Monorrepositorios en Git
¿Qué es un monorrepositorio?
Existen diferentes definiciones, pero nosotros definimos un monorrepositorio de la siguiente manera:
- El repositorio contiene más de un proyecto lógico (por ejemplo, un cliente iOS y una aplicación web)
- Lo más probable es que estos proyectos no estén relacionados, que estén poco conectados o que puedan conectarse por otros medios (por ejemplo, a través de herramientas de gestión de dependencias)
- El repositorio es grande en muchos sentidos:
- Número de confirmaciones
- Número de ramas y/o etiquetas
- Número de archivos rastreados
- Tamaño del contenido rastreado (medido según el directorio .git del repositorio)
Facebook tiene un ejemplo de monorrepositorio:
Con miles de confirmaciones a la semana en cientos de miles de archivos, el repositorio de origen principal de Facebook es enorme, muchas veces mayor incluso que el kernel de Linux, que registró 17 millones de líneas de código y 44 000 archivos en 2013.
Material relacionado
Cómo mover un repositorio de Git completo
VER LA SOLUCIÓN
Aprende a usar Git con Bitbucket Cloud
El repositorio de pruebas que utilizó Facebook al llevar a cabo pruebas de rendimiento fue el siguiente:
- 4 millones de confirmaciones
- Historial lineal
- Alrededor de 1,3 millones de archivos
- El tamaño del directorio .git era de aproximadamente 15 GB
- El tamaño del archivo de índice era de 191 MB
Cuestiones conceptuales
Hay muchos desafíos conceptuales a la hora de gestionar proyectos no relacionados en un monorrepositorio en Git.
En primer lugar, Git rastrea el estado de todo el árbol en todas las confirmaciones que se llevan a cabo. Esto está bien para proyectos individuales o relacionados, pero es difícil de manejar en el caso de repositorios que contienen muchos proyectos no relacionados. En pocas palabras, las confirmaciones en partes no relacionadas del árbol afectan al subárbol que es relevante para un desarrollador. Este problema es peor a gran escala, con un gran número de confirmaciones que avanzan en el historial del árbol. Como la punta de la bifurcación cambia constantemente, es necesario hacer fusiones frecuentemente o un rebase local para enviar los cambios.
En Git, una etiqueta es un alias con nombre para una confirmación en particular, que se refiere a todo el árbol. Sin embargo, las etiquetas pierden utilidad en el contexto de un monorrepositorio. Hazte esta pregunta: si estás trabajando en una aplicación web que se implementa continuamente en un monorrepositorio, ¿qué relevancia tiene la etiqueta de publicación para el cliente iOS con control de versiones?
Problemas de rendimiento
Además de estas cuestiones conceptuales, hay una serie de aspectos relacionados con el rendimiento que pueden afectar a la configuración de un monorrepositorio.
Número de confirmaciones
Gestionar proyectos no relacionados en un único repositorio a gran escala puede ser problemático a nivel de confirmación. Con el tiempo, puede llevar a una gran cantidad de confirmaciones con una tasa de crecimiento significativa (Facebook habla de "miles de confirmaciones a la semana"). Esto resulta especialmente problemático, ya que Git utiliza un gráfico acíclico dirigido (DAG) para representar el historial de un proyecto. Si hay una gran cantidad de confirmaciones, cualquier comando que recorra el gráfico podría volverse lento a medida que el historial aumenta.
Some examples of this include investigating a repository's history via git log or annotating changes on a file by using git blame. With git blame if your repository has a large number of commits, Git would have to walk a lot of unrelated commits in order to calculate the blame information. Other examples would be answering any kind of reachability question (e.g. is commit A reachable from commit B). Add together many unrelated modules found in a monorepo and the performance issues compound.
Número de referencias
Tener una gran cantidad de referencias (es decir, ramas o etiquetas) en un monorrepositorio afecta al rendimiento de muchas maneras.
Ref advertisements contain every ref in your monorepo. As ref advertisements are the first phase in any remote git operation, this affects operations like git clone, git fetch or git push. With a large number of refs, performance takes a hit when performing these operations. You can see the ref advertisement by using git ls-remote with a repository URL. For example, git ls-remote git://git.kernel.org/ pub/scm/linux/kernel/git/torvalds/linux.git will list all the references in the Linux Kernel repository.
