Cómo gestionar
repositorios grandes con Git

Nicola Paolucci
Experto en desarrollo
Git es una opción fantástica para llevar un seguimiento de la evolución de tu código base y colaborar de manera eficiente con tus compañeros. Pero ¿qué ocurre cuando el repositorio del que quieres realizar un seguimiento es muy grande?
En esta entrada te voy a dar técnicas para afrontarlo.
Dos categorías de repositorios grandes
Si lo piensas bien, hay dos razones principales por las que los repositorios crecen masivamente:
- Acumulan un historial muy largo (el proyecto crece durante un periodo de tiempo prolongado y el equipaje se acumula).
- Incluyen activos binarios enormes que deben rastrearse y combinarse con el código.
... o quizá ambas cosas.
A veces, el segundo tipo de problema se ve agravado por el hecho de que los artefactos binarios obsoletos anteriores todavía siguen almacenados en el repositorio, pero para eso hay una corrección relativamente fácil, aunque molesta (la veremos más abajo).
Las técnicas y las soluciones alternativas para cada caso son diferentes, aunque a veces complementarias, así que las explicaré por separado.
Clonar repositorios con un historial muy largo
Aunque el umbral para calificar un repositorio como "masivo" es bastante alto, sigue siendo difícil clonarlos. Y no siempre se pueden evitar los historiales largos. Algunos repositorios deben mantenerse intactos por razones legales o reglamentarias.
La solución sencilla: clonación superficial de Git
La primera solución para clonar rápidamente y ahorrar tiempo y espacio en disco, tanto al desarrollador como al sistema, es copiar solo las revisiones recientes. La opción de clonación superficial de Git te permite extraer solo las últimas n confirmaciones del historial del repositorio.
¿Que cómo se hace? Tan solo hay que usar la opción --depth; por ejemplo:
git clone --depth [depth] [remote-url]
Imagina que has acumulado diez o más años de historial de proyectos en tu repositorio (por ejemplo, para Jira migramos a Git un código base de 11 años): el ahorro de tiempo puede ir sumando y llegar a ser muy notable.
La clonación completa de Jira es de 677 MB y el directorio de trabajo tiene más de 320 MB, lo que representa más de 47 000 confirmaciones. Una clonación superficial tarda 29,5 segundos en comparación con los 4 minutos y 24 segundos de una clonación completa de todo el historial. Los beneficios también aumentan proporcionalmente según la cantidad de activos binarios que tu proyecto haya consumido a lo largo del tiempo.
Material relacionado
Cómo mover un repositorio de Git completo
VER LA SOLUCIÓN
Aprende a usar Git con Bitbucket Cloud
Consejo: Las clonaciones superficiales también son prácticas para los sistemas de compilación conectados a un repositorio de Git.
Las clonaciones superficiales solían ser algo así como ciudadanos del mundo Git deteriorados, ya que algunas operaciones apenas se admitían. Sin embargo, las versiones recientes (a partir de la 1.9) han mejorado mucho la situación, y ahora se pueden llevar a cabo operaciones de incorporación y envío correctamente a los repositorios incluso desde una clonación superficial.
La solución selectiva: filter-branch
En el caso de los repositorios enormes que tienen un gran volumen de código binario redundante que se ha confirmado por error o activos antiguos que ya no se necesitan, el uso de git filter-branch es una solución fantástica. El comando permite recorrer todo el historial del proyecto filtrando, modificando y omitiendo archivos según patrones predefinidos.
Esta es una herramienta muy eficaz una vez que hayas identificado lo que sobra en tu repositorio. Hay scripts de ayuda disponibles para identificar objetos grandes, por lo que debería ser bastante fácil utilizarla.
Esta es la sintaxis:
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'Sin embargo, git filter-branch tiene un inconveniente menor: al usar _filter-branch_, se reescribe de manera efectiva todo el historial del proyecto. Es decir, todos los identificadores de confirmación cambian. Esto requiere que todos los desarrolladores vuelvan a clonar el repositorio actualizado.
Por lo tanto, en caso de que planifiques llevar a cabo una acción de limpieza con git filter-branch, debes avisar a tu equipo, planificar una congelación breve mientras se lleva a cabo la operación y, a continuación, comunicar a todos que deben clonar el repositorio otra vez.
Consejo: Puedes consultar más información sobre git filter-branch en esta entrada sobre cómo descomponer tu repositorio de Git.
Alternativa a la clonación superficial: clonar una sola rama
A partir de la versión git 1.7.10, también puedes limitar la cantidad de historial que clonas clonando una sola rama, como se muestra a continuación:
git clone [remote url] --branch [branch_name] --single-branch [folder]Este truco específico es útil cuando trabajas con ramas divergentes y de larga duración, o bien si tienes muchas ramas y solo necesitas trabajar con algunas de ellas. Si solo tienes un puñado de ramas con muy pocas diferencias, probablemente no notes un gran cambio al hacerlo.
Gestionar repositorios con activos binarios enormes
El segundo tipo de gran repositorio es el que contiene activos binarios enormes. Es algo con lo que se encuentran muchos equipos distintos de software (y otros). Los equipos de videojuegos tienen que trabajar con modelos 3D enormes, los equipos de desarrollo web pueden tener que rastrear los activos de imágenes sin procesar y los equipos de CAD pueden tener que manipular y rastrear el estado de entregables binarios.
Git no es especialmente malo en la gestión de activos binarios, pero tampoco es particularmente bueno. De manera predeterminada, Git comprimirá y almacenará todas las versiones completas posteriores de los activos binarios, lo que obviamente no es ideal si tienes muchos.
Hay algunos trucos básicos que mejoran la situación, como ejecutar la recolección de basura (‘git gc’) o ajustar el uso de las confirmaciones delta para algunos tipos binarios en .gitattributes.
No obstante, es importante reflexionar sobre la naturaleza de los activos binarios de tu proyecto, ya que eso te ayudará a determinar el enfoque más eficaz. Por ejemplo, se deben tener en cuenta los siguientes puntos:
- Para los archivos binarios que cambian significativamente, y no solo en algunos encabezados de metadatos, la compresión delta probablemente será inútil. Por lo tanto, usa ‘delta off’ en esos archivos para evitar el trabajo innecesario de compresión delta durante el reempaquetado.
- En la situación anterior, es probable que esos archivos tampoco se compriman muy bien con zlib, por lo que podrías desactivar la compresión con ‘core.compression 0’ o ‘core.compression 0’. Esa es una configuración global que afectaría negativamente a todos los archivos no binarios que en realidad se comprimen bien, por lo que tiene sentido si divides los activos binarios en un repositorio independiente.
- Es importante recordar que ‘git gc’ convierte los objetos sueltos “duplicados” en un solo archivo empaquetado. Pero, de nuevo, a menos que los archivos se compriman de alguna manera, esa acción probablemente no cambie de forma significativa el archivo empaquetado resultante.
- Explora los ajustes que puedes hacer a ‘core.bigFileThreshold’. No se le aplicará compresión delta (sin tener que configurar .gitattributes) a ningún archivo de más de 512 MB, así que tal vez sea algo que valga la pena modificar.
Solución para árboles de carpetas grandes: git sparse-checkout
Una pequeña ayuda para el problema de los activos binarios es la extracción escasa (disponible a partir de Git 1.7.0). Esta técnica permite mantener limpio el directorio de trabajo al detallar explícitamente las carpetas que quieres rellenar. Desafortunadamente, no afecta al tamaño del repositorio local en general, pero puede ser útil si tienes un árbol de carpetas enorme.
¿Cuáles son los comandos involucrados? He aquí un ejemplo:
- Clona el repositorio completo una vez: ‘git clone’
- Activa la función: ‘git config core.sparsecheckout true’
- Añade las carpetas que sean necesarias de forma explícita, ignorando las carpetas de activos:
- echo src/ › .git/info/sparse-checkout
- Lee el árbol según se especifica:
- git read-tree -m -u HEAD
Después del procedimiento anterior, puedes volver a usar tus comandos de Git habituales, pero tu directorio de trabajo solo contendrá las carpetas que has especificado antes.
Solución de control para actualizar archivos grandes: submódulos
[ACTUALIZACIÓN] ...o puedes omitir todo eso y usar Git LFS
Si trabajas habitualmente con archivos grandes, la mejor solución podría ser aprovechar la compatibilidad con archivos grandes (LFS) que Atlassian desarrolló conjuntamente con GitHub en 2015. (Sí, has leído bien. Nos asociamos con GitHub en una contribución de código abierto al proyecto Git).
Git LFS es una extensión que almacena punteros (¡naturalmente!) en archivos grandes de tu repositorio en lugar de almacenar los archivos en sí. Los archivos reales se almacenan en un servidor remoto. Como puedes imaginar, esto reduce muchísimo el tiempo que se tarda en clonar el repositorio.
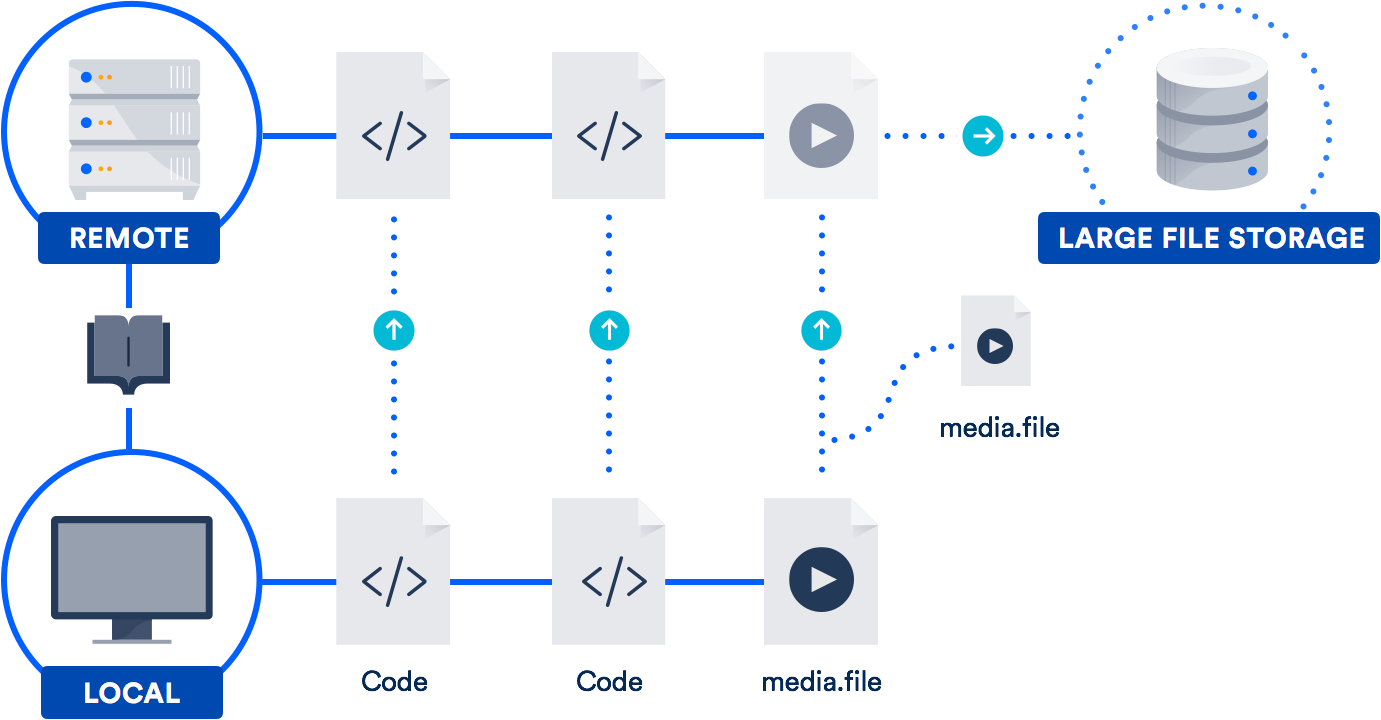
Al igual que GitHub, Bitbucket es compatible con Git LFS. Por eso, es probable que ya tengas acceso a esta tecnología, que es especialmente útil para equipos que incluyen diseñadores, videógrafos, músicos o usuarios de CAD.
Conclusiones
No renuncies a las fantásticas capacidades de Git solo porque tengas un historial de repositorio o activos de gran tamaño. Hay soluciones viables para ambos problemas.
Consulta los otros artículos que he vinculado para obtener más información sobre submódulos, dependencias de proyecto y Git LFS. Si quieres ponerte al día sobre comandos y flujo de trabajo, en nuestro micrositio de Git encontrarás muchos tutoriales. ¡Que te diviertas programando!
Compartir este artículo
Tema siguiente
Lecturas recomendadas
Consulta estos recursos para conocer los tipos de equipos de DevOps o para estar al tanto de las novedades sobre DevOps en Atlassian.

Blog de Bitbucket

Ruta de aprendizaje de DevOps
