Atlassian Cloud
Arquitetura e práticas operacionais do Atlassian Cloud
Saiba mais sobre a arquitetura do Atlassian Cloud e as práticas operacionais que a gente segue
Introdução
Atlassian cloud apps and data are hosted on industry-leading cloud provider Amazon Web Services (AWS). Our products run on a platform as a service (PaaS) environment that is split into two main sets of infrastructure that we refer to as Micros and non-Micros. Jira, Confluence, Jira Product Discovery, Statuspage, Guard, and Bitbucket run on the Micros platform, while Opsgenie and Trello run on the non-Micros platform.
Arquitetura de serviços distribuídos
With this AWS architecture, we host a number of platform and product services that are used across our solutions. This includes platform capabilities that are shared and consumed across multiple Atlassian products, such as Media, Identity, and Commerce, experiences such as our Editor, and product-specific capabilities, like Jira Work Item service and Confluence Analytics.
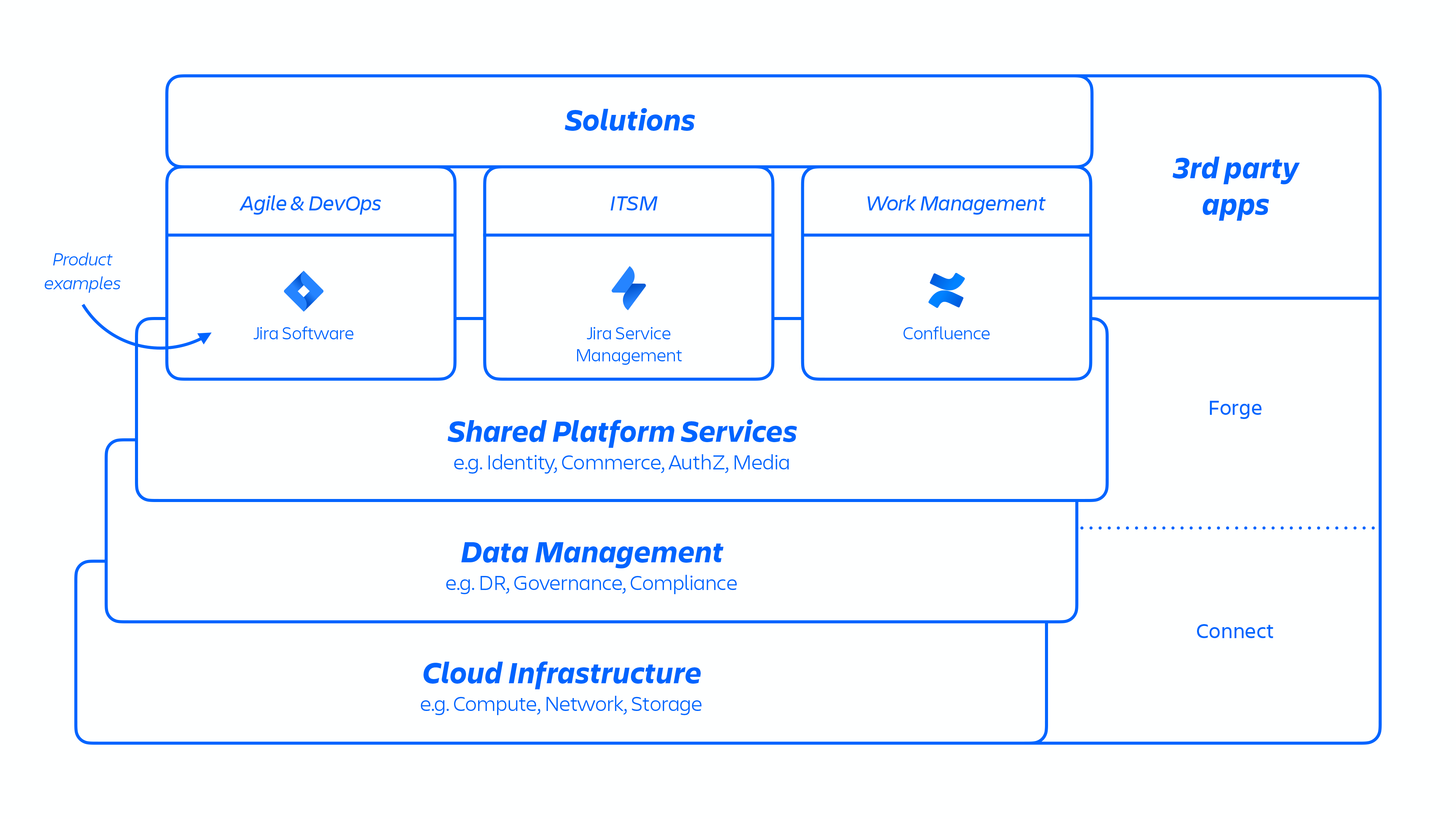
Figura 1
Os desenvolvedores da Atlassian fornecem esses serviços por meio do Kubernetes ou de uma plataforma como serviço (PaaS) desenvolvida a nível interno chamada Micros. Ambos fazem a orquestração automática da implantação de serviços compartilhados, infraestrutura, repositórios de dados e recursos