CI/CD con Git: 5 consejos para repositorios de Git compatibles con CI
El punto de partida para alcanzar el éxito es el repositorio.

Sarah Goff-Dupont
Redactora principal
Git y la entrega continua constituyen una de esas deliciosas combinaciones de "chocolate con fresas" que a veces encontramos en el mundo del software: dos grandes sabores que saben mejor cuando se mezclan. Así que quiero compartir algunos consejos para hacer que las compilaciones en Bamboo funcionen correctamente con los repositorios de Bitbucket. La mayor parte de la interacción ocurre en las fases de compilación y pruebas de la entrega continua, de modo que verás que hablo sobre todo de "CI", más que de "CD".
1: Almacena los archivos grandes fuera del repositorio
Una de las cosas que se suelen oír sobre Git es que se debe evitar colocar archivos grandes en el repositorio: binarios, archivos de medios, artefactos archivados, etc. Eso es porque, una vez que se añade un archivo, estará siempre ahí en el historial del repositorio, lo que significa que, cada vez que se clona el repositorio, ese archivo grande y pesado también se clonará.
Sacar un archivo del historial del repositorio no es tarea fácil. De hecho, es como hacerle una lobotomía al código base. Esta extracción quirúrgica de archivos altera todo el historial del repositorio, lo que impide tener una idea clara de los cambios que se han hecho y de cuándo se han hecho. Estas son buenas razones para evitar archivos grandes, pero es que además...
Mantener los archivos grandes fuera de tus repositorios de Git es especialmente importante para la CI
Cada vez que realices una compilación, tu servidor de integración continua debe clonar tu repositorio en el directorio de compilación de trabajo. Y, si el repositorio está repleto de artefactos enormes, se ralentiza ese proceso y se incrementa el tiempo que deben esperar los desarrolladores para obtener los resultados de la compilación.
Vale, de acuerdo. Pero ¿qué pasa si tu compilación depende de binarios de otros proyectos o artefactos grandes? Es una situación muy habitual, y probablemente siempre lo será. La pregunta es: ¿cómo podemos gestionarlo de forma efectiva?
Ver la solución
Desarrolla y pon en marcha software con Open DevOps
Material relacionado
Descubre qué es el desarrollo basado en troncos
Un sistema de almacenamiento externo como Artifactory (que tiene un complemento para Bamboo), Nexus o Archiva puede ser útil para los artefactos generados por tu equipo o por otros equipos. Los archivos necesarios pueden introducirse en el directorio de compilación al principio de la compilación, como pasa con las bibliotecas de terceros que introduces con Maven o Gradle.
Consejo de experto: Si los artefactos cambian con frecuencia, evita sincronizar los archivos grandes con el servidor de compilación cada noche; así, solo tendrás que transferirlos a través del disco en el momento de la compilación. Con las sincronizaciones nocturnas, terminarías teniendo versiones desfasadas de los artefactos. Además, los desarrolladores necesitan estos archivos para las compilaciones en sus equipos locales. Por eso, la mejor opción es integrar la descarga del artefacto en la compilación.
Si aún no dispones de un sistema de almacenamiento externo en tu red, te resultará más fácil aprovechar la compatibilidad con archivos grandes (LFS) de Git.
Git LSF es una extensión que almacena punteros en archivos grandes en tu repositorio, en lugar de almacenar los archivos en sí. Dichos archivos se almacenan en un servidor remoto. Como supondrás, esto reduce significativamente el tiempo de clonación.
