Правило автоматизации Jira при слиянии запроса pull
Posted by: Matt David
Business intelligence, as we know it today, would not be possible without the data warehouse.
At its core, business intelligence is the ability to answer complex questions about your data and use those answers to make informed business decisions. In order to do this well, you need a data warehouse, which not only provides a safe way to centralize and store all your data but also a method to quickly find the answers you need, when you need them.
And that’s a pretty important role. By 2025, it’s estimated humanity will have produced a total of 175 zettabytes of data. For context, that’s 175,000,000,000 terabytes.
Where does all of this information go? Well, most of it goes in the data warehouses.
Companies use data warehouses to manage transactions, understand their data, and keep it all organized. In short, data warehouses make large amounts of information more usable for organizations of all sizes and types.
This has made them a linchpin of data pipelines and business intelligence systems the world over. And understanding how data warehouses work can help you fulfill the full potential of business intelligence (it’s not as complex as it may seem).
What is a data warehouse?
A data warehouse is a data management system that stores large amounts of data for later use in processing and analysis. You can think of it as a large warehouse where trucks (i.e., source data) unload their data. That data is then sorted into rows and rows of well-organized shelves that make it easy to find exactly what you’re looking for later.
The biggest innovation data warehouses introduced at their inception, according to DW 2.0: The Architecture for the Next Generation of Data Warehousing, was the ability to store “integrated granular historical data.”
Breaking that down into human terms, this means data warehouses excel at storing data that’s:
- Integrated: They combine data from many databases and data sources.
- Granular: The data they house is highly detailed and can be used in many different ways.
Historical: They can host a continuous record of data over years and years.
You can store this data in three different ways: on-premise data warehouses, cloud data warehouses, and hybrid data warehouses.
On-premise data warehouses run on physical servers that your company owns and manages. Cloud data warehouses are fully online, and you pay for space on servers that another company manages, like Amazon Redshift. Hybrid data warehouses are a mix of both on-premise and cloud, and companies making the transition to the cloud over a period of time use this option.
With all the data stored in one place, data warehouses use a specific approach to process data called online analytical processing (OLAP), which is specifically designed for complex queries.
One way to think about it is that when you go to your data warehouse to ask a question about the relationship between one set of data and another, OLAP is a way of organizing and moving among the rows and rows of shelves to quickly find that information.
This is great for business intelligence because the questions you ask about your data in order to make decisions are rarely simple. Because data warehouses use OLAP, they make finding answers to these complex questions very efficient. As a result, they’ve become a foundation for many successful business intelligence systems.
За рамками Agile
In business intelligence, data warehouses serve as the backbone of data storage. Business intelligence relies on complex queries and comparing multiple sets of data to inform everything from everyday decisions to organization-wide shifts in focus.
To facilitate this, business intelligence is comprised of three overarching activities: data wrangling, data storage, and data analysis. Data wrangling is usually facilitated by extract, transform, load (ETL) technologies, which we’ll explain in detail below, and data analysis is done using business intelligence tools, like Atlassian Analytics.
The glue holding this process together is data warehouses, which serve as the facilitator of data storage using OLAP. They integrate, summarize, and transform data, making it easier to analyze.
Even though data warehouses serve as the backbone of data storage, they’re not the only technology involved in data storage. Many companies go through a data storage hierarchy before reaching the point where they absolutely need a data warehouse.
За рамками Agile
As we explain in our Cloud Data Management eBook (a super easy — and dare we say fun — read), there are generally four stages of data sophistication: source data, data lakes, data warehouses, and data marts. Knowing when to invest in a data warehouse requires you to know each stage, but at the end of the day, the data warehouse stage is what unlocks the true power of your data.
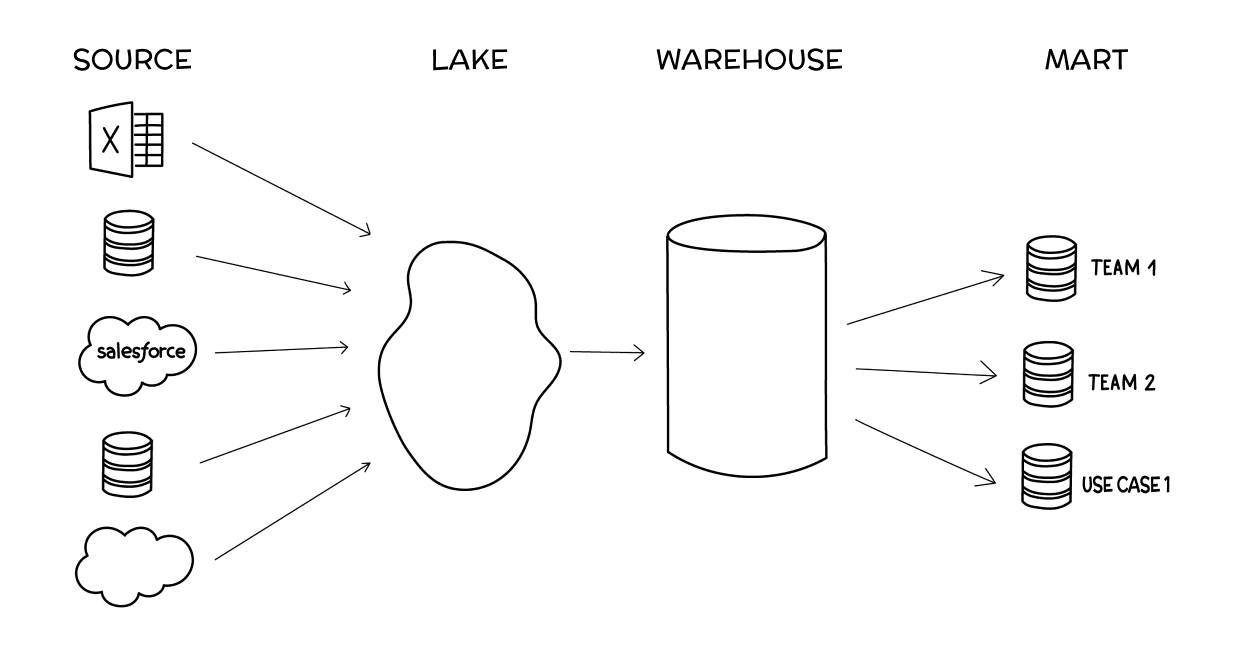
Source data
Source data is any individual set of data like databases, Excel spreadsheets, individual application reports, etc. It’s structured (i.e., organized) yet siloed data that works fine alone but does not provide a larger picture of your organization’s data as a whole.