de gerenciamento, incluindo requisitos de controle de conformidade e segurança (consulte a figura 1 acima). Em geral, um produto da Atlassian consiste em vários serviços “conteinerizados”, que são implantados na AWS usando o Micros ou Kubernetes. Os produtos da Atlassian usam os principais recursos da plataforma (veja a figura 2 abaixo), que variam do roteamento de solicitações a repositórios de objetos binários, autenticação/autorização, conteúdo transacional gerado pelo usuário (UGC) e armazenamento de relações de entidades, data lakes, registro comum, rastreamento de solicitações, observabilidade e serviços de análise. Esses microsserviços são criados usando pilhas técnicas aprovadas e padronizadas no nível da plataforma:
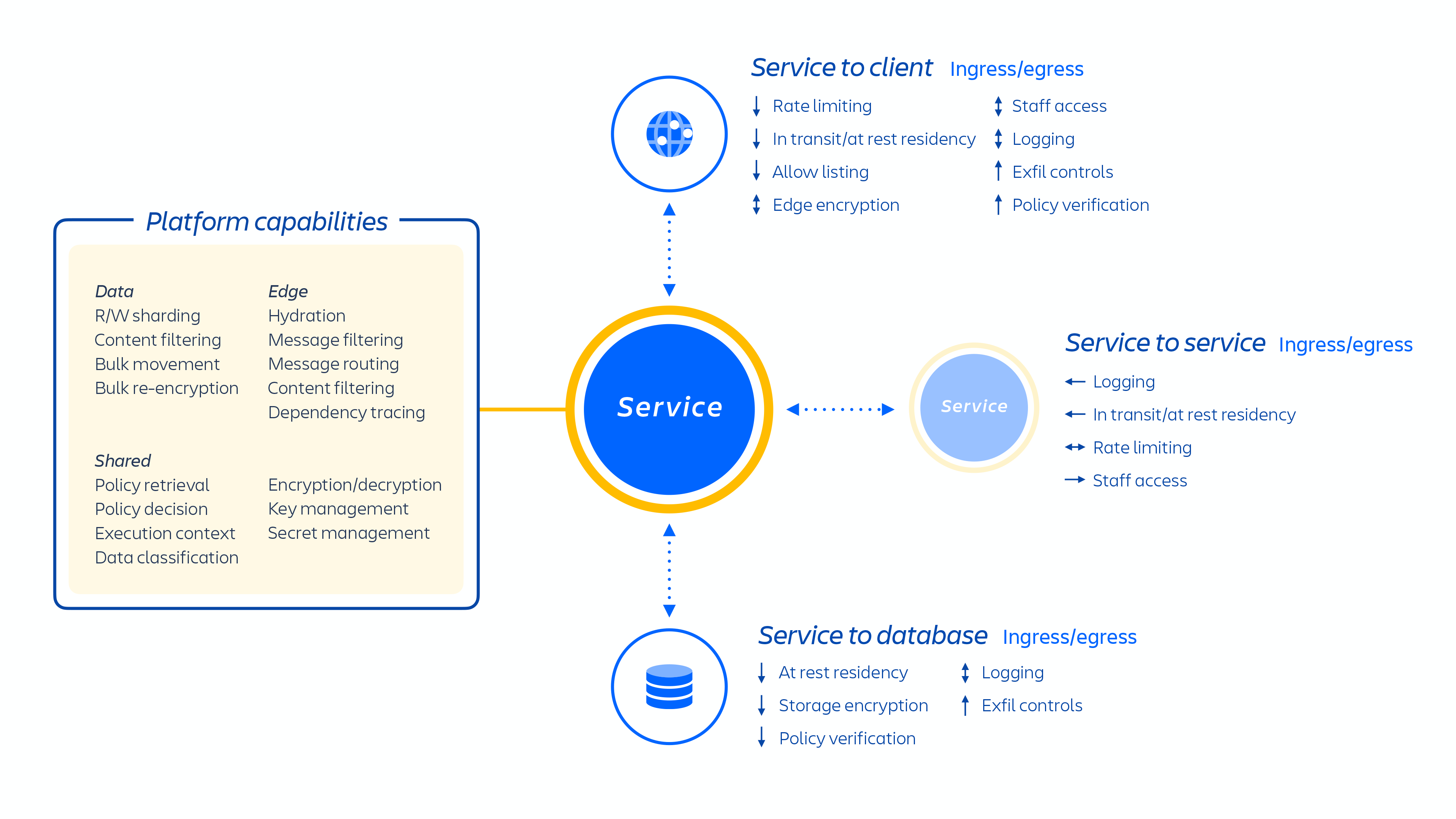
Figura 2
Arquitetura de vários locatários
On top of our cloud infrastructure, we built and operate a multi-tenant micro-service architecture along with a shared platform that supports our products. In a multi-tenant architecture, a single service serves multiple customers, including databases and compute instances required to run our cloud apps. Each shard (essentially a container – see figure 3 below) contains the data for multiple tenants, but each tenant's data is isolated and inaccessible to other tenants. It is important to note that we do not offer a single tenant architecture.