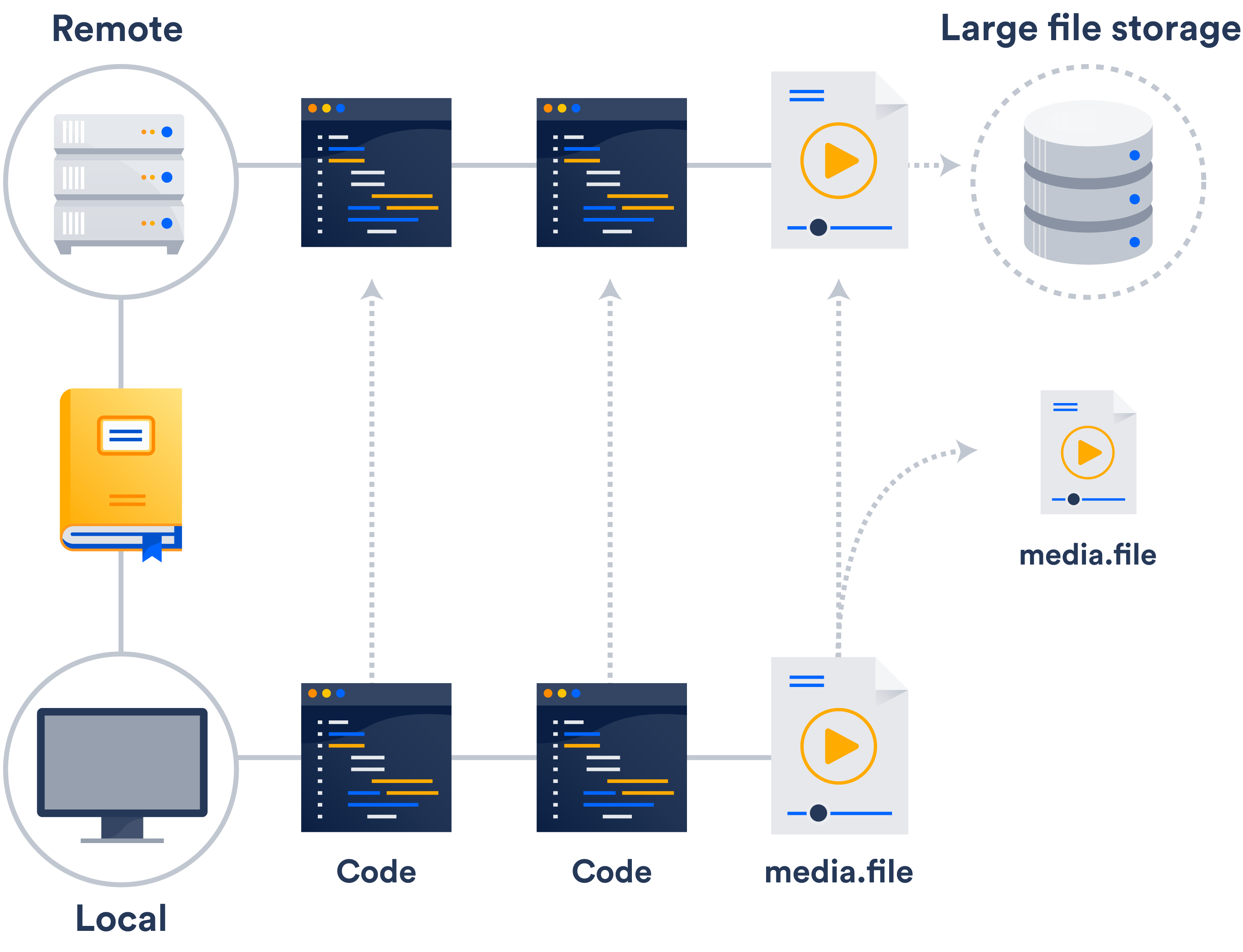
Es probable que ya tengas acceso a LFS de Git, ya que tanto Bitbucket como GitHub lo admiten.
2: Usar clones superficiales para la IC
Cada vez que se ejecuta una compilación, el servidor de compilación clona el repositorio en el directorio de trabajo actual. Como he mencionado antes, cuando Git clona un repositorio, clona todo el historial del repositorio de forma predeterminada. Por eso, con el tiempo, esta operación cada vez tardará más.
En el caso de clones superficiales, solo se extraerá la instantánea actual del repositorio. Esto puede ser bastante útil para acelerar las compilaciones, sobre todo cuando se trabaja con repositorios grandes o antiguos.
