Правило автоматизации Jira при слиянии запроса pull
Last modified: October 22, 2019
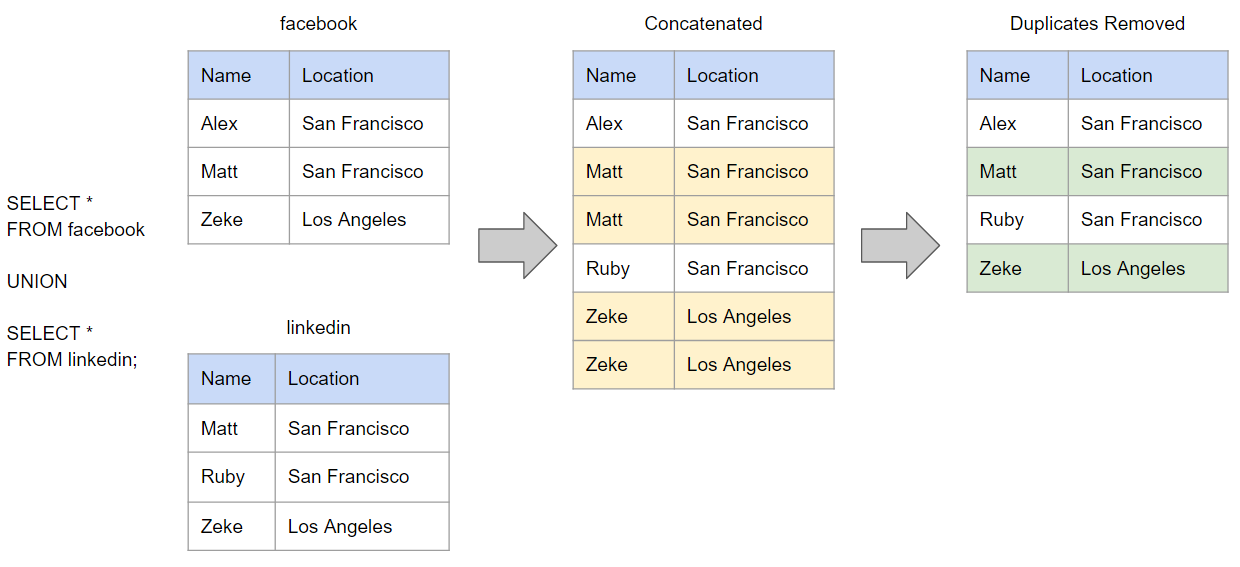
UNION and UNION ALL are SQL operators used to concatenate 2 or more result sets. This allows us to write multiple SELECT statements, retrieve the desired results, then combine them together into a final, unified set.
The main difference between UNION and UNION ALL is that:
- UNION: only keeps unique records
UNION ALL: keeps all records, including duplicates
За рамками Agile
UNION
UNION ALL
If we were to now perform the UNION ALL on the same data set, the query would skip the deduplication step and return the results shown.
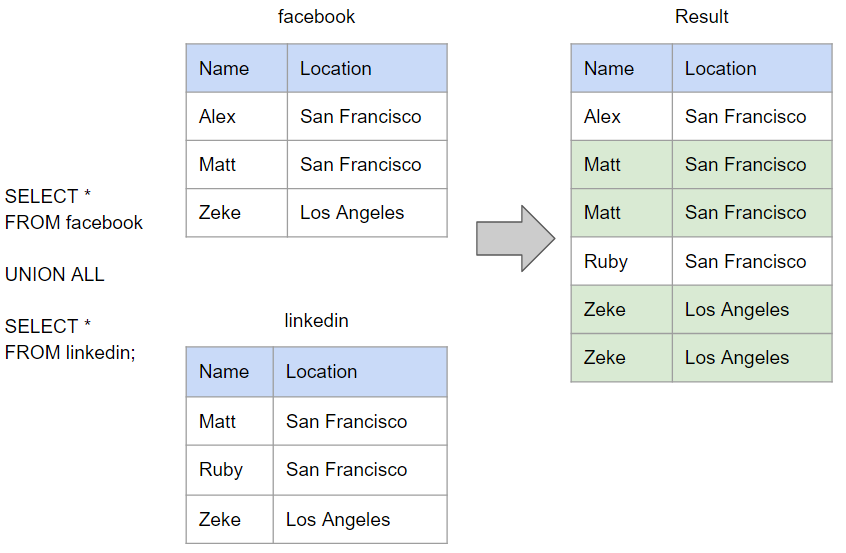
*Note: In both of these examples, the field names from the first SELECT statement are retained and used as the field names in the result set. These can be changed later if desired.