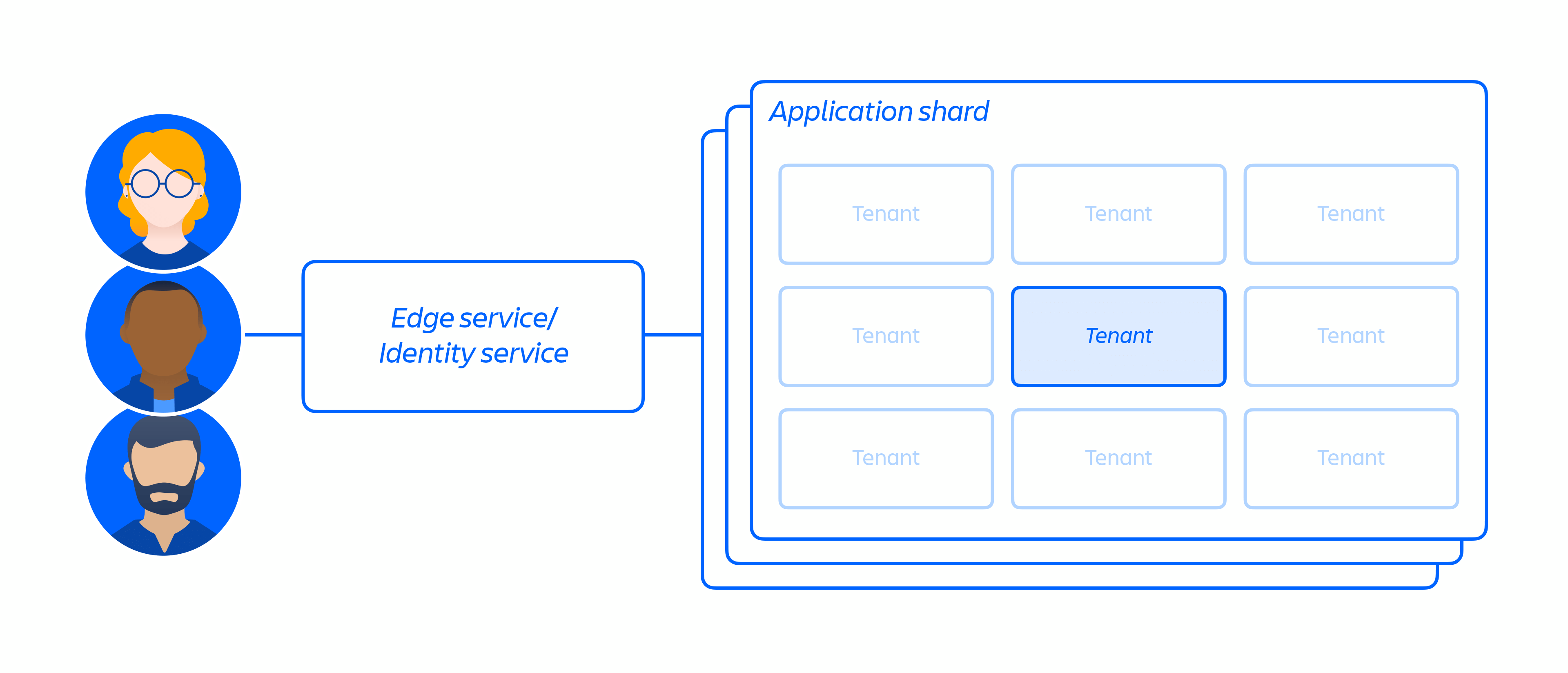
Figura 3
Os microsserviços da Atlassian implementam o mínimo de privilégio possível e são projetados para reduzir o escopo de qualquer exploração de dia zero e minimizar a probabilidade de movimento lateral no ambiente de nuvem que a gente oferece. Cada microsserviço tem o próprio armazenamento de dados que pode ser acessado apenas com o protocolo de autenticação para esse serviço específico, ou seja, nenhum outro serviço tem acesso de leitura ou de gravação a essa API.
A gente se concentrou no isolamento dos microsserviços e dos dados, em vez de oferecer uma infraestrutura dedicada por locatário, pois esse isolamento restringe o acesso ao âmbito limitado dos dados de um único sistema. A dissociação da lógica e a autenticação e autorização de dados ocorrem na camada do aplicativo, de modo a atuar como verificação de segurança adicional conforme as solicitações são enviadas para esses serviços. Assim, apenas o acesso aos dados exigidos por algum serviço específico var ficar limitado, caso algum microsserviço seja comprometido.
Provisionamento de locatário e ciclo de vida
Quando um novo cliente é provisionado, uma série de eventos aciona a orquestração de serviços distribuídos e o provisionamento de armazenamentos de dados. Esses eventos em geral podem ser mapeados para uma das sete etapas do ciclo de vida:
1. Os sistemas de comércio são atualizados de imediato com as informações de controle de acesso e os metadados mais recentes desse cliente; depois, o sistema de orquestração de provisionamento alinha o “estado dos recursos provisionados” com o estado da licença por meio da série de eventos de locatário e produto.
Eventos de locatário
Esses eventos afetam o locatário como um todo e podem ser:
- Criação: um locatário é criado e usado para novos sites
- Destruição: o locatário inteiro é excluído
Eventos de produtos
- Ativação: após a ativação de produtos licenciados ou aplicativos de terceiros
- Desativação: após a desativação de determinados produtos ou aplicativos
- Suspensão: após a suspensão de determinado produto existente, desativando assim o acesso a um determinado site próprio
- Cancelamento da suspensão: após o cancelamento da suspensão de determinado produto existente, permitindo assim o acesso ao site próprio
- Atualização de licença: contém informações sobre o número de licenças para determinado produto, bem como o status (ativo/inativo)
2. Criação do site do cliente e ativação do conjunto correto de produtos para o cliente. O conceito do site é o contêiner de vários produtos licenciados para determinado cliente. (por exemplo: Confluence e Jira Software para < nome do site >.atlassian.net).