Data lake
For teams who have graduated to a need to centralize their source data into one place, a data lake is increasingly becoming the next step. A data lake serves as a central repository for all raw, unstructured (i.e., not organized) data.
If a data warehouse is like backing up a truck and unloading the data in an orderly fashion into a well-organized shelving system, data lakes are like backing the truck up and dumping all the data into, well, a lake. James Dixon, who coined the term “data lake”, describes it as the natural raw state of data that, for people with the diving skills, serves as a frontier to explore.
The drawback of a data lake is that the data is not ready for analysis. It’s not well-organized, there may be duplicates, and in order to make sense of it, you’ll need to tell your diver exactly what you’re looking for. Even then, the diver might not find exactly what you need after all that effort.
Data warehouse
Like a data lake, a data warehouse centralizes your data, but as we’ve established, it’s well-organized and set up for efficient analysis. It’s a single source of truth for all data that’s easier to understand and navigate.
Data warehouses can hook right up to source data, but nowadays, we’re seeing more and more companies use their data warehouse as a layer on top of their data lake. Following Dixon’s comparison, if a data lake is the water/data in its natural, unorganized state, a data warehouse is where you treat it and make it ready for consumption.
Data mart
Using a data warehouse for some projects can be like swatting a fly with a sledgehammer. If, for instance, the marketing team returns time and time again to the warehouse to make similar queries, you can set up a data mart.
Data marts are curated data sets created for specific use cases. Again, bringing up Dixon’s description, the marketing team doesn’t need to go to the treatment center every time they need water. The data warehouse can be used to package data/water into ready-to-drink “water bottles.”
In this data storage ecosystem, the data warehouse is still the backbone. It’s structured and relatively easy to understand (like source data), yet it provides a holistic, centralized view (like a data lake), making it much easier to use that data however you need (like creating data marts).
За рамками Agile
Data warehouses are fairly complex systems but can be thought of as encompassing three core aspects: storage, software, and labor. When making the decision to implement a data warehouse, you need to take into account the investment required for all three.
Storage is a fairly simple choice. As we mentioned earlier, you can host your data warehouse on-premises, in the cloud, or use a hybrid approach. On-premises hosting is, according to some, on its way out. Cloud hosting is much cheaper and more flexible because you’re renting space on another’s server. You don’t need to run maintenance, you can expand and cut back as needed, and there is an ever-expanding set of features added each year. Bridging the gap between these two approaches is hybrid hosting, which, as we mentioned before, is the preferred choice for companies migrating from on-premises to cloud hosting.
To get data into your data warehouse, you need to use a type of software commonly called ETL software. Extract, transform, load (ETL) is a process where the data is extracted, made ready for use, then loaded into the data warehouse.
Nowadays, we recommend and see many more companies using an alternative to ETL called extract, load, transform (ELT). Often companies will extract data from source data, load it into a data lake, then use data warehouses to transform the data. Both ETL and ELT are facilitated with software like Panoply.io and Stitch. If you’d like to learn more, check out our detailed resource on ETL, ELT, and even ETLT.
Of course, data warehouses don’t run themselves. Labor is a significant part of keeping a data warehouse running because it’s not just a system; it’s a “full-fledged…architecture” that requires experts to set up and manage.
The purpose of all this work is to centralize and organize data, so it can be more easily understood. This is where business intelligence tools come in. They essentially sit atop the data warehouses as a layer that helps you query, analyze, and visualize your data.
За рамками Agile
While data warehouses store data, business intelligence platforms analyze data. When you get these two systems to work together seamlessly, you’ll unlock the full benefits of business intelligence.
Business intelligence tools fulfill the “data analysis” stage of business intelligence, but they get their name because they’re the culmination of the other two steps: data wrangling and data storage.
First, business intelligence tools integrate with many different sources, including your data warehouse. They then provide an easy way to query the data in order to analyze data for trends and insights. Then, they make it easy to visualize and share data using dashboards and reports.
These three steps, built on top of a good data warehouse foundation, will make it easier to follow through on the core promise of business intelligence: providing everyone in your organization with the ability to understand and act on data.
За рамками Agile
Once your data warehouse is in place, go ahead and connect it to your business intelligence platform. Atlassian Analytics makes it as simple as possible with two ways to connect: direct connection or SSH tunnel connection.
Direct connection
- Whitelist Atlassian Analytics's IP address.
- Fill out the form in Atlassian Analytics’s “Add a Data Source” page.
- You’re connected!
SSH tunnel connection
- Create an SSH Key.
- Install AutoSSH on your server.
- Add Atlassian Analytics as a read-only user.
- Fill out the form in Atlassian Analytics’s “Add a Data Source” page under the “SSH Tunnel tab.”
- You’re connected!
- Create a crontab entry to confirm.
Once connected, you can easily query and analyze your data from your data warehouse, gaining an enterprise-level view of your data pipeline.