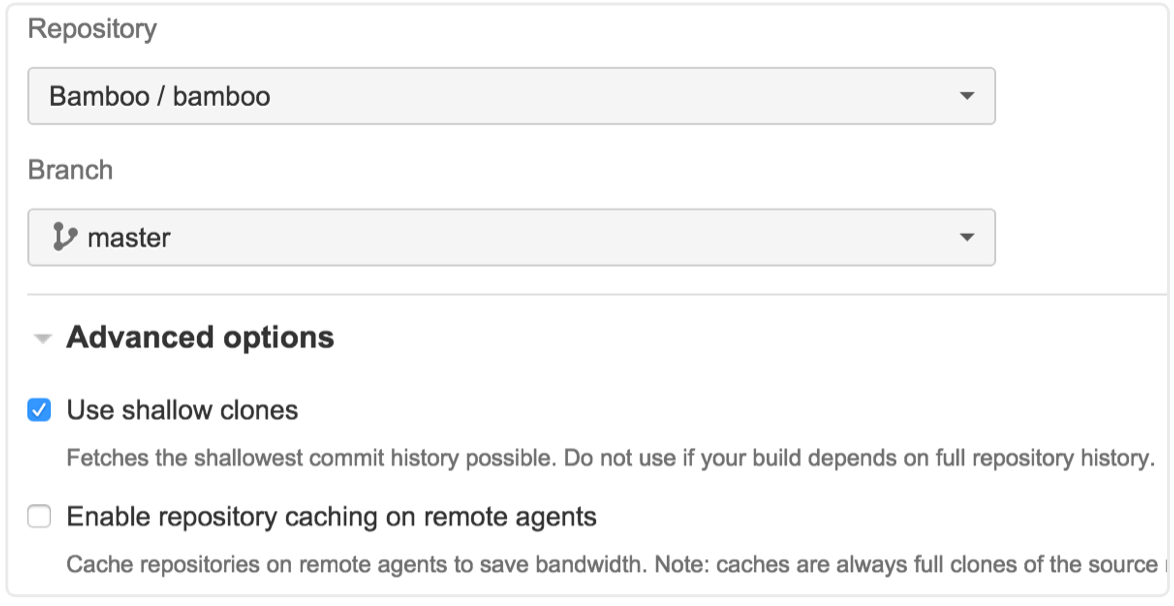
Pero digamos que tu compilación requiere el historial completo del repositorio; si, por ejemplo, uno de los pasos de tu compilación actualiza el número de versión en tu POM (o algo parecido), o si fusionas dos ramas con cada compilación. Para ambos casos, Bamboo debe volver a implementar cambios en tu repositorio.
Con Git, se pueden hacer cambios sencillos en los archivos (como actualizar un número de versión) sin necesidad de contar con el historial completo. Sin embargo, para la fusión sigue siendo necesario el historial del repositorio, ya que Git necesita retroceder y encontrar el antepasado común de las dos ramas, lo que supone un problema si la compilación usa la clonación superficial. Esto me lleva al tercer consejo.
3: Almacenar en el caché el repositorio en agentes de compilación
Esto también agiliza el proceso de clonado; de hecho, Bamboo lo hace de forma predeterminada.