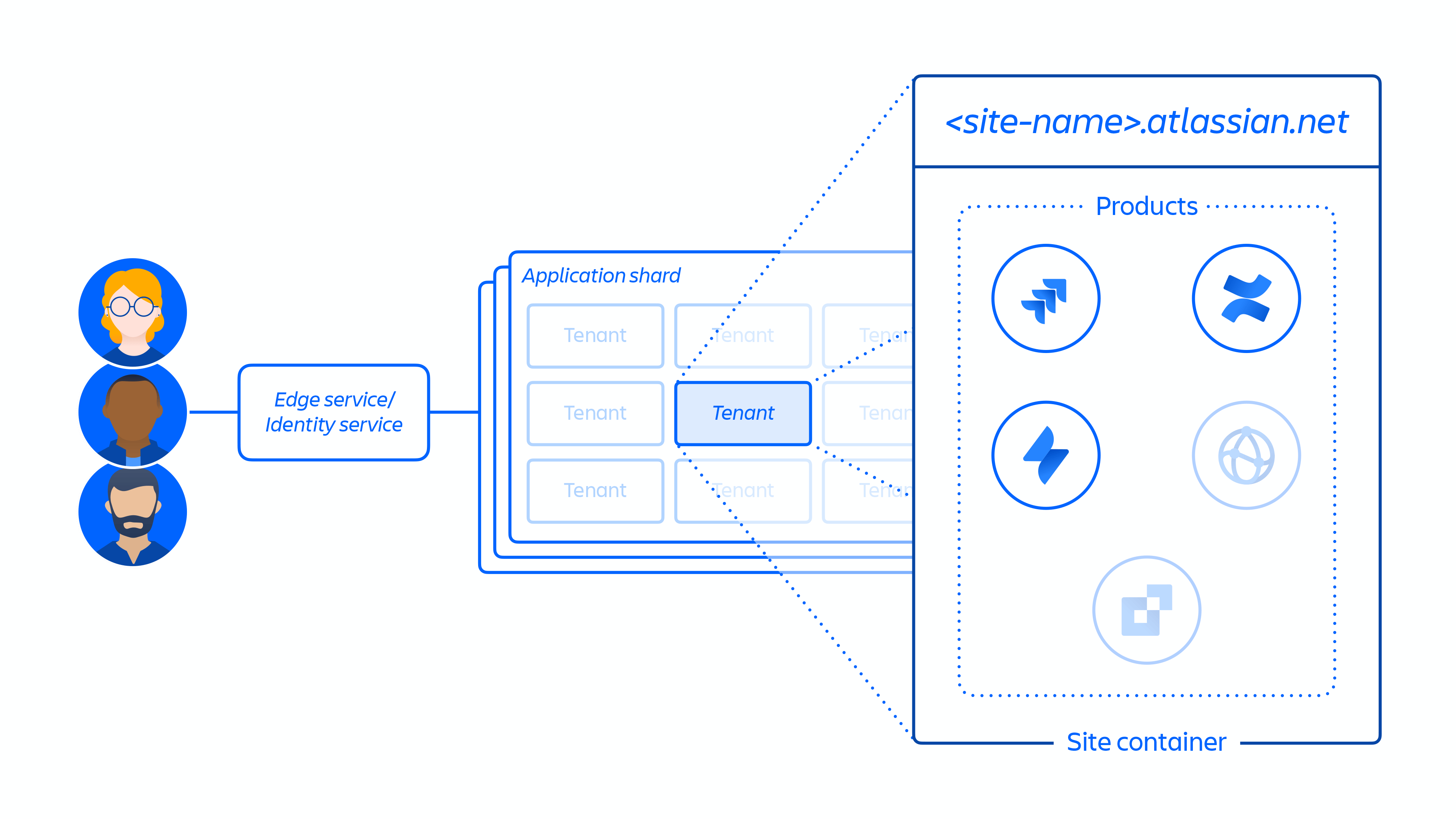
Figura 4
3. Provisionamento de produtos no site do cliente na região designada.
Quando o produto é provisionado, ele vai ter a maior parte do conteúdo hospedado perto de onde os usuários o acessam. Para otimizar o desempenho do produto, a gente não limita a movimentação de dados quando eles são hospedados em todo o mundo e podem mover dados entre regiões conforme necessário.
Para alguns produtos da Atlassian, a gente também oferece residência de dados. A residência de dados permite que os clientes escolham se os dados do produto são distribuídos em todo o mundo ou mantidos no local em uma das localizações geográficas definidas que a gente oferece.
4. Criação e armazenamento dos principais metadados e configurações do(s) produto(s) e do site do cliente.
5. Criação e armazenamento dos dados de identidade do site e do(s) produto(s), como usuários, grupos, permissões etc.
6. Provisionamento de bancos de dados de produtos no site, por exemplo: família de produtos Jira, Confluence, Compass, Atlas.