За рамками Agile
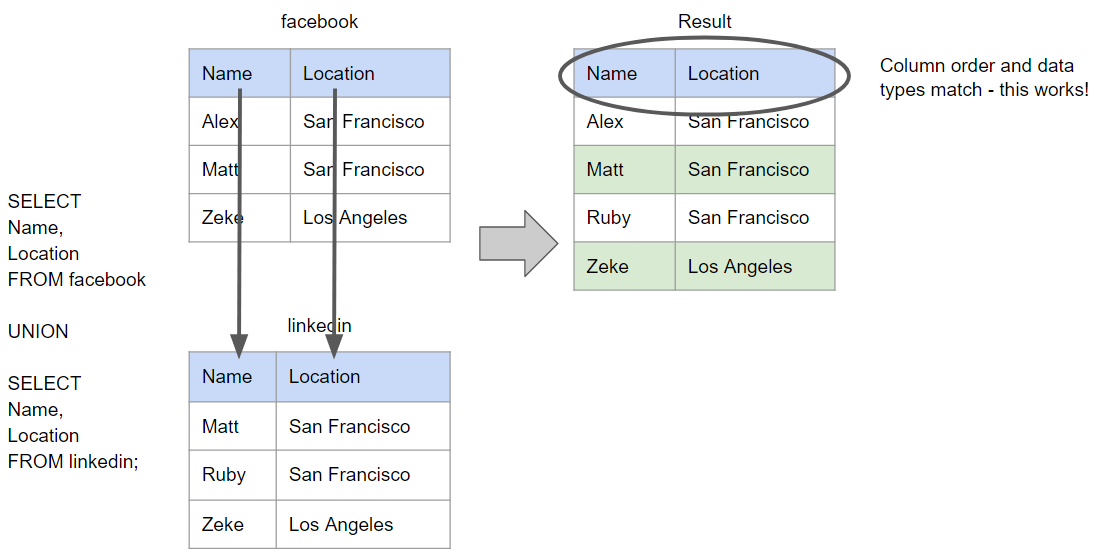
UNION or UNION ALL have the same basic requirements of the data being combined:
- There must be the same number of columns retrieved in each SELECT statement to be combined.
- The columns retrieved must be in the same order in each SELECT statement.
- The columns retrieved must be of similar data types.
The next 2 examples shows that we would return results whether we used UNION or UNION ALL since all required criteria are met.
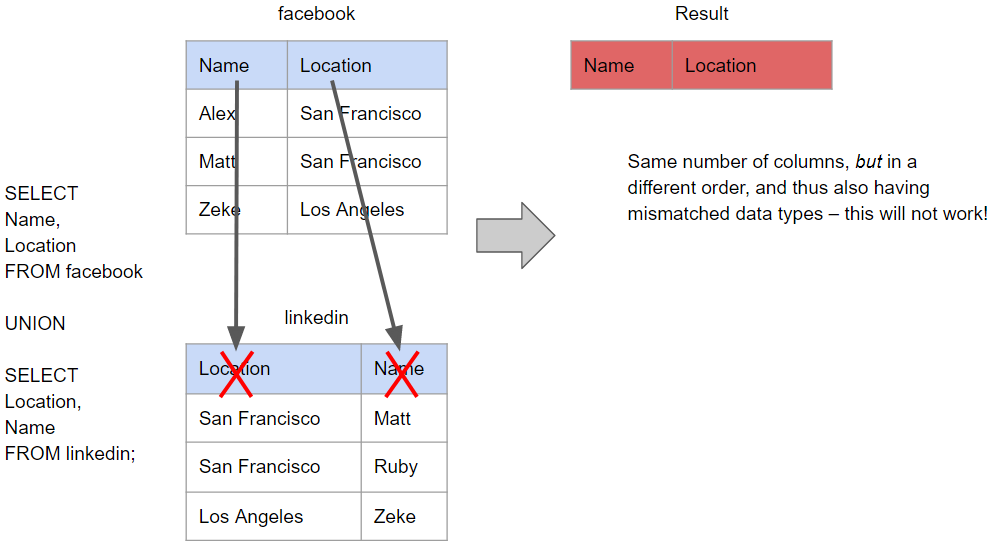
This final example would fail. While we have the correct number of columns, they are now queried in the wrong order in the second SELECT statement and thus the data types also do not match up. This will result in an error being returned.
За рамками Agile
We have seen that UNION and UNION ALL are useful to concatenate data sets and to manage whether or not we retain duplicates. UNION performs a deduplication step before returning the final results, UNION ALL retains all duplicates and returns the full, concatenated results. To allow success the number of columns, data types, and data order in each SELECT must be a match.
Written by: Josiah Faas
Reviewed by: Matt David