If refs are loosely stored listing branches would be slow. After a git gc refs are packed in a single file and even listing over 20,000 refs is fast (~0.06 seconds).
Any operation that needs to traverse a repository's commit history and consider each ref (e.g. git branch --contains SHA1) will be slow in a monorepo. In a repository with 21708 refs, listing the refs that contain an old commit (that is reachable from almost all refs) took:
Tiempo del usuario (segundos): 146,44*
* Este valor variará en función de las cachés de página y de la capa de almacenamiento subyacente.
Número de archivos rastreados
La memoria caché de índice o directorio (.git/index) rastrea todos los archivos de tu repositorio. Git se vale de este índice para determinar si un archivo ha cambiado ejecutando stat(1) en todos los archivos y comparando la información de modificación del archivo con la información contenida en el índice.
Por lo tanto, el número de archivos rastreados afecta al rendimiento* de muchas operaciones:
git statuspodría ser lento (estadísticas de cada archivo, el archivo de índice será grande)git committambién podría ser lento (también muestra estadísticas de cada archivo)
* Esto variará en función de las cachés de página y de la capa de almacenamiento subyacente, y solo se nota cuando hay una gran cantidad de archivos (decenas o cientos de miles).
Archivos grandes
Los archivos grandes en un solo subárbol/proyecto afectan al rendimiento de todo el repositorio. Por ejemplo, los activos multimedia de gran tamaño que se añaden a un proyecto de cliente iOS en un monorrepositorio se clonan a pesar de que un desarrollador (o agente de compilación) trabaje en un proyecto no relacionado.
Efectos combinados
Ya sea por la cantidad de archivos, la frecuencia con la que se cambian o su tamaño, estos problemas combinados tienen un mayor impacto en el rendimiento:
- Cambiar entre ramas/etiquetas, que es más útil en un contexto de subárbol (por ejemplo, el subárbol en el que estoy trabajando), actualiza todo el árbol. Este proceso puede ser lento debido a la cantidad de archivos afectados o porque requiere una solución alternativa. Al usar
git checkout ref-28642-31335 -- templates, por ejemplo, actualiza el directorio./templatespara que coincida con la rama en cuestión, pero sin actualizarHEAD, lo que tiene el efecto secundario de marcar los archivos actualizados como modificados en el índice. - La clonación y la recuperación se ralentizan y consumen muchos recursos en el servidor, ya que toda la información se condensa en un archivo de paquete antes de la transferencia.
- La recolección de basura es lenta y se desencadena por defecto con los envíos (si es necesaria).
- El uso de recursos es elevado en las operaciones para las que hay que crear o volver a crear un archivo de paquete, como
git upload-pack, git gc.
Estrategias de mitigación
Aunque sería genial que Git admitiera los repositorios monolíticos, que suelen utilizarse en casos especiales, los objetivos de diseño de Git que lo hicieron enormemente exitoso y popular a veces no permiten usarlo de una manera para la que no fue diseñado, como nos gustaría a veces. La buena noticia para la gran mayoría de los equipos es que los repositorios monolíticos realmente grandes tienden a ser la excepción y no la regla. Entonces, aunque espero que este artículo te parezca interesante, lo más probable es que nunca te enfrentes a una situación así.
Dicho esto, hay diversas estrategias de mitigación que pueden ser de gran ayuda cuando se trabaja con repositorios grandes. Mi colega Nicola Paolucci presenta algunas soluciones alternativas para repositorios con historiales largos o activos binarios grandes.
Eliminar referencias
Si el repositorio tiene decenas de miles de referencias, puedes plantearte eliminar las que ya no necesitas. El DAG conserva el historial de los cambios y las confirmaciones de fusión apuntan a los elementos principales, de modo que el trabajo que hagas en las ramas podrá rastrearse, aunque la rama ya no exista.
En un flujo de trabajo basado en ramas, el número de ramas de larga duración que conviene conservar es pequeño. No tengas miedo de eliminar una rama de función de corta duración después de una fusión.
Puedes optar por eliminar todas las ramas que se hayan fusionado en una rama principal (por ejemplo, production). Seguirás pudiendo rastrear el historial de cómo han evolucionado los cambios, siempre y cuando se pueda acceder a una confirmación desde la rama main y hayas fusionado tu rama con una confirmación de fusión. El mensaje de confirmación de fusión predeterminado suele incluir el nombre de la rama, para que puedas conservar esta información, si es necesario.