7. Provisionamento dos aplicativos licenciados do(s) produto(s).
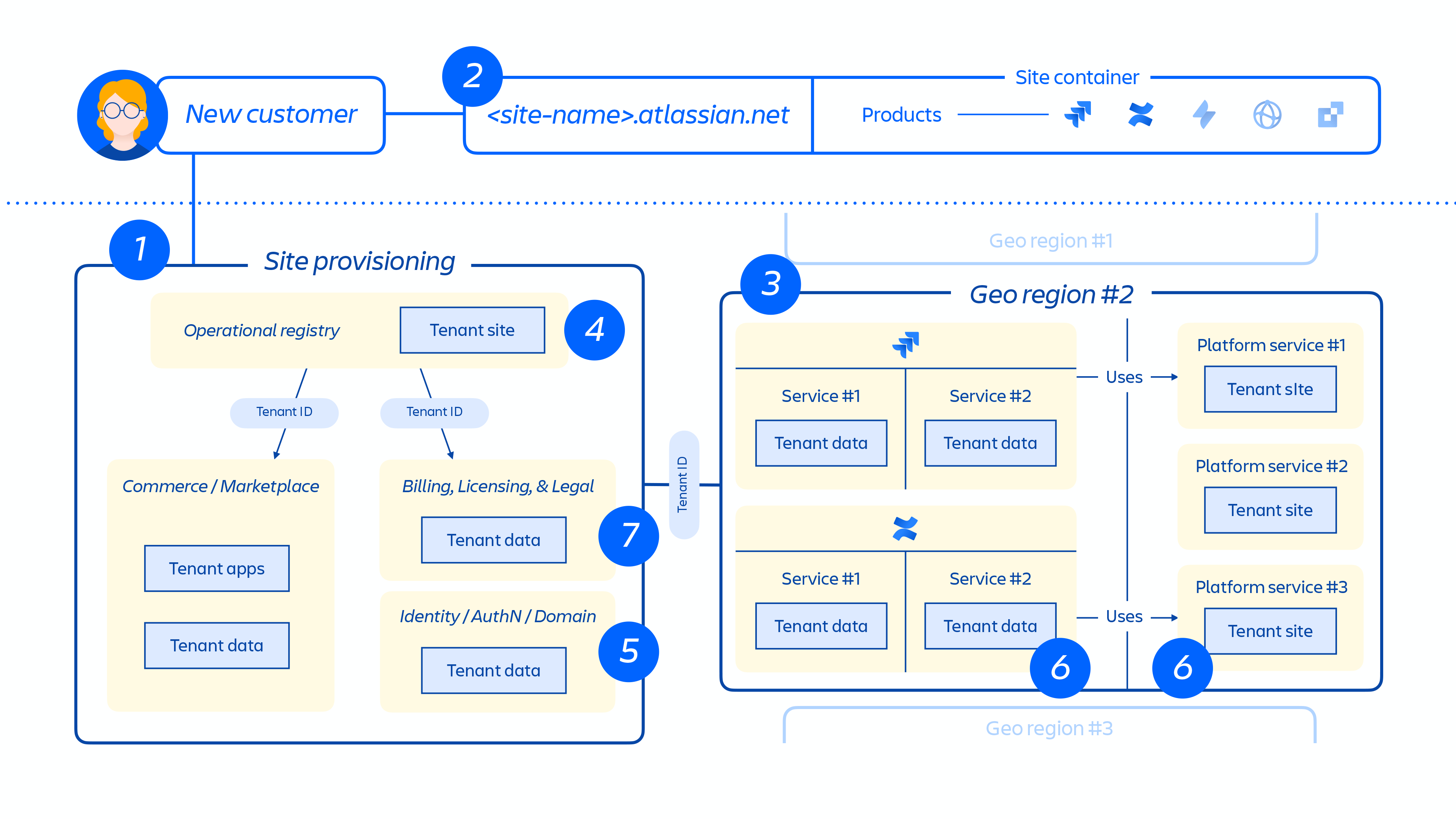
Figura 5
A Figura 5 acima demonstra como o site do cliente é implantado na arquitetura distribuída, não apenas em um único banco de dados ou loja. Essa ação inclui vários locais físicos e lógicos que armazenam metadados, dados de configuração, dados do produto, dados da plataforma e outras informações relacionadas ao site.