innych komponentów systemu lub spowolnienie prac innych zespołów. Dodatkowo zapewniają one programistom większą elastyczność, ponieważ mogą bez obaw sięgać po różne technologie, gdyż nie są ograniczeni potrzebami innych usług.
Krótko mówiąc, architektura mikrousług ułatwia opracowywanie i utrzymywanie rozwiązań obsługujących poszczególne obszary działalności. Jeśli jednak przyjrzymy się usługom razem oraz sposobowi, w jaki wchodzą one we wzajemne interakcje w celu wykonania czynności, sprawa zaczyna się komplikować. Twój system jest teraz rozproszony, przez co powstaje wiele punktów potencjalnych awarii — należy brać to pod uwagę. Musisz uwzględnić nie tylko przypadki, w których usługa nie odpowiada, ale także konieczność radzenia sobie ze spowolnionymi odpowiedziami sieci. Odzyskiwanie po awarii również bywa problematyczne, ponieważ musisz uważać, aby przywrócone usługi nie zostały zalane oczekującymi komunikatami.
Gdy zaczniesz wyodrębniać obszary funkcjonalne z systemów monolitycznych, musisz od początku zwracać uwagę, aby Twoje projekty były tworzone z myślą o awarii.
Nacisk na monitorowanie w celu ułatwienia testowania mikrousług
Testowanie jest kolejną wadą mikrousług w porównaniu z systemem monolitycznym. Skonfigurowanie i uruchomienie środowiska testowego dla aplikacji utworzonej w oparciu o jedną bazę kodu nie jest trudne. W większości przypadków wystarczy uruchomić serwer backendowy połączony z bazą danych, aby móc zainicjować swój pakiet testów.
W świecie mikrousług nie jest to takie łatwe. Testy jednostkowe nadal będą przebiegały dość podobnie, jak w monolicie, i na tym poziomie raczej nie odczujesz większych trudności. Jednak testowanie integracji i systemu jest już znacznie trudniejsze. Może zajść konieczność uruchomienia kilku usług jednocześnie, przygotowania różnych magazynów danych i uwzględnienia w konfiguracji kolejek wiadomości, co nie było konieczne w przypadku monolitu. W związku z tym przeprowadzanie testów funkcjonalnych jest znacznie droższe, a więcej ruchomych elementów bardzo utrudnia przewidywanie różnych rodzajów awarii, do jakich może dojść.
Monitorowanie pozwala wychwycić problemy na wczesnym etapie i stosownie zareagować. Musisz zrozumieć podstawy działania różnych usług i reagować nie tylko wówczas, gdy przestają działać, ale także wtedy, gdy zachowują się w sposób nieoczekiwany. Zaletą przyjęcia architektury mikrousług jest jednak to, że system powinien być odporny na częściowe awarie. Jeśli więc zaczniesz dostrzegać nieprawidłowości w usłudze śledzenia dostaw aplikacji Pizzup, konsekwencje nie będą tak poważne, jak w przypadku systemu monolitycznego. Nasza aplikacja powinna być zaprojektowana tak, aby wszystkie inne usługi reagowały właściwie, a klienci mogli dalej zamawiać pizzę, podczas gdy my będziemy przywracać funkcję śledzenia na żywo.
Opanowanie ciągłego dostarczania w celu ograniczenia konfliktów przy wdrożeniach
Ręczne wydawanie systemu monolitycznego do produkcji jest żmudnym i ryzykownym zajęciem, ale da się to zrobić. Naturalnie nie zalecamy tego podejścia i zachęcamy każdy zespół zajmujący się tworzeniem oprogramowania do wdrożenia ciągłego dostarczania w odniesieniu do wszystkich rodzajów prac rozwojowych, jednak na początku projektu swoje pierwsze wdrożenia możesz wykonać samodzielnie za pośrednictwem wiersza poleceń.
Gdy rośnie liczba usług, które trzeba wdrażać wiele razy dziennie, takie podejście przestaje mieć sens. Dlatego tak ważne jest, aby w ramach przejścia na mikrousługi opanować ciągłe dostarczanie, a tym samym zmniejszyć ryzyko nieudanych wydań oraz dać zespołowi możliwość skoncentrowania się na tworzeniu i utrzymaniu aplikacji, a nie jej żmudnym wdrażaniu. Praktykowanie ciągłego dostarczania oznacza również, że usługa przeszła testy akceptacji przed przekazaniem do produkcji. Błędy będą się oczywiście pojawiać, jednak z czasem stworzysz niezawodny pakiet testów, dzięki któremu zespół zyska większą pewność co do jakości wydań.
Uruchamianie mikrousług nie jest sprintem
Mikrousługi są popularną i szeroko stosowaną praktyką w branży. W przypadku złożonych projektów zapewniają one większą elastyczność tworzenia i wdrażania oprogramowania. Ułatwiają również identyfikację i formalizację komponentów biznesowych systemu, co przydaje się, gdy kilka zespołów pracuje nad tą samą aplikacją. Jednak zarządzanie systemami rozproszonymi ma też pewne oczywiste wady, dlatego architekturę monolityczną należy dzielić tylko wówczas, gdy precyzyjnie zdefiniowane są granice usług.
Tworzenie mikrousług należy postrzegać raczej jako proces niż bezpośredni cel zespołu. Zacznij od drobnych kroków, aby zrozumieć wymagania techniczne systemu rozproszonego, możliwości mało kłopotliwej obsługi awarii oraz proces skalowania poszczególnych komponentów. Potem w miarę zdobywania doświadczenia i wiedzy możesz stopniowo wyodrębniać więcej usług.
Przejście na architekturę mikrousług nie musi się odbyć za jednym razem. Znacznie bezpieczniejsza będzie strategia iteracyjna, zakładająca przenoszenie po kolei mniejszych elementów do mikrousług. Wyznacz najlepiej zdefiniowane granice usług w opracowanej aplikacji monolitycznej i na zasadzie iteracyjnej przekształcaj je w samodzielne mikrousługi.
Wnioski…
Podsumowując, mikrousługi są strategią korzystną zarówno dla czysto technicznego procesu tworzenia kodu, jak i dla ogólnej strategii organizacji biznesowej. Mikrousługi ułatwiają organizowanie zespołów w jednostki skoncentrowane na opracowaniu i posiadaniu konkretnych funkcji biznesowych. Takie szczegółowe podejście poprawia wydajność i ogólną jakość komunikacji w firmie. Korzyści, jakie przynoszą mikrousługi, mają jednak swoją cenę. Ważne, aby przed przejściem na architekturę mikrousług wyraźnie zdefiniować granice usług.
Choć architektura mikrousług przynosi wiele korzyści, prowadzi ona również do zwiększenia stopnia złożoności. Firma Atlassian opracowała narzędzie Compass, aby pomóc firmom w zarządzaniu złożonościami architektur rozproszonych w miarę ich skalowania. Jest to rozszerzalna platforma środowiska programistycznego, która w centralnej lokalizacji z możliwością wyszukiwania łączy wszystkie niepowiązane informacje o wynikach prac inżynierskich i współpracy zespołowej.
Udostępnij ten artykuł
Następny temat
Zalecane lektury
Dodaj te zasoby do zakładek, aby dowiedzieć się więcej na temat rodzajów zespołów DevOps lub otrzymywać aktualności na temat metodyki DevOps w Atlassian.

Społeczność rozwiązania Compass

Samouczek: Tworzenie komponentu