Gestión de grandes cantidades de archivos
Si el repositorio tiene una gran cantidad de archivos (decenas o cientos de miles), puede venir bien usar un almacenamiento local rápido con mucha memoria que se pueda usar como caché de búfer. Esta es un área que requeriría cambios más significativos para el cliente, similares, por ejemplo, a los que Facebook implementó para Mercurial.
Su estrategia utilizaba notificaciones del sistema de archivos para registrar los cambios en los archivos en lugar de iterar sobre todos los archivos para comprobar si alguno de ellos había cambiado. Se ha examinado un concepto similar (que también usa watchman) para Git, pero aún no se ha llegado a resultados.
Uso de Git Large File Storage (LFS)
Esta sección se actualizó el 20 de enero de 2016
En el caso de proyectos que incluyen archivos grandes, como vídeos o gráficos, Git LFS permite reducir su impacto en el tamaño y el rendimiento general del repositorio. En lugar de almacenar objetos grandes directamente en el repositorio, Git LFS almacena un archivo de marcador de posición pequeño con el mismo nombre que contiene una referencia al objeto, que a su vez se almacena en un almacén de objetos grande y especializado. Git LFS se enlaza a las operaciones nativas de envío (push), incorporación (pull), extracción (checkout) y recuperación (fetch) de Git para gestionar la transferencia y sustitución de estos objetos en tu árbol de trabajo de forma transparente. De esta forma, puedes trabajar con archivos grandes en tu repositorio como lo harías normalmente, sin las desventajas de tener un tamaño de repositorio excesivo.
Bitbucket Server 4.3 (y posteriores) incorpora una implementación de Git LFS v1.0 (y posteriores) totalmente compatible y permite previsualizar y comparar grandes activos de imagen rastreados por LFS directamente en la interfaz de usuario de Bitbucket.
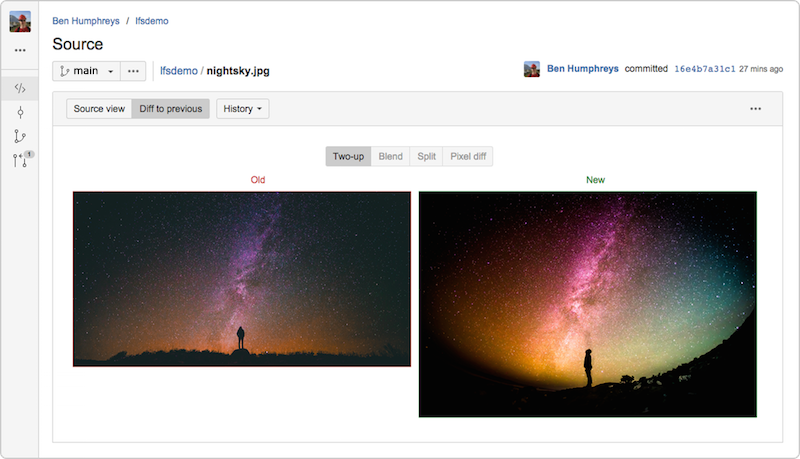
Mi compañero de Atlassian Steve Streeting es colaborador en activo del proyecto LFS y hace muy poco escribió sobre este proyecto.
Determinar los límites y dividir el repositorio
La solución más radical es dividir tu monorrepositorio en repositorios de Git más pequeños y selectivos. Intenta que no se rastree cada cambio en un único repositorio y, en su lugar, determina los límites de los componentes (por ejemplo, identificando módulos o componentes que tengan un ciclo de publicación similar). Una buena forma de comprobar si los subcomponentes están despejados es usar etiquetas en un repositorio y verificar si tienen sentido para otras partes del árbol de origen.
Aunque sería genial que Git admitiera monorrepositorios, el concepto de monorrepositorio no encaja del todo con lo que ha dado a Git su éxito y popularidad. Sin embargo, eso no significa que debas renunciar a las capacidades de Git si tienes un monorrepositorio; en la mayoría de los casos, hay soluciones viables para cualquier incidencia que pueda surgir.
Compartir este artículo
Tema siguiente
Lecturas recomendadas
Consulta estos recursos para conocer los tipos de equipos de DevOps o para estar al tanto de las novedades sobre DevOps en Atlassian.

Blog de Bitbucket

Ruta de aprendizaje de DevOps