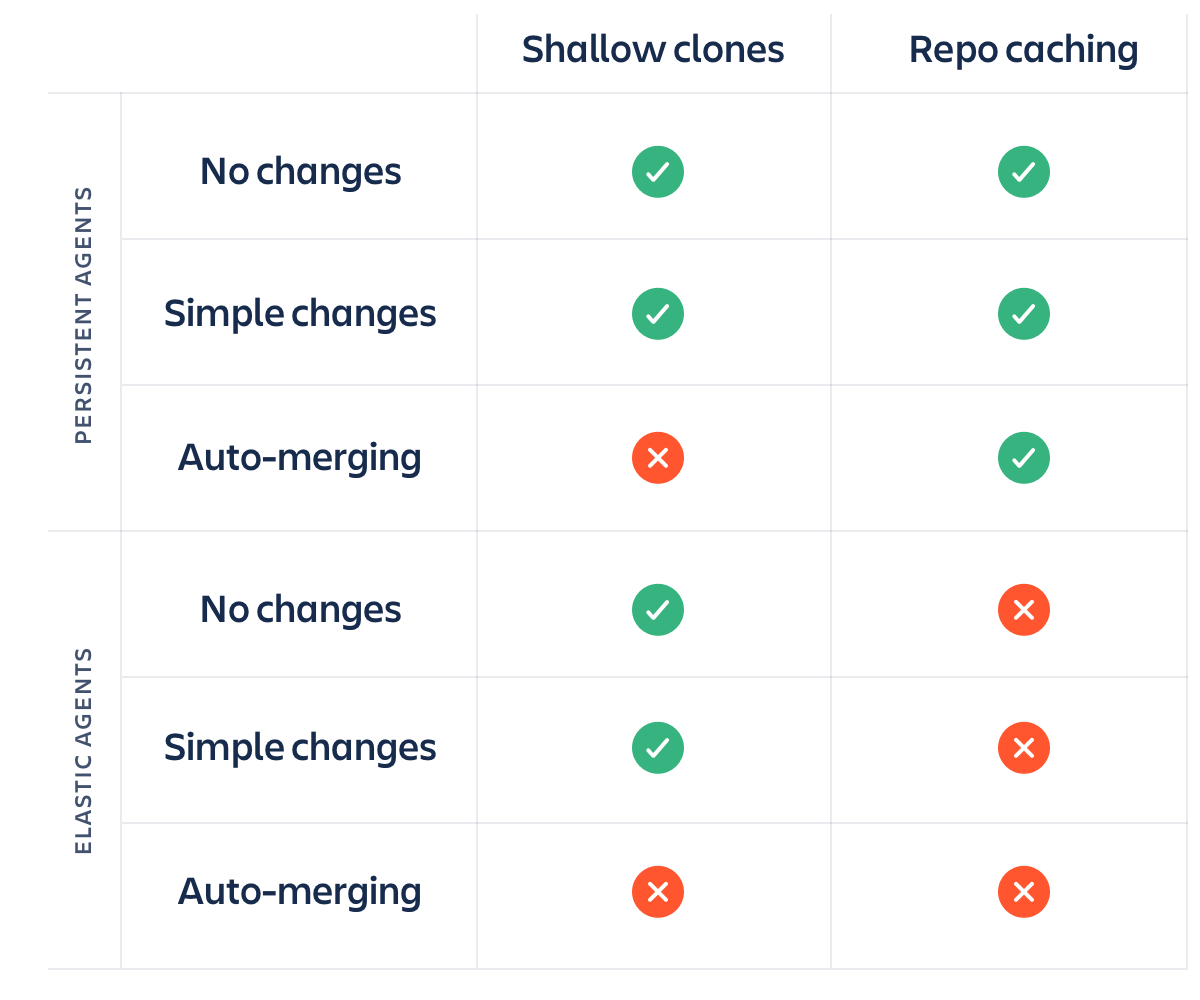
Ten en cuenta que el almacenamiento en caché del repositorio solo te beneficia a ti si usas agentes persistentes entre compilaciones. Si creas y destruyes agentes de compilación en EC2 u otro proveedor de servicios en la nube cada vez que se ejecuta una compilación, el almacenamiento en caché del repositorio dejará de tener sentido, ya que estarás trabajando con un directorio de compilaciones vacío y tendrás que incorporar una copia completa del repositorio cada vez.
Los clones superficiales más el almacenamiento en caché del repositorio, dividido entre agentes persistentes frente a agentes extensibles, da como resultado una interesante red de factores. Aquí tienes una pequeña base para ayudarte a elaborar tus estrategias.
4: Elegir los activadores con sensatez
Casi no hace falta decir que ejecutar la integración continua en todas las ramas activas es una buena idea. Pero ¿también es buena idea ejecutar todas las compilaciones en todas las ramas para todas las confirmaciones? Probablemente, no. Aquí te explicamos por qué.
Veamos, por ejemplo, el caso de Atlassian. Contamos con más de 800 desarrolladores, cada uno de los cuales introduce cambios en el repositorio varias veces al día, principalmente a sus ramas de función. Eso son muchas compilaciones, lo que supone mucho tiempo de espera en la cola a menos que escales tus agentes de compilación de forma instantánea e infinita.
