Wie erstellt man Microservices?
Best Practices für den Übergang zu einer Microservices-Architektur

Sten Pittet
Senior Product Manager
Nehmen wir an, deine Anwendung basiert auf einem Code und ist relativ groß und monolithisch. Bislang hat sie immer gut funktioniert, aber dann fingen die Probleme an. Du würdest sie gerne weiterentwickeln, damit sie widerstandsfähiger, skalierbarer und unabhängig einsetzbar wird. Dafür musst du die Struktur der Anwendung auf einer detaillierten Microservices-Ebene neu überdenken.
Microservices gewinnen an Beliebtheit, seit Anwendungen zunehmend verteilter und komplexer werden. Das Grundprinzip von Mikroservices besteht in der Entwicklung von Anwendungen durch das Aufteilen von Geschäftskomponenten in kleinere Services. Diese lassen sich unabhängig voneinander bereitstellen und betreiben. Die Trennung von Zuständigkeiten zwischen Services wird als "Servicegrenzen" definiert.
Servicegrenzen sind eng mit den Geschäftsanforderungen und den Grenzen der Organisationsstrukturen verbunden. Einzelne Services können an separate Teams, Budgets und Roadmaps gebunden sein. Beispiele für Servicegrenzen sind Services für die Zahlungsabwicklung und die Benutzerauthentifizierung. Microservices unterscheiden sich von älteren Softwareentwicklungspraktiken, bei denen alle Komponenten gebündelt wurden.
In diesem Dokument beziehen wir uns auf ein imaginäres Start-up namens "Pizzup", um die Anwendung von Microservices in einem modernen Softwareunternehmen zu veranschaulichen.

Teste Compass kostenlos
Als Unterstützung beim Entwickeln, zum Katalogisieren von Diensten und zum Optimieren des Softwarezustands.
Wie erstellt man Microservices?
Schritt 1: Beginne mit einem Monolith
Die erste Best Practice für Microservices ist, dass du sie wahrscheinlich gar nicht benötigst. Wenn du keine Benutzer für deine Anwendung hast, besteht die Möglichkeit, dass sich die Geschäftsanforderungen während der Erstellung deines MVP (Minimum Viable Product) schnell ändern. Dies liegt einfach an der Art der Softwareentwicklung und dem Feedbackzyklus, der stattfinden muss, während du die wichtigsten Geschäftsfunktionen identifizierst, die dein System bereitstellen muss. Microservices erhöhen den Aufwand und die Komplexität der Verwaltung exponentiell. Aus diesem Grund ist es für neue Projekte viel weniger Aufwand, den gesamten Code und die Logik in einer einzigen Codebasis zu speichern, da dies das Verschieben der Grenzen der einzelnen Module deiner Anwendung erleichtert.
Beginnen wir am Beispiel von Pizzup mit einem einfachen Problem, für das wir eine Lösung suchen: Wir wollen, dass die Kunden ihre Pizza online bestellen können.

Zugehöriges Material
Microservices und monolithische Architektur im Vergleich
Lösung anzeigen
Verbesserte Entwicklung mit Compass
Wenn wir über den Vorgang der Pizzabestellung nachdenken, identifizieren wir zuerst die verschiedenen Grundfunktionen, die unsere Anwendung braucht, um diesen Bedarf zu decken. Wir müssen in der Lage sein, eine Liste der verschiedenen Pizzen zu verwalten, die wir zubereiten können. Die Kunden müssen die Möglichkeit haben, eine oder mehrere Pizzen auszuwählen, die Zahlung abzuwickeln, die Lieferung zu planen und so weiter. Wir können unseren Kunden auch die Möglichkeit zur Erstellung eines Kontos bieten, um die nächste Bestellung bei Pizzup zu erleichtern. Nachdem wir mit unseren ersten Benutzern gesprochen haben, erfahren wir möglicherweise, dass uns eine Live-Verfolgung der Lieferung und die Unterstützung von Mobilgeräten einen Vorteil gegenüber der Konkurrenz verschaffen würden.