Uno de nuestros servidores internos de Bamboo alberga 935 planes de compilación distintos. Conectamos 141 agentes de compilación a este servidor y seguimos las prácticas recomendadas, como la aprobación de artefactos y la paralelización de pruebas, para que cada compilación fuera lo más eficiente posible. Aun así, las compilaciones después de cada envío generaban cuellos de botella.
En lugar de configurar otra instancia de Bamboo con más de 100 agentes adicionales, hemos dado un paso atrás y nos hemos preguntado si de verdad era necesario. Y la respuesta ha sido que no.
De este modo, ofrecimos a los desarrolladores la opción de crear sus compilaciones de ramas con pulsador, en lugar activarlas siempre automáticamente. Es una buena forma de hacer balance del rigor de las pruebas con la conservación de recursos, y las ramas es donde se produce la mayor parte de la actividad, de modo que hay una gran oportunidad para ahorrar.
A muchos desarrolladores les gusta el control adicional que ofrecen las compilaciones mediante pulsador, y ven que se ajusta forma natural en su workflow. Otros prefieren no pensar sobre cuándo ejecutar una compilación, y se ciñen a los activadores automatizados. Cualquier enfoque puede funcionar. Lo importante es someter las ramas a pruebas y garantizar que cuentas con una compilación limpia antes de realizar una fusión más adelante.

Las ramas críticas, como la principal y las de versión estable, son otra historia. En ellas, las compilaciones se activan de forma automática, ya sea buscando cambios en el repositorio o enviando una notificación de envío de Bitbucket a Bamboo. Como utilizamos ramas de desarrollo para todo nuestro trabajo en progreso, las únicas confirmaciones en la rama principal deben ser (en teoría) ramas de desarrollo que se fusionan. Además, estas son las líneas de código desde las que lanzamos y creamos nuestras ramas de desarrollo. Por eso es tan importante que obtengamos los resultados de las pruebas a tiempo en cada fusión.
5: Dejar los sondeos y empezar a usar hooks
Sondear tu repositorio cada pocos minutos en busca de cambios es pan comido para Bamboo. Pero si tienes cientos de compilaciones en miles de ramas con decenas de repositorios, todo se va acumulando rápidamente. En lugar de sobrecargar Bamboo con todos esos sondeos, puedes configurar Bitbucket para que indique cuándo se ha enviado un cambio y se requiere una compilación.
Normalmente, esto se consigue añadiendo un hook al repositorio, aunque en este caso la integración entre Bitbucket y Bamboo se encarga de toda la configuración por ti. Una vez vinculados en el back-end, las compilaciones basadas en el repositorio activan Just Work™ para que esté listo para usar, sin hooks ni configuraciones especiales.
Independientemente de las herramientas, los desencadenadores basados en el repositorio tienen la ventaja de que desaparecen automáticamente cuando la rama de destino se vuelve inactiva. Esto quiere decir que nunca malgastarás ciclos de CPU en los sistemas de CI sondeando cientos de ramas abandonadas ni perderás tiempo desactivando manualmente las compilaciones de rama. (Si prefieres seguir con los sondeos, vale la pena señalar que Bamboo se puede configurar fácilmente para que ignore las ramas después de un número determinado de días de inactividad).
La clave para usar Git con CI es...
... pensarlo todo muy bien. Algunas de las cosas que iban de fábula al aplicar CI con un VCS centralizado dejarán de ir tan bien con Git. Así que el primer paso es comprobar tus suposiciones. Para los clientes de Atlassian, el segundo paso consiste en integrar Bamboo y Bitbucket. En nuestra documentación encontrarás más información. ¡Feliz compilación!
Compartir este artículo
Tema siguiente
Lecturas recomendadas
Consulta estos recursos para conocer los tipos de equipos de DevOps o para estar al tanto de las novedades sobre DevOps en Atlassian.

La comunidad de DevOps

Leer el blog