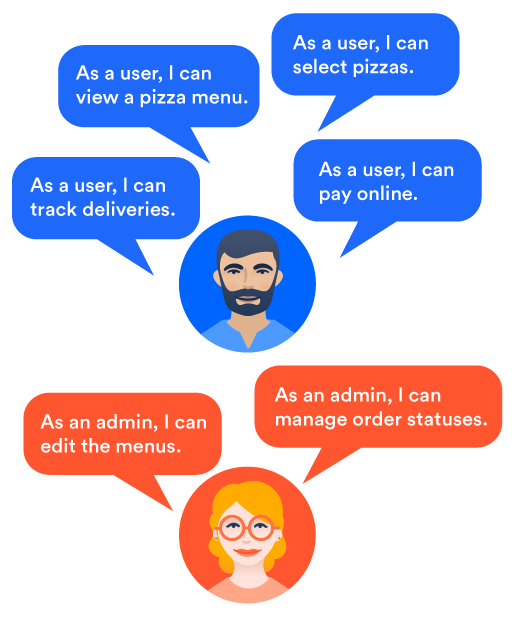
Was zu Beginn eine einfache Anforderung war, wird schnell zu einer Liste neuer Funktionen.
Microservices funktionieren gut, wenn du die verschiedenen Services, die von deinem System benötigt werden, gut verstanden hast. Sie sind jedoch viel schwieriger zu handhaben, wenn die Kernanforderungen einer Anwendung nicht genau bestimmt wurden. Es ist ziemlich kostspielig, Service-Interaktionen, APIs und Datenstrukturen in Microservices neu zu definieren, da möglicherweise wesentlich mehr dynamische Elemente koordiniert werden müssen. Aus diesem Grund empfehlen wir, die Anwendung einfach zu halten, bis du genügend Benutzerfeedback gesammelt hast, um sicher zu sein, dass du die Grundbedürfnisse deiner Kunden kennst und entsprechend planen kannst.
Aber Vorsicht: Der Aufbau eines Monoliths kann schnell zu kompliziertem Code führen, der sich schwer in kleinere Teile zerlegen lässt. Daher empfiehlt es sich, eindeutige Module zu identifizieren, damit du sie später aus dem Monolith extrahieren kannst. Du kannst auch damit beginnen, die Logik von deiner Web-Benutzeroberfläche zu trennen und die Interaktion über eine REST-API über HTTP mit deinem Backend sicherzustellen. Dies erleichtert den Übergang zu Microservices, wenn du beginnst, einige der API-Ressourcen zu verschiedenen Services zu verschieben.
Schritt 2: Organisiere deine Teams auf die richtige Weise
Bisher schien der Aufbau von Microservices im Wesentlichen eine technische Angelegenheit zu sein. Man musste eine Codebasis in mehrere Services aufteilen, die richtigen Muster implementieren, um die Services bei Fehlern ordnungsgemäß zu beenden und nach Netzwerkproblemen wiederherzustellen, mit der Datenkonsistenz umzugehen, die Servicelast zu überwachen usw. Jetzt musst du dich mit einer Vielzahl neuer Konzepte vertraut machen. Was du jedoch unbedingt berücksichtigen musst, ist die Umstrukturierung der Organisation deiner Teams.
Das Gesetz von Conway ist keine Erfindung, sondern lässt sich in allen Arten von Teams beobachten. Ein Softwareteam, das sich aus drei unabhängig voneinander arbeitenden Teams im Backend, im Frontend und im Betrieb zusammensetzt, entwickelt separate Frontend- und Backend-Monolithen, die das Betriebsteam ohne jegliche Möglichkeit der Einflussnahme in die Produktion übernehmen muss. Diese Art von Struktur ist für Microservices nicht geeignet, da jeder Service als ein eigenes Produkt gelten sollte, das unabhängig von den anderen ausgeliefert werden muss.
Stattdessen solltest du kleinere DevOps-Teams bilden, die über alle Kompetenzen verfügen, die sowohl für die Entwicklung als auch die Wartung ihrer jeweiligen Services erforderlich sind. Es hat große Vorteile, deine Teams auf diese Weise zu organisieren. Zunächst einmal bekommen deine Entwickler eine bessere Vorstellung von den Auswirkungen ihres Codes in der Produktion. Das hilft ihnen dabei, bessere Releases zu erstellen und verringert das Risiko von Problemen für die Kunden. Zweitens werden Deployments für jedes Team zu einer Selbstverständlichkeit, da sie an Verbesserungen des Codes und an der Automatisierung der Deployment-Pipeline gemeinsam arbeiten.
Schritt 3: Teile den Monolith auf, um eine Microservices-Architektur zu erstellen
Sobald du die Grenzen deiner Services ermittelt hast und weißt, wie du deine Teams umstrukturieren willst, kannst du deinen Monolithen aufteilen und mit der Erstellung der Microservices beginnen. Im Folgenden findest du die wichtigsten Punkte, über die du zu diesem Zeitpunkt nachdenken solltest.
Eine RESTful API sorgt für einfache Kommunikation zwischen Services
Wenn du noch keine REST-API verwendest, ist dies jetzt ein guter Zeitpunkt, sie in deinem System einzuführen. Wie Martin Fowler erklärt, brauchst du "intelligente Endpunkte und dumme Pipes". Das Kommunikationsprotokoll zwischen deinen Services sollte so einfach wie möglich und nur für die Übertragung von Daten verantwortlich sein, ohne sie zu transformieren. Das eigentliche Wunder findet an den Endpunkten statt: Sie erhalten eine Anfrage, verarbeiten sie und geben im Gegenzug eine Antwort aus.
Microservices-Architekturen streben danach, die Dinge so einfach wie möglich zu halten, um eine enge Kopplung der Komponenten zu vermeiden. In einigen Fällen kannst du eine ereignisgesteuerte Architektur mit asynchroner nachrichtenbasierter Kommunikation verwenden. Aber du solltest dir auf jeden Fall grundlegende Warteschlangenservices für Nachrichten wie RabbitMQ ansehen und vermeiden, die über das Netzwerk übertragenen Nachrichten komplexer zu machen.
Teile Daten in Kontextgrenzen oder Datendomänen auf
Monolith-Anwendungen verwenden eine einzelne Datenbank für alle Geschäftsfunktionen der Anwendung. Wenn ein Monolith in Microservices aufgebrochen wird, ergibt diese einzelne Datenbank keinen Sinn mehr. Eine zentrale Datenbank kann bei der Skalierung des Datenverkehrs sogar zum Engpass werden. Wenn ein bestimmter Service mit hoher Last auf die Datenbank zugreift, wird unter Umständen der Datenbankzugriff eines anderen Services unterbrochen. Darüber hinaus kann eine einzelne Datenbank die Zusammenarbeit mehrerer Teams beeinträchtigen, die versuchen, das Schema gleichzeitig zu verändern. Dann wird möglicherweise eine Aufteilung der Datenbank notwendig oder es müssen zusätzliche Datenspeichertools hinzugefügt werden, um die Datenanforderungen der Microservices zu erfüllen.
Das Refactoring eines monolithischen Datenbankschemas kann eine heikle Angelegenheit sein. Es muss eindeutig definiert werden, welche Datensätze jeder Service benötigt und wo es zu Überscheidungen kommt. Eine solche Schemaplanung kann mit Hilfe von Kontextgrenzen erfolgen, einem Muster aus dem Domain Driven Design. Eine Kontextgrenze wird als eigenständiges System definiert, einschließlich der Ein- und Ausgänge in bzw. aus dem System.
Wenn ein Benutzer in diesem System auf eine Bestellung zugreift, kannst du seine Kundeninformationen in einer Tabelle anzeigen. Diese Tabelle kann zudem genutzt werden, um die vom Abrechnungssystem verwaltete Rechnung zu befüllen. All das scheint logisch und einfach zu sein, aber mit Microservices sollten diese Services entkoppelt werden, damit auf Rechnungen auch dann zugegriffen werden kann, wenn das Bestellsystem nicht verfügbar ist. Außerdem kannst du die Rechnungstabelle unabhängig von anderen Services optimieren oder weiterentwickeln. Jeder Service verfügt somit möglicherweise über einen eigenen Datenspeicher, um auf die benötigten Daten zuzugreifen.
Aber es entstehen dadurch auch neue Probleme, da einige Daten in verschiedenen Datenbanken dupliziert werden. Kontextgrenzen können den besten Ansatz für den Umgang mit gemeinsam genutzten oder duplizierten Daten aufzeigen. Du solltest eine ereignisgesteuerte Architektur einführen, um die serviceübergreifende Synchronisierung von Daten zu unterstützen. Zum Beispiel können deine Abrechnungs- und Lieferverfolgungsservices auf Ereignisse des Kontoservices reagieren, wenn Kunden ihre persönlichen Daten aktualisieren. Nachdem die Services dieses Ereignis empfangen haben, aktualisieren sie ihren Datenspeicher entsprechend. Diese ereignisgesteuerte Architektur ermöglicht es, die Kontoservicelogik einfach zu halten, da sie nicht alle anderen abhängigen Services kennen muss. Sie teilt dem System einfach mit, was geschehen ist, und die anderen Services reagieren entsprechend darauf.
Du kannst auch alle Kundeninformationen im Kontoservice und nur eine Fremdschlüsselreferenz in deinem Abrechnungs- und Lieferservice aufbewahren. Du interagierst dann mit dem Kontodienst, um bei Bedarf die relevanten Kundendaten zu erhalten, anstatt vorhandene Datensätze zu duplizieren. Es gibt keine universelle Lösung für diese Probleme und du musst dich mit jedem Einzelfall befassen, um festzustellen, welcher Ansatz jeweils der beste ist.
Plane beim Aufbau deiner Microservices-Architektur das Auftreten von Fehlern ein
Wir haben gesehen, wie Microservices gegenüber einer monolithischen Architektur große Vorteile bieten können. Sie sind kleiner und spezialisiert, was sie leicht verständlich macht. Sie sind entkoppelt, was bedeutet, dass du einen Service refaktorieren kannst, ohne befürchten zu müssen, die anderen Komponenten des Systems zu beschädigen oder die Entwicklung der anderen Teams zu verlangsamen. Sie bieten deinen Entwicklern auch mehr Flexibilität, da sie bei Bedarf verschiedene Technologien auswählen können, ohne durch die Anforderungen anderer Services eingeschränkt zu werden.
Kurz gesagt, eine Microservices-Architektur erleichtert die Entwicklung und Aufrechterhaltung jeder Geschäftsfunktion. Wie alle Services in ihrer Gesamtheit miteinander interagieren, um Aktionen durchzuführen, ist jedoch etwas komplizierter. Dein System ist jetzt verteilt und verfügt über mehrere mögliche Schwachstellen, die du berücksichtigen musst. Dabei geht es nicht nur um fehlende Reaktionen eines Services, sondern auch um den Umgang mit langsameren Reaktionen im Netzwerk. Die Wiederherstellung nach einem Fehler kann ebenfalls manchmal schwierig sein, da du sicherstellen musst, dass Services, die wieder in Betrieb gehen und ausgeführt werden, nicht durch ausstehende Nachrichten überflutet werden.
Wenn du damit beginnst, Funktionen aus deinen monolithischen Systemen zu extrahieren, darfst du auf keinen Fall vergessen, von Anfang an den Umgang mit Fehlern einzuplanen.
Lege Wert auf Überwachung, um das Testen von Microservices zu erleichtern
Tests sind ein weiterer Nachteil von Microservices im Vergleich zu einem monolithischen System. Eine Anwendung, die als eine einzige Codebasis erstellt wird, benötigt nicht viel, um eine Testumgebung in Betrieb zu nehmen. In den meisten Fällen musst du einen Backend-Server in Verbindung mit einer Datenbank starten, um deine Testsuite ausführen zu können.
In der Welt der Microservices ist dies nicht so einfach. Komponententests dürften sich nicht allzu sehr von denen des Monoliths unterscheiden und sollten dir keine Probleme bereiten. Integrations- und Systemtests gestalten sich hingegen schwieriger. Unter Umständen musst du mehrere Services zusammen starten, verschiedene Datenspeicher in Betrieb nehmen und deine Konfiguration muss möglicherweise Nachrichtenwarteschlangen enthalten, die bei deinem Monolith nicht erforderlich waren. In dieser Situation wird die Durchführung von Funktionstests wesentlich kostspieliger und die zunehmende Anzahl von dynamischen Elementen macht es sehr schwierig, die verschiedenen Arten von Fehlern vorherzusagen, die auftreten können.
Mithilfe der Überwachung kannst du Probleme frühzeitig erkennen und entsprechend reagieren. Du musst die Grundlagen deiner verschiedenen Services verstehen und nicht nur reagieren können, wenn sie ausfallen, sondern auch, wenn sie sich unerwartet verhalten. Ein Vorteil der Einführung einer Microservices-Architektur besteht darin, dass dein System gegen teilweisen Ausfall widerstandsfähig sein sollte. Wenn du also Anomalien im Lieferverfolgungsservice unserer Pizzup-Anwendung feststellst, ist dies weniger schlimm als in einem monolithischen System. Unsere Anwendung sollte so gestaltet sein, dass alle anderen Services ordnungsgemäß reagieren und unsere Kunden Pizzen bestellen können, während wir die Live-Lieferverfolgung wiederherstellen.
Nutze Continuous Delivery für reibungslosere Deployments
Die manuelle Freigabe eines monolithischen Systems in die Produktion ist mühsam und riskant, aber nicht unmöglich. Natürlich empfehlen wir diesen Ansatz nicht und ermutigen jedes Softwareteam, Continuous Delivery für alle Entwicklungsarbeiten zu nutzen. Zu Beginn eines Projekts kannst du jedoch deine ersten Deployments selbst über die Befehlszeile durchführen.
Dieser Ansatz ist nicht nachhaltig, wenn du eine zunehmende Anzahl von Services hast, die mehrmals täglich bereitgestellt werden müssen. Daher ist es im Rahmen deiner Umstellung auf Microservices von entscheidender Bedeutung, dass du Continuous Delivery einführst, um das Risiko eines Releasefehlers zu reduzieren und sicherzustellen, dass sich dein Team auf die Entwicklung und den Betrieb der Anwendung konzentriert, anstatt sich mit dem Deployment aufzuhalten. Continuous Delivery bedeutet auch, dass dein Service Akzeptanztests bestanden hat, bevor er in die Produktion geht. Natürlich werden Fehler auftreten, aber im Laufe der Zeit entsteht eine robuste Testsuite, sodass sich dein Team zunehmend auf die Qualität der Releases verlassen kann.
Das Ausführen von Microservices ist kein Sprint
Microservices sind eine beliebte und weit verbreitete Best Practice der Branche. Für komplexe Projekte bieten sie eine größere Flexibilität bei der Entwicklung und der Bereitstellung von Software. Sie helfen zudem bei der Identifizierung und Formalisierung der Geschäftskomponenten deines Systems, was nützlich ist, wenn mehrere Teams an derselben Anwendung arbeiten. Es gibt jedoch auch einige eindeutige Nachteile bei der Verwaltung verteilter Systeme und die Aufteilung einer monolithischen Architektur sollte nur erfolgen, wenn ein klares Verständnis der Servicegrenzen besteht.
Der Aufbau von Microservices sollte als Weg und nicht als unmittelbares Ziel für ein Team angesehen werden. Fange klein an, um die technischen Anforderungen eines verteilten Systems kennenzulernen und zu verstehen, wie Services beim Auftreten von Fehlern ordnungsgemäß beendet und einzelne Komponenten skaliert werden können. Mit zunehmender Erfahrung und Kenntnis kannst du nach und nach mehr Services extrahieren.
Die Migration in eine Microservices-Architektur muss nicht auf einen Schlag durchgeführt werden. Eine iterative Strategie zur sequenziellen Migration kleinerer Komponenten zu Microservices ist sicherer. Identifiziere die am besten definierten Servicegrenzen innerhalb einer etablierten Monolith-Anwendung und arbeite iterativ daran, sie in ihren eigenen Microservice zu entkoppeln.
Fazit
Zusammenfassend lässt sich sagen, dass Microservices eine Strategie sind, die sowohl für den Entwicklungsprozess des technischen Codes als auch für die allgemeine Strategie der Unternehmensorganisation von Vorteil ist. Mit Microservices lassen sich Teams in Einheiten organisieren, die sich auf die Entwicklung und den Besitz bestimmter Geschäftsfunktionen konzentrieren. Dieser granulare Fokus verbessert die allgemeine Geschäftskommunikation und -effizienz. Die Vorteile von Microservices bringen aber auch einige Nachteile mit sich. Es ist wichtig, dass Servicegrenzen vor der Migration auf eine Microservices-Architektur klar definiert sind.
Obwohl eine Microservices-Architektur zahlreiche Vorteile bietet, erhöht sie auch die Komplexität. Atlassian hat Compass entwickelt, um Unternehmen bei der Handhabung komplexer verteilter Architekturen während der Skalierung zu unterstützen. Die Lösung ist eine erweiterbare Developer-Experience-Plattform, die unzusammenhängende Informationen über die gesamten Entwicklungsergebnisse und die Teamzusammenarbeit an einem zentralen, durchsuchbaren Ort zusammenführt.
Diesen Artikel teilen
Nächstes Thema
Lesenswert
Füge diese Ressourcen deinen Lesezeichen hinzu, um mehr über DevOps-Teams und fortlaufende Updates zu DevOps bei Atlassian zu erfahren.

Compass-Community

Tutorial: Erstellen einer